
アンサンブル学習とは
アンサンブル学習とは、複数の学習アルゴリズムを組み合わせて予測性能を向上させる機械学習の手法です。異なるベースモデルの強みを活かし、個々の弱点を最小限に抑えることで、アンサンブル法は堅牢で正確な予測モデルを作成します。アンサンブル学習の主な技術は、バギング、ブースティング、スタッキングの3つです。
バギング、ブースティング、スタッキングの3つの主要なアンサンブル学習技術を理解して実装することにより、複雑な現実世界の問題に簡単に対処できる正確で安定した機械学習モデルを作成することができます。
モデルのバイアスと分散
バイアスと分散は、アンダーフィッティングとオーバーフィッティングのトレードオフを理解する上で重要な概念です。バイアスと分散がモデルの性能にどのように影響するかを理解することで、さまざまなタスクに適した最適なモデルやアンサンブル学習技術を選択できます。
- 高いバイアス
高いバイアスとは、モデルがデータの基本的なパターンを捉えられず、フィットが悪くなることを指します。これはモデルの単純さや適切でない仮定の使用に起因することがあります。モデルが高いバイアスを示すとき、データにアンダーフィットし、入力特徴量と目的変数の関係を十分に捉えることができません。
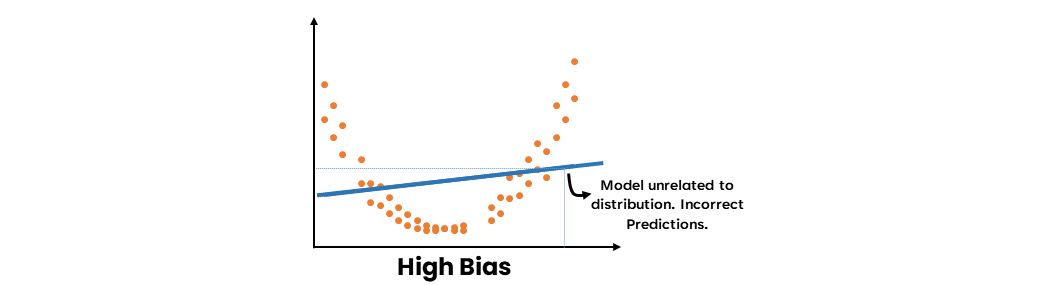
Ensemble Learning Methods: Bagging, Boosting and Stacking
- 高い分散
高い分散とは、トレーニングデータのわずかな変動に敏感なモデルのことで、オーバーフィットを引き起こします。オーバーフィットモデルは、トレーニングデータ上優れた性能を発揮しますが、新しい未知のデータには適用できません。モデルが高い分散を示すとき、データの基本的なパターンだけでなく、ノイズも捉えるため、テストデータセットでの性能に悪影響を与える可能性があります。
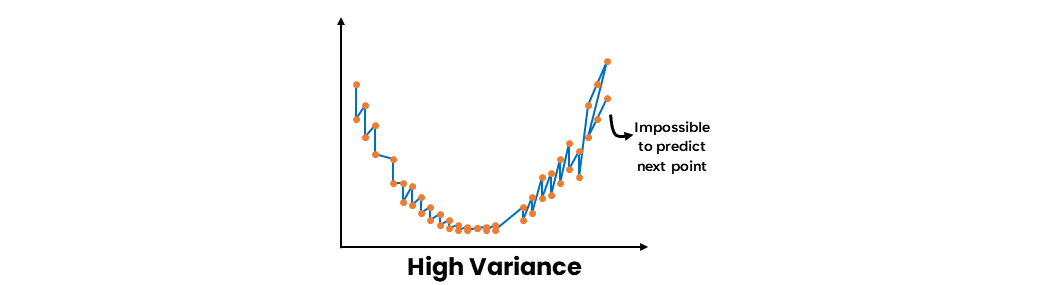
Ensemble Learning Methods: Bagging, Boosting and Stacking
バギング:ブートストラップ集約
バギングは、機械学習モデルの性能を改善するアンサンブル学習技術で、予測の分散を減らすことを目的としています。元のデータセットの異なるサブセットで複数のベースモデルを独立にトレーニングし、多数決(分類)または平均化(回帰)によりその予測を集約することで機能します。
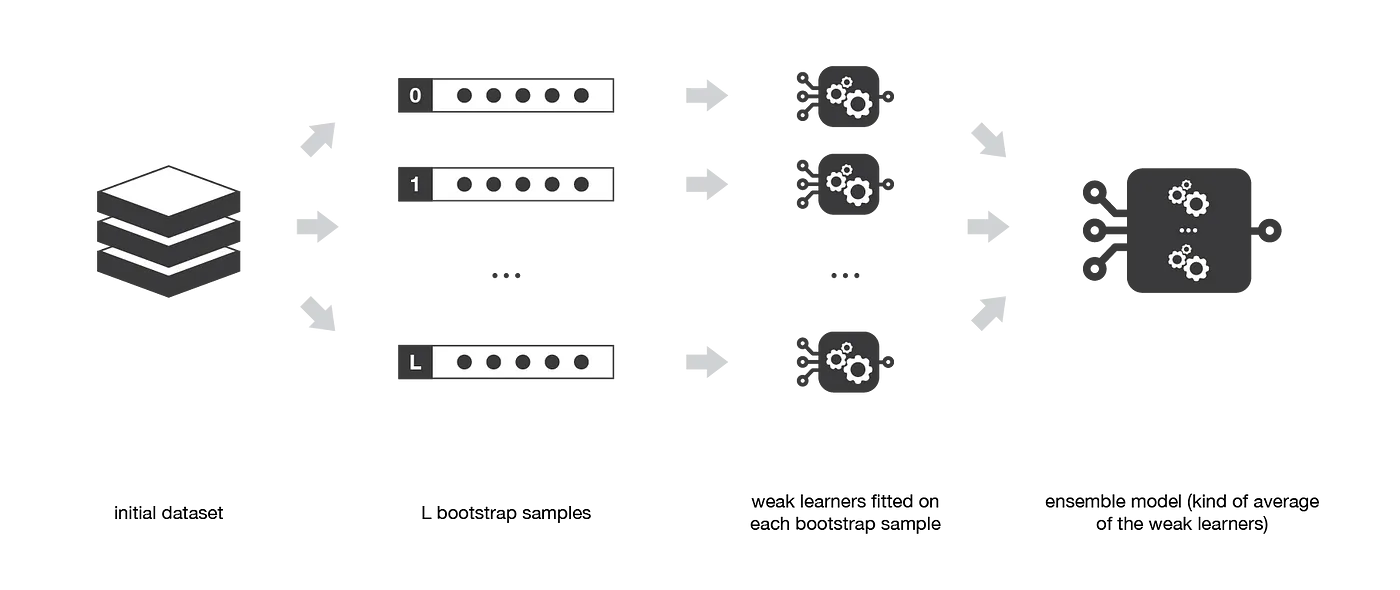
Ensemble methods: bagging, boosting and stacking
ブートストラップサンプル
ブートストラップサンプルとは、復元抽出によって得られた元のデータセットのランダムに選択されたサブセットです。バギングでは、それぞれのベース学習器が異なるブートストラップサンプルでトレーニングされるため、いくつかのデータポイントが複数回含まれたり、または一切含まれなかったりすることがあります。このプロセスにより、ベース学習器の多様性が導入され、最終的にアンサンブルの予測の分散が減少するのに役立ちます。

Ensemble Learning: Bagging, Boosting & Stacking
アルゴリズムと実装
バギングアルゴリズムは、次の手順で構成されています。
- 元のデータセットのn個のブートストラップサンプルを作成
- 各ブートストラップサンプルに対してベース学習器を独立にトレーニング
- 全てのベース学習器から予測を集約
以下は、バギングアルゴリズムの実装例です。
- ベース学習器の数とベース学習器のタイプ(決定木、ロジスティック回帰など)を初期化
- 各ベース学習器に対して、元のデータセットのブートストラップサンプルを作成
- 対応するブートストラップサンプルでベース学習器をトレーニング
- 全てのベース学習器に対して、手順2-3を繰り返す
- テストデータセットから各ベース学習器の予測を取得
- 最終的な予測を得るために、多数決(分類)または平均化(回帰)を使用して予測を集約
利点
- バギングは、複数のベース学習器の予測を平均化することによって、オーバーフィッティングを減らし、より正確で安定したモデルを提供します。
- 決定木などの不安定な学習器の性能を向上させるのに効果的です。
- バギングは、それぞれのベース学習器が独立にトレーニングされるため、並列化が容易です。
制限事項
- ベース学習器の選択とベース学習器の数は、アンサンブルの性能に大きく影響する可能性があります。
- バギングは主に分散を減らすことに焦点を当てているため、バイアスを減らす効果がない場合があります。
- 大規模なデータセットや複雑なベース学習器を使用する場合など、計算コストが高くなる可能性があります。
ブースティング:適応的アンサンブル学習
ブースティングは、連続的に弱い学習器をトレーニングすることで予測の精度を向上させるアンサンブル学習技術です。シーケンス内の各学習器は、前の学習器でのエラーを修正することを目的としています。ブースティングは、基本的な学習器が高いバイアスや低い精度を示す場合に特に適しており、バイアスを減らして予測力を向上させることを目的としています。
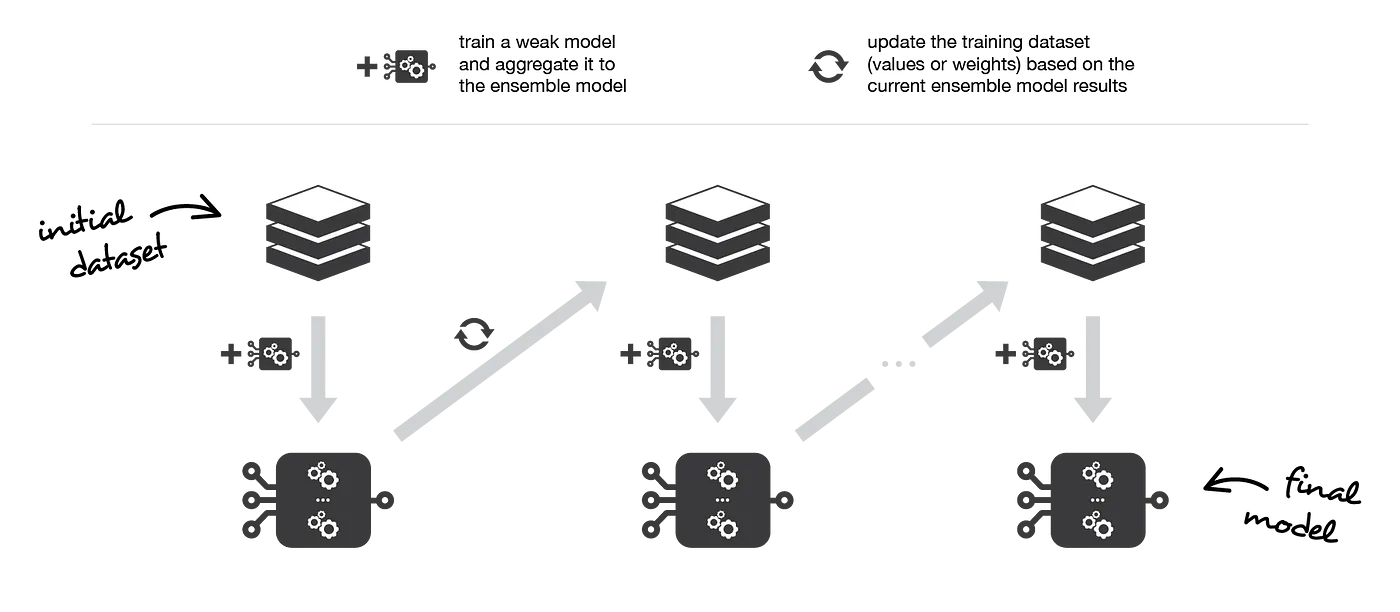
Ensemble methods: bagging, boosting and stacking
弱学習器
弱学習器とは、ランダムチャンスよりもわずかに正確な予測を生成できる比較的シンプルな機械学習モデルのことです。弱学習器は通常計算効率が高く、トレーニングが容易ですが、単純さによる予測力の制限がある場合があります。弱学習器の例には、決定スタンプ(単層の決定木)や浅い決定木があります。
ブースティングなどのアンサンブル学習技術の文脈では、弱学習器は組み合わせて強力な学習器を形成し、より正確で信頼性の高い予測を提供することができます。アンサンブルアプローチは、複数の弱学習器の強みを活用し、個々の制限を補償することによって、結合モデルの全体的な予測性能を高めます。
主要なアルゴリズム:AdaBoostとGradient Boosting
ブースティングファミリーの2つの人気のあるアルゴリズムは、AdaBoost(Adaptive Boosting)とGradient Boostingです。両方のアルゴリズムは、弱学習器のパフォーマンスを向上させることを目的としていますが、その目標を達成するためのアプローチには違いがあります。
-
AdaBoost
AdaBoostは、前の弱学習器でのエラーに基づいてトレーニングサンプルの重みを更新する反復アルゴリズムです。各反復では、前の学習器で誤分類されたサンプルに焦点を当てて、更新されたサンプルの重みで新しい弱学習器をトレーニングします。 -
Gradient Boosting
Gradient Boostingは、勾配降下法を使用して損失関数を最適化することによってブースティングの概念を拡張します。各反復では、新しい弱学習器がアンサンブルに追加され、その学習器の重みが全体の損失関数を最小化するように調整されます。
アルゴリズムと実装
以下はブースティングアルゴリズムの概要です。
- トレーニングサンプルの重みを均一に初期化
- 加重データセットで弱学習器をトレーニング
- 前の学習器でのエラーに基づいてサンプルの重みを更新
- 反復を望む回数だけステップ2〜3を繰り返す
- 弱学習器の予測を重み付き和または多数決で組み合わせる
ブースティングアルゴリズムを実装するには、次の手順を実行します。
- 弱学習器の数とベース学習器のタイプ(決定木、ロジスティック回帰など)を選択
- サンプルの重みを均等に初期化
- 各弱学習器に対して:
- 加重データセットでベース学習器をトレーニング
- ベース学習器のエラー率を計算
- エラー率に基づいてサンプルの重みを更新
- サンプルの重みを正規化
- テストデータセットの各弱学習器から予測を取得
- 重み付き和(回帰)または多数決(分類)を使用して予測を組み合わせ、最終的な予測を取得
利点
- ブースティングは、難しいサンプルに焦点を当ててバイアスを減らし、弱学習器の精度を大幅に向上させることができます。
- Baggingに比べて過剰適合しにくいため、モデルの安定性が高いです。
- ブースティングは、決定木など、さまざまなベース学習器タイプに適用できるため、汎用性が高いアンサンブル学習技術です。
制限事項
- ブースティングは、雑音や外れ値に敏感であり、難しいサンプルに焦点を当てる傾向があるため、不安定な結果を引き起こすことがあります。
- 多数の弱学習器や複雑なベース学習器を使用する場合、計算量が増加することがあります。
- 弱学習器の数やベース学習器のタイプの選択は、アンサンブルのパフォーマンスに重大な影響を与える可能性があります。
スタッキング:学習器の結合
スタッキング (Stacking) またはスタックド一般化 (Stacked Generalization) とは、複数のベース学習器を予測値に基づいてメタモデルをトレーニングすることで結合し、各ベース学習器の強みを生かしながら弱点を補うアンサンブル学習のテクニックです。複数のベース学習器の予測から学習することで、単独のモデルより高い予測精度を達成することができます。
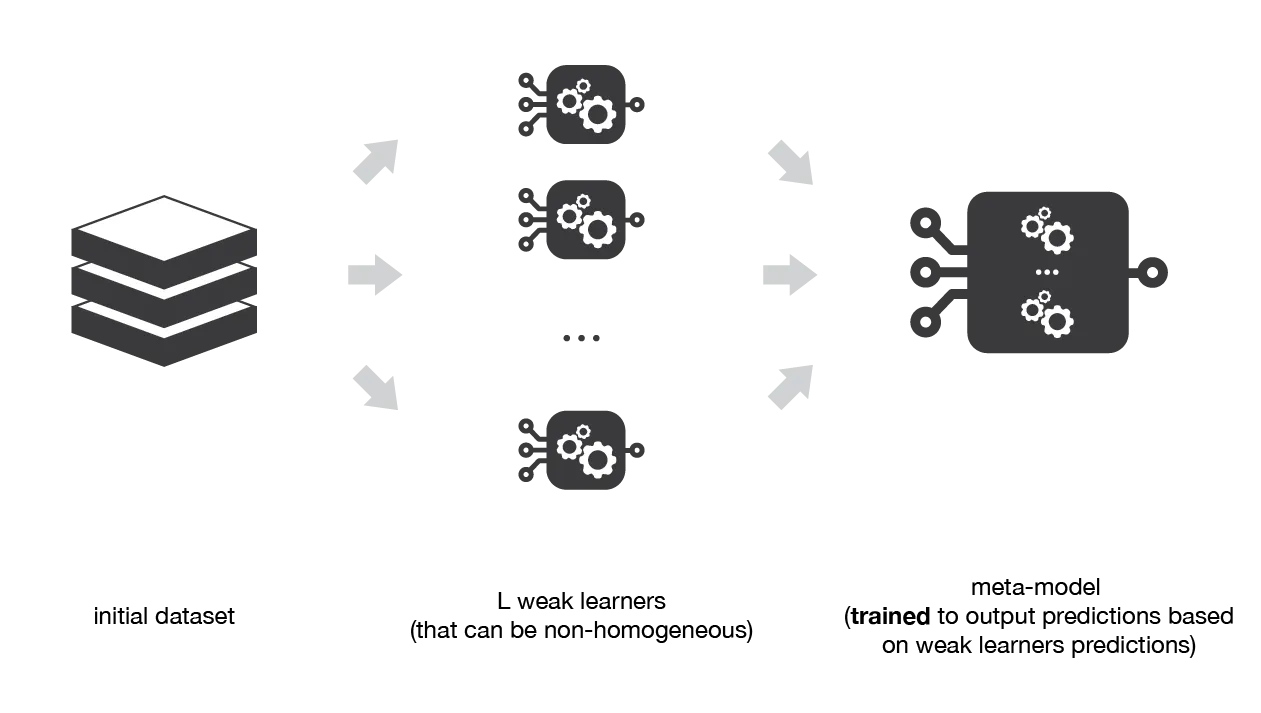
Ensemble methods: bagging, boosting and stacking
アルゴリズムと実装
スタッキングアルゴリズムは次の手順に分解できます。
- データセットをトレーニングセットと検証セットに分割
- トレーニングセットでベース学習器をトレーニング
- 各ベース学習器から検証セットの予測を取得
- ステップ3の予測をメタモデルのトレーニングに使用
- テストデータセットでベース学習器とメタモデルの予測を取得
以下はスタッキングアルゴリズムの実装例です。
- ベース学習器の数、ベース学習器のタイプ、およびメタモデル(ロジスティック回帰、決定木など)を選択
- データセットをトレーニングセットと検証セットに分割
- トレーニングセットで各ベース学習器をトレーニング
- 各ベース学習器から検証セットの予測を取得
- ステップ4の予測を特徴量としてメタモデルをトレーニング
- 各ベース学習器からテストデータセットの予測を取得
- ステップ6の予測を特徴量としてメタモデルから最終予測を取得
利点
- スタッキングは、異なるベース学習器の強みを活用し、個々のモデル単体よりも高い予測精度を達成することができます。
- さまざまなベース学習器タイプとメタモデルに適用できるため、汎用的なアンサンブル学習テクニックです。
- スタッキングは、個々のベース学習器の弱みを軽減し、より堅牢で信頼性の高い予測をもたらすことができます。
制限事項
- スタッキングは計算量が多くなることがあります。特に、複数のベース学習器や複雑なメタモデルを使用する場合はそうです。
- ベース学習器、メタモデルの選択、およびベース学習器の数は、アンサンブルの性能に大きな影響を与えることがあります。
- 複雑なメタモデルや不十分な検証データを使用する場合、過剰適合する可能性があります。
テクニックの比較:バギング、ブースティング、スタッキング
性能指標
アンサンブル学習テクニックを比較する場合、その効果を評価するためにさまざまな性能指標を考慮することが重要です。一般的な指標には以下があります。
-
正解率
全予測のうち正解の割合 -
適合率、再現率、F1スコア
特に不均衡なデータセットの分類性能をより包括的に評価するための指標 -
平均二乗誤差(MSE)または平方根平均二乗誤差(RMSE)
回帰タスクにおける予測値と実際の値の差を測定するための指標 -
ROC曲線下の面積(AUC-ROC)
真陽性率と偽陽性率のトレードオフを測定する指標
異なるタスクに対する適用性
各アンサンブル学習テクニックには独自の特性があり、それぞれ異なるタスクに適しています。
-
バギング
バギングは、不安定な学習器(決定木など)の安定性を向上させ、過学習を減らすためにもっとも効果的です。ベース学習器の分散が高いタスクに適しています。 -
ブースティング
ブースティングは、バイアスを減らして弱い学習器の精度を向上させるように設計されています。ベース学習器が高いバイアスまたは低い精度を示すタスクに適しています。 -
スタッキング
スタッキングは、複数のベース学習器の強みを活用することで、より優れた予測を導くタスクに適しています。さまざまなベース学習器タイプとメタモデルに適用できるため、汎用的なテクニックです。
計算量
アンサンブル学習テクニックの計算量は、ベース学習器の数、ベース学習器のタイプ、およびメタモデル(スタッキングの場合)に依存します。
-
バギング
バギングは簡単に並列化できます。それぞれのベース学習器は独立してトレーニングされます。ただし、大量のベース学習器や複雑なベース学習器を使用する場合は、計算量が多くなることがあります。 -
ブースティング
ブースティングは、ベース学習器を順次トレーニングするため、計算量が多くなることがあります。複数の弱学習器や複雑なベース学習器を使用する場合、計算量が増加する傾向があります。 -
スタッキング
スタッキングは、複数のベース学習器と複雑なメタモデルを使用する場合、計算量が多くなることがあります。さらに、データセットをトレーニングセットと検証セットに分割する必要があるため、計算コストが増加することがあります。
参考


















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS