

はじめに
重みの初期化は、深層学習モデルのトレーニングにおいて重要な側面の1つであり、モデルのパフォーマンス、トレーニング時間、安定性に大きな影響を与えます。ニューラルネットワークの初期重みは、モデルがトレーニング中にどの程度速く収束するか、最適またはサブオプティマルな解に収束するかどうかに影響を与えることができます。正しい重みの初期化戦略を選択することは、深層学習プロジェクトで最良の結果を得るために不可欠です。
重みの初期化は、ニューラルネットワーク内の重みの初期値を決定することによって学習プロセスの準備を整えます。適切な重みの初期化により、より速い収束と改善された汎化が実現されます。一方、不適切な初期化は収束が遅くなるか、学習が失敗する可能性があります。異なる重みの初期化技術の影響を理解することで、実践者はより情報を得て、より優れたモデルを開発することができます。
重みの初期化の技術
この章では、深層学習コミュニティで広く使用されているさまざまな重みの初期化技術について説明します。各技術には独自の利点があり、異なるタイプのニューラルネットワークアーキテクチャや活性化関数に適しています。これらの方法を理解することで、深層学習モデルを設計してトレーニングする際に、より情報を得て意思決定をすることができます。
ゼロ初期化
ゼロ初期化は、ネットワーク内の全ての重みがゼロで初期化されるもっとも簡単な方法です。実装が容易ですが、このアプローチには重大な欠点があります。全てのニューロンが同じ特徴を学習し、モデルがデータの複雑さを捉えることができなくなり、パフォーマンスが低下する「対称性の問題」という現象が発生することがあるので、深層学習モデルにはゼロ初期化を使用しないことが一般的に推奨されています。
ランダム初期化
対称性の問題を克服するために、ランダム初期化は重みに小さなランダムな値を割り当てます。この方法により、各ニューロンが異なる特徴を学習し、モデルがデータの複雑さを捉えることができるようになります。ただし、ランダム初期化にも問題があります。初期重みが大きすぎるか小さすぎる場合、勾配消失や爆発などが発生し、学習プロセスに悪影響を与える可能性があります。
Xavier (Glorot)初期化
Xavier初期化は、GlorotとBengioによって2010年に提案されたもので、レイヤーの入力ユニット数と出力ユニット数に基づいて初期重みをスケーリングすることで、ランダム初期化に関連する問題に対処します。具体的には、重みは平均0、分散
He (Kaiming)初期化
He初期化、またはKaiming初期化とも呼ばれ、Heらによって2015年に導入されました。Xavier初期化と同様に、He初期化も初期重みをスケーリングしますが、ReLUとそのバリアントを活性化関数として使用するネットワークに特化しています。重みは平均0、分散
LeCun初期化
LeCun初期化は、Yann LeCunによって提案された人気のある重みの初期化方法の1つです。XavierとHe初期化と同様に、LeCun初期化もレイヤーの入力サイズに基づいて初期重みをスケーリングします。重みは平均0、分散
直交初期化
直交初期化は、Saxeらによって2013年に導入されたもので、重み行列をランダムな直交行列で初期化します。この方法により、逆伝搬中の勾配の大きさを保持することができ、収束を加速し、パフォーマンスを向上させることができます。直交初期化は、勾配消失や爆発が問題になる深層または再帰的なニューラルネットワークに特に有用です。
適切な初期化方法の選択
適切な重みの初期化方法を選択することは、効果的な深層学習モデルのトレーニングに不可欠です。この章では、初期化技術を選択する際に考慮すべき要因、および特定のユースケースに最適な方法を選択するためのガイドラインについて説明します。
ネットワークアーキテクチャ
ニューラルネットワークのアーキテクチャは、最適な重みの初期化方法を決定する上で重要な役割を果たします。例えば、多層のディープネットワークは、勾配の消失や爆発がより起こりやすいため、Xavier、He、または直交初期化などの方法がより適しています。一方、浅いネットワークは初期化方法の選択に対して敏感ではありません。
活性化関数
ニューラルネットワークで使用する活性化関数のタイプも、重みの初期化の選択に影響します。
- シグモイドまたはtanh活性化関数は、XavierまたはLeCun初期化が適しています。
- ReLUおよびそのバリアント(Leaky ReLUやParametric ReLUなど)は、He(Kaiming)初期化に適しています。
- 勾配の消失または爆発が問題になる深層または再帰的なニューラルネットワークは、直交初期化を使用すると有益です。
問題の複雑さ
解決する問題の複雑さも、適切な重みの初期化方法を選択する上で重要です。高次元データや複数のモダリティを持つタスクなど、より複雑な問題では、効果的な学習を保証するためにより洗練された初期化技術が必要になる場合があります。
適切な初期化方法の選択
上記の要因に基づいて、次のガイドラインは、特定のユースケースに最適な重みの初期化技術を選択するのに役立ちます。
- ゼロ初期化は、対称問題とモデルのパフォーマンス低下を引き起こすため、避ける必要がある
- シグモイドまたは双曲線正接活性化関数を使用するネットワークの場合、XavierまたはLeCun初期化を検討する
- ReLUまたはそのバリアントを使用するネットワークの場合、He(Kaiming)初期化が一般的に適切な選択肢になる
- 勾配の消失または爆発が問題になる深いまたは再帰的なネットワークの場合、直交初期化を使用することが適している場合がある
これらは一般的なガイドラインであり、特定の問題に対して最適な重みの初期化方法は異なる場合があることに注意してください。さまざまな技術を試して、トレーニングプロセス中にモデルのパフォーマンスに与える影響を監視することが重要です。
重みの初期化技術の比較
この章では、Pythonでそれらを実装し、4つの隠れ層ニューラルネットワークのアクティベーション分布に対する影響を分析することで、重みの初期化技術を比較します。パブリックなデータセットを使用し、ヒストグラム形式で活性化分布を可視化して、初期化方法の違いをよりよく理解することができます。
データセットとモデルの設定
この比較には、手書き数字(0-9)の60,000のトレーニング画像と10,000のテスト画像から構成される人気のあるMNISTデータセットを使用します。シンプルなフィードフォワードニューラルネットワークを5層とReLU活性化関数を使用します。
モデルは、次の構造を持つ5層のニューラルネットワークです。
- 入力層:784のノード(28×28ピクセルのMNIST画像サイズに対応)
- 1つ目の隠れ層:512のノード
- 2つ目の隠れ層:256のノード
- 3つ目の隠れ層:128のノード
- 4つ目の隠れ層:64のノード
Pythonで重みの初期化技術を実装
まず、必要なライブラリをインポートし、初期化関数を定義します。
import numpy as np
import matplotlib.pyplot as plt
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import Adam
from keras.initializers import Zeros, RandomNormal, GlorotNormal, HeNormal, LecunNormal
# Define weight initialization functions
def init_zeros(shape, dtype=None):
return Zeros()(shape, dtype=dtype)
def init_random_normal(shape, dtype=None):
return RandomNormal(stddev=0.01)(shape, dtype=dtype)
def init_xavier(shape, dtype=None):
return GlorotNormal()(shape, dtype=dtype)
def init_he(shape, dtype=None):
return HeNormal()(shape, dtype=dtype)
def init_lecun(shape, dtype=None):
return LecunNormal()(shape, dtype=dtype)
モデルの構築と活性化分布の可視化
次に、指定された重みの初期化方法を使用してモデルを構築し、MNISTデータセットでトレーニングし、各層のアクティベーション分布のヒストグラムを描画する関数を作成します。
def build_and_train_model(init_func, dataset, layer_dims=[784, 512, 256, 128, 64], activation='relu', epochs=5):
(X_train, y_train), (X_test, y_test) = dataset
model = Sequential()
input_dim = layer_dims[0]
for layer_dim in layer_dims[1:]:
model.add(Dense(layer_dim, input_dim=input_dim, activation=activation, kernel_initializer=init_func))
input_dim = layer_dim
model.compile(optimizer=Adam(), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs=epochs, validation_data=(X_test, y_test), verbose=0)
activations = []
for layer in model.layers:
intermediate_model = Sequential(model.layers[:model.layers.index(layer) + 1])
activations.append(intermediate_model.predict(X_test))
return history, activations
アクティベーション分布の分析
次に、各初期化方法に対するアクティベーション分布を、各層のヒストグラムをプロットして分析します。
initializers = {
'Zero': init_zeros,
'Random Normal': init_random_normal,
'Xavier': init_xavier,
'He': init_he,
'LeCun': init_lecun
}
dataset = mnist.load_data()
fig, axes = plt.subplots(len(initializers), 4, figsize=(25, 25))
plt.style.use('ggplot')
for idx, (name, init_func) in enumerate(initializers.items()):
_, activations = build_and_train_model(init_func, dataset)
for layer_idx, activation in enumerate(activations):
axes[idx, layer_idx].hist(activation.flatten(), bins=50, density=True, color='blue', alpha=0.5)
axes[idx, layer_idx].set_xlim(-1, 1)
axes[idx, layer_idx].set_ylim(0, 4)
axes[idx, layer_idx].set_title(f'{name} Initialization - Layer {layer_idx + 1}', fontsize=16)
axes[idx, layer_idx].set_xlabel('Activation Value', fontsize=12)
axes[idx, layer_idx].set_ylabel('Density', fontsize=12)
plt.subplots_adjust(hspace=0.4, wspace=0.4)
plt.show()
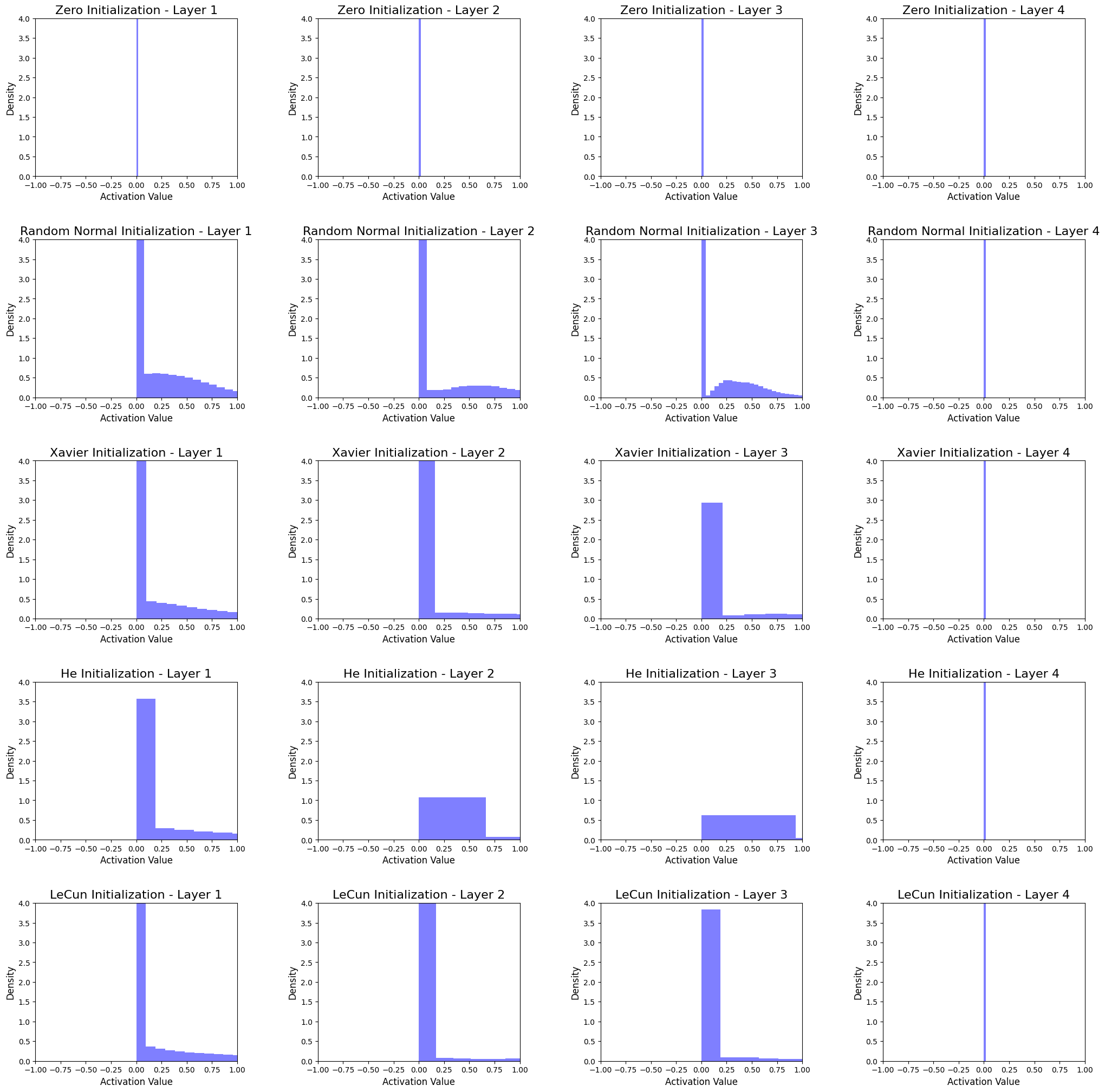
ヒストグラムの解釈
ヒストグラムは、4つの隠れ層ニューラルネットワークの各初期化方法に対するアクティベーション分布を示しています。ヒストグラムを分析することにより、次のような結論を導くことができます。
-
ゼロ初期化
全ての層のアクティベーションがゼロに集中しています。これは、モデルがデータの複雑さを捉えることができず、学習が困難になるため、パフォーマンスが低下することを示しています。 -
ランダム正規初期化
各層のアクティベーションは正規分布を持ちます。ただし、アクティベーションの大部分はゼロに近く、デッドニューロンにつながる可能性があるため、学習プロセスに悪影響を与える可能性があります。 -
Xavier初期化
アクティベーションは、Random Normal初期化よりも高い標準偏差を持つ正規分布を持ち、より良い学習が得られます。この方法は、シグモイドまたはtanh活性化関数を使用するネットワークに適していますが、ReLU活性化関数には最適な選択肢ではないかもしれません。 -
He初期化
アクティベーションは、他の方法と比較してより均等に広がっているため、デッドニューロンを回避し、より良い学習が可能になります。この方法は、ReLU活性化関数を使用するネットワークに特に適しており、一般的に優先される方法です。 -
LeCun初期化
アクティベーションは、Xavier初期化と似ていますが、標準偏差がやや低いです。この方法は、シグモイドまたはtanh活性化関数を使用するネットワークに適しています。
全ての方法で、最後の隠れ層のアクティベーションはゼロに集中しています。その原因の1つは、最後の隠れ層のノードサイズ(64ノード)かもしれません。
分析から、重みの初期化方法の選択がネットワーク内のアクティベーションの分布に重要な影響を与えることがわかります。一般的に、He初期化はReLU活性化関数を使用するネットワークに最適であり、シグモイドまたはtanh活性化関数を使用するネットワークにはXavierまたはLeCun初期化が適している可能性があります。特定のニューラルネットワークアーキテクチャと活性化関数の特性に基づいて適切な重みの初期化技術を選択することが重要です。

















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS