
バイアス・バリアンスのトレードオフとは
バイアス・バリアンスのトレードオフとは、バイアス(偏り)とバリアンス(分散)の最適なバランスを見つけ、予測誤差を最小限に抑えるプロセスです。一般的に、モデルの複雑さを増やすとバイアスは減りますが、バリアンスは増加し、モデルの複雑さを減らすとバイアスは増えますが、バリアンスは減少します。新しい未知のデータに対して最適なパフォーマンスを発揮するための適切なバランスを見つけることが必要です。
機械学習におけるバイアスとバリアンス
この章では、バイアスとバリアンスの概念について深く掘り下げ、明確な定義と直感的な例を紹介します。
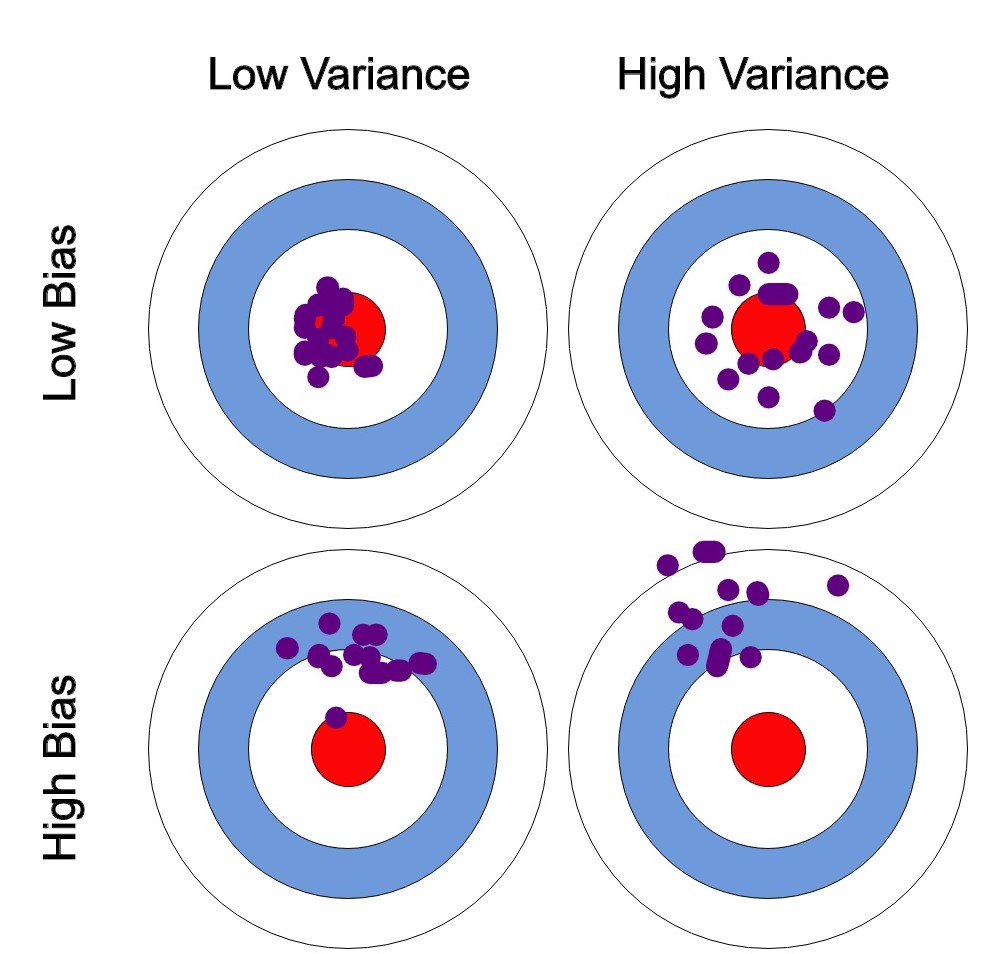
バイアス: システマティックエラー
バイアスは、現実世界の問題を単純化されたモデルで近似することによって導入されるエラーを指します。機械学習の文脈では、バイアスはモデルの予測が平均的に真の値とどの程度一致するかを測定します。高いバイアスのモデルはデータについて強い仮定をし、アンダーフィットの原因となり、モデルがデータの基本的なパターンを捉えるのに単純すぎる場合があります。
例えば、広さ、ベッドルーム数、場所などの特徴量を持つ住宅価格のデータセットを考えてみます。高いバイアスのモデルは、住宅価格が他の特徴量を無視して広さだけに依存すると仮定する場合があります。この過剰な簡略化は、モデルがベッドルーム数や場所の違いによる住宅価格の変動を捉えられないため、データに適合しない結果となる可能性があります。
バリアンス: ランダムエラー
一方、バリアンスは、モデルがトレーニングデータの小さな変動に対する敏感さによって導入されるエラーを指します。高いバリアンスのモデルは非常に柔軟で、トレーニングデータに非常に密接にフィットしますが、オーバーフィットの傾向があり、モデルがトレーニングデータに特化しすぎて、新しい未知のデータに対して性能が低下する可能性があります。
住宅価格の例に戻りますと、高いバリアンスのモデルは、利用可能な全ての特徴量とその複雑な相互作用を考慮して、トレーニングデータに非常に適合するかもしれません。しかし、このモデルは、外れ値や測定エラーなどのノイズに非常に敏感であるため、新しいデータに対して汎化性能が低く、以前に未知の住宅価格に対して性能が低下する可能性があります。
バイアス・バリアンス分解
バイアス・バリアンス分解は、機械学習モデルの総予測誤差を、バイアスとバリアンスの成分および削減できない誤差に分解するための技術です。総予測誤差は次の式で表されます。
バイアス項は、モデルの平均予測と真の値の二乗誤差を表します。バリアンス項は、データの小さな変動に対するモデルの感度を測定し、Irreducible Errorは、問題自体に固有の誤差であり、削減することはできません。
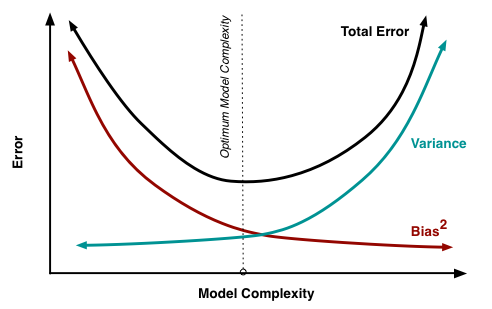
Understanding the Bias-Variance Tradeoff
トレードオフを管理するためのテクニック
この章では、バイアス・バリアンスのトレードオフを効果的に管理するためのさまざまなテクニックを紹介します。これらの戦略を採用することで、データサイエンティストは、バイアスとバリアンスの最適なバランスを見つけ、汎化性能を向上させ、新しい未知のデータに対するパフォーマンスを改善するモデルを構築できます。
正則化
正則化は、モデルの目的関数にペナルティ項を加えて、モデルの複雑さを制限することでオーバーフィットを防ぐための技術です。L1(Lasso)正則化とL2(Ridge)正則化の2つの一般的な正則化の種類があります。
正則化を組み込むことで、モデルの複雑さを制御し、オーバーフィットを緩和し、バイアスとバリアンスのバランスを改善することができます。
クロスバリデーション
クロスバリデーションは、データセットを複数のトレーニングセットと検証セットに分割して、機械学習モデルのパフォーマンスを評価する技術です。もっとも一般的なクロスバリデーションの形式は、データセットをk個の同じ大きさのフォールドに分割するk-foldクロスバリデーションです。モデルはk-1フォールドでトレーニングし、残りの1フォールドで検証され、このプロセスは、検証ごとに異なるフォールドを使用してk回繰り返されます。
クロスバリデーションにより、新しい未知のデータに対するモデルのパフォーマンスをより正確に評価し、異なるモデルやハイパーパラメータの設定を比較し、バイアスとバリアンスの最適なバランスを達成するモデルを選択することができます。
アンサンブル学習
アンサンブル学習は、複数のベースモデルの予測を組み合わせて、より正確で堅牢な全体的な予測を作成する技術です。バギング、ブースティング、スタッキングなど、いくつかの種類のアンサンブル学習手法があります。
アンサンブル学習技術は、高いバイアスと高いバリアンスの両方の効果を緩和し、両者のバランスを改善し、新しいデータに対するモデルのパフォーマンスを向上させることができます。
参考


















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS