


Apa itu model statistik
Model statistik adalah model matematika yang menjelaskan pola atau hukum tentang data yang diamati. Model ini memilih distribusi probabilitas sesuai dengan karakteristik data dan mengestimasi parameter distribusi probabilitas yang dapat menjelaskan data yang diamati dengan baik.
Estimasi parameter
Saya akan melakukan estimasi parameter dalam Python untuk data sampel berikut dengan ukuran sampel 50.
data = [2,2,4,6,4,5,2,3,1,2,0,4,3,3,3,3,4,2,7,2,4,3,3,3,4,
3,7,5,3,1,7,6,4,6,5,2,4,7,2,2,6,2,4,5,4,5,1,3,2,3]
Investigasi data
Pertama, mari kita lihat histogram dari data.
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
plt.style.use('ggplot')
plt.figure(figsize=(10,5))
data = [2,2,4,6,4,5,2,3,1,2,0,4,3,3,3,3,4,2,7,2,4,3,3,3,4,
3,7,5,3,1,7,6,4,6,5,2,4,7,2,2,6,2,4,5,4,5,1,3,2,3]
plt.hist(data, bins = [-0.5 + v for v in range(max(data) + 2)], alpha=0.5, rwidth=0.95)
plt.xlabel('data')
plt.ylabel('Frequency')
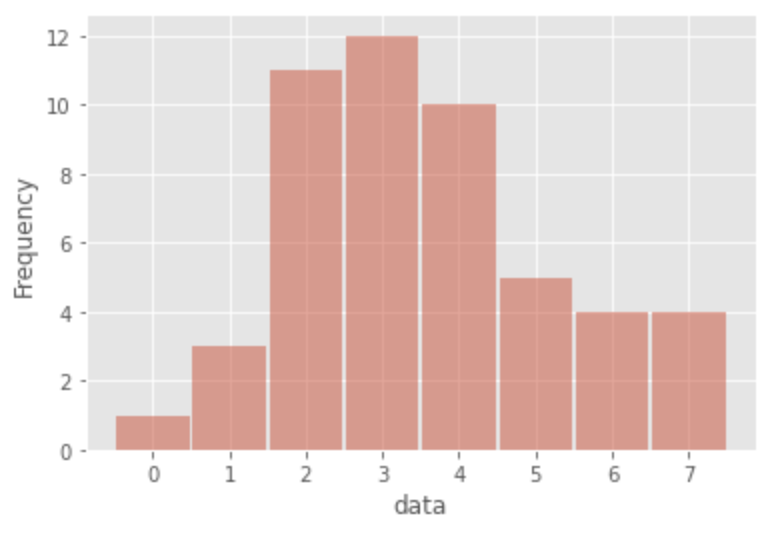
Berikutnya mari kita lihat ringkasan data.
import pandas as pd
df = pd.DataFrame(data, columns=['x'])
df.describe()
| x | |
|---|---|
| count | 50.00000 |
| mean | 3.56000 |
| std | 1.72804 |
| min | 0.00000 |
| 25% | 2.00000 |
| 50% | 3.00000 |
| 75% | 4.75000 |
| max | 7.00000 |
Mari kita lihat varians sampel.
# sample variabce
df.var()
2.986122
Survei ini mengonfirmasi hal-hal berikut ini:
- Distribusi seperti gunung
- Data adalah data hitungan (bilangan bulat non-negatif)
- Rata-rata sampel adalah 3,56
- Varians sampel adalah 2,99
Asumsi distribusi probabilitas
Dari data sampel, kita asumsikan distribusi probabilitas yang diikuti oleh populasi. Kita mengetahui hal-hal berikut ini tentang data sampel.
- Data adalah data hitungan
- Batas bawah adalah 0 tetapi batas atas tidak diketahui
- Rata-rata sampel adalah 3,56 dan varians sampel adalah 2,99, yang relatif dekat
Dari karakteristik di atas, kita asumsikan sebuah [distribusi Poisson] (/en/articles/poisson-distribution) dengan
Distribusi Poisson vs. distribusi sampel
Visualisasikan distribusi Poisson dari
fig, ax1 = plt.subplots()
plt.hist(data, bins = [-0.5 + v for v in range(max(data) + 2)], alpha=0.5, rwidth=0.95)
poisson_values = poisson.rvs(3.56, size=10000)
prod = (pd.value_counts(poisson_values) / 10000).sort_index()
ax2 = ax1.twinx()
ax2.plot(prod)
plt.show()
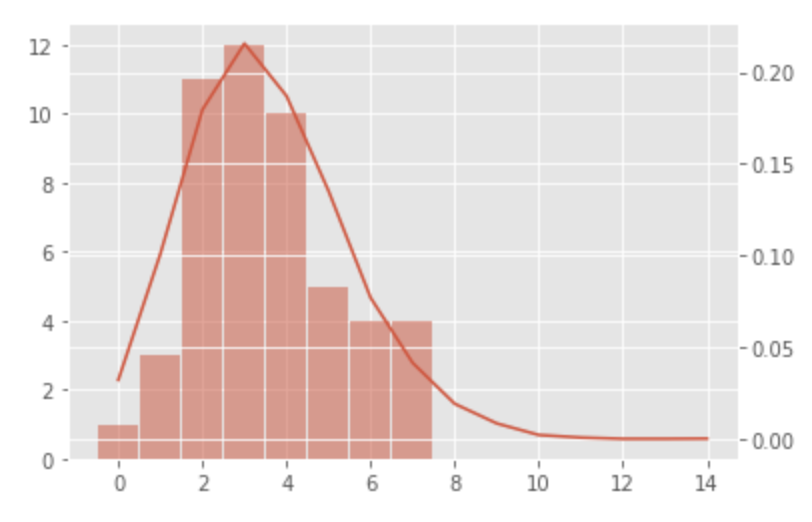
Tampak bahwa distribusi data sampel dapat diwakili oleh distribusi Poisson dengan
Estimasi parameter dari distribusi probabilitas yang diasumsikan
Parameter distribusi probabilitas diestimasi berdasarkan data sampel. Di sini kita menggunakan metode estimasi parameter yang disebut maximum likelihood estimation.
Maximum likelihood estimation adalah metode estimasi parameter yang mencari parameter yang memaksimalkan likelihood, sebuah statistik yang menyatakan seberapa baik parameter tersebut sesuai dengan data yang diamati. Dalam hal ini, parameternya adalah
Likelihood adalah hasil kali dari probabilitas untuk semua data sampel. Likelihood adalah fungsi dari parameter, dilambangkan dengan
di mana
Kita memeriksa
Gambar berikut ini menunjukkan bentuk distribusi dan nilai
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import sympy
from scipy.stats import poisson
%matplotlib inline
plt.style.use('ggplot')
plt.figure(figsize=(10,5))
lams = np.arange(3.2,4.5,0.4)
for i, lam in enumerate(lams):
log_l = 0
for y in data:
f = (lam**y)*sympy.exp(-lam)/sympy.factorial(y)
logf=sympy.log(f)
log_l = log_l + logf
fig, ax = plt.subplots()
ax.hist(data, bins = [-0.5 + v for v in range(max(data) + 2)], alpha=0.5, rwidth=0.95)
poisson_values = poisson.rvs(lam, size=10000)
prod = (pd.value_counts(poisson_values) / 10000).sort_index()
ax2 = ax.twinx()
ax2.plot(prod, label=f'lambda={round(lam, 1)}, log L={round(log_l, 1)}')
plt.legend()
plt.show()
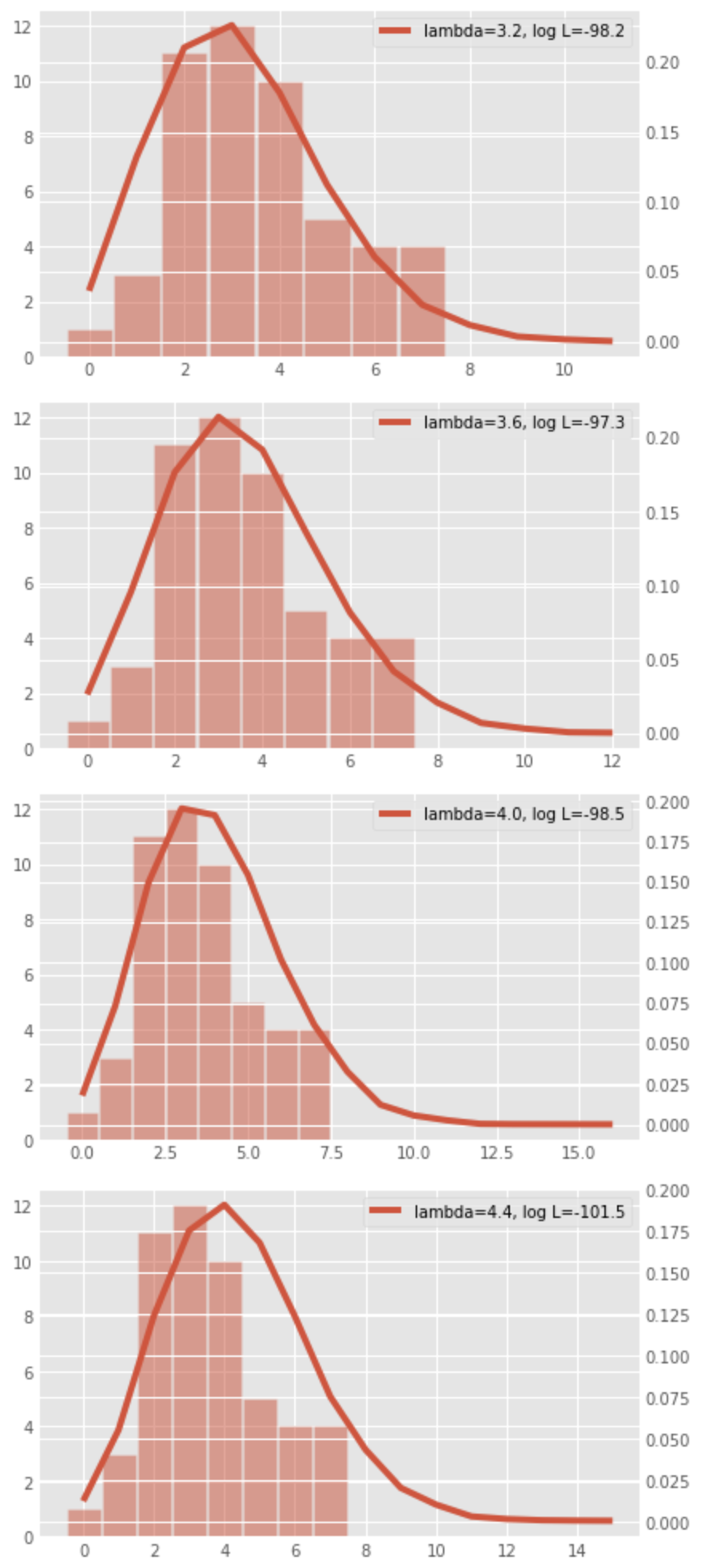
Kita dapat melihat bahwa log-likelihood kemungkinan akan dimaksimalkan di sekitar
Untuk memperoleh log likelihood maksimum, kita dapat menemukan
Menghitung persamaan di atas, kita melihat bahwa kemungkinan dimaksimalkan ketika
Distribusi probabilitas mana yang harus digunakan untuk model statistik
Ketika memilih distribusi probabilitas untuk model statistik untuk menjelaskan data yang diamati, poin-poin berikut perlu diperiksa:
- Jenis data (diskrit atau kontinu)
- Rentang data
- Hubungan antara varians sampel dan rata-rata sampel
Untuk beberapa distribusi probabilitas, kondisi yang diperlukan yang dapat digunakan sebagai distribusi probabilitas untuk model statistik adalah sebagai berikut.
| Jenis data | Rentang data | Hubungan antara varians sampel |
Distribusi probabilitas |
|---|---|---|---|
| Diskrit | Distribusi Poisson | ||
| Diskrit | Distribusi binomial negatif | ||
| Diskrit | Distribusi binomial | ||
| Kontinu | Distribusi normal | ||
| Kontinu | Distribusi log-normal | ||
| Kontinu | Distribusi gamma | ||
| Kontinu | Distribusi beta |
















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS