


BERT とは
BERTとは、Bidirectional Encoder Representations from Transformersの略で、2018年10月11日にGoogleが発表した自然言語処理モデルです。
BERTは大規模の教師なしデータを用いる双方向型の Transformer による事前学習モデルです。BERTは事前学習モデルであり、予測モデルではないため、BERT単体では何もできません。文書分類や感情分析など個別のタスク用にファインチューニングを行うことで予測モデルとなります。
BERT の特徴
BERTには次の特徴があります。
- 文脈理解
- 高い汎用性
- データ不足の克服
文脈理解
BERT以前にはELMoやOpenAI GPTといった言語処理モデルが存在しました。ELMoは浅い双方向モデルであり、OpenAI GPTは単一方向モデルだであったため、文脈を理解することができませんでした。
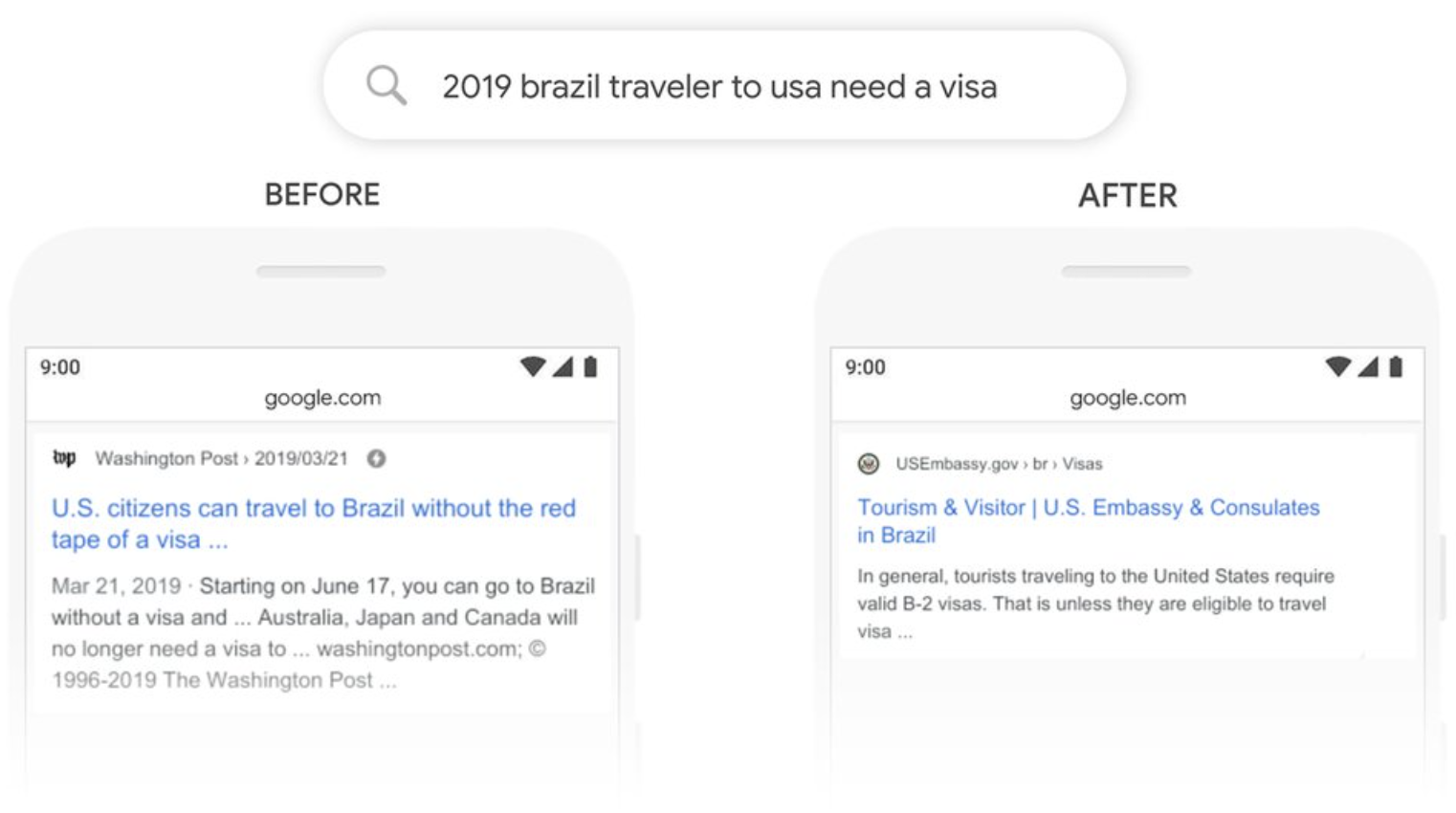
BERT導入以前のGoogle検索では「to」のような文と文の関係を結ぶ言葉を処理できませんでした。Googleが紹介している一例をここでは解説します。
BERTが導入される以前のGoogle検索では、「to」のような文と文の関係を結ぶ単語を処理することができませんでした。例えば、次の検索ワードがあるとします。
2019 brazil traveler to usa need a visa
上記の検索ワードの場合、ユーザーが知りたいことはブラジルからの旅行者はアメリカに行く際にビザが必要かどうかです。しかし、BERTの導入以前は「to」を処理できないため、「ブラジルへのアメリカ人旅行者」と解釈してしまうこともあり、ニーズとは合致しない検索結果が表示されていました。
BERTは双方向型Transformerを用いた、文脈を理解できるモデルです。BERT導入後、「アメリカへのブラジル人旅行者」と解釈ができるようになり、アメリカ大使館がブラジル人旅行者向けに公開しているビザ情報のページを上位に表示することができるようになりました。
Understanding searches better than ever before
高い汎用性
BERTでは、WikipediaやBooksCorpusなどから得た大量の文章データを事前学習し、その後ファインチューニングにより感情分析や翻訳などの様々なタスクに応用することができます。
データ不足の克服
BERTは従来のモデルとは異なり、ラベルなしのデータセットを処理することができます。ラベルが付与されたデータセットは入手が困難なケースが多いです。BERTではラベルが付与されていないデータを処理の材料にできるため、データ不足を克服することができます。
BERT の仕組み
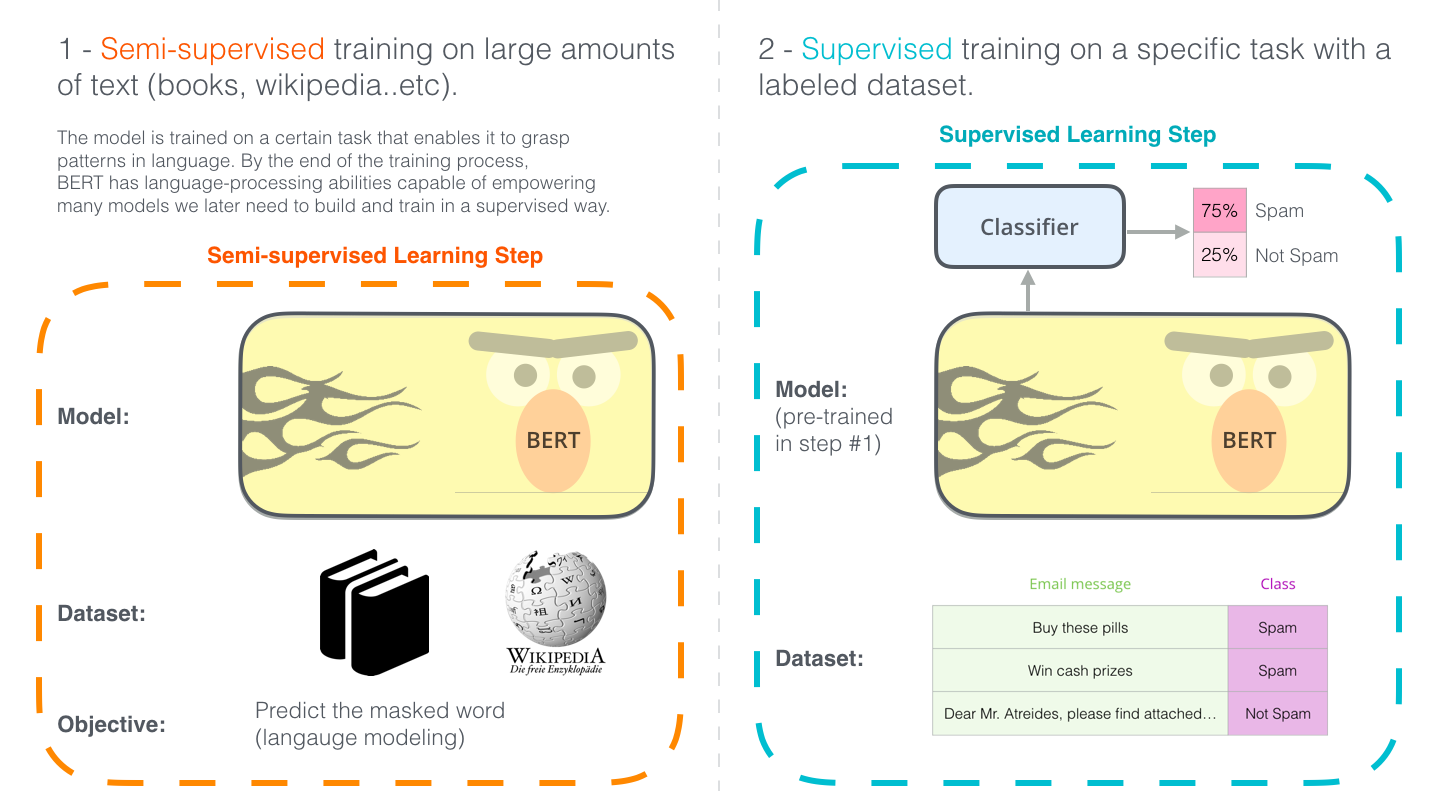
BERTの学習には次の2つのステップがあります。
- 事前学習
ラベルなしデータを用いて、事前学習を行う - ファインチューニング
事前学習の重みを初期値として、ラベルありデータでファインチューニングを行なう
例として、スパム分類タスクを図で表すと次のようになります。
The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)
BERTはTransformerのEncoderのみというアーキテクチャとなっており、BASEモデルとLARGEモデルが存在します。
| Model | L (Transformer ブロックの数) | H (隠れ層のサイズ) | A (Self-Attention ヘッドの数) | パラメータ数 |
|---|---|---|---|---|
| 12 | 768 | 12 | 110M | |
| 24 | 1024 | 16 | 340M |
事前学習
BERTの事前学習で用いるデータはラベルなしの生の文章データです。
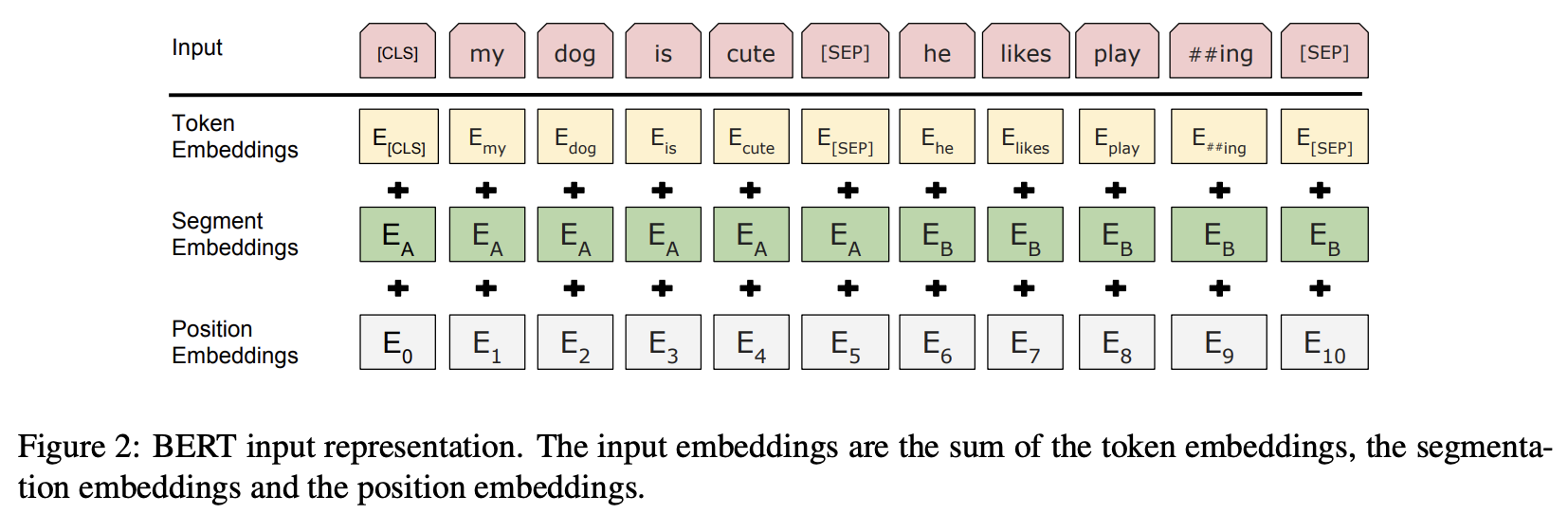
文書データは下図のようにベクトルのシーケンスに変換されます。
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
最上段の「Input」では、先頭に [CLS]、2つの文章A、 Bの末尾に [SEP]という特殊トークンを挿入して連結した構造が1入力シーケンスになります。
2段目以降では、入力シーケンスを投入した直後、3つのEmbeddingsによりトークン、文章の区分、シーケンス内の位置がそれぞれ事前学習の過程で学習されるH次元の埋め込み表現に置き換えられ、それらを加算したベクトルのシーケンスがTransformerへの入力になります。
- Token Embeddings: トークンID
- Segment Embeddings: 文章A、Bの区分
- Position Embeddings: シーケンス内の位置
BERTはこの入力に対し、次の2つの目的関数を合わせた事前学習を行います。
- Masked language Model
- Next Sentence Prediction
Masked Language Model
従来の自然言語処理モデルでは、文章を単一方向からでしか処理できなかったため、目的の単語の前の文章データから予測する必要がありました。しかし、BERTは双方向のTransformerによって学習するため、従来の手法に比べ精度が格段に向上しました。それを実現しているのがMasked Language Modelになります。
Masked Language Modelの処理は、入力文の15%の単語を確率的に別の単語で置き換えし、文脈から置き換える前の単語を予測させるという仕組みになっています。選択された15%のうち、80%は [MASK]に置き換えるマスク変換、10%をランダムな別の単語に変換、残りの10%はそのままの単語にします。
- 選択された15%のうち80%の単語は[MASK]に変換
- my dog is hairy ➡︎ my dog is [MASK]
- 選択された15%のうち10%の単語はランダムな単語に変換
- my dog is hairy ➡︎ my dog is apple
- 選択された15%のうち10%の単語はそのままにする
- my dog is hairy ➡︎ my dog is hairy
このように置換された単語を周りの文脈から当てるタスクを解くことで、単語に対応する文脈情報を学習することができます。
Next Sentence Prediction
Masked Language Modelにおいて単語に関しての学習はできるものの、文単位の学習を行うことはできません。そこで、2つの入力文に対してその2文が隣り合っているかを当てるよう学習します。Next Sentence Predictionによって、2つの文の関係性を学習することができます。
Next Sentence Predictionでは、文の片方を50%の確率で他の文に置き換え、それらが隣り合っているかどうか(isNext、notNext)を判別することによって学習します。2文を[SEP]というトークンで分け、isNextかnotNextか分類するために[CLS]というトークンが用意されます。
| 例文 | 判定 |
|---|---|
| [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP] | isNext |
| [CLS] the man went to [MASK] store [SEP] penguin [MASK] are flightless birds [SEP] | notNext |
このようにして、BERTは単語だけでなく文全体の表現についても学習することができるようになります。
ファインチューニング
BERTの事前学習済みモデルは、解きたいタスクに応じてファインチューニングします。ファインチューニングでは、比較的少数のラベル付きデータを用いて学習します。
ファインチューニングを行うときには、事前学習で得られたパラメータをモデルの初期値として、ラベル付きデータを用いてパラメータを学習します。
このように、ファインチューニングの際に事前学習で得られたパラメータを初期値として用いることで比較的少数の学習データでも高い性能のモデルを得ることができます。
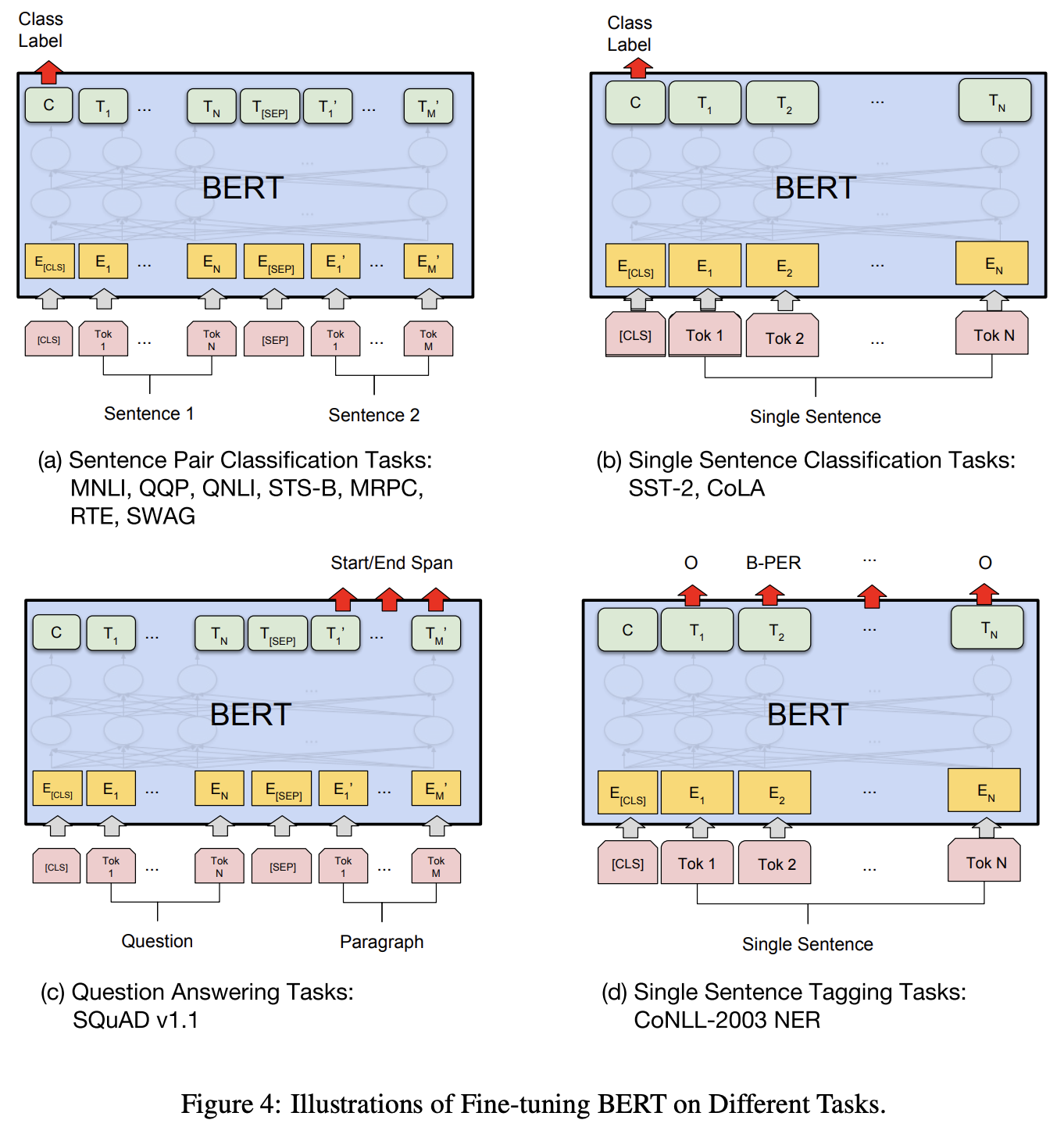
次の図はファインチューニングの例を示しています。
- (a) Sentence Pair Classification Tasks
- (b) Single Sentence Classification Tasks
- (c) Question Answering Tasks
- (d) Single Sentence Tagging Tasks
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT の性能ベンチマーク
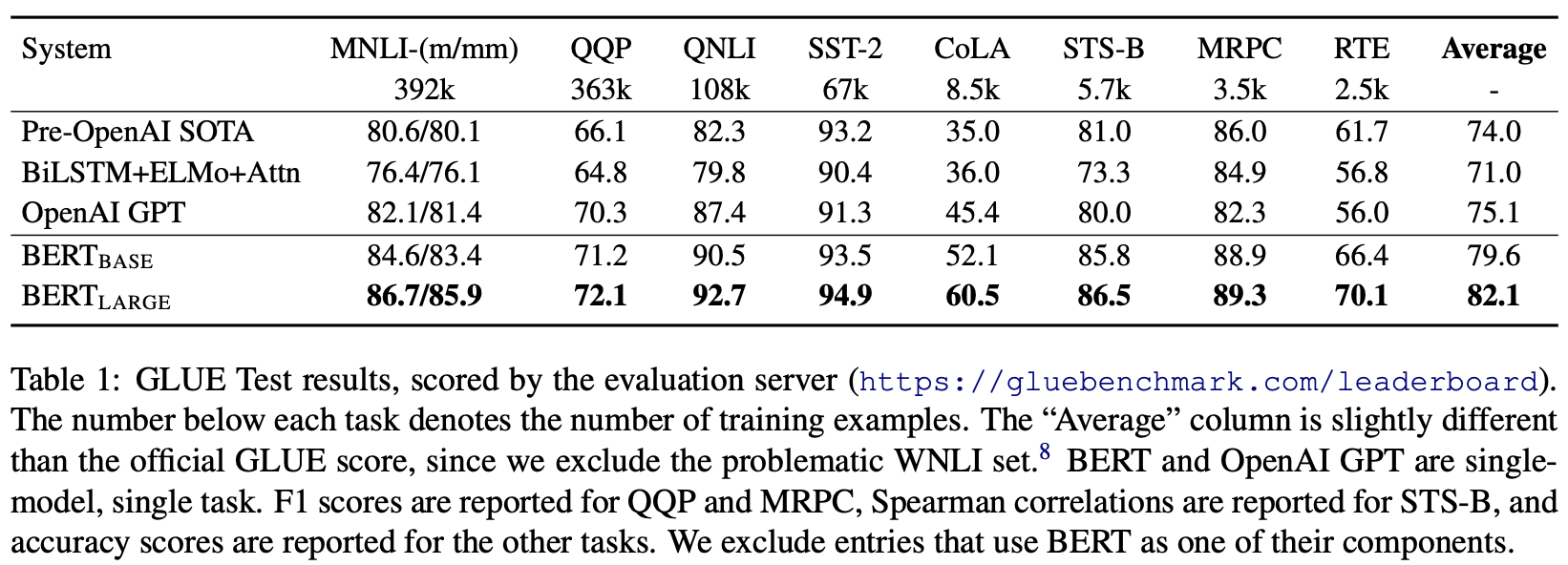
自然言語処理モデルの性能はGLUE(The General Language Understanding Evaluation)という指標で評価されます。GLUEはあらゆる自然言語処理タスクにおけるスコアを算出するベンチマークです。次の表は論文内で記載されたGLUEの結果になります。
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
全てのデータセットにおいてOPEN AIなどの既存モデルよりもBERTの方が高いスコアを出しています。
参考
















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS