

Transformer とは
Transformerとは、2017年にGoogleが発表した Attention Is All You Need というNLPに関する論文の中で初めて登場した深層学習モデルです。TransformerはそれまでNLPの世界で主流であったRNNを用いたEncoder-Decoderモデルとは異なり、Attention のみを用いたEncoder-Decoderモデルです。
Transformerは現在の最新NLPモデルで使われている重要基礎モデルです。また、最近では画像認識の領域にもTransformerが使われ始めています。
Transformer の特徴
Transformerは次の特徴があります。
- RNNを使わず Attention 層のみで構築
- RNNを併用する場合ではできなかった並列計算を実現し、計算が高速化
- Positional Encoding 層の採用
- 入力する単語データに文全体における単語の位置情報を埋め込むことで文脈情報を保持することが可能
- Attention層における Query-Key-Value モデルの採用
- 単語同士の照応関係をより正確に反映できるようになり、精度が改善
Transformer の開発の歴史
Transformerは歴史的に次のモデル開発の流れで誕生しました。
- RNN
- Seq2seq
- Attention付きSeq2seq
- Transformer
RNN
言語モデルでは、文脈を考慮した処理が必要になります。例えば次のような文章があるとします。
Bob gets an apple. He eats it.
ここで、「He」が誰なのか、「it」が何なのかは文脈を理解していないと分かりません。
そこで、RNNなどに代表される文章全体の依存関係情報を保持できる再帰モデルが誕生します。入力データを固定長ベクトルに変形するときに、以前の単語の情報も加味して固定長ベクトルに変形されるというアイデアになります。RNNでは、同じ関数を再帰的に利用して逐次的に出力し、次の入力に用いられるデータの一部に前の出力が含まれます。
RNNは文脈を反映することができるようになりましたが、RNNでは逐次計算が行われ、計算の並列化することができないため、計算の高速化が難しいという問題を残します。
Seq2seq
機械翻訳など異なる時系列データを利用するためにSeq2seqモデル(Encoder‐DecoderのRNN)が考案されます。
Seq2seqではEncoder-Decoderにおいて入力データはひとつの固定長ベクトルに変換され、RNNなどと同様の形で利用されています。このSeq2seqは異なる時系列データの変換という点では大きな成果を上げた一方、次の問題点も明らかになります。
- 固定長ベクトルに圧縮していることで長文だと情報が入りきらない
- 単語や文章同士の照応関係を利用することができない
照応関係を利用することは、翻訳タスクなど異なる時系列データを扱う場合では特に重要になります。例えば漠然と「water」が何を意味するかを探すより、「water」と「eau (water in French)」の照応関係をふまえた方がより正確な翻訳が可能になることを意味しています。
Attention 付き Seq2seq
Seq2seqの課題を解決したのが、Attention付きSeq2seqです。Attentionは、それまでEncoder部分から作られる固定長ベクトルが最後の部分しか利用されていなかった点に着目し、各単語が入力される際に出力される固定長ベクトルを全て利用することで次のことを可能にしました。
- 単語の数と同じ数だけの固定長文脈ベクトルを獲得することができる(文章の長さに応じた情報量を獲得することができる)
- Attentionにより各単語間の照応関係を獲得することができる
Transformer
Attentionを利用することでより精度が向上しましたが、以前としてRNNを併用することで生じている、並列処理できず計算の高速化が困難であるという問題を抱えていました。
そこで、RNNを使わずに完全にAttention層のみを用いるTransformerが誕生しました。TransformerはRNNやAttention付きSeq2seqなどが抱えていた並列化ができないという問題や、精度の高い依存関係モデルを構築できないという問題を解決することに成功しました。
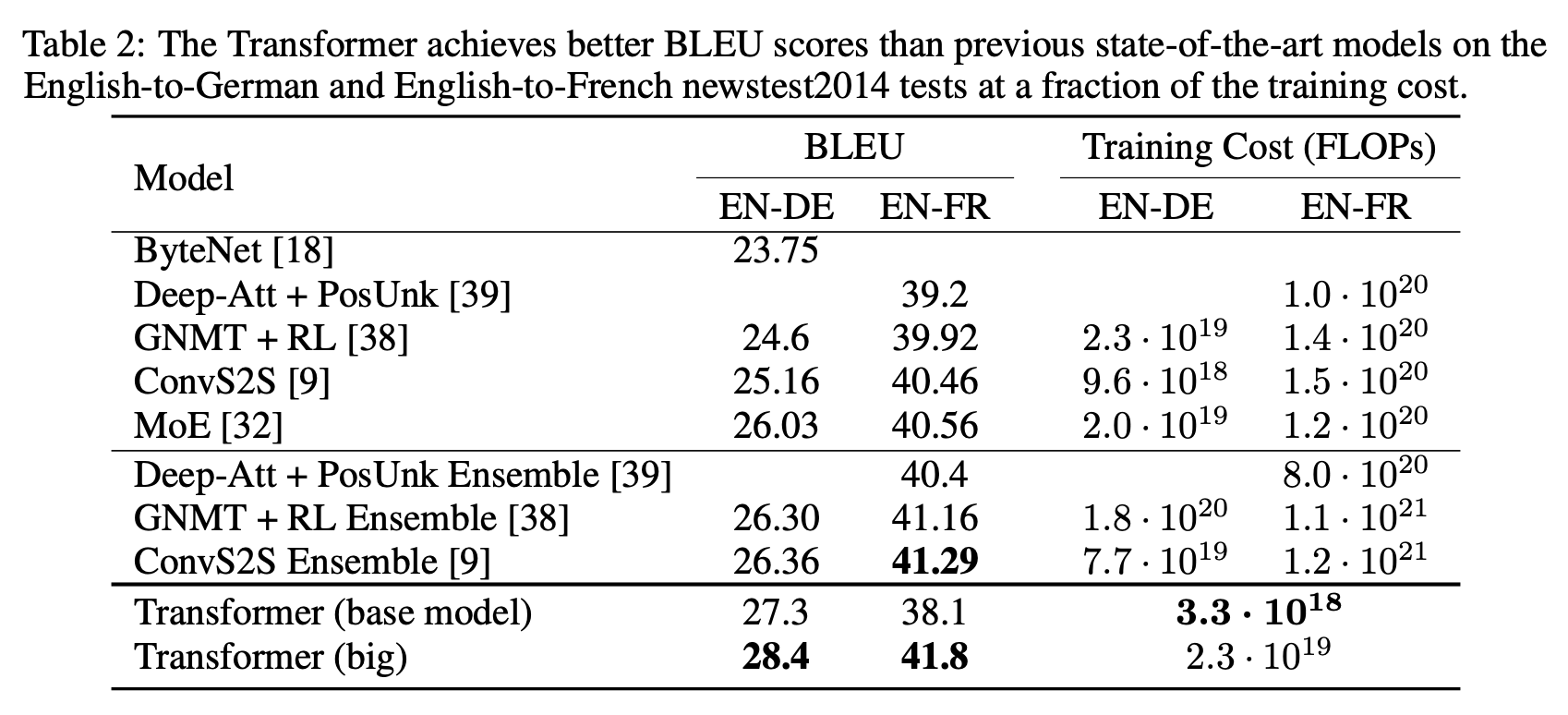
TransformerはWMT 2014の英独(EN-DE)、英仏(EN-FR)翻訳タスクで、以下を達成しています。
- 当時の最高BLEUスコアを確立
- かつ、トレーニングコストを競合モデルの数分の一に抑制
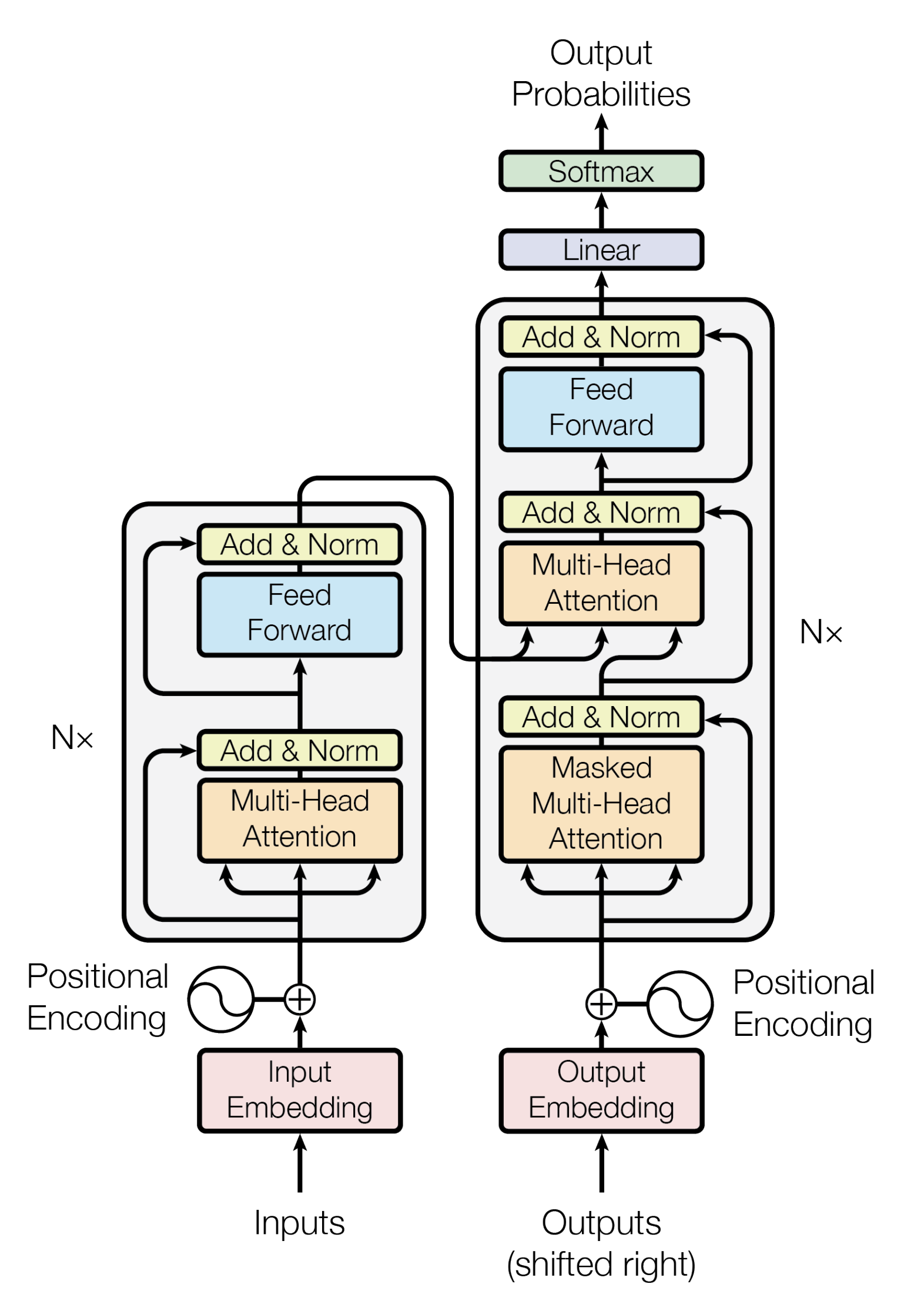
Transformer のアーキテクチャ
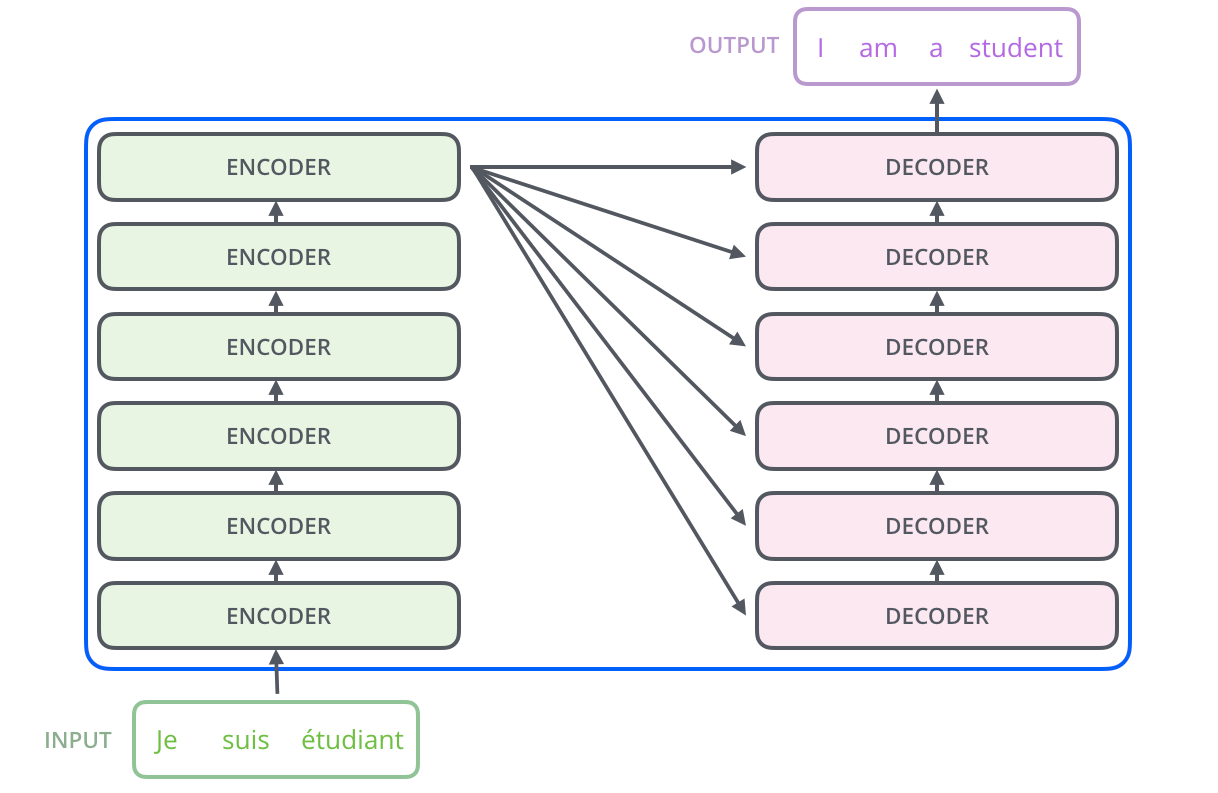
以下は翻訳タスク時のTransformerのアーキテクチャです。
TransformerはEncoder-Decoderモデルをベースとしています。
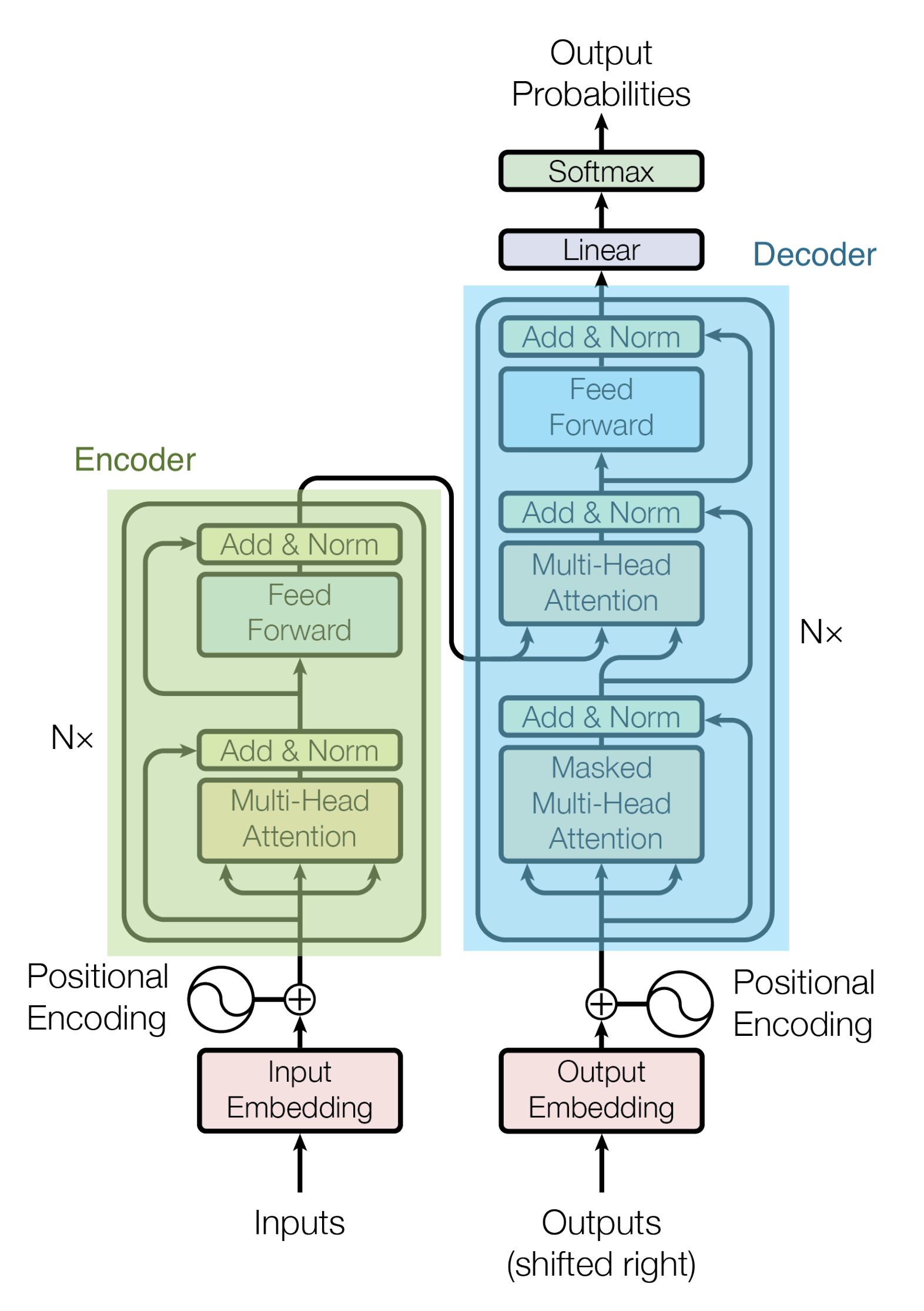
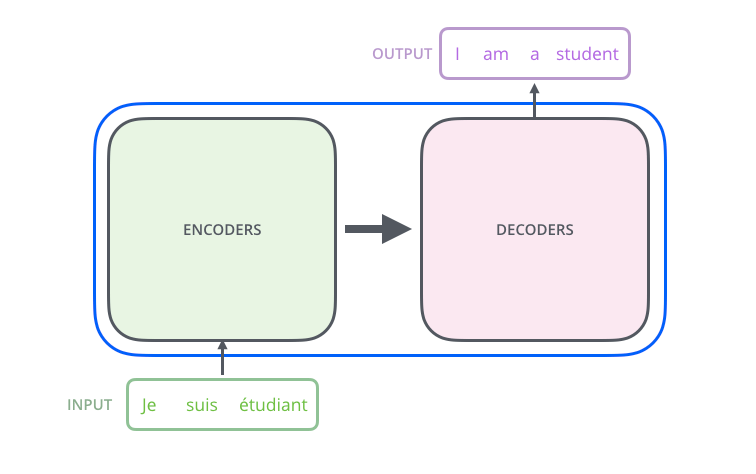
Encoderは、Encoderの積み重ねで構成されます。論文中では6つのEncoderが積み重ねられています。(他の数字を実験的に試すことも可能です。)Decoderにおいても、6つのDecoderの積み重ねで構成されます。
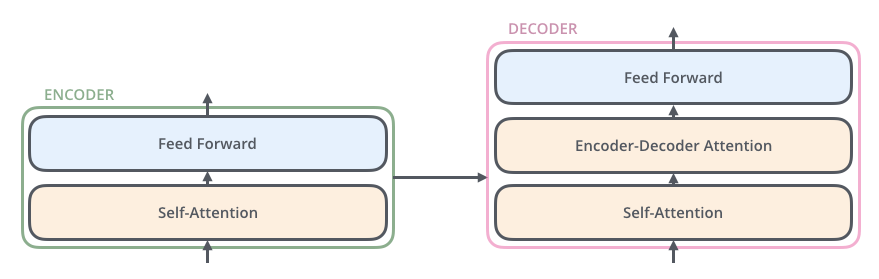
EncoderとDecoderの中身はMulti-Head AttentionとFeed Forward(全結合層)で構成されています。
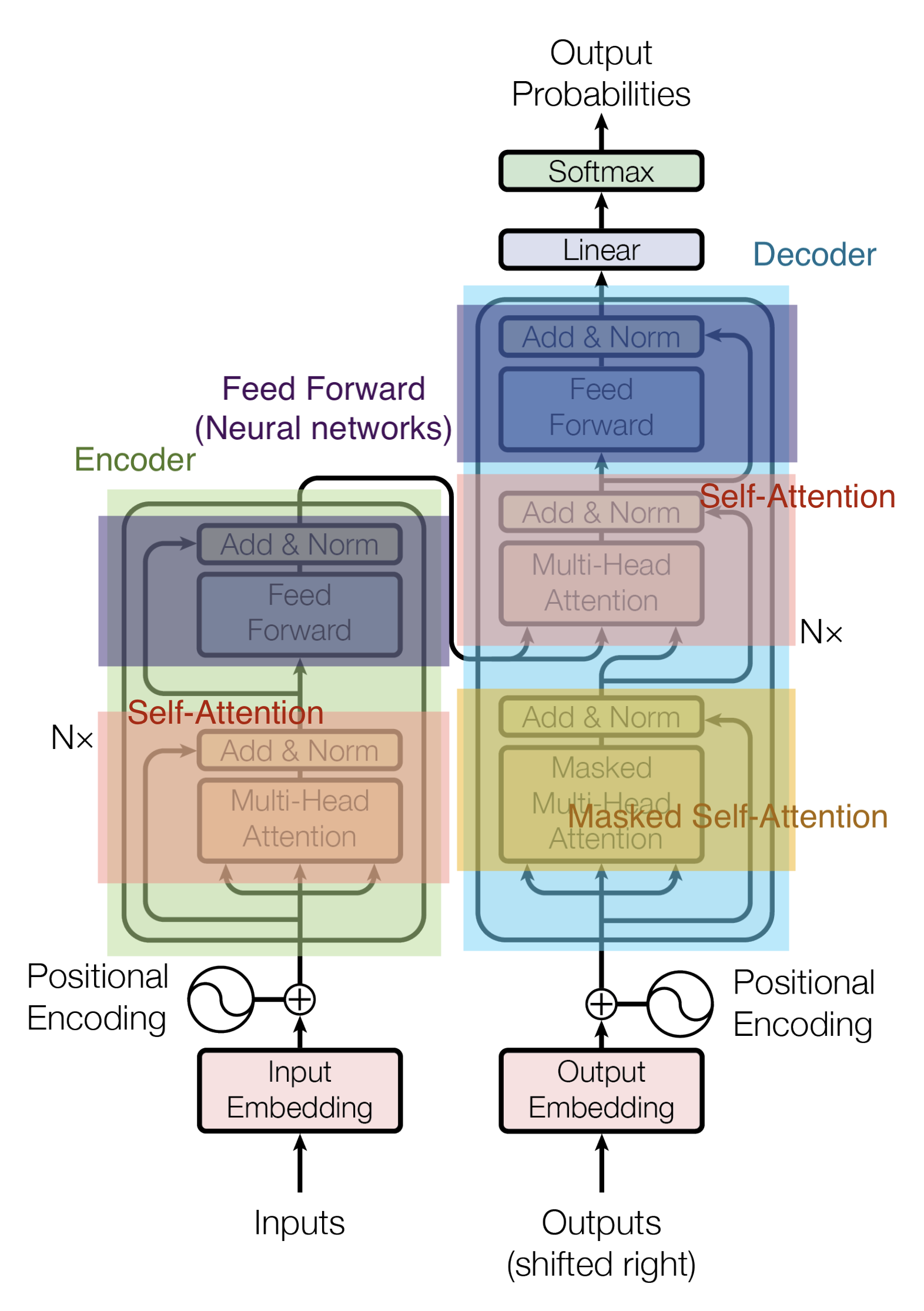
Encoderの入力は、まずSelf-Attentionを通過し、その後にFeed Forward層を通過します。
DecoderはSelf-AttentionとFeed Forward層の両方を含みますが、その間にはAttentionがあり、入力系列のどこに注目するべきかのサポートをします。(下図のEncoder-Decoder AttentionはSeq2seqモデルにおけるAttentionと同じ役割を果たします。)
ここで、各入力単語は、サイズが512の埋め込みベクトルのされてからEncoderやDecoderに渡されます。以下では、埋め込みベクトルを単純な4つの箱で表現します。

単語を埋め込み化する処理はEncoderの最下段の前で行われます。全てのEncoderは共通して、それぞれサイズが512であるベクトルのリストを受け取ります。このリストのサイズはハイパーパラメータとして設定可能であり、基本的にはトレーニングデータセットの中でもっとも長い文の長さになります。
それぞれの単語埋め込みベクトルはEncoderを通過します。
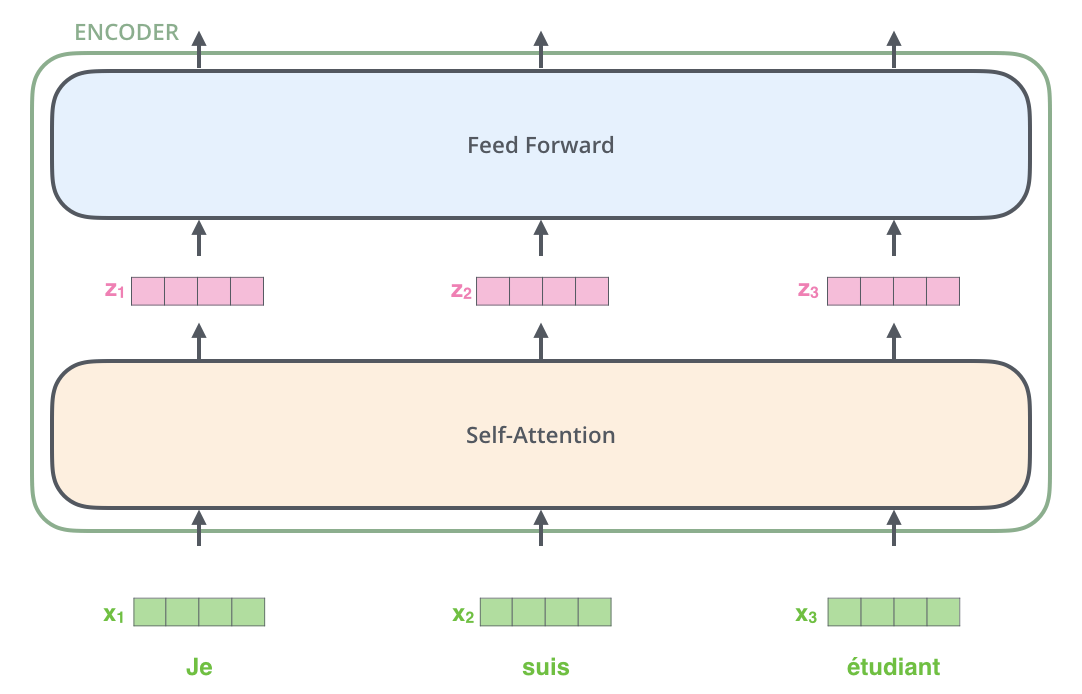
ここで、Transformerの重要な特性の1つとして、各位置にある単語はEncoder内のそれぞれのパスを通って流れます。Self-Attention層では、これらのパス間に依存性がありますが、Feed Forward層にはそのような依存関係がありません。そのため、Feed Forward層を流れる間に様々なパスを並列に実行することができます。
Encoder
Encoderは入力として単語の埋め込みベクトルのリストを受け取ります。EncoderはベクトルのリストをSelf-Attention層に渡し、次にFeed Forward層に渡し、そして次のEncoderに出力を送ります。
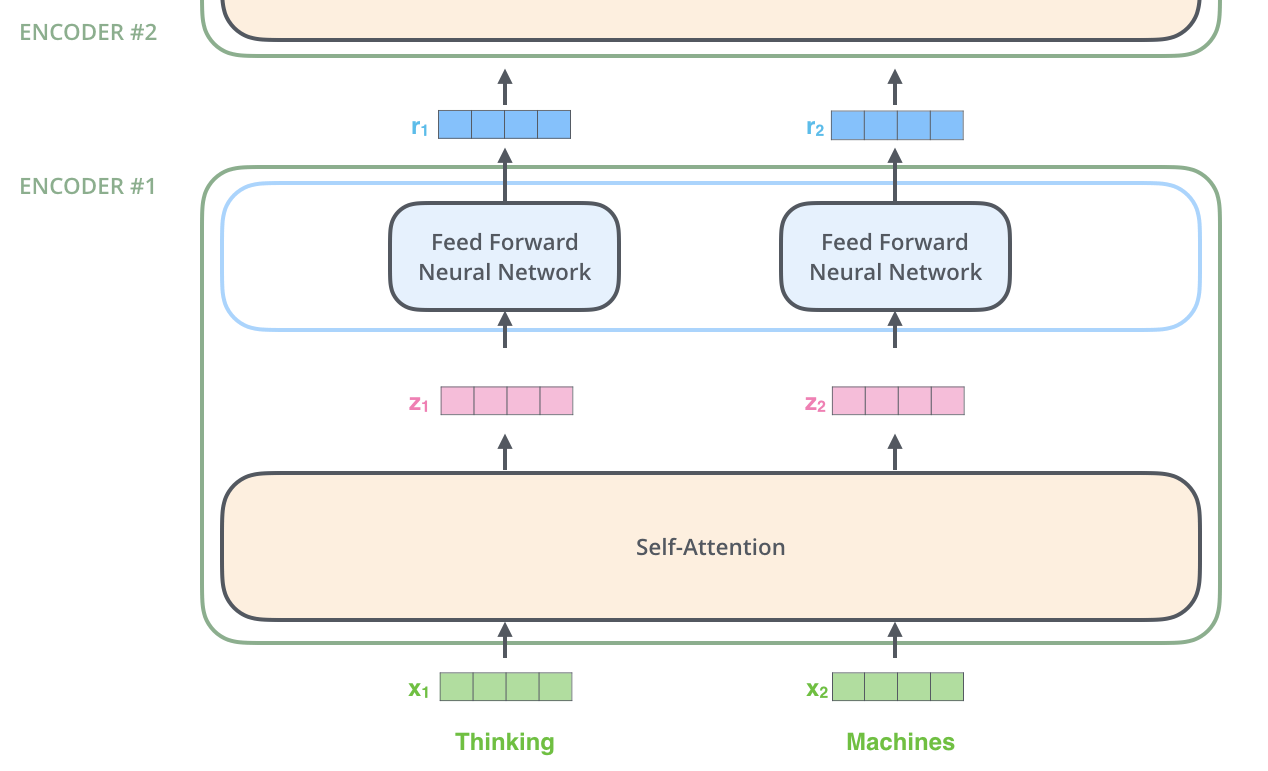
Self-Attention
Self-Attention層はSeq2seqで利用されていたAttention層(異なるデータ間の照応関係を獲得する)とは異なり、入力データ内の単語同士の照応関係の情報を獲得します。
| 照応関係 | Attention | |
|---|---|---|
| 従来の Attention | I am a student <=> Je suis un étudiant | 「I」は、特に「Je」や「étudiant」との照応関係を獲得 |
| Self-Attention | I am a student <=> I am a student | 「I」は、特に「I」や「have」との照応関係を獲得 |
例えば、次の入力文を翻訳したいとします。
The animal didn’t cross the street because it was too tired
上記の文章の「it」は何を指しているものを理解することは、人間にとっては簡単でも機械にとっては難しいです。
Self-Attentionでは、モデルが「it」という単語を処理しているときに「it」を「animal」と関連付けることができます。
例えば、Encoder#5(1番上のEncoder)では、「it」という言葉をエンコードしています。Attentionの一部は「animal」にもっとも注目しており、その表現の一部を「it」のエンコードに組み込んでいます。

このように、Self-Attentionを行うことで同一文章内の類似度が獲得され、特に多義語や代名詞などが指しているものを正しく理解することができるようになります。
また、Self-Attentionでは計算量が小さくなります。以下は論文で使われた表です。

Self-Attentionは次の流れで実装されます。
- Queryベクトル、Keyベクトル、Valueベクトルを作成
- 入力の単語埋め込みベクトルのスコアを計算
- スコアをKeyベクトルの次元の平方根で除算
- Softmaxスコアを計算
- 各ValueベクトルにSoftmaxスコアを乗算
- 重み付けされたValueベクトルを加算
Self-Attentionを実装する最初のステップでは、Encoderの各入力ベクトル(各単語の埋め込み)から各単語について次の3つのベクトルを作成します。
- Queryベクトル
- Keyベクトル
- Valueベクトル
これらのベクトルは、埋め込みベクトル行列
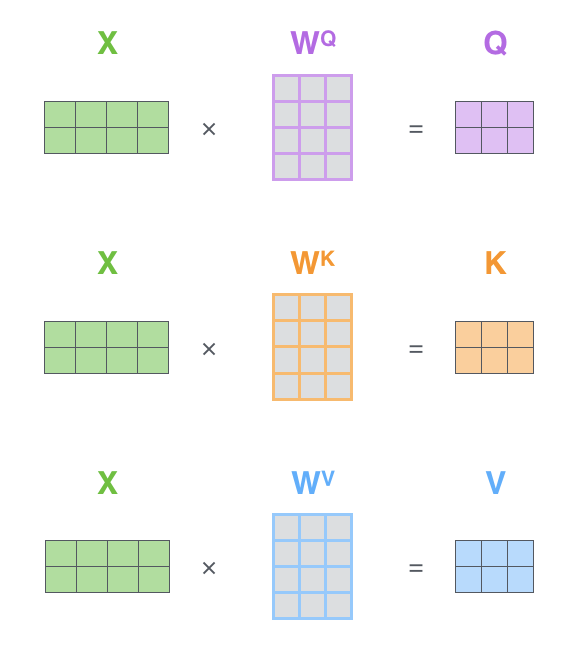
これらの新しいベクトルは、埋め込みベクトルよりも次元が小さいです。埋め込みベクトルとEncoderの入出力ベクトルの次元は512ですが、新しく作られたベクトルの次元は64です。これはMulti-Head Attentionの計算を一定にするためのアーキテクチャです。
下図では新しいベクトルの次元は3になっています。
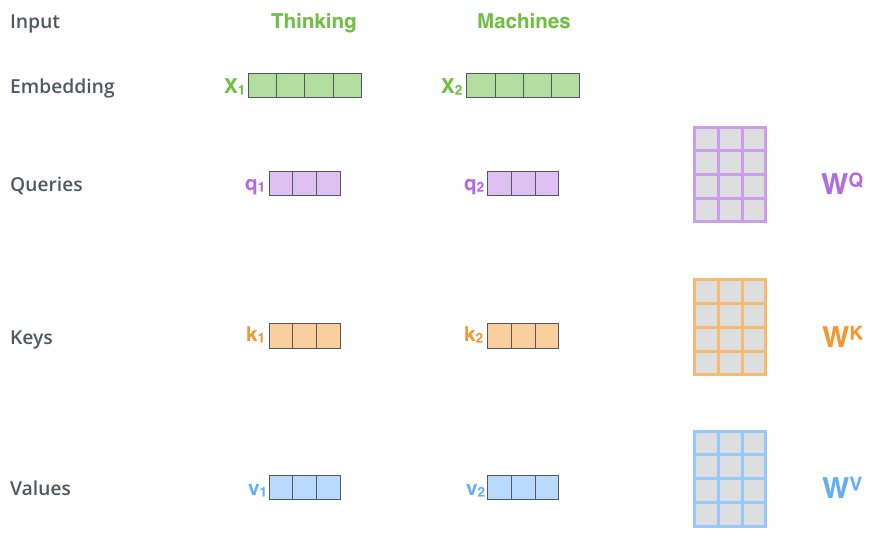
Self-Attentionを実装する第2のステップはスコアを計算することです。今回の例では、最初の単語「Thinking」のSelf-Attentionを計算するとします。この単語に対して入力文の各単語をスコア化する必要があります。スコアはある位置にある単語をエンコードする際に、入力文の他の部分にどのくらいの焦点を当てるかを決定します。
スコアはQueryベクトルと、注目している単語のKeyベクトルとの内積を取ることで計算されます。つまり,位置1の単語のSelf-Attentionを処理している場合、最初のスコアは
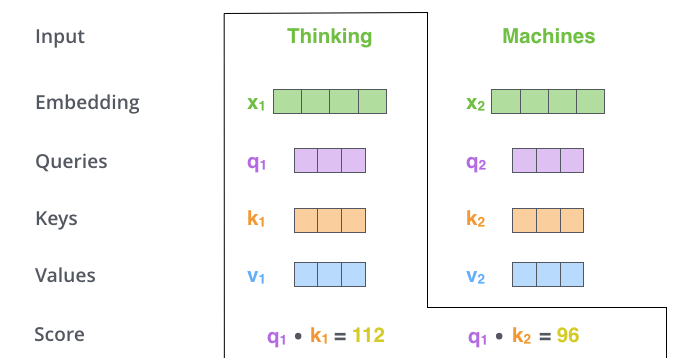
第3および第4のステップでは、スコアを8で割ります。8という数字は論文で使用したKeyベクトルの次元の平方根に由来します。この処理によって、より安定した勾配を保持することができます。他の値を指定することもできますが、Keyベクトルの次元の平方根がデフォルトとなります。そして結果をSoftmaxに渡します。Softmaxは全てを正の値にして、足して1になるようにスコアを正規化します。
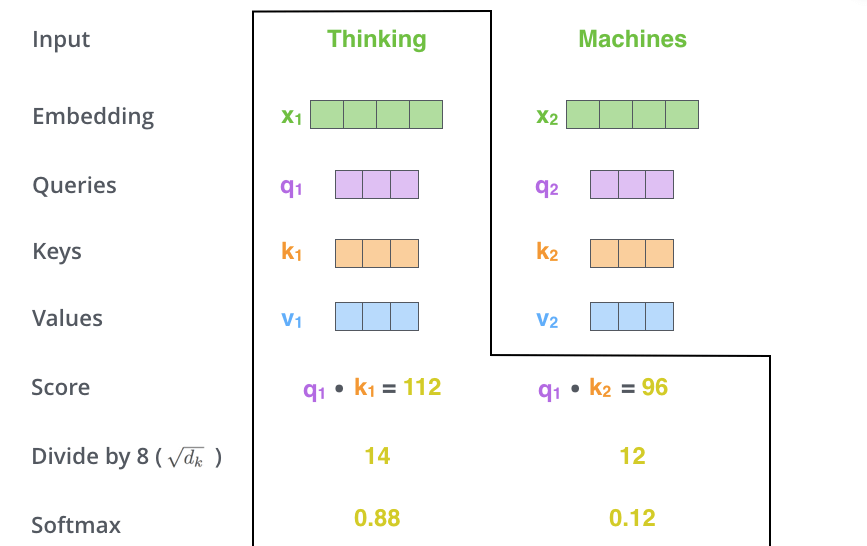
このSoftmaxのスコアは、各単語がこの位置でどれだけ表現されるかを決定します。大抵は現在処理している位置にある単語がもっとも高いSoftmaxのスコアを持つことになりますが、現在の単語に関連する別の単語に注目することが有用な場合もあります。
5番目のステップでは、各ValueベクトルにSoftmaxスコアを掛け合わせます。この処理により、注目したい単語の値はそのまま残り、無関係な単語はかき消されます。
最後のステップでは、重み付けされたValueベクトルを足し合わせます。この処理により、現在処理している位置(下の例では最初の単語について)のSelf-Attention層の出力が生成されます。
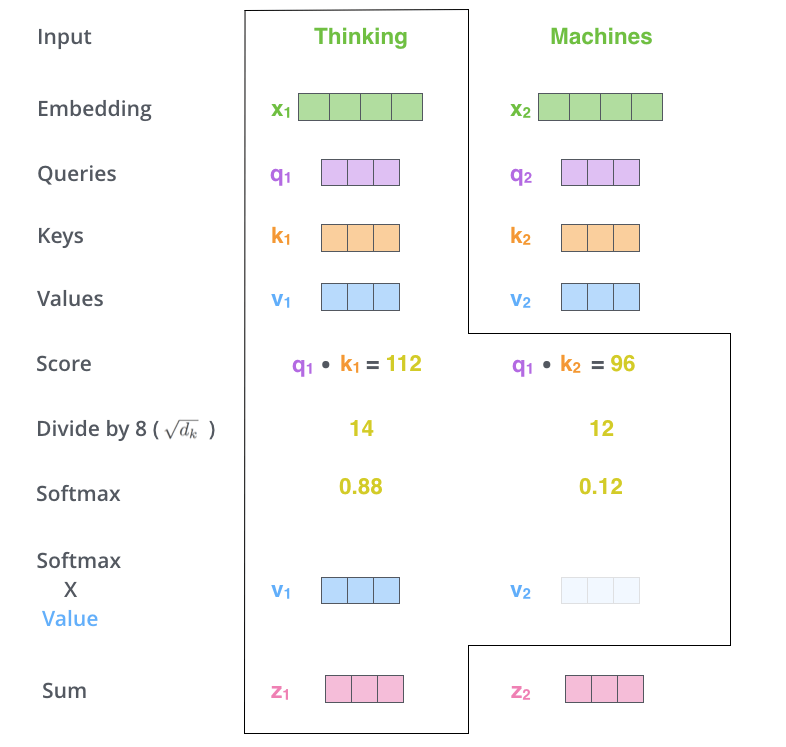
これらの結果として得られるベクトル
Multi-Head Attention
論文ではMulti-Head Attentionと呼ばれるメカニズムを追加することで、Self-Attention層をさらに洗練させています。Multi-Head AttentionはTransformerの仕組みでもっとも重要な部分です。このメカニズムによって従来モデルの「長期記憶ができない」、「並列化できない」という二つの問題が解決されます。
Multi-Head Attentionは、モデルの異なる位置に注目する能力を拡張させます。多くの場合は実際処理を行なっている単語自体に支配されますが、上の例において、
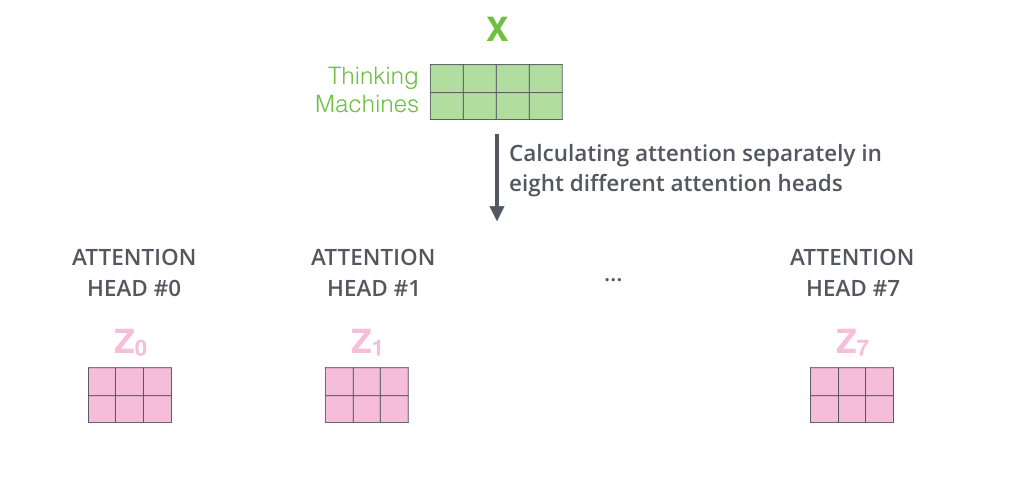
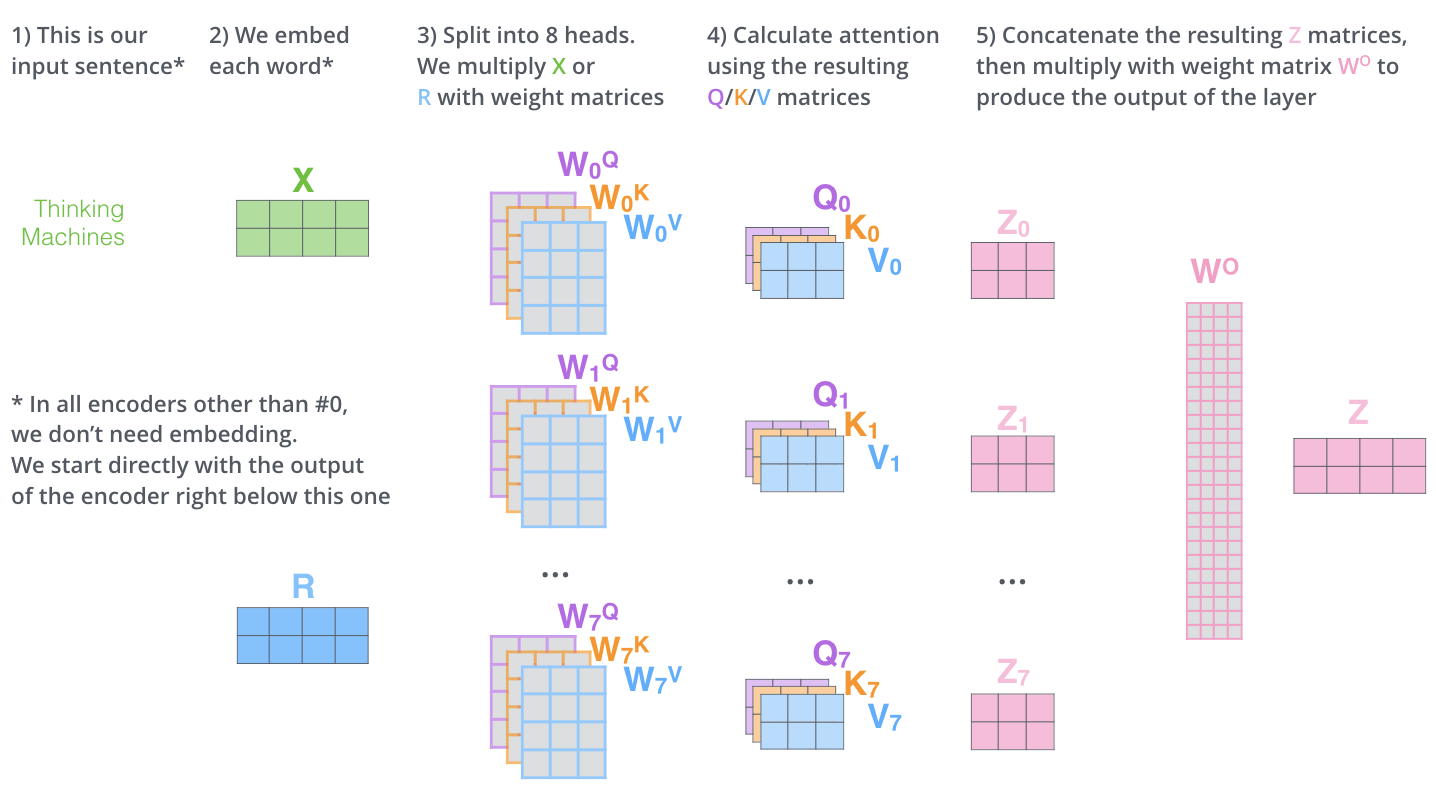
また、Multi-Head Attentionでは、別々のQuery/Key/Value重み行列を維持し、結果として異なるQuery/Key/Value行列を生成します。Transformerは8つのAttentionを使用するので、各EncoderとDecoderに対して8つのQuery/Key/Valueセットが必要になります。
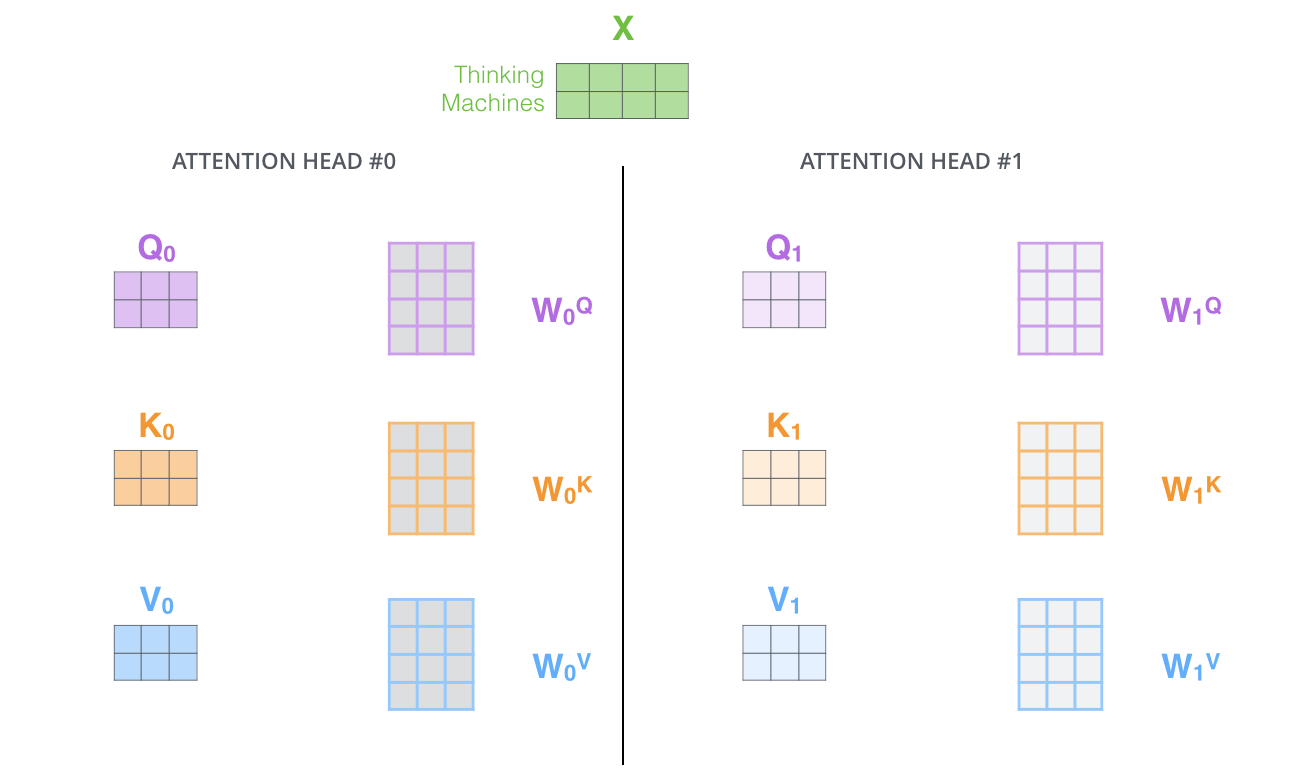
Self-Attentionの計算を異なる重み行列を用いて8回行うと、8つの異なる
Feed Forward層は8つの行列ではなく1つの行列(各単語のベクトル)を期待しています。そのため、行列を連結し、重み行列
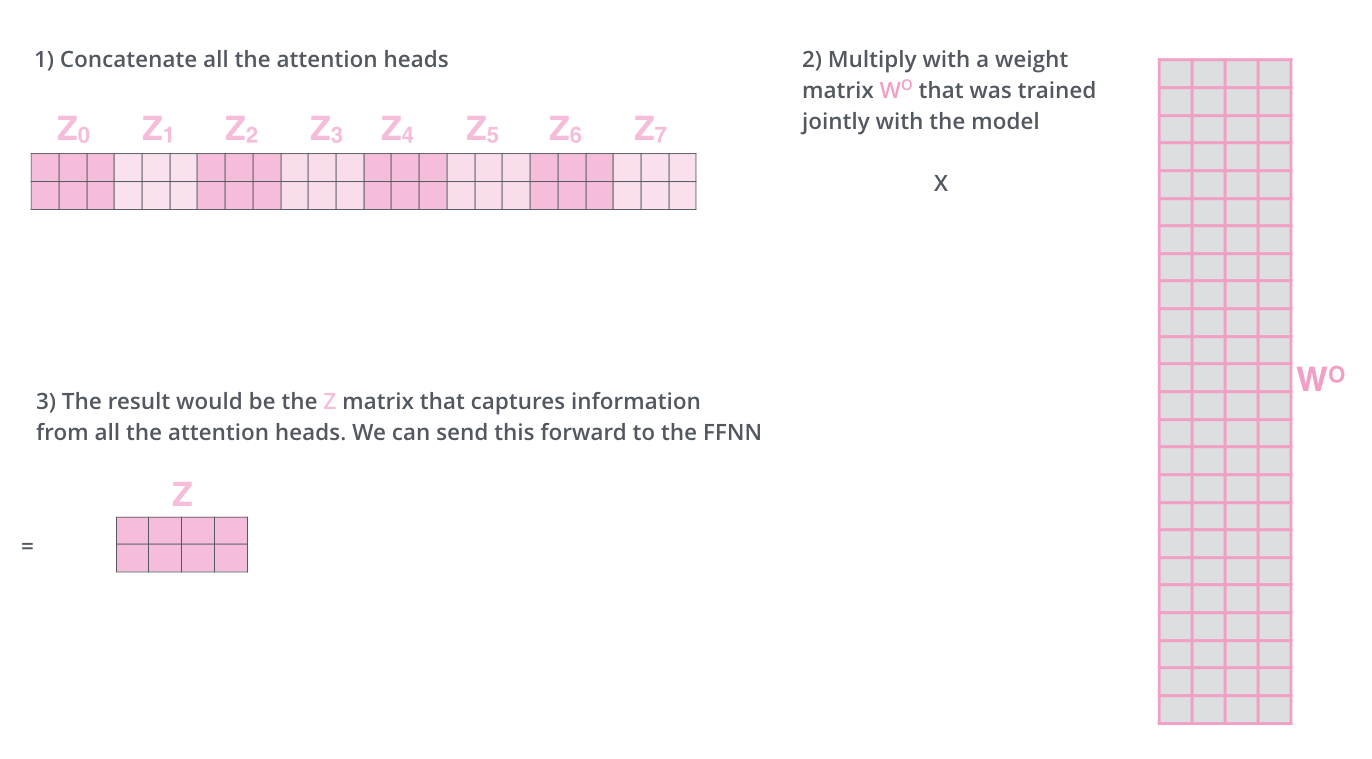
Multi-Head Attentionの行列の演算を1つのビジュアルにまとめると次のようになります。
先ほどの例文の中で「it」という単語をエンコードするときに、異なるSelf-Attentionがどこに注目しているかを確認します。

「it」という言葉をエンコードするとき、あるSelf-Attention(赤色のSelf-Attention)は「animal」にもっとも注目し、別のSelf-Attention(緑色のSelf-Attention)では「tired」にもっとも注目しています。ある意味では「it」という言葉のモデルの表現は、「animal」と「tired」の両方の表現の一部を組み込んでいると解釈できます。
Feed Forward
Feed Forward層は、ReLUで活性化する2048次元の中間層と512次元の出力層から成る2層の全結合ニューラルネットワークです。Feed Forward層はEncoderおよびDecoderの各層に含まれています。式は次のとおりです。
Positional Encoding
TransformerはRNNを採用していないため、それまでRNNが担っていた「文脈」を取得できなくなるなります。例えば、「I love cats」と「cats love I」は同じものになってしまってしまいます。
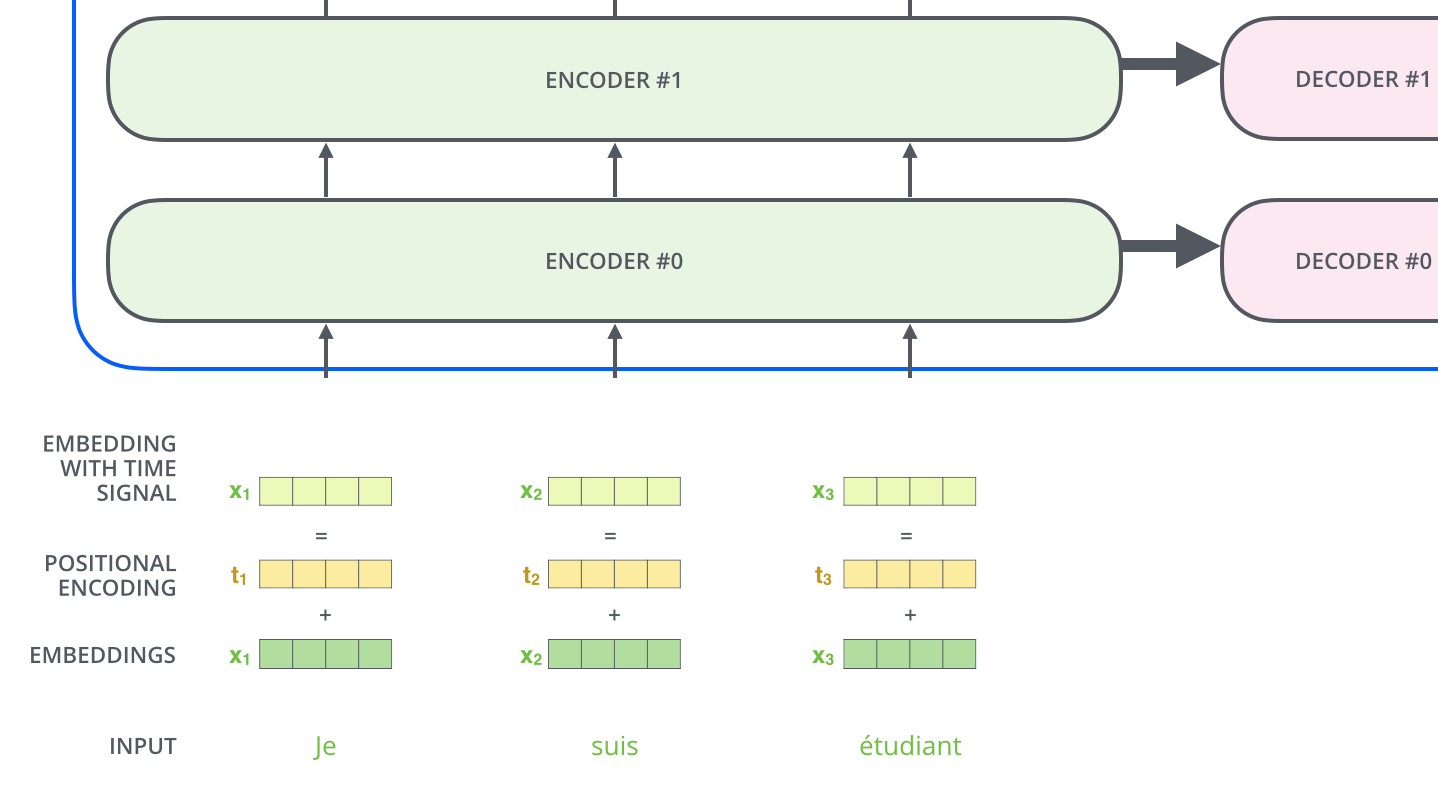
Positional Encoding層は上記の問題を解決するために導入された仕組みで、各要素に文中の位置情報を付与します。位置情報を付与することで、各要素データを並列処理したとしても、元々入力データが持っていた文章上の前後要素との関係情報を維持できるようになります。
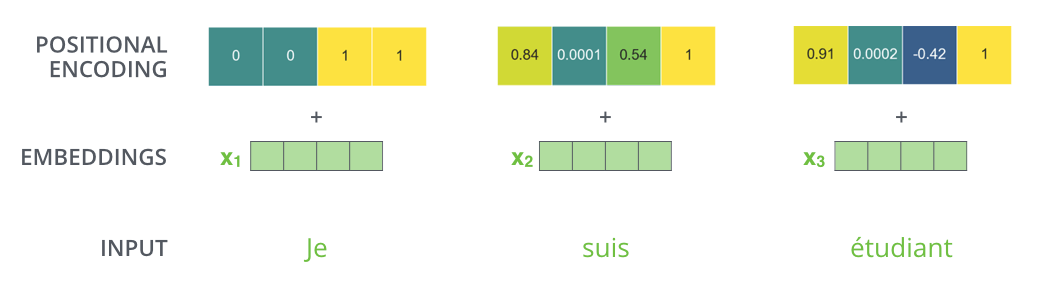
実際には、Positional Encodingは周波数が異なるsin関数・cos関数をの値をベクトルに埋め込むことで位置情報を与えています。
埋め込みの次元数が4であるとすると、実際のPositional Encodingベクトルの値は次のようになります。
Decoder
Decoderでは、まずは入力系列が処理されます。最上段のEncoderの出力は、続いてkeyベクトルとValueベクトルのセットに変換されます。これらは,各DecoderがEncoder-Decoder Attentionで使用するもので、Decoderが入力系列の適切な場所に注目するのに役立ちます。
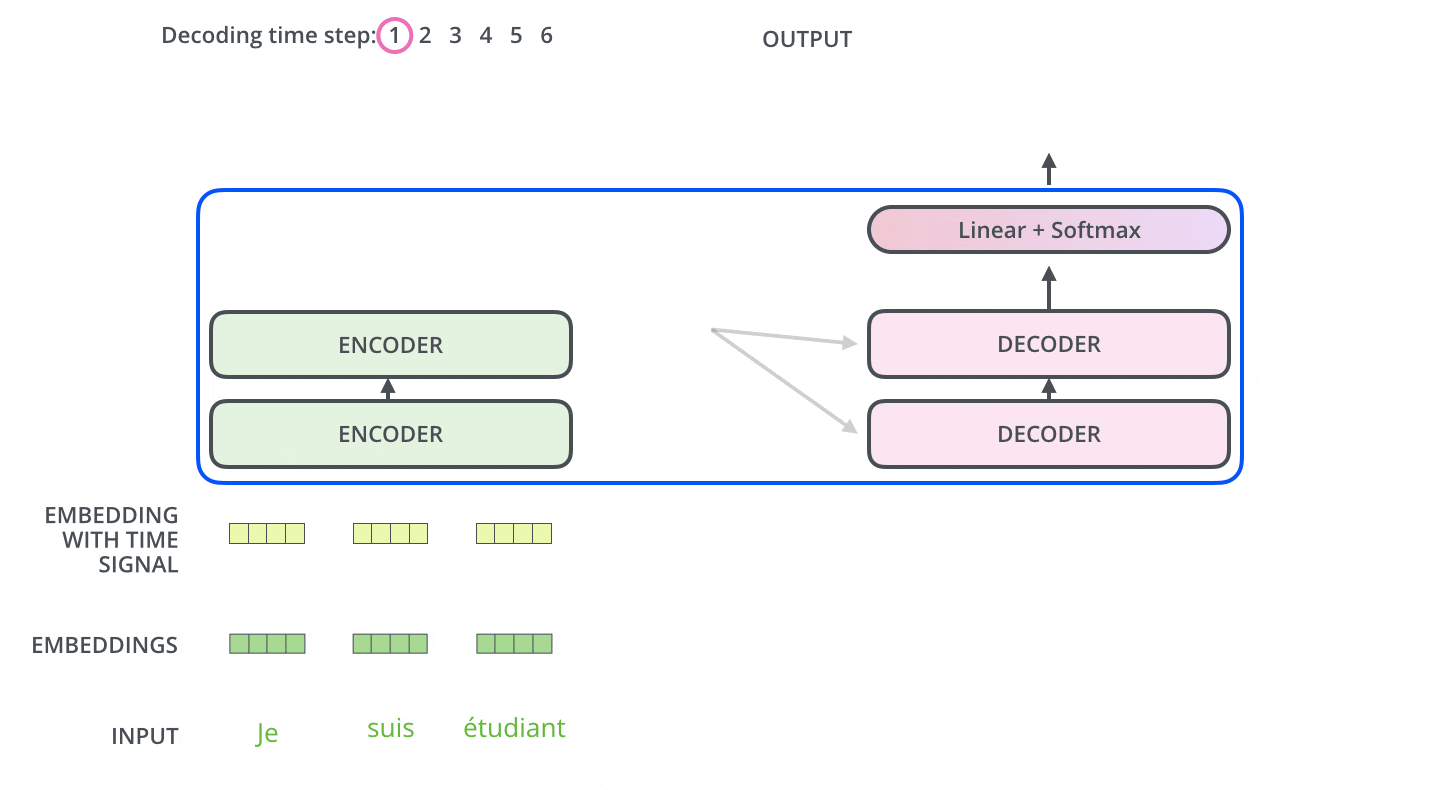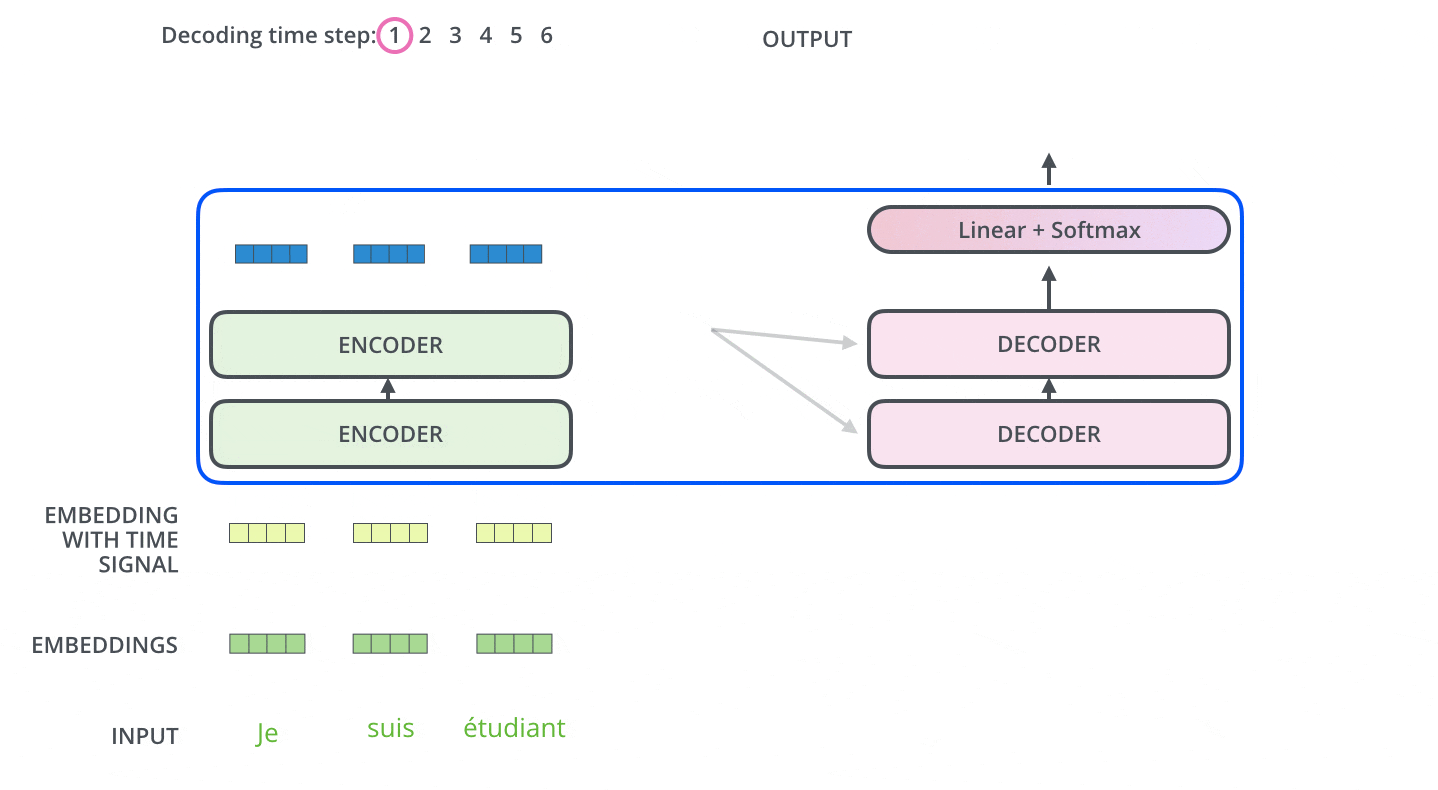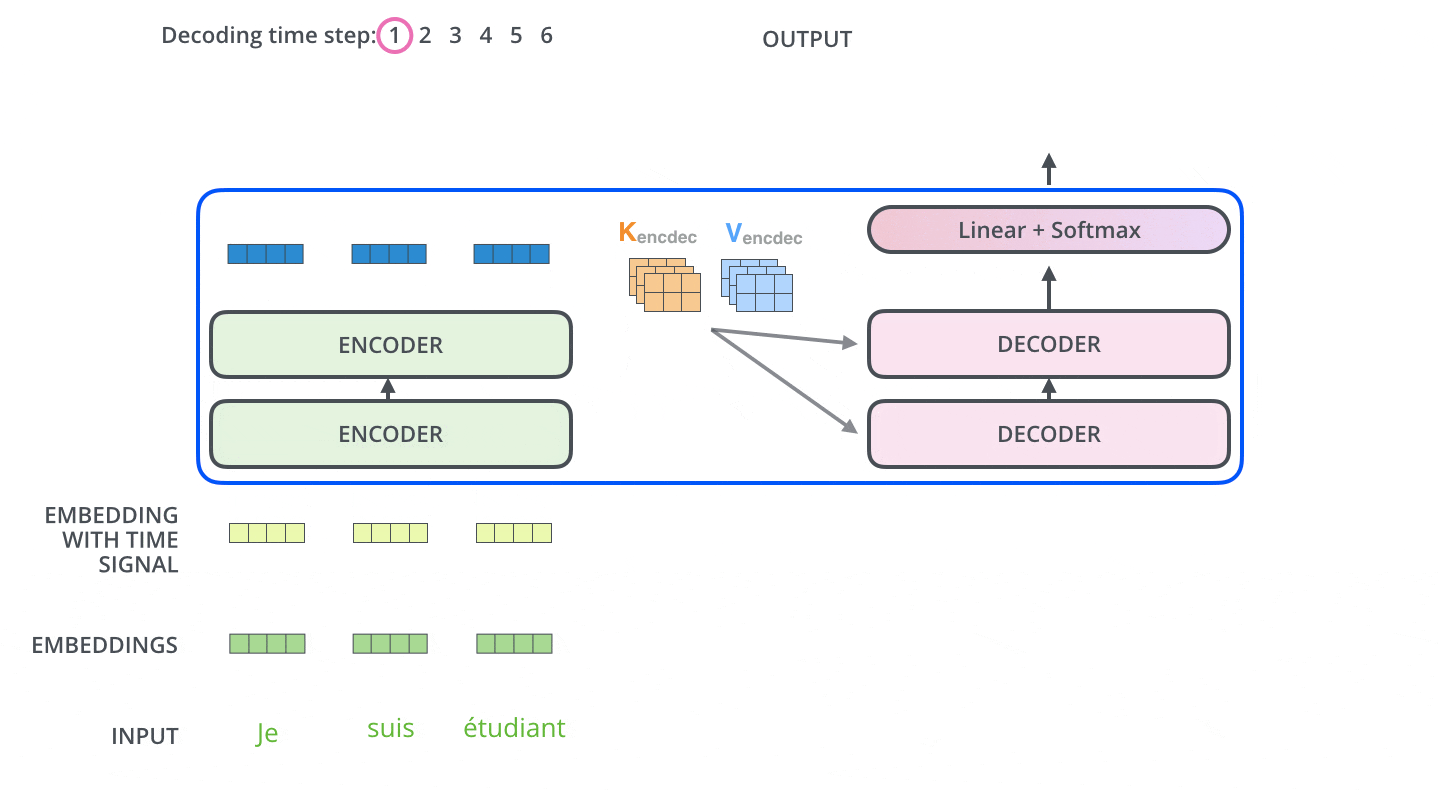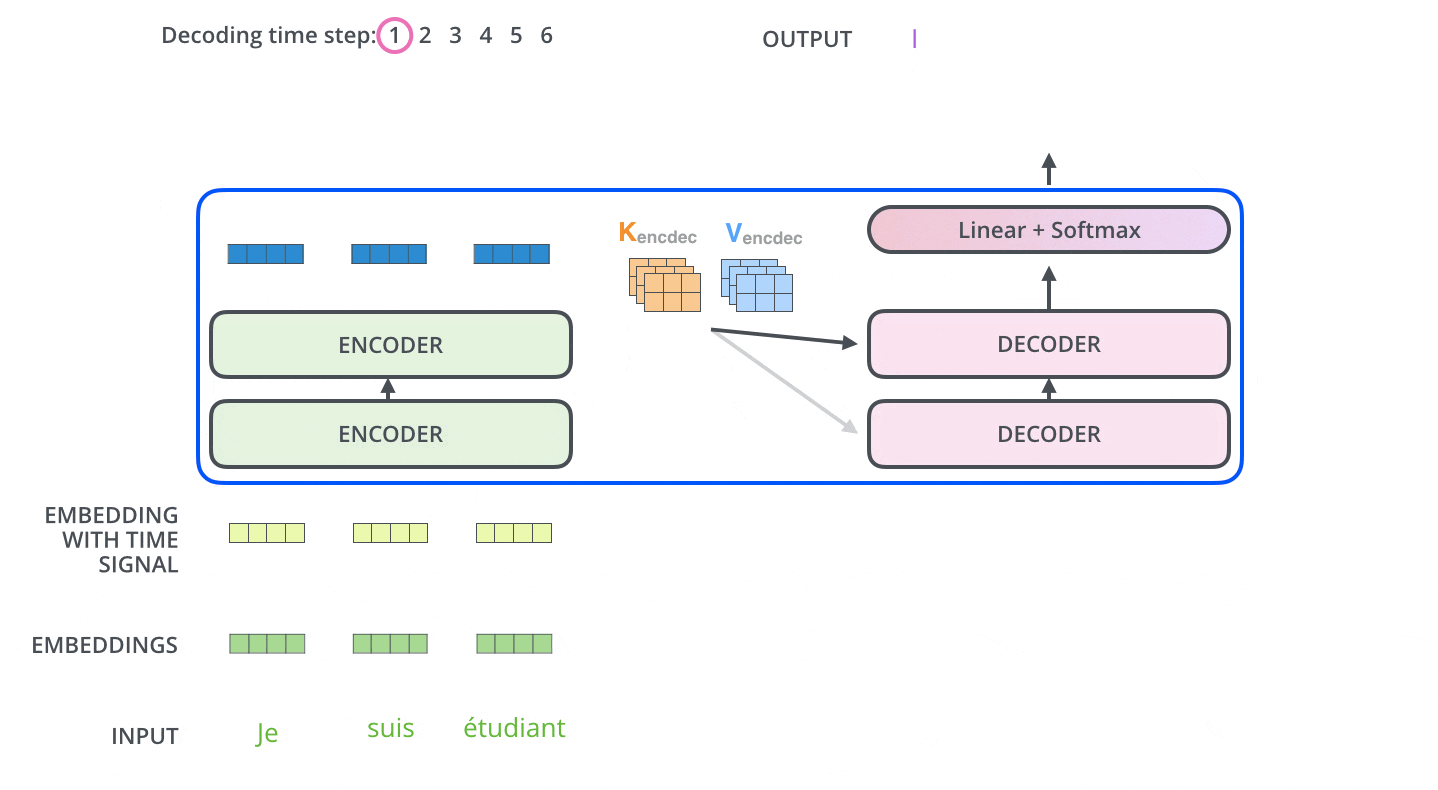
エンコーディングを終えた後にデコーディングに入ります。デコーディングの各ステップでは、出力系列(ここでは英訳文)の内、1つの要素を出力します。
次のステップでは、TransformerのDecoderは、出力が完了したことを示す特別なシンボルに到達するまでプロセスを繰り返します。各ステップの出力は、次のタイムステップで最下段のDecoderに供給され、Decoderはデコード結果を上段のDecoderに送ります。その際にEncoderの入力で行ったことと同様に、各単語の位置を示すためにDecoderの入力に位置エンコーディングベクトルを追加します。
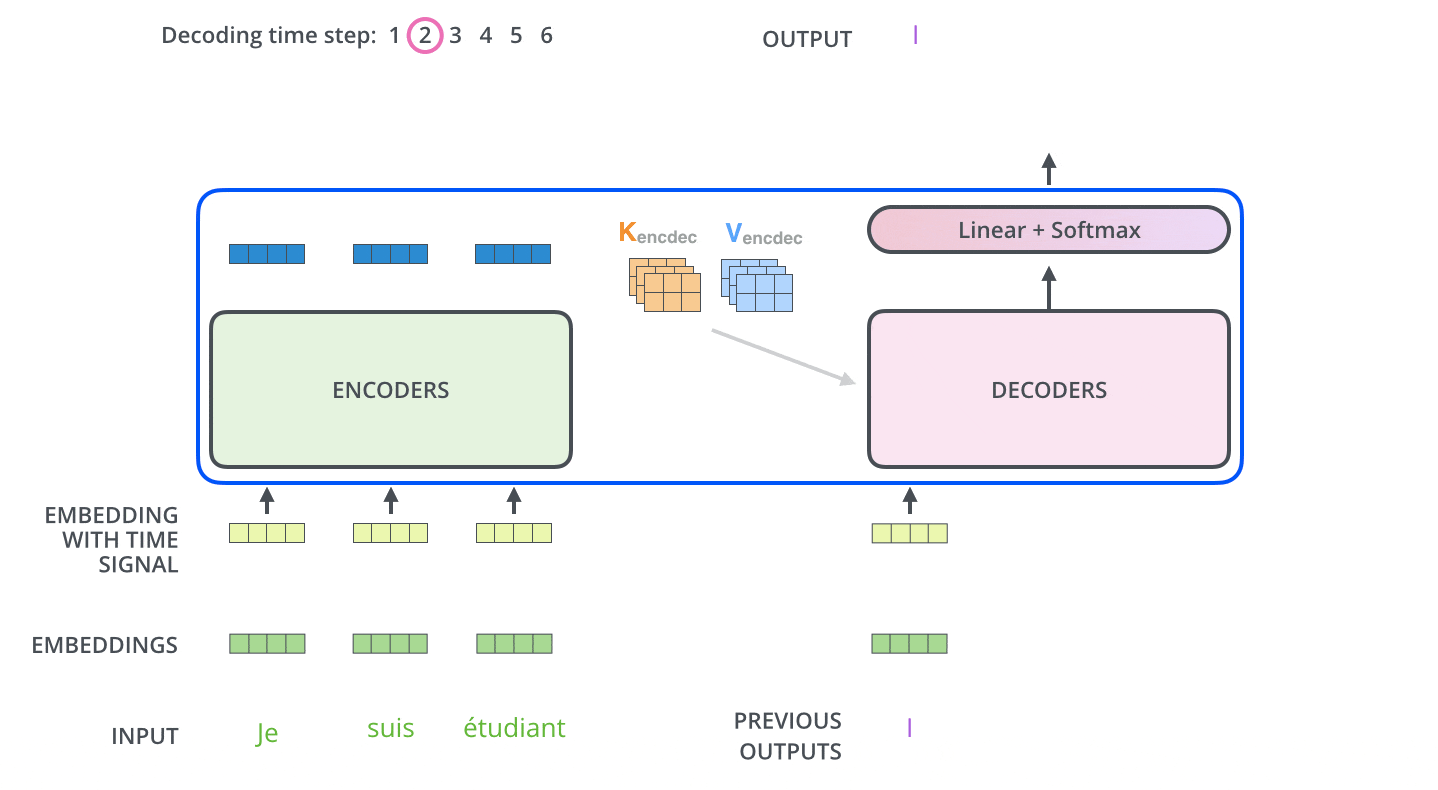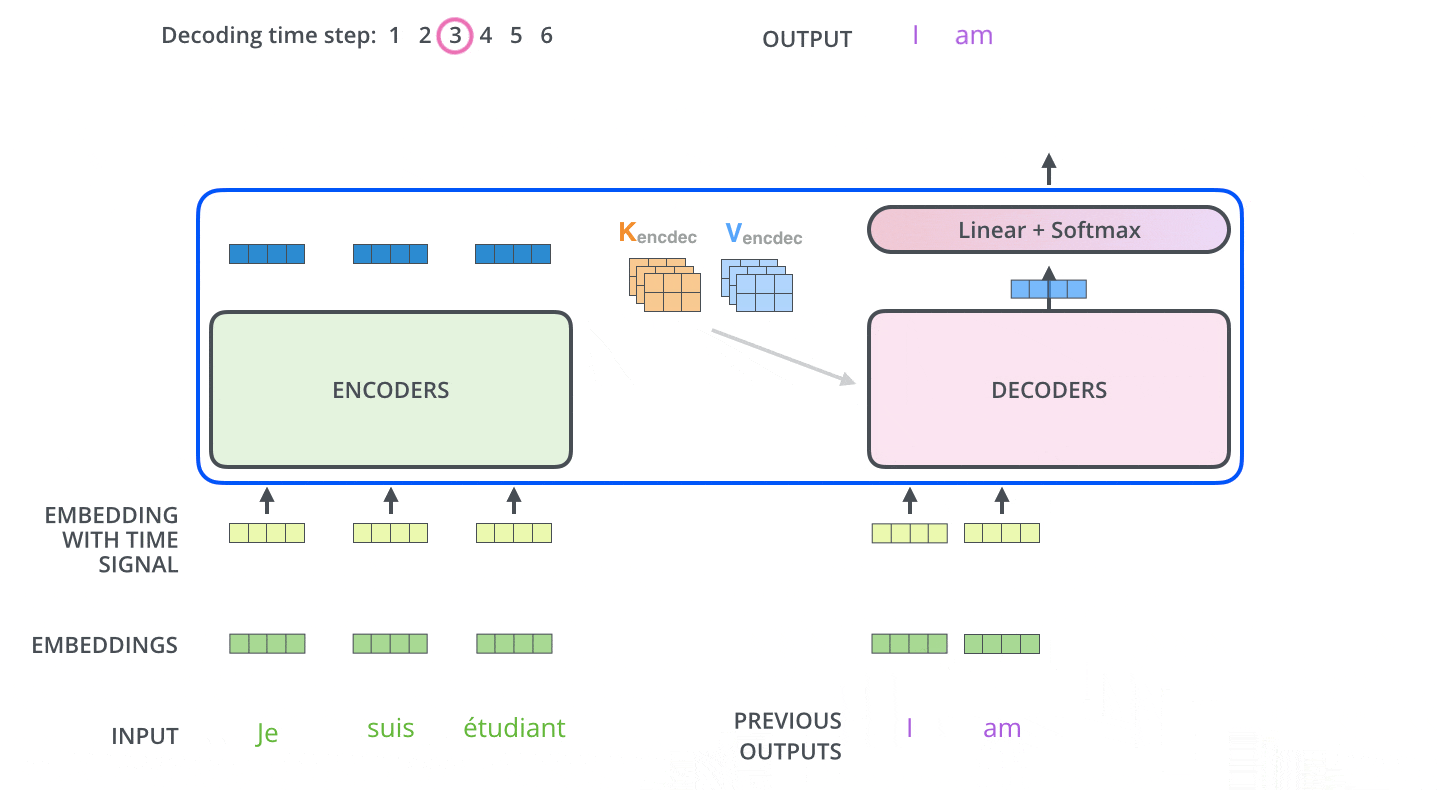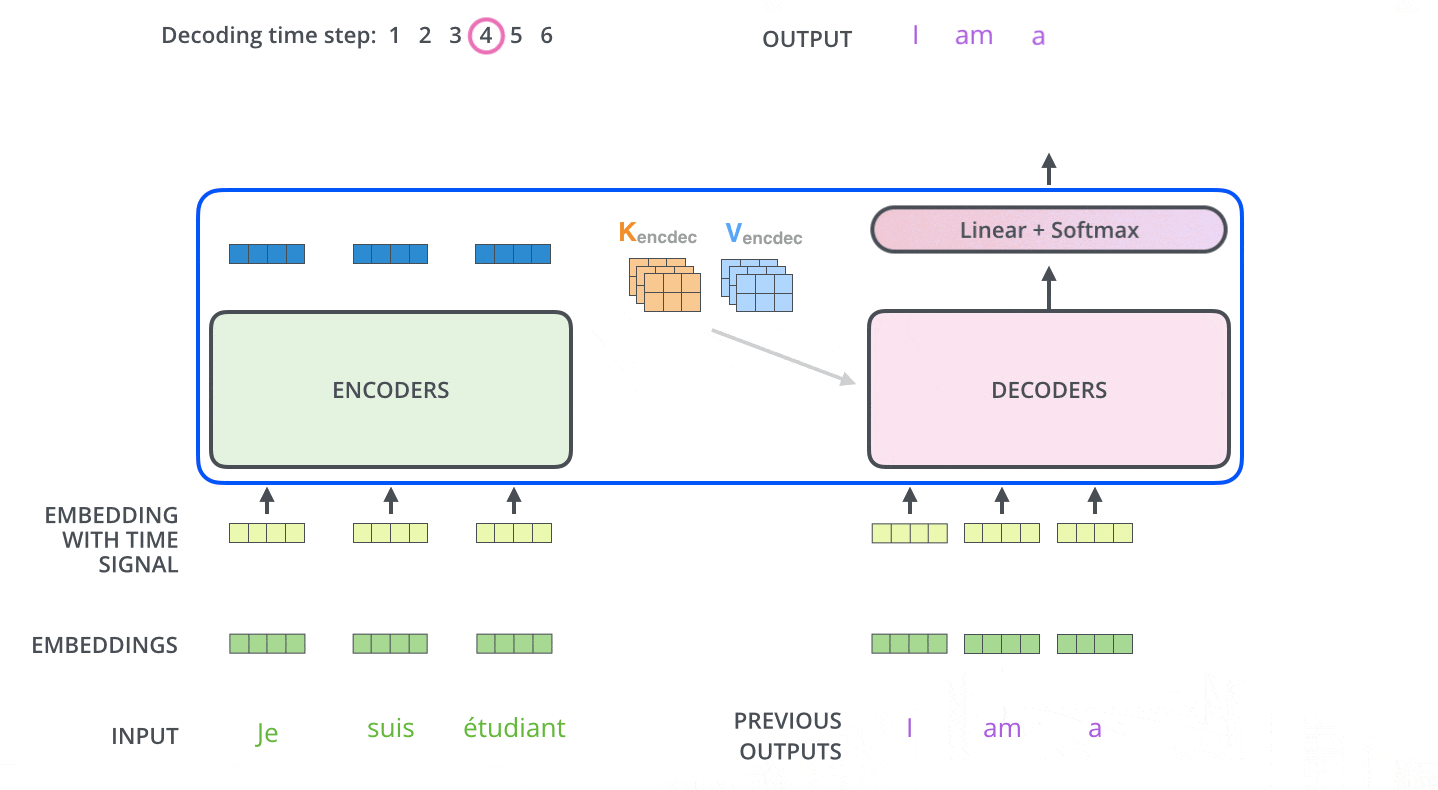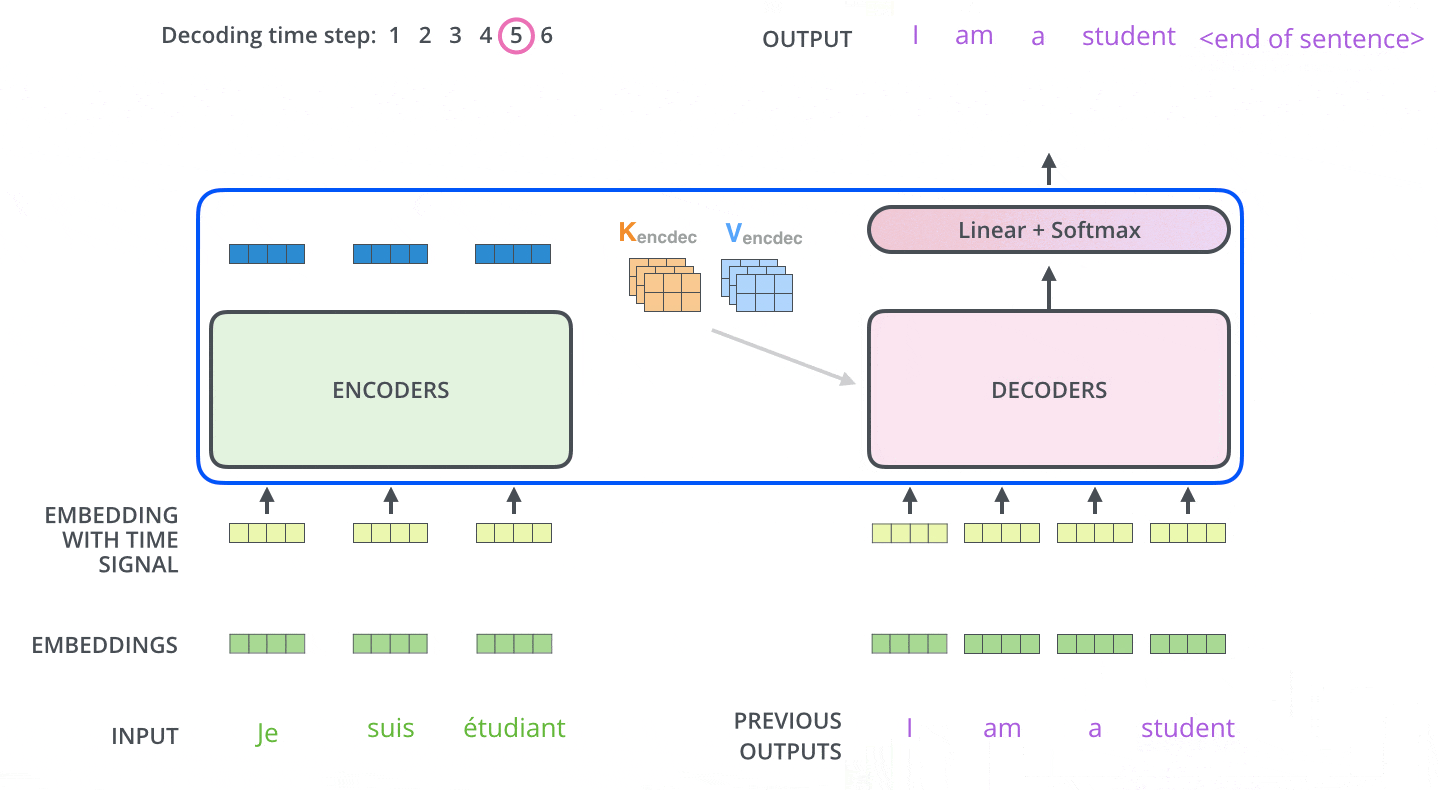
Masked Multi-Head Attention
Decoderの最初のMulti-Head Attentionは、使うべきでない情報をマスキング(入力文章の単語のうちの一部をハイフンなどで置き換えること)したMasked Self-Attentionになります。
トレーニング時のDecoderの入力は、翻訳後の単語列になりますが、翻訳語の単語列は前から順番に作成していく必要があり、
マスキングをしなければ、その単語より前の単語だけでなく先の単語の答えも見ながら当てるということになってしまい、カンニングになってしまいます。
Linear と Softmax
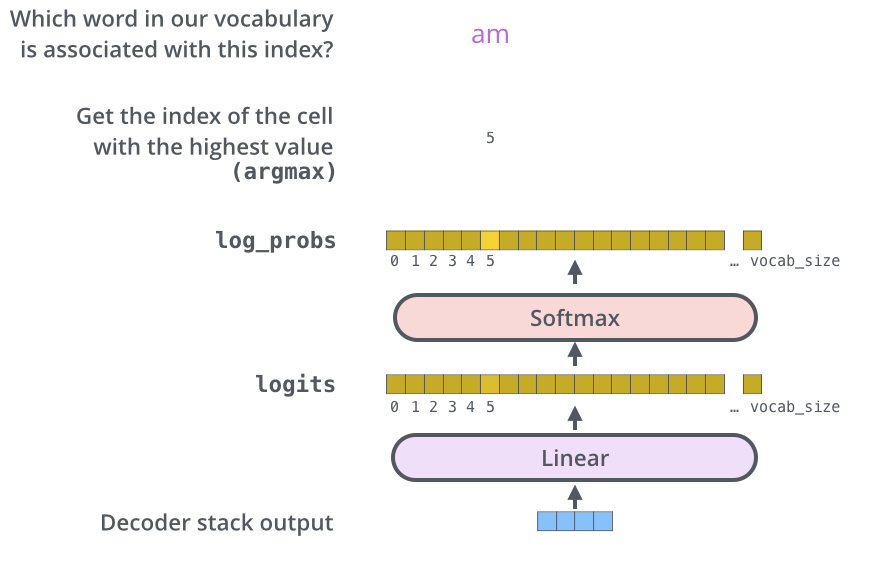
Decoderにより、ベクトル出力されます。このベクトルはLinear層とSoftmax層により単語に変換されます。
Linear層は単純な全結合ネットワークで、Decoderから出力されたベクトルをロジットベクトルと呼ばれるベクトルに変換します。例えば、モデルが訓練データセットから10,000個の英単語を学習したと仮定すると、ロジットベクトルは10,000セルの幅になります。
Softmax層ではロジットベクトルを確率に変換します。もっとも高い確率を持つセルが選択され、それに関連する単語がこの時間ステップの出力として生成されます。
Transformer のフレームワーク
TransformerのモデルはHugging Face社が提供しているTransformersというフレームワークを用いることで簡単に実装することができます。
TransformersはPyTorchやTensorFlowといった人気のディープラーニングライブラリ向けのPythonモジュールとなっています。
Transformer の発展形
Transformerに基づく言語理解AIモデルは大きく次の2つがあります。
- BERT
- GPTシリーズ
Transformer の Colab ノートブック
次のGoogle Colabノートブックでは、 TransformerのAttentionがどの単語に注目しているかを視覚的に理解することができます。
Tensorflow 付属のノートブック
VizBERT
参考

















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS