



Hugging Face Transformers Tokenizer
Transformer のモデルでは、生のテキストデータを直接入力することはできないため、テキストを数値データに変換する必要があります。この数値データへの変換を行うのがTokenizerです。
Tokenizerは入力テキストに対して次の処理を行います。
- テキストを単語、サブワード、記号などといった最小の単位に区切る(トークン化)
- ぞれぞれのトークンにIDを振る
- モデルの入力に必要な情報となるスペシャルトークンを入力テキストに追加する
- 例えばBERTでは文の始まりを示す
<CLS>や文の区切りを示す<EOS>といったトークンが必要になります。
- 例えばBERTでは文の始まりを示す
AutoTokenizerクラスのfrom_pretrainedメソッドを使用することで指定したモデルのTokenizerを使うことができます。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
encoded_input = tokenizer("Do not meddle in the affairs of wizards, for they are subtle and quick to anger.")
print(encoded_input)
>> {'input_ids': [101, 2079, 2025, 19960, 10362, 1999, 1996, 3821, 1997, 16657, 1010, 2005, 2027, 2024, 11259, 1998, 4248, 2000, 4963, 1012, 102],
>> 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
戻り値の意味は次のとおりです。
| 戻り値 | 説明 |
|---|---|
| input_ids | 入力テキストをトークンに分け、それぞれを ID に置き換えたもの |
| attention_mask | 入力トークンについて、Attention の対象となるかを示すもの |
| token_type_ids | 一つの入力が複数文になっている場合などに、各トークンについてそれぞれがどの文のものかを示すもの |
基本的な使い方
次のようにAutoTokenizerクラスを使い、Tokenizerをインスタンス化します。
from transformers import AutoTokenizer
checkpoint = "bert-base-cased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
次のようにTokenizerを使ってテキストをエンコードすることができます。
text = "The quick brown fox jumps over the lazy dog."
encoded_text = tokenizer(text)
print(encoded_text)
>> {
>> 'input_ids': [101, 1109, 3613, 3058, 17594, 15457, 1166, 1204, 1103, 16688, 3676, 119, 102],
>> 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
>> }
convert_ids_to_tokensメソッドを使用することで、IDからトークンに戻すこともできます。
tokens = tokenizer.convert_ids_to_tokens(encoded_text.input_ids)
print(tokens)
['[CLS]', 'The', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog', '.', '[SEP]']
[CLS]というのはBERTモデルで文頭を示すトークンであり、[SEP]は文の区切りを表すトークンを指しています。inputs_idsの101は[CLS]を指し、102は[SEP]を指しています。
convert_tokens_to_stringメソッドを使用することで、IDからテキストへの変換することができます。
print(tokenizer.convert_tokens_to_string(tokens))
[CLS] The quick brown fox jumps over the lazy dog. [SEP]
IDからテキストへの変換は次のように行います。
decoded_string = tokenizer.decode(encoded_text["input_ids"])
print(decoded_string)
The quick brown fox jumps over the lazy dog.
スペシャルトークンなどは自動で除去してくれるので、推論結果の出力を行う際に活用しやすい形になっています。
複数の文のエンコード
Tokenizerに複数の文をリストで渡すことでまとめてエンコードすることができます。
batch_sentences = [
"But what about second breakfast?",
"Don't think he knows about second breakfast, Pip.",
"What about elevensies?",
]
encoded_inputs = tokenizer(batch_sentences)
print(encoded_inputs)
>> {'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102],
>> [101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
>> [101, 1327, 1164, 5450, 23434, 136, 102]],
>> 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0],
>> [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> [0, 0, 0, 0, 0, 0, 0]],
>> 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1],
>> [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
>> [1, 1, 1, 1, 1, 1, 1]]}
エンコーディングには次のオプションを設定することができます。
- 各文をバッチ内の文の最大長にパディング
- 各文をモデルが許容できる最大長で切り捨て
- テンソルを返す
パディング
モデルの入力であるテンソルは、均一な形状を持つ必要があります。そのため、文の長さ異なることが問題となり得ます。パディングは短い文に特別なパディングトークンを追加することでテンソルが長方形であることを保証する戦略です。
padding=Trueに設定すると、バッチ内の短いシーケンスが最長シーケンスに一致するようにパディングされます。
batch_sentences = [
"But what about second breakfast?",
"Don't think he knows about second breakfast, Pip.",
"What about elevensies?",
]
encoded_input = tokenizer(batch_sentences, padding=True)
print(encoded_input)
>> {'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
>> [101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
>> [101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
>> 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
>> 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
>> [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
>> [1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
切り捨て
一方、配列が長すぎてモデルが扱えない場合もあります。この場合、シーケンスを短く切り詰める必要があります。
truncation=Trueに設定すると、モデルが受け入れる最大の長さまでシーケンスを切り詰めることができます。
batch_sentences = [
"But what about second breakfast?",
"Don't think he knows about second breakfast, Pip.",
"What about elevensies?",
]
encoded_input = tokenizer(batch_sentences, padding=True, truncation=True)
print(encoded_input)
>> {'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
>> [101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
>> [101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
>> 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
>> 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
>> [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
>> [1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
テンソルを返す
モデルに与える実際のテンソルをTokenizerに返します。
return_tensorsパラメータに、PyTorchの場合はpt、TensorFlowの場合はtfを設定します。
batch_sentences = [
"But what about second breakfast?",
"Don't think he knows about second breakfast, Pip.",
"What about elevensies?",
]
encoded_input = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="pt")
print(encoded_input)
>> {'input_ids': tensor([[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
>> [101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
>> [101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]]),
>> 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]),
>> 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
>> [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
>> [1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]])}
batch_sentences = [
"But what about second breakfast?",
"Don't think he knows about second breakfast, Pip.",
"What about elevensies?",
]
encoded_input = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="tf")
print(encoded_input)
>> {'input_ids': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
>> array([[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
>> [101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
>> [101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
>> dtype=int32)>,
>> 'token_type_ids': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
>> array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], dtype=int32)>,
>> 'attention_mask': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
>> array([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
>> [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
>> [1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]], dtype=int32)>}
推奨オプション
以下はパディングと切り捨ての推奨オプションをまとめた表です。
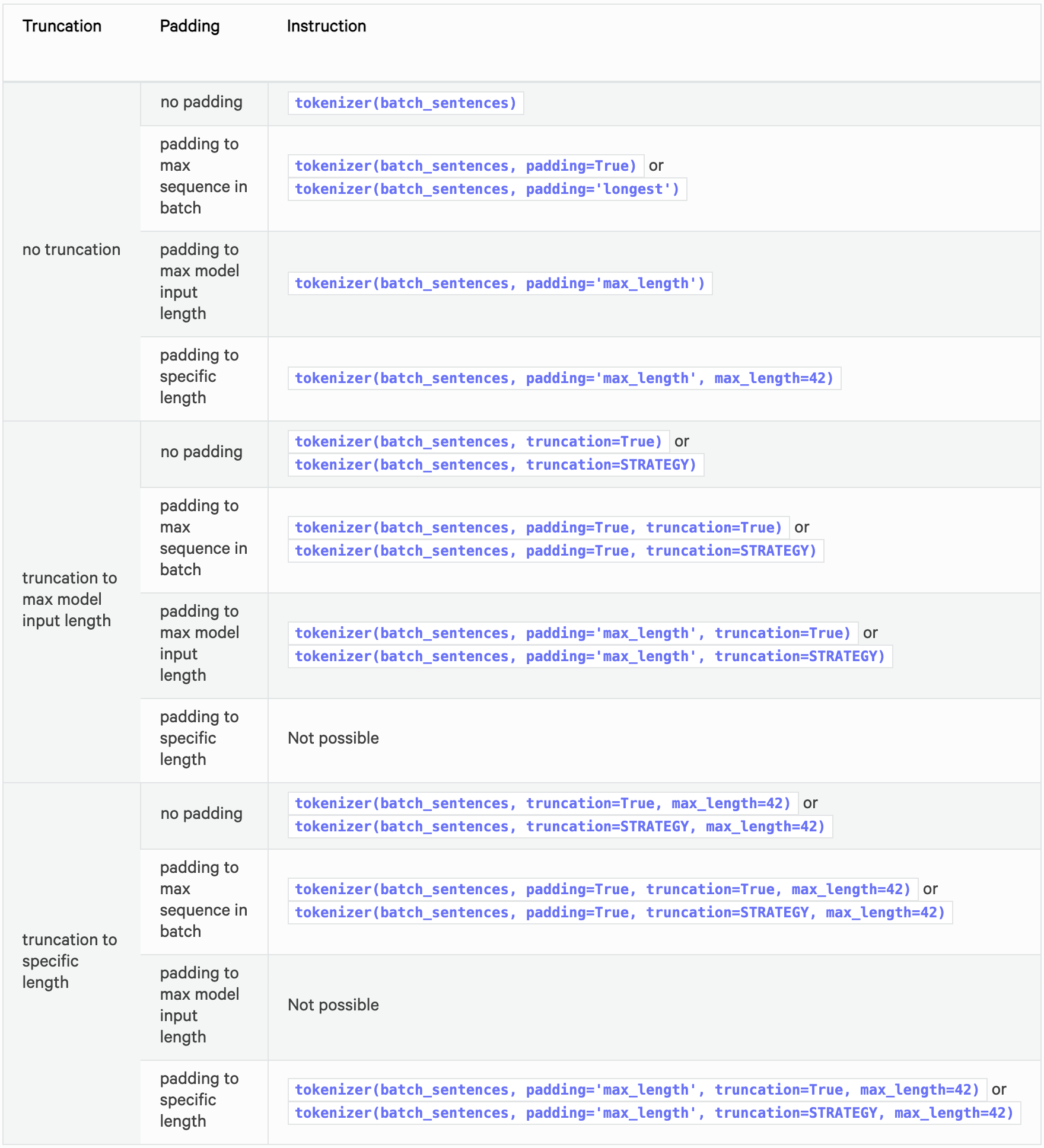
パディングと切り捨ての詳細の仕様については以下をご参照ください。
文のペア
2つの文が類似しているかどうかを分類したい場合など、モデルに文のペアを与える必要がある場合があります。
BERTでは、入力は次のように表現します。
[CLS] Sequence A [SEP] Sequence B [SEP]
2つの文を2つの引数として与えることで、モデルが期待する形式で文のペアをエンコードすることができます。
encoded_input = tokenizer("How old are you?", "I'm 6 years old")
print(encoded_input)
>> {'input_ids': [101, 1731, 1385, 1132, 1128, 136, 102, 146, 112, 182, 127, 1201, 1385, 102],
>> 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1],
>> 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
token_type_idsは、どの部分が文Aで、どの部分が文Bであるかを判別するために使います。そのため、token_type_idsは全てのモデルで必須というわけではありません。
デフォルトでは、Tokenizerのトークン化は関連するモデルが期待する入力のみを返します。return_input_idsまたはreturn_token_type_idsを使用することで、これらの特別な引数のいずれかを強制的に返す、または返さないことができます。
取得したトークンIDをデコードすると、スペシャルトークンが適切に追加されていることが分かります。
tokenizer.decode(encoded_input["input_ids"])
>> "[CLS] How old are you? [SEP] I'm 6 years old [SEP]"
処理したい文のペアのリストがある場合は、それら2つのリストをTokenizerに渡します。
batch_sentences = ["Hello I'm a single sentence",
"And another sentence",
"And the very very last one"]
batch_of_second_sentences = ["I'm a sentence that goes with the first sentence",
"And I should be encoded with the second sentence",
"And I go with the very last one"]
encoded_inputs = tokenizer(batch_sentences, batch_of_second_sentences)
print(encoded_inputs)
>> {'input_ids': [[101, 8667, 146, 112, 182, 170, 1423, 5650, 102, 146, 112, 182, 170, 5650, 1115, 2947, 1114, 1103, 1148, 5650, 102],
>> [101, 1262, 1330, 5650, 102, 1262, 146, 1431, 1129, 12544, 1114, 1103, 1248, 5650, 102],
>> [101, 1262, 1103, 1304, 1304, 1314, 1141, 102, 1262, 146, 1301, 1114, 1103, 1304, 1314, 1141, 102]],
>> 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
>> [0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
>> [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1]],
>> 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
>> [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
>> [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
モデルに与えられたものをチェックするために、input_idsのリストを1つずつデコードすることも可能です。
for ids in encoded_inputs["input_ids"]:
print(tokenizer.decode(ids))
>> [CLS] Hello I'm a single sentence [SEP] I'm a sentence that goes with the first sentence [SEP]
>> [CLS] And another sentence [SEP] And I should be encoded with the second sentence [SEP]
>> [CLS] And the very very last one [SEP] And I go with the very last one [SEP]
事前にトークン化された入力
Tokenizerに事前トークン化された入力を渡すこともできます。
事前トークン化された入力を使用したい場合は、Tokenizerに入力を渡す際にis_pretokenized=Trueを指定します。
encoded_input = tokenizer(["Hello", "I'm", "a", "single", "sentence"], is_pretokenized=True)
print(encoded_input)
>> {'input_ids': [101, 8667, 146, 112, 182, 170, 1423, 5650, 102],
>> 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0],
>> 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
Tokenizerはadd_special_tokens=Falseを指定しない限り、スペシャルトークンを追加することにご注意ください。
文のバッチを次のようにエンコードすることができます。
batch_sentences = [["Hello", "I'm", "a", "single", "sentence"],
["And", "another", "sentence"],
["And", "the", "very", "very", "last", "one"]]
encoded_inputs = tokenizer(batch_sentences, is_pretokenized=True)
次のように文のペアをエンコードすることもできます。
batch_of_second_sentences = [["I'm", "a", "sentence", "that", "goes", "with", "the", "first", "sentence"],
["And", "I", "should", "be", "encoded", "with", "the", "second", "sentence"],
["And", "I", "go", "with", "the", "very", "last", "one"]]
encoded_inputs = tokenizer(batch_sentences, batch_of_second_sentences, is_pretokenized=True)
参考















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS