


畳み込みニューラルネットワーク(CNN)とは
畳み込みニューラルネットワーク(CNN)は、畳み込み層、プーリング層、完全連結層を使用して、画像などのグリッド状の構造化データを処理するために設計された人工ニューラルネットワークの一種です。CNNは、画像分類、物体検出、セマンティックセグメンテーションなどのコンピュータビジョンタスクで広く使用されています。
CNNのアーキテクチャ
入力層
入力層は、画像などの生データがネットワークに供給されるCNNの最初のポイントです。画像の場合、入力は通常、高さ、幅、チャネル(カラー画像の場合は赤、緑、青チャネルなど)を持つ3次元テンソルとして表されます。入力層の主な役割は、入力データを前処理して標準化し、ネットワークが効果的に学習できるようにすることです。
畳み込み層
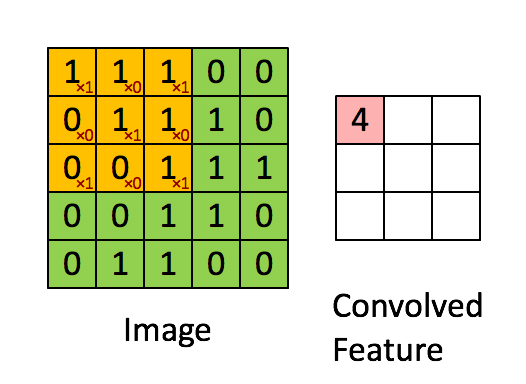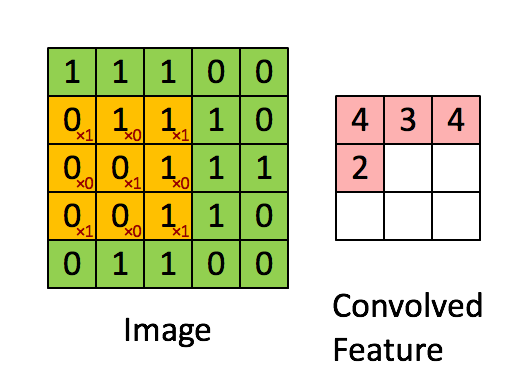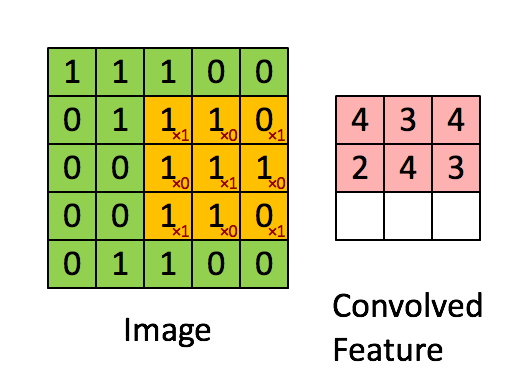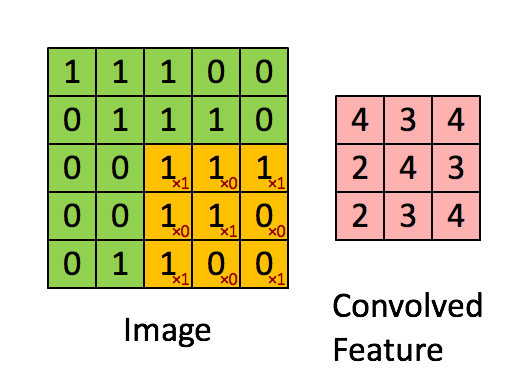
畳み込み層は、CNNの中核となるコンポーネントです。入力データに一連のフィルタ、またはカーネルを適用し、エッジ、テクスチャ、形などのローカルな特徴を学習できるようにします。フィルタは入力データ上にスライドして、要素ごとの乗算を実行し、結果を合計して特徴マップを生成します。畳み込み層の各フィルタは、入力データ内の特定の特徴を検出する責任があります。
特徴マップ
特徴マップは、畳み込み層の出力であり、入力データ内の学習された特徴の存在を捉えます。畳み込み演算を使用して、入力データにフィルタまたはカーネルを適用して生成されます。CNNが複数の層を経て進むにつれて、特徴マップはより抽象的で高次元になり、ネットワークが複雑なパターンと構造を認識できるようになります。
A Comprehensive Guide to Convolutional Neural Networks — the ELI5 way
ピンクの行列が特徴マップです。
フィルタ(カーネル)
フィルタ、またはカーネルは、畳み込み層で使用される小さな行列で、入力データから特徴を抽出するために使用されます。各フィルタは、エッジ、テクスチャ、形などの特定の特徴を検出する責任があります。フィルタはランダムな値で初期化され、トレーニングプロセス中にネットワークによって学習されます。フィルタサイズは、学習された特徴の細かさを制御するために調整できるハイパーパラメータであり、フィルタの次元またはカーネルサイズとして知られています。
A Comprehensive Guide to Convolutional Neural Networks — the ELI5 way
黄色の行列がフィルタです。
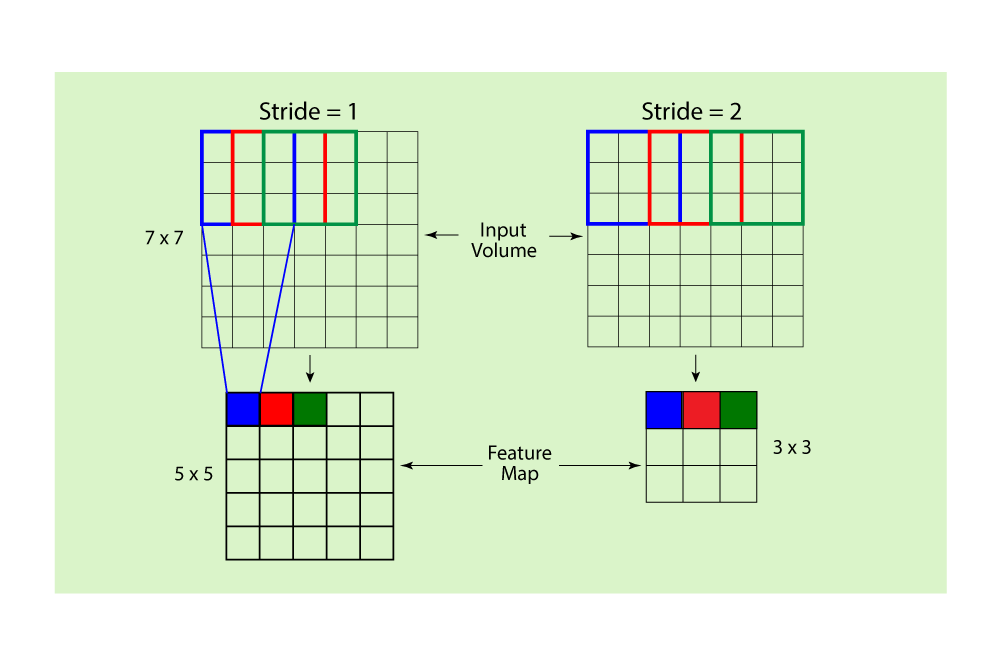
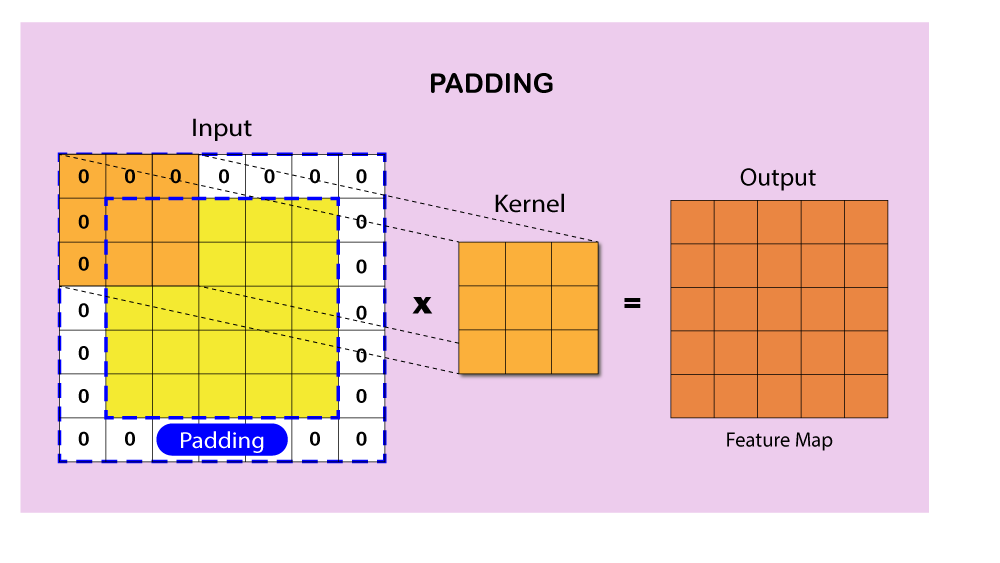
ストライドとパディング
ストライドとパディングは、畳み込み層で畳み込み演算を制御するハイパーパラメータです。ストライドは、畳み込み中にフィルタが入力データを移動するピクセル数を示します。大きなストライドは、より小さな特徴マップを生成し、計算量を減らします。パディングは、入力データの周りに余分なピクセル(通常はゼロ値)を追加して、畳み込み演算後に特徴マップの空間的な寸法を維持するプロセスを指します。パディングには2つの主要なタイプがあります。「valid」パディングでは、パディングが適用されません。「same」パディングでは、パディングが追加され、出力特徴マップが入力データと同じ寸法を持つようになります。ストライドとパディングを調整することで、CNNのパフォーマンスや計算効率に重要な影響を与えることができます。
活性化関数
活性化関数は、非線形性を導入してCNNに複雑なパターンと表現を学習させるために使用されます。畳み込み層の出力に適用され、特徴マップを変換します。CNNでよく使用されるいくつかの人気のある活性化関数には、Rectified Linear Unit(ReLU)、Leaky ReLU、Sigmoid、Hyperbolic Tangent(tanh)があります。ReLUは、計算効率が高く、勾配消失問題を緩和できるため、もっとも一般的に使用される活性化関数です。
プーリング層
プーリング層は、畳み込み層によって生成された特徴マップの空間的な寸法と計算量を減らすことで、ダウンサンプリングを担当します。この層は、ネットワークが移動、回転、スケーリングに不変になるようにし、特徴を認識する能力を向上させます。Max pooling、Average pooling、Global average poolingなどのさまざまなタイプのプーリング操作があります。もっとも一般的に使用されるのはMax poolingで、特徴マップ内の指定された領域内の最大値を選択します。

Convolutional Neural Network: An Overview
全結合層(Affine層)
いくつかの畳み込み層とプーリング層の後、CNNには1つ以上の全結合層が含まれることがよくあります。これらの層は、前の層から学習された特徴を統合し、抽出されたパターンに基づいて高次元の決定を行う責任があります。全結合層は、各ニューロンが前後の全てのニューロンに接続されている従来のフィードフォワードニューラルネットワークに見られるものと似ています。
出力層
出力層は、CNNの最後の層であり、ネットワークの予測または分類を生成する責任があります。この層は通常、softmax活性化関数を使用し、可能なクラスにわたる確率分布を生成します。回帰タスクの場合、出力層は線形活性化関数を使用する場合があります。損失関数(クロスエントロピー、平均二乗誤差など)は、ネットワークの予測と正解の差を測定し、トレーニング中の最適化プロセスを指導します。
PythonでCNNの実装
このセクションでは、PyTorchフレームワークを使用して簡単なCNNを実装し、公開されているCIFAR-10データセットでトレーニングします。 CIFAR-10データセットは、10クラスの60,000枚の32x32カラー画像で構成されており、各クラスに6,000枚の画像が含まれています。 50,000枚のトレーニング画像と10,000枚のテスト画像があります。
まず、必要なライブラリをインポートします。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import torchvision.datasets as datasets
次に、CNNアーキテクチャを定義します。
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, padding=1)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, padding=1)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.fc1 = nn.Linear(64 * 8 * 8, 128)
self.relu3 = nn.ReLU()
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool1(self.relu1(self.conv1(x)))
x = self.pool2(self.relu2(self.conv2(x)))
x = x.view(x.size(0), -1)
x = self.relu3(self.fc1(x))
x = self.fc2(x)
return x
model = SimpleCNN()
損失関数、オプティマイザ、その他の設定を定義します。
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)
CIFAR-10データセットをロードしてデータを拡張します。
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=100, shuffle=True, num_workers=2)
test_loader = DataLoader(test_dataset, batch_size=100, shuffle=False, num_workers=2)
モデルをトレーニングします。
num_epochs = 10
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch {epoch + 1}, Loss: {running_loss / (i + 1)}")
テストデータセットでモデルのパフォーマンスを評価します。
model.eval()
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f"Accuracy of the model on the 10,000 test images: {100 * correct / total}%")
Epoch 1, Loss: 2.1893566000461577
Epoch 2, Loss: 1.9117810306549072
Epoch 3, Loss: 1.7671691884994507
Epoch 4, Loss: 1.662340677499771
Epoch 5, Loss: 1.5774701907634736
Epoch 6, Loss: 1.5232401647567748
Epoch 7, Loss: 1.4739297952651977
Epoch 8, Loss: 1.431945639371872
Epoch 9, Loss: 1.39970556807518
Epoch 10, Loss: 1.3656729533672334
Accuracy of the model on the 10,000 test images: 51.57%
CNNが「見る」ものを可視化
この章では、CNNが内部でどのように動作するかを、入力画像がレイヤーを通過する際に「見る」ものを可視化することによって理解します。公開データセットと、PyTorchを使用して、CNNの異なる深さでの視点を理解するのに役立つ可視化を作成します。
必要なライブラリをインポートし、CIFAR-10データセットをロードします。
import torch
import torchvision
import torchvision.transforms as transforms
# Data normalization
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# Load CIFAR-10 dataset
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=10,
shuffle=True, num_workers=2)
事前学習済みのCNNモデルのロード
可視化には、PyTorchが提供する事前学習済みのCNNモデルを使用します。人気があり、よく実行されるVGG16モデルを使用します。次のように、事前学習済みのVGG16モデルをロードします。
import torchvision.models as models
# Load the pre-trained VGG16 model
vgg16 = models.vgg16(pretrained=True)
CNNの視点を可視化
CNNが異なるレイヤーで「見る」ものを可視化するために、与えられたレイヤーから特徴マップを抽出し、それらを画像としてプロットする関数を作成します。次のコードは、PyTorchとmatplotlibを使用してこれを行う方法を示しています。
import matplotlib.pyplot as plt
import numpy as np
def visualize_layer(model, input_image, layer_index):
# Define a forward hook to extract the output of the target layer
def hook(module, input, output):
global layer_output
layer_output = output.detach()
# Register the forward hook
handle = model.features[layer_index].register_forward_hook(hook)
# Run the input image through the model
output = model(input_image.unsqueeze(0))
# Remove the forward hook
handle.remove()
# Plot the feature maps
num_feature_maps = layer_output.shape[1]
rows = int(np.sqrt(num_feature_maps))
cols = int(np.ceil(num_feature_maps / rows))
fig, axes = plt.subplots(rows, cols, figsize=(cols*2, rows*2))
for i in range(rows * cols):
ax = axes[i // cols, i % cols]
if i < num_feature_maps:
ax.imshow(layer_output[0, i].numpy(), cmap='gray')
ax.axis('off')
plt.show()
CIFAR-10データセットからサンプル画像を選択し、前処理します。
sample_image, label = trainset[0]
sample_image = (sample_image * 0.5 + 0.5).permute(1, 2, 0).numpy()
# Plot the original image
plt.imshow(sample_image)
plt.axis('off')
plt.show()
そして、VGG16モデルの異なるレイヤーの特徴マップを可視化します。
# Visualize the feature maps at layer 1 (first convolutional layer)
visualize_layer(vgg16, trainset[0][0], layer_index=0)
# Visualize the feature maps at layer 5 (fifth convolutional layer)
visualize_layer(vgg16, trainset[0][0], layer_index=4)
# Visualize the feature maps at layer 15 (fifteenth convolutional layer)
visualize_layer(vgg16, trainset[0][0], layer_index=14)



これらの可視化は、CNNがネットワーク内の異なる深さで入力画像を「見る」方法を示しています。初期のレイヤーでは、特徴マップはエッジ、コーナー、テクスチャなどの単純なパターンをキャプチャします。画像がレイヤーを進むにつれて、特徴マップはより抽象的で複雑になり、データセットの異なるクラスを識別するためにCNNが役立つ高次のパターンを表します。
参考
















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS