


DistilBERT とは
DistilBERTとはHuggingface社が2019年に発表した DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter という論文で登場したモデルです。DistilBERTは BERT をベースとした Transformer モデルであり、BERT-baseよりもパラメータが40%少なく、60%高速に動作し、GLUE Benchmarkで測定されたBERTの97%の性能を維持することができます。
DistilBERTは、Teacherと呼ばれる大きなモデルをStudentと呼ばれる小さなモデルに圧縮する技術である知識蒸留(Distillation Knowledge)を用いて訓練されます。BERTを蒸留することで、元のBERTモデルと多くの類似点を持ちながら、より軽量で実行速度が速いTransformerモデルを得ることができます。
DistilBERT 誕生の背景
近年のNLPでは、大量のパラメータをラベルなしデータで事前学習をすることにより、精度の高い言語モデルを作ることが主流となっています。BERTやGPTシリーズなどはモデルがどんどん巨大化し、1つのサンプルの計算も非常に時間がかかってしまい、一般ユーザーには計算負荷が高すぎるという課題があります。
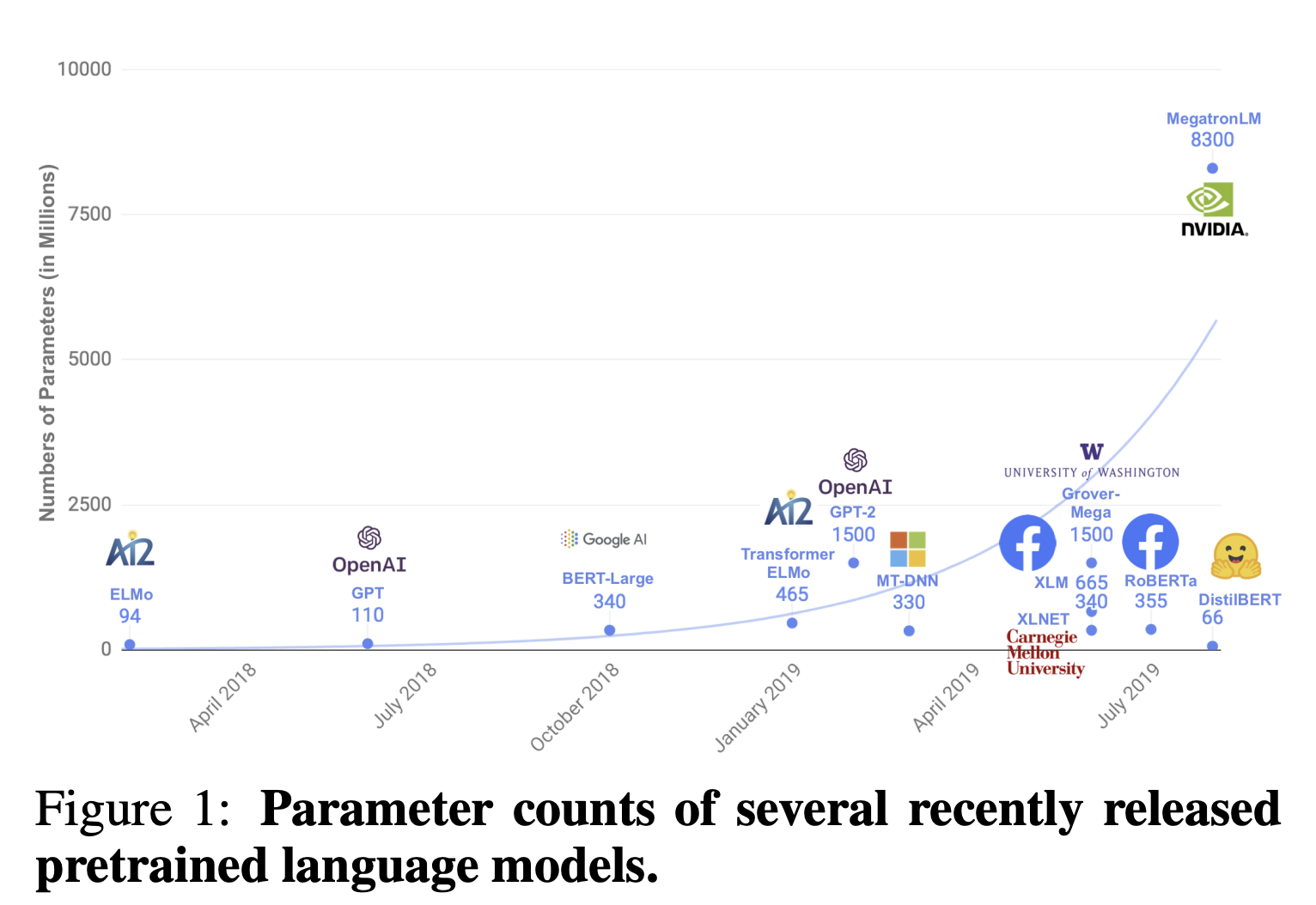
そのため、本論文では、精度を維持しつつより軽量なモデルを作ることを目指しています。
Knowledge Distillation
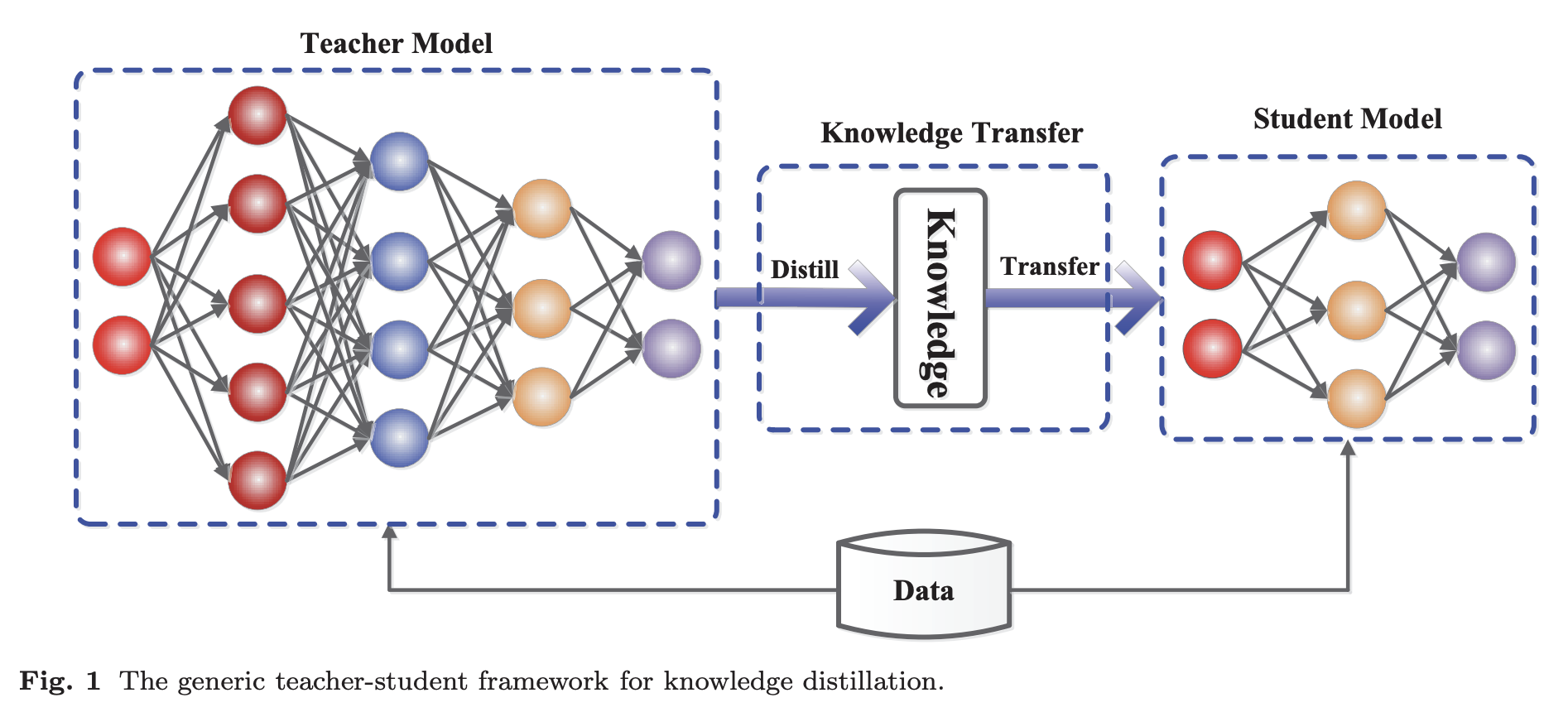
Knowledge Distillationとは、2015年に Distilling the Knowledge in a Neural Network という論文で登場した手法で、計算量の多い大きなモデル(Teacherモデル)から、妥当性を保ちながら小さなモデル(Studentモデル)へ知識を圧縮して転送するというものです。StudentはTeacherの振る舞いを再現するように訓練されます。ただし、StudentはTeacherほど大きな記憶容量(パラメータ数)はありませんので、その少ない記憶容量でできるだけTeacherに近づけるようにします。
-
Teacherモデル
非常に大きなモデルや、ドロップアウトのような強力な正則化を行なって個別に学習したモデルのアンサンブル -
Studentモデル
Teacherモデルの蒸留された知識に依存する小さなモデル
Knowledge Distillation: A Survey
DistilBERTにおいて、TeacherはBERT、StudentはDistilBERTを指します。
DistilBERT の構造
Student のアーキテクチャ
StudentであるDistilBERTは、BERTと同じ一般的なアーキテクチャを踏襲しています。DistilBERTではパラメータを削減するために次の施策を行います。
- Token embeddings層の削除
- Pooler層(Transformer Encoderの後の分類用の層)の削除
- Transformerの層数を半分にする(BERT_BASE: 12, DistilBERT: 6)
これらの施策により、パラメータ数が40%減少することになります。
Student の初期値
Studentの初期値にはTeacherであるBERTのパラメータが使われます。ただし、Studentの層数はTeacherの層数の半分なので、対応する2つの層のうちの1つを初期値としています。
Distillation
DistilBERTでは学習方法を次のように設定しています。
- バッチサイズを4,000と大きくする
- ダイナミックにマスキングを行う
- Next Sentence Predictionは実施しない
トレーニングの損失関数
DistilBERTの損失関数はDistillation Loss (
Distillation Loss
Distillation Loss (
ここで、
上式の損失関数よって、もっとも予測確率が高い単語だけでなく、その次に予測確率が高い単語の予測確率なども真似することができ、Teacherの予測する分布を学習することができます。
例えば次の文章があるとします。
I watched [MASK] yesterday.
TeacherであるBERTの予測確率が次のようになったとします。
| 予測単語 | 予測確率 |
|---|---|
| movie | 0.8 |
| TV | 0.1 |
| baseball | 0.05 |
| MMA | 0.05 |
このとき、Studentは「movie」だけでなく、「TV」や「MMA」、「baseball」の予測確率もTeacherであるBERTに近づけるように学習します。
ただし、ここでは予測確率 softmax–temperatureという関数を使って表します。
softmax–temperatureを使うことで予測確率の小さい単語の予測確率も学習するように仕向けています。
Masked Language Model Loss
Masked Language Modelling Loss (
Cosine Embedding Loss
Cosine Embedding Loss (
参考
















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS