



Hugging Face Transformers Model
Hugging Face Transformersライブラリは、多くの事前トレーニング済みモデルを提供しており、これらのモデルを簡単に使用して、新しいタスクに適用することができます。同時に、自分自身のトレーニング済みモデルを Model Hub に登録して、他のユーザーと共有することもできます。
この記事では、Modelについて解説します。
Transformer の派生モデル
Transformer のアーキテクチャは下図のようになっています。
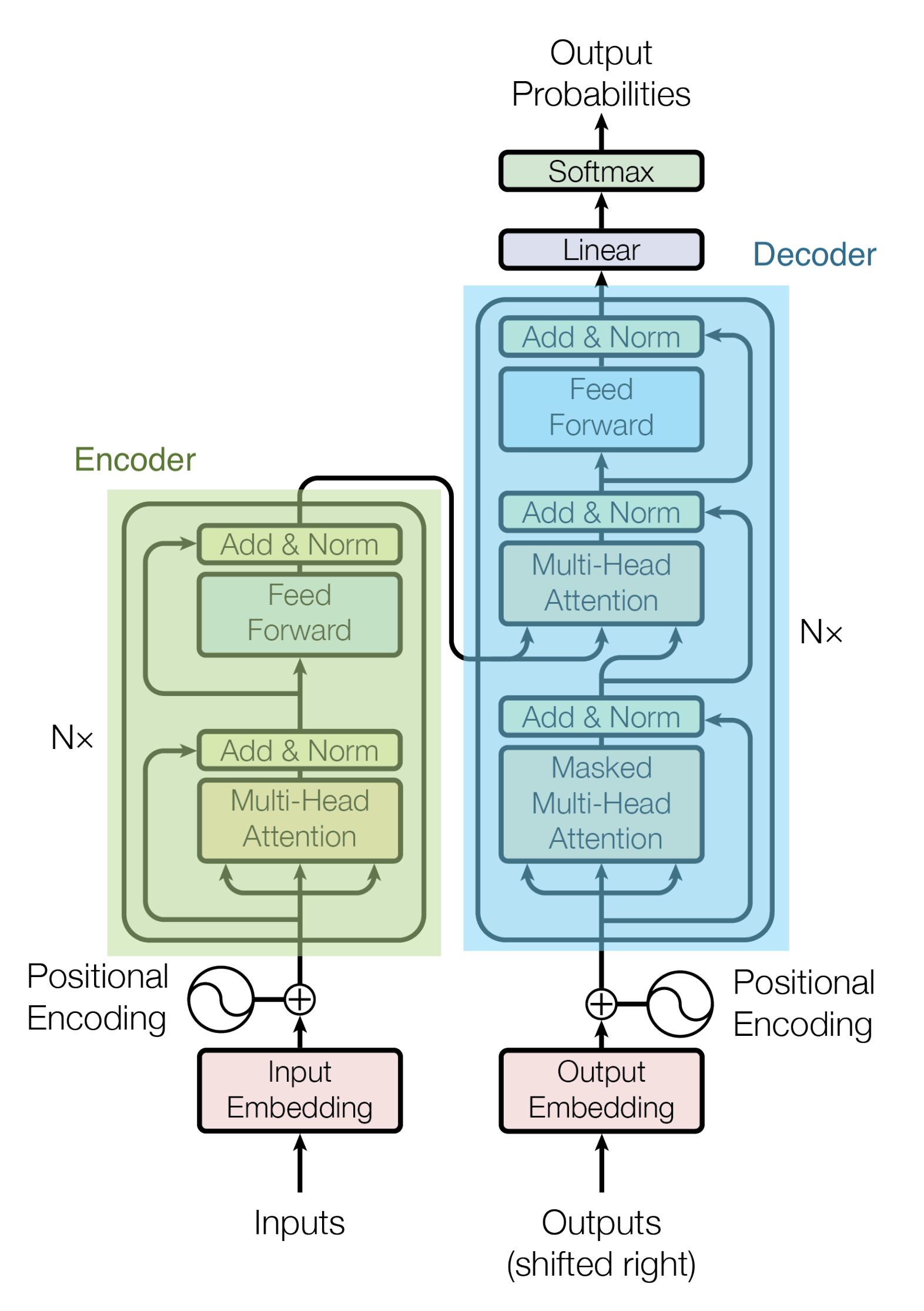
Transformerの派生モデルとして、EncoderとDecoderを切り離して個別に使用した次のようなモデルがあります。
- Encoder モデル
- BERT
- ALBERT
- RoBERTa
- DistilBERT
- XLM
- XLM-RoBERTa
- ELECTRA
- Decoder モデル
- GPT
- GPT-2
- CTRL
- Reformer
- XLNet
- Encoder-Decoder モデル
- BART
- T5
- MBart
Encoder モデル
Encoderモデルは、TransformerのEncoder部分のみを使ったモデルです。Attention 層は入力系列データに含まれる全ての単語に対して注目することができ、各単語の前後にある単語にも注目できる双方向のAttentionとなっています。
入力系列データの一部をマスキングし、元の単語を予測させるという穴埋め問題を解くタスクを設定して学習が行われます。Encoderモデルは入力系列データの特徴表現を出力するので、それを分類器に渡す形でモデリングが可能なタスクに適しています。例えば文書分類、固有表現認識、対象の文書内から回答部分を抽出するタイプの質問応答などが得意です。
BERT
BERT は Wikipedia と Bookcorpus で構成される大規模なコーパスを使って事前トレーニングされた双方向Transformerです。
ALBERT
ALBERTはBERTに対して次の微調整をしたモデルです。
- トークンの埋め込み次元を隠れ層の次元から切り離し、埋め込み次元を削減
- 全ての層で同じパラメータを共有することによりパラメータ数が減少
- 次文予測を文の順序予測に置き換えて学習
RoBERTa
RoBERTaはBERTをベースにより多くの学習データと大きなバッチで長時間学習させたモデルです。
DistilBERT
DistilBERT は事前学習フェーズでKnowledge Distillationを使うことで、BERTを蒸留したモデルです。BERTの性能の97%を達成しつつ、40%少ないメモリ使用量と60%の高速化を達成しています。
XLM
XLMは複数の言語で学習されたTransformerです。このモデルの学習には次の3つの異なるタイプがあります。
- 因果言語モデル(Causal language modeling, CLM)
- マスク付き言語モデル(Masked language modeling, MLM)
- MLMと翻訳言語モデル(Translation language modeling, TLM)の組み合わせ
XLM-RoBERTa
XLM-RoBERTaは Common Crawl コーパスを用いて2.5TBのデータセットを用いて学習させたモデルです。このデータセットには翻訳が含まれていないため、XLMで用いられた翻訳言語モデルは削除されています。
ELECTRA
ELECTRAは生成器(Generator)と識別器(Discriminator)の2つの変換器を学習させる新しい事前学習アプローチです。Generatorの役割はシーケンス中のトークンを置き換えることであり、従ってマスクされた言語モデルとして学習されます。一方、Discriminatorは、シーケンス中のどのトークンがGeneratorによって置き換えられたかを識別しようとするモデルです。
Decoder モデル
Decoderモデルは、TransformerのDecoder部分のみを使ったモデルです。入力系列データに含まれる単語に対して、次に続く単語を予測するタスクを設定して学習を進めます。
Attention層は入力データに含まれる単語のうち、それぞれの単語の前にある単語にのみ注目します。Decoderモデルはテキスト生成のようなタスクに適したモデルとなっています。
GPT
GPTはOpenAIが2018年に提案したGenerative Pre-trained Transformerという大規模な言語モデルで、タスクに特化した学習をしなくても自然な文章を生成できることが特徴です。GPTでは前の単語を元に次の単語を予測することでモデルを事前学習をします。
GPTでは Book Corpus データセットで事前学習されています。
GPT-2
GPT-2はOpenAIが2019年に提案したGPTの後継モデルです。GPTのモデルと学習データセットをスケールアップすることでGPT2が誕生しました。
CTRL
CTRLは、系列の先頭にコントロールトークンを追加することで、生成される系列のスタイルを制御することができるモデルです。
Reformer
Reformerは、メモリフットプリントと計算時間を削減するための多くの改良を加えたDecoderモデルです。
XLNet
XLNetは、自己回帰法を用いて事前学習を行い、入力シーケンスの分解順序の全ての並べ換えに対して期待尤度を最大化することで双方向の文脈を学習するモデルです。
Encoder-Decoder モデル
Encoder-Decoderモデルは、Transformerのアーキテクチャを全体的に活用したモデルです。
Encoder部分は入力系列データの単語全てに注目し、Decoder部分はそれぞれの単語よりも前に出てくる単語のみに注目します。Encoderモデルでの穴埋め問題を解くタスクと、Decoderモデルで次に続く単語を予測するタスクの両方を設定して学習を進めます。
Encoder-Decoderモデルは機械翻訳や対話システムなど、テキストを入力してその内容に応じて別のテキストを出力するといったタスクへの応用に適しています。
BART
BARTは、BERTとGPTの事前学習をEncoder、Decoderのアーキテクチャの中で組み合わせたものです。
T5
T5はGoogleが2020年に提案したモデルで、Text-to-Text Transfer Transformerの略です。T5は全ての自然言語理解と自然言語生成のタスクをテキストの変換タスクに変換して統一的に解くことができます。
MBart
MBARTは、25言語の大規模モノリンガルコーパスにBARTの目的語を用いて事前学習させたモデルです。MBARTは複数の言語の完全なテキストをノイズ除去することで、完全なシーケンス間のモデルを事前学習する最初の方法の一つです。
Model の使い方
Transformerライブラリをインストールします。
$ pip install transformers
Model の読み込み
AutoModelクラスにより、使いたいモデルのcheckpointを指定することで簡単にモデルを使うことができます。次の例ではbert-base-uncasedというモデルを指定しています。
from transformers import AutoModel
checkpoint = 'bert-base-uncased'
model = AutoModel.from_pretrained(checkpoint)
Hugging Face Transformersでは多くの事前学習済みモデルが公開されています。モデルの詳細は次のリンクから確認することができます。
モデルの構造
例えばBERTを使う場合は次のように読み込むこともできます。
from transformers import BertConfig, BertModel
config = BertConfig()
model = BertModel(config)
print(config)
BertConfig {
"attention_probs_dropout_prob": 0.1,
"classifier_dropout": null,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"position_embedding_type": "absolute",
"transformers_version": "4.24.0",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 30522
}
それぞれの属性の意味は次のリンクから確認することができます。
モデルの保存
次のコードでモデルを保存することができます。保存先のディレクトリが存在しない場合には、フォルダが自動的に作成されます。
model.save_pretrained("./tmp")
保存をすると次の2種類のファイルが保存されます。
config.jsonpytorch_model.bin
保存したモデルの読み込み
保存したモデルを読み込むには次のようにコードを記述します。
saved_model = model.from_pretrained("./tmp")
事前学習済み Transformer モデル利用時の注意点
学習済みモデルは一定のバイアスが含まれていることに注意をする必要があります。
BERTのfill-mask Pipelineを使って、職業に関する文において、主語を男性とした場合と女性とした場合の2種類を用意し、それぞれ職業名にあたる部分をマスクして当てはまる単語の候補をモデルに出力させてみます。
from transformers import pipeline
unmasker = pipeline("fill-mask", model="bert-base-uncased")
result = unmasker("This man works as a [MASK].")
print("man:", [r["token_str"] for r in result])
result = unmasker("This woman works as a [MASK].")
print("woman:", [r["token_str"] for r in result])
man: ['carpenter', 'lawyer', 'farmer', 'businessman', 'doctor']
woman: ['nurse', 'maid', 'teacher', 'waitress', 'prostitute']
いずれの結果も主語の性別に紐づいた職業名が候補として出力されていますが、重複しているものはなく、性別により差があることが分かります。さらに、主語が女性の場合の5番目の候補で、prostituteという蔑称としての意味合いを含んでいる単語が出力されています。
BERTモデルは Wikipedia と Bookcorpus という偏見などをあまり含まないであろうデータセットで事前学習されていますが、このような結果を出力してしまうケースもあります。
参考















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS