

Attention とは
Attentionとは、NLPにおいて、文章中のどの単語に注目すればよいのかを表すスコアです。Attentionは Neural Machine Translation by Jointly Learning to Align and Translate という論文で初めて登場し、Attentionは論文中では「soft align」や「soft search」という言葉で表現されています。
次の英文を日本語に翻訳する場合を考えます。
I like apple.
この英文を翻訳すると次のようになります。
私はりんごが好きです。
我々人間が「apple」を「りんご」と訳すときは、「apple」という単語や、その直前の「like」に着目しています。
このように、我々人間は翻訳時に文章中の何かしらの単語に注意を向けています。この考え方をニューラルネットワークモデルに応用したのがAttentionです。
Attention の理解
Attentionの視覚的な理解を試みます。次の記事がとても分かりやすいので参考にしつつ、随時補足します。
従来の Encoder-Decoder モデル
Attentionが現れた背景にはEncoder-Decoderモデル(Seq2seq)の能力の限界があります。
Encoder-Decoderモデルとは、EncoderとDecoderという2つのRNNからなるモデルです。Encoderは入力の各要素を処理し、捉えた情報を固定次元の文脈ベクトル(context vector)にコンパイルします。入力全ての処理後にEncoderは文脈ベクトルをDecoderに送り、Decoderは文脈ベクトル、隠れ状態(hidden state)、一つ前の出力を入力として各要素を次々と出力していきます。
- Encoder: 入力単語
x c - Decoder: 文脈ベクトル
c h_i y_{i-1} y_i
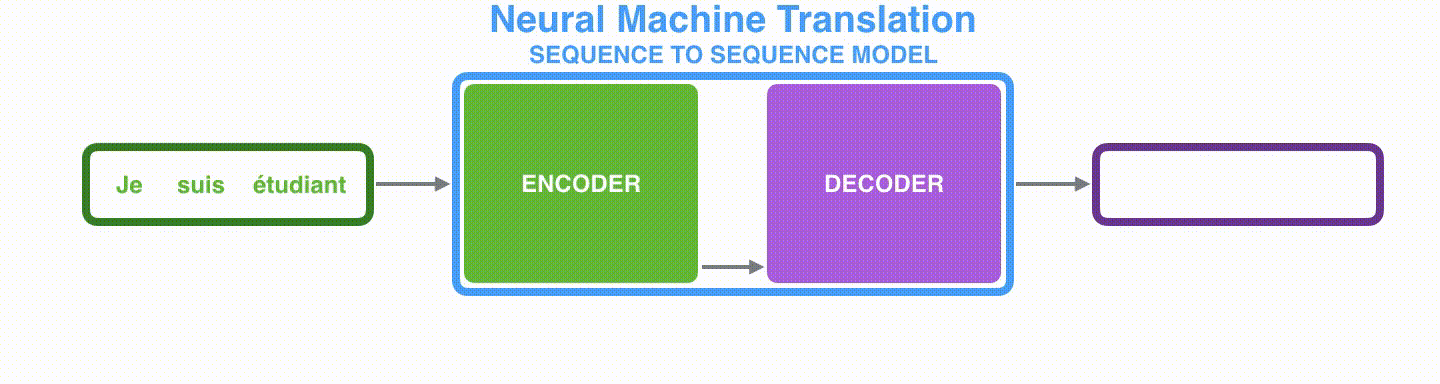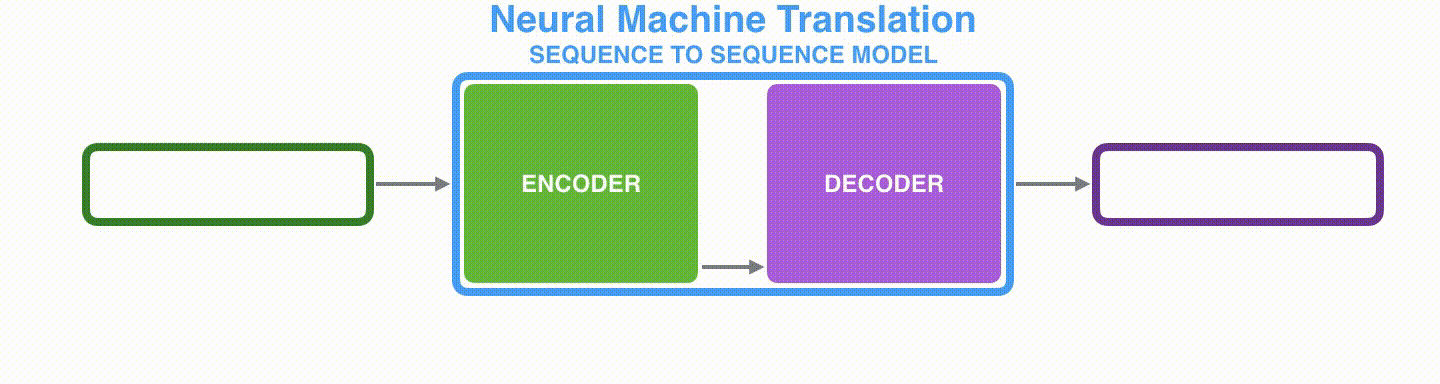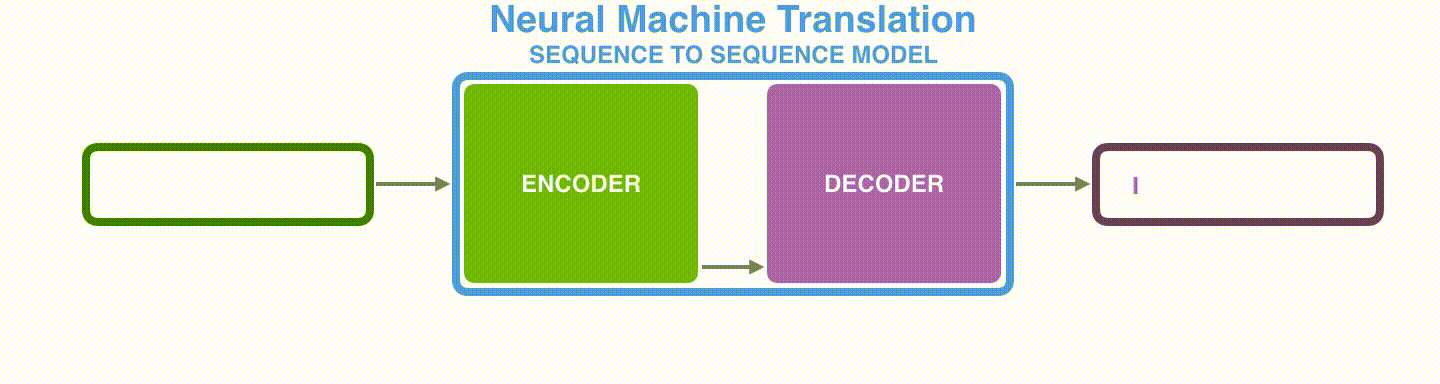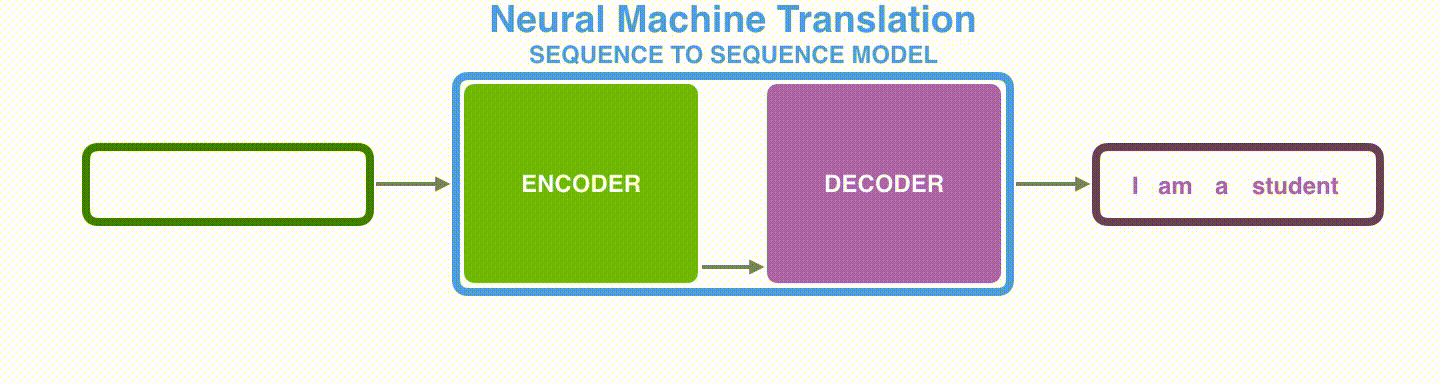
Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
文脈ベクトルの大きさはモデルの設計時に設定することができます。基本的にはRNNの隠れ層の次元(256、512、1024次元)と同じにします。下図では4次元に設定しています。

Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
RNNは各タイムステップで入力と隠れ状態(hidden state)を受け取ります。Encoderの場合は、入力として1つの単語を受け取ります。受け取った単語は単語埋め込みと呼ばれるアルゴリズムを利用して単語ベクトルに変換します。単語埋め込みモデルは独自に学習したモデル、もしくは事前学習済みモデルを使います。埋め込みベクトルの次元は200や300などが一般的です。下図では4次元のベクトルで表しています。

Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
RNNでは最初のタイムステップでhidden state #0とinput vector #1を受け取り、処理を行なってからhidden state #1とinput vector #2を出力します。
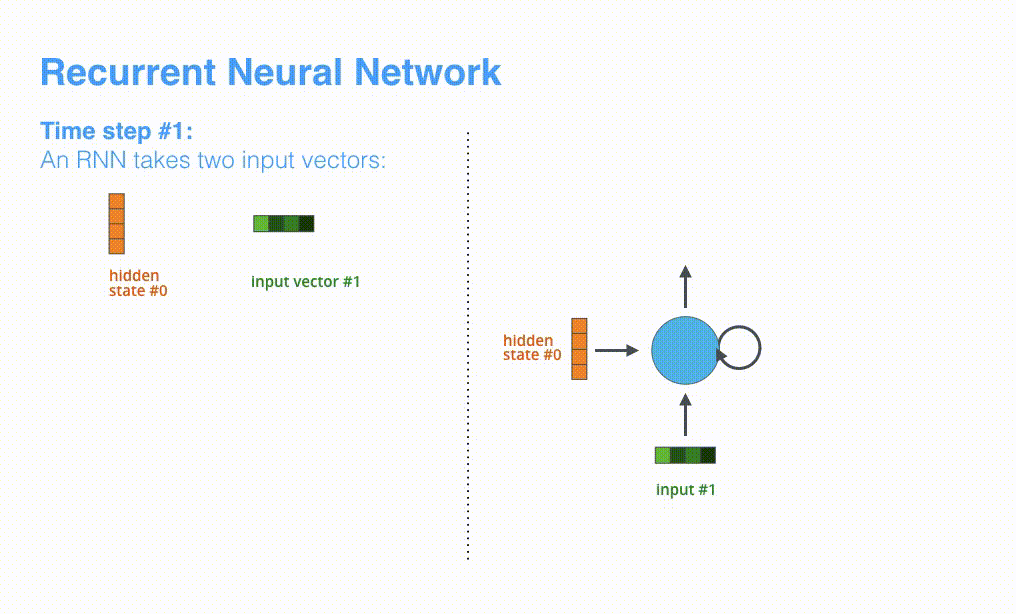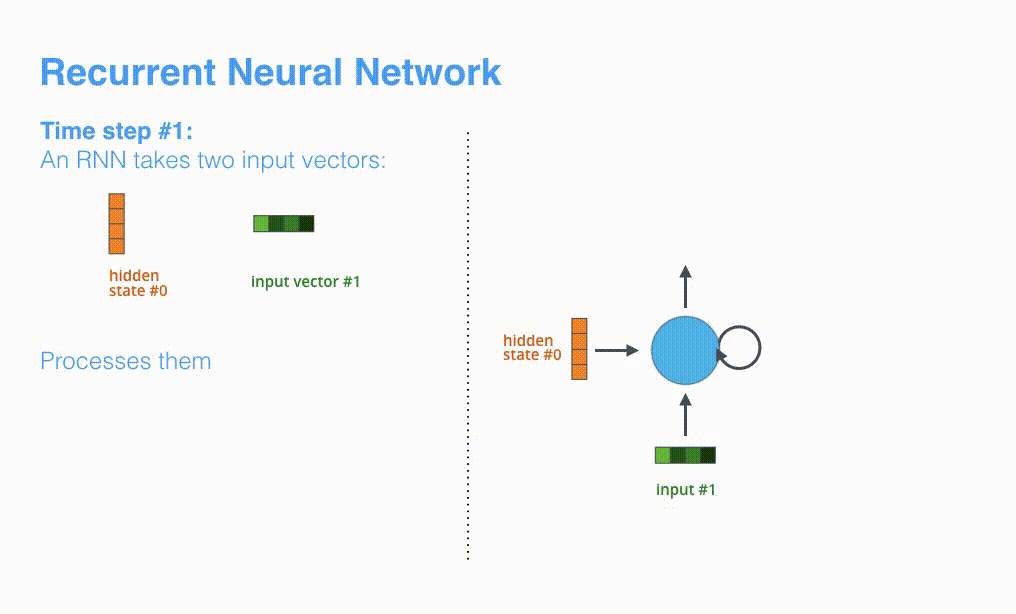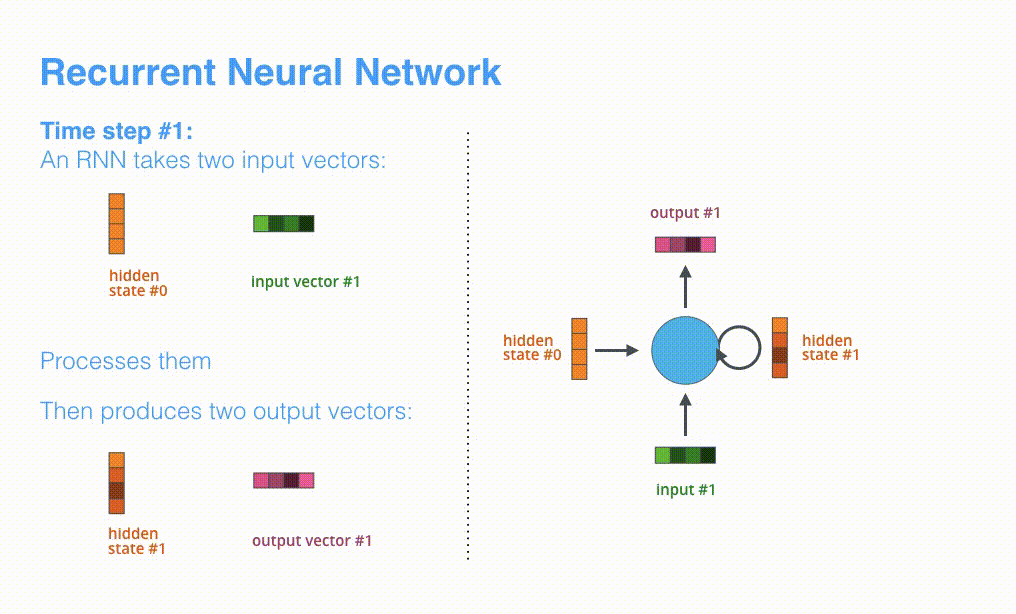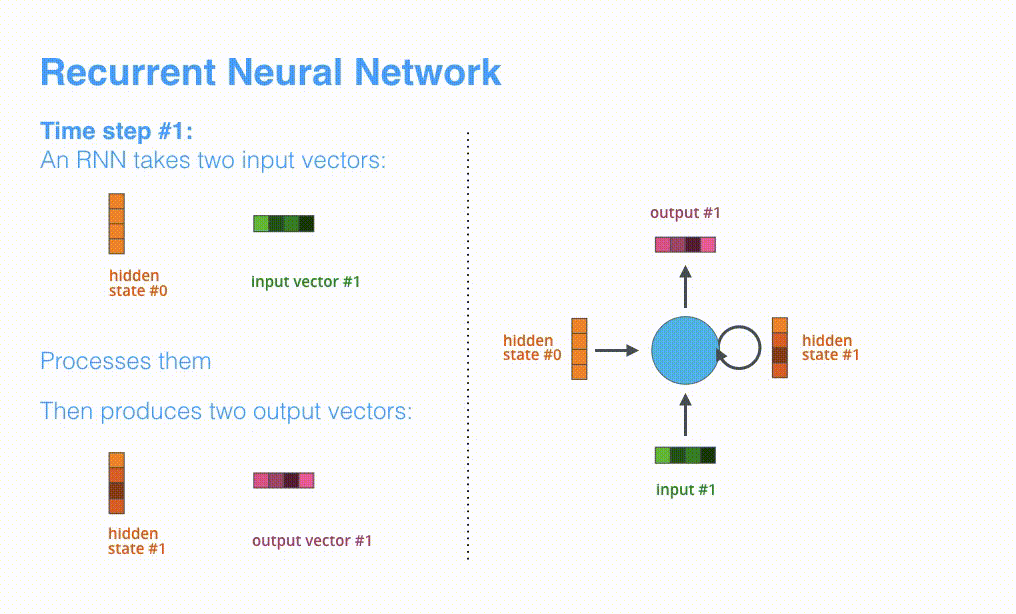
Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
次のタイムステップではinput #2とhiden state #1を受け取ります。その次のタイムステップではinput #3とhidden state #2を受け取ります。
RNNのEncoder-Decoderモデルは下図のような挙動をします。Encoderが処理した最後の隠れ状態(hidden state #3)が,文脈ベクトルとしてDecoderに渡されます。
Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
Decoderも同様に各タイムステップごとの隠れ状態を保持しており、文脈ベクトルと隠れ状態、一つ前の出力を入力として、単語を出力します。
Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
Attention 付き Encoder-Decoder モデル
Encoder-Decoderモデルでは、文脈ベクトルは固定次元です。つまり、Encoderで常に同じ長さのベクトル表現に変換されているということになります。短い文章であれば変換後のベクトル表現はしっかりと情報を保持していると考えられますが、文章が長くなると情報がベクトル表現に入りきれなくなります。そのため長い文章では精度が落ちてしまうという問題があります。
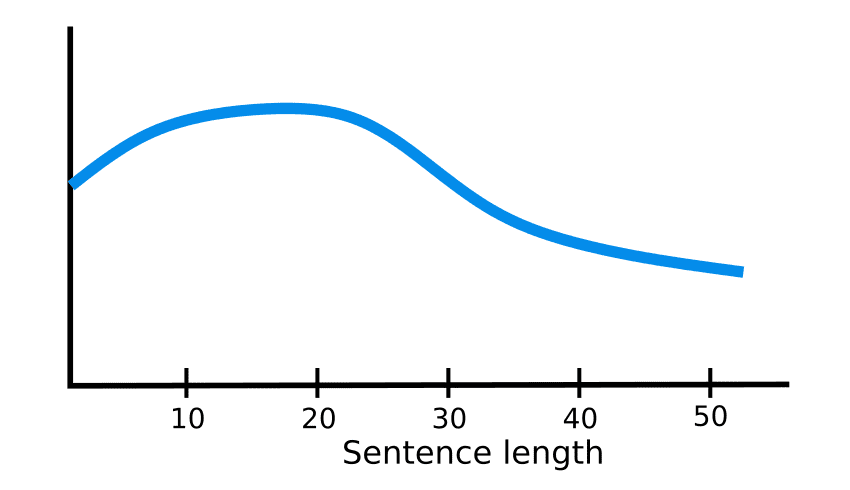
How Attention works in Deep Learning: understanding the attention mechanism in sequence models
この問題の解決策としてAttentionというアーキテクチャが生まれました。
タイムステップ7では、Attentionを利用することでDecoderは英訳を生成する前にétudiantに注目することができます。入力の情報を増幅させる仕組みにより、Attentionが加わったモデルはより優れた性能を発揮します。
Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
Attention付きのEncoder-Decoderモデル(seq2seq)は従来のモデルと比べて次の2点の違いがあります。
- Encoderはより多くの情報をDecoderに渡す
- Decoderは各タイムステップに関連する入力の要素に注目する
1つ目の違いとして、Encoderは最後の隠れ状態を渡すのではなく、全ての隠れ状態をDecoderに渡します。
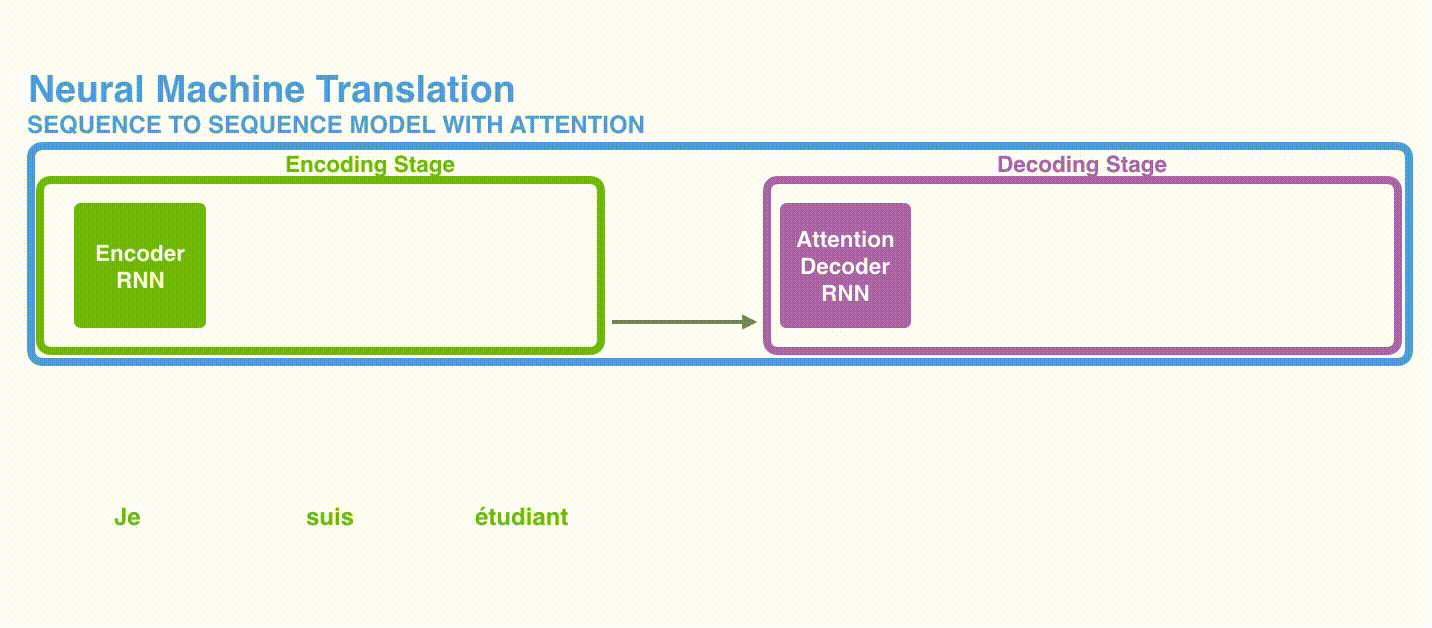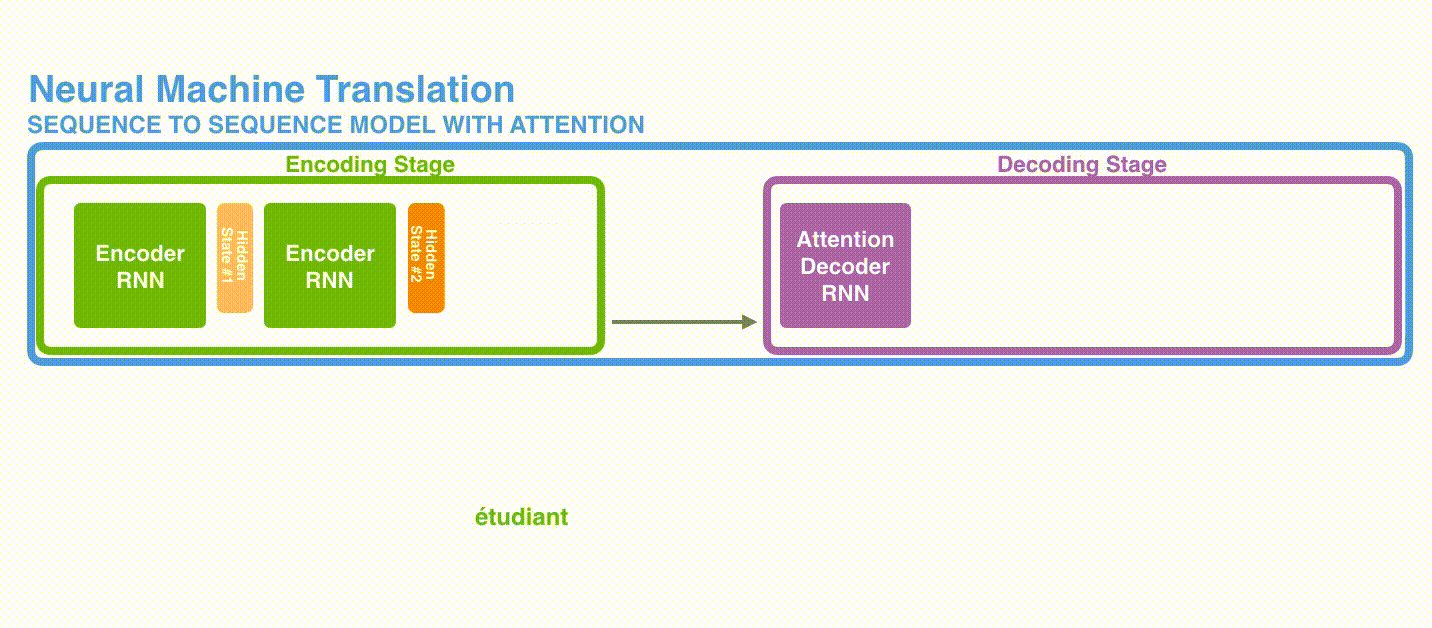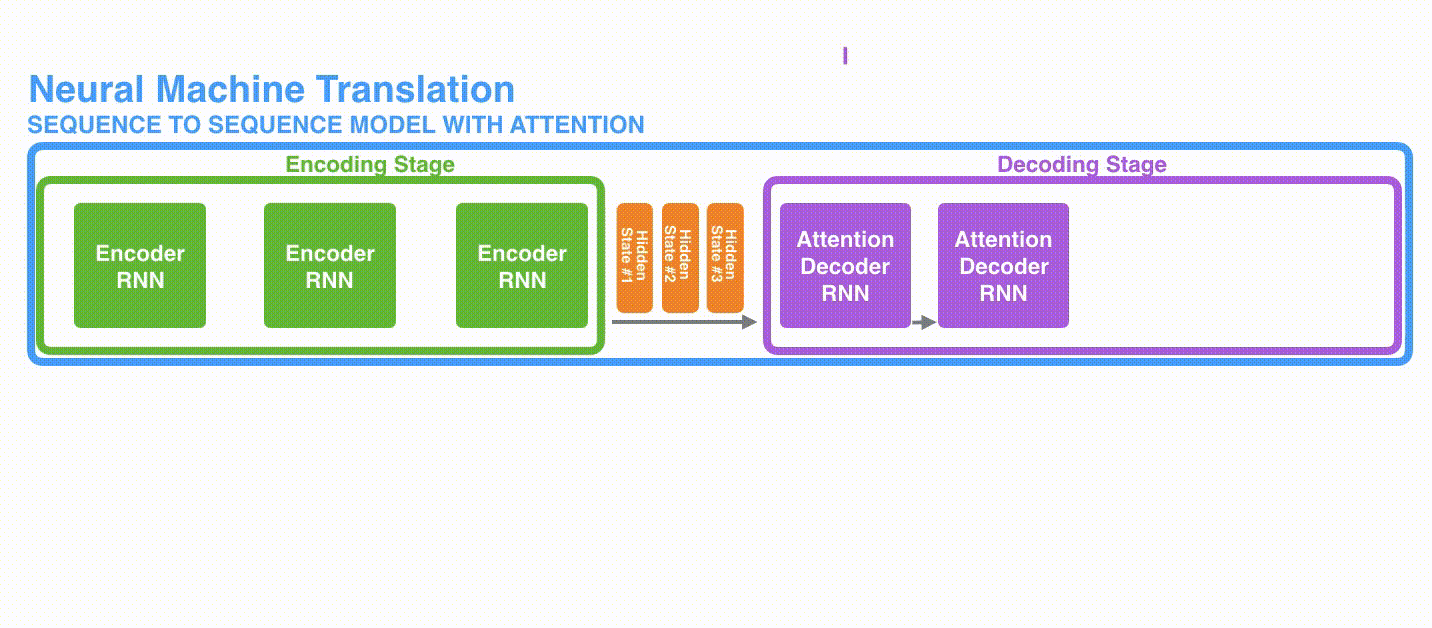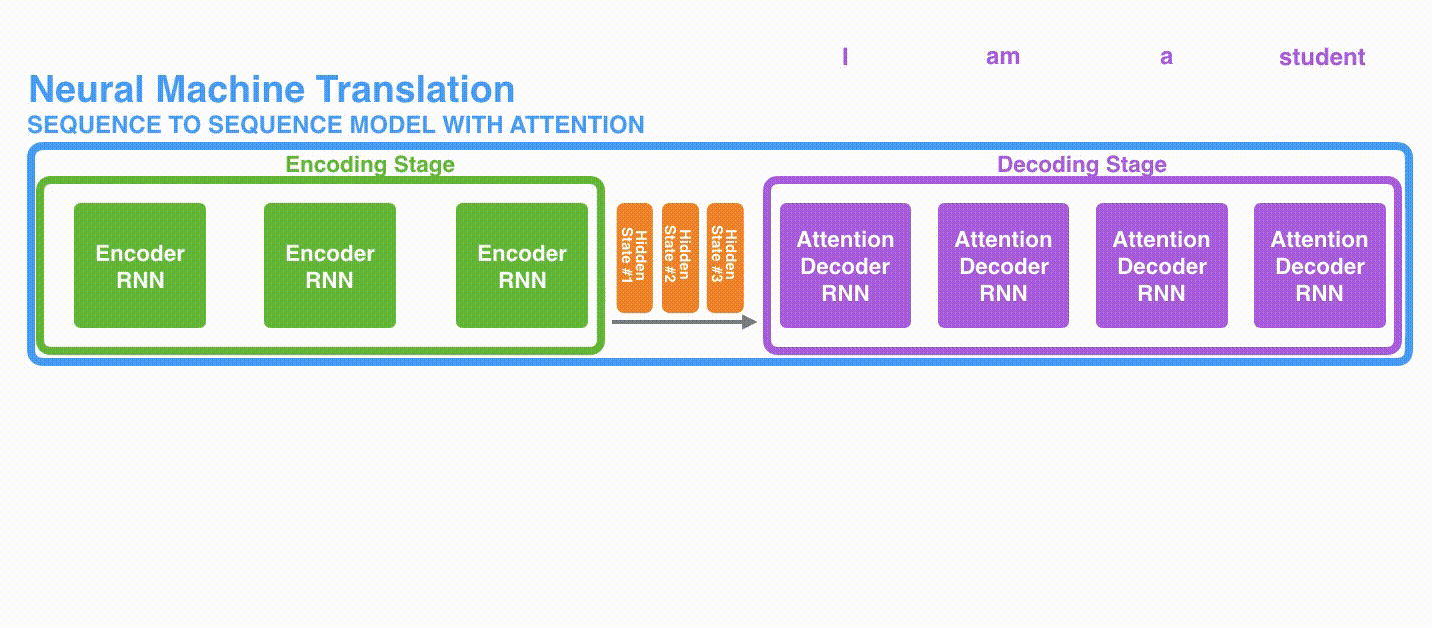
2つ目の違いとして、Attention付きのDecoderは各タイムステップにおいて、出力を生成する前に次の処理を行います。
- 受け取ったEncoderの全ての隠れ状態を見る
- それぞれの隠れ状態にスコアを与える
- 各隠れ状態にソフトマックスを通したスコアを乗算することで隠れ状態の重み付けをする(高スコアの隠れ状態を増幅させ、低スコアの隠れ状態をかき消す)

Attentionは次のように機能します。
- DecoderのRNNは
<END>トークンと隠れ状態の初期値を受け取る - RNNは新しい隠れ状態(h4)を生成する
- Attention: Encoderの全ての隠れ状態とDecoderが生成した隠れ状態(h4)を利用し、各タイムステップにおける文脈ベクトル(C4)を生成する
- Decoderの隠れ状態(h4)と文脈ベクトル(C4)を結合する
- 結合されたベクトルを全結合層に通す
- 全結合層の出力が各タイムステップにおいて出力される
- 以上を各タイムステップごとに繰り返す
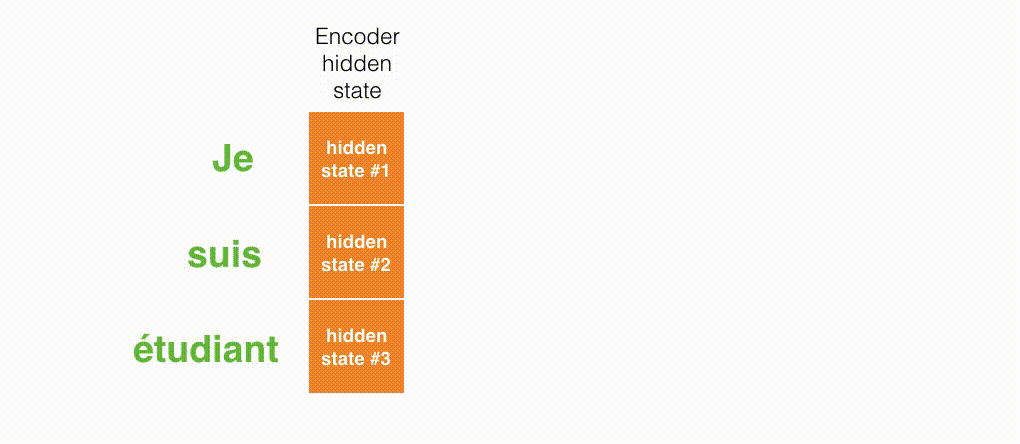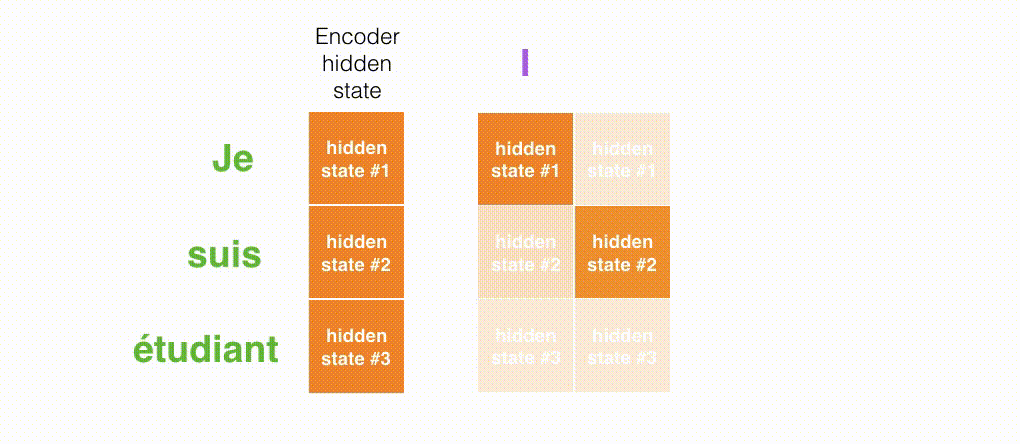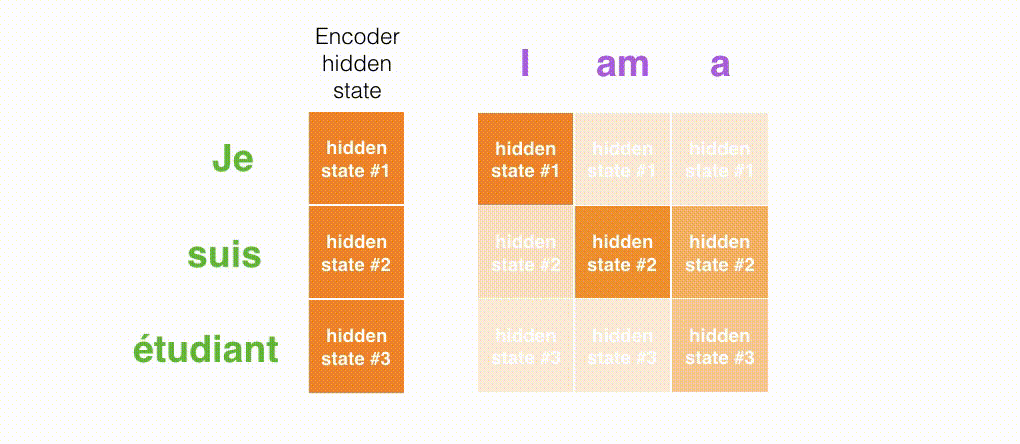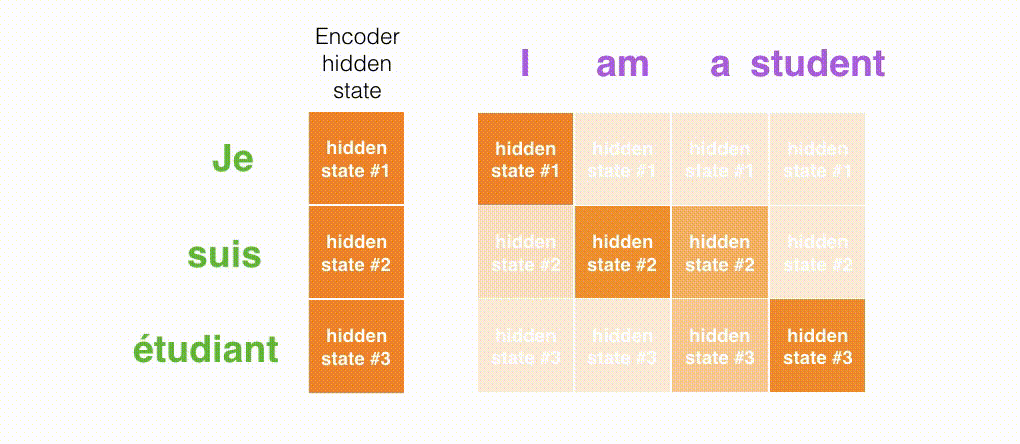
Decoderの各タイムステップで入力のどの部分に注目しているかの様子は次のようになります。
下図は、Neural Machine Translation by Jointly Learning to Align and Translate という論文で示された図です。色が白いほどAttentionが着目しているということになります。例えば、「agreement」という単語を生成するときに入力の「accord」に注目していることが分かります。

参考

















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS