


はじめに
この記事では、LightGBMのインストールプロセス、基本的なワークフローについて説明します。
インストールとセットアップ
LightGBMをインストールする前に、システムが次の要件を満たしていることを確認してください。
- Python 3.6以上
- NumPyおよびSciPy
- scikit-learn(オプションで、追加の機能を提供します)
pipを使用してLightGBMをインストールできます。
$ pip install lightgbm
LightGBMの基本的なワークフロー
公開データセットでモデルをトレーニングするLightGBMの基本的なワークフローを説明します。 scikit-learnライブラリを介して利用可能なIrisデータセットを使用します。
from sklearn import datasets
iris = datasets.load_iris()
X, y = iris.data, iris.target
scikit-learnを使用して、データをトレーニング用とテスト用に分割します。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
LightGBM Datasetの作成
トレーニングデータをLightGBM Datasetオブジェクトに変換する必要があります。このオブジェクトは、LightGBMとの使用に特化しており、大規模なデータセットや高度な機能の効率的な処理を可能にします。
import lightgbm as lgb
train_data = lgb.Dataset(X_train, label=y_train)
モデルパラメータの設定
モデルをトレーニングする前に、モデルパラメータを指定する必要があります。これらのパラメータは、目的関数、クラス数、ブースティングの種類、および学習率など、モデルのさまざまな側面を制御します。
params = {
'objective': 'multiclass',
'num_class': 3,
'metric': 'multi_logloss',
'boosting_type': 'gbdt',
'learning_rate': 0.05,
}
モデルのトレーニング
トレーニングデータと指定されたパラメータを使用して、LightGBMモデルをトレーニングできます。 num_boost_roundパラメータは、ブースティングのラウンド数を制御し、モデルの複雑さと性能に影響を与えます。
model = lgb.train(params, train_data, num_boost_round=100)
モデルパフォーマンスの評価
テストセット上でモデルのパフォーマンスを評価します。
from sklearn.metrics import accuracy_score
import numpy as np
y_pred = model.predict(X_test)
y_pred = [np.argmax(row) for row in y_pred]
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
Accuracy: 1.0
予測
トレーニング済みモデルを使用して予測します。
sample = X_test[0]
predicted_class = model.predict([sample])
print("Predicted class:", np.argmax(predicted_class))
Predicted class: 1
LightGBMのAPI
この章では、LightGBM APIについて詳しく説明し、その主要な機能を紹介します。LightGBM分類器と回帰器、ハイパーパラメータの調整、クロスバリデーション、不均衡なデータの処理、および早期停止について説明します。
LightGBM分類器
LightGBM分類器は、GBDTアルゴリズムの分類タスク用の実装です。APIの中で、LGBMClassifierとして使用できます。使用するには、クラスをインポートし、所望のモデルパラメータでインスタンスを作成します。
from lightgbm import LGBMClassifier
clf = LGBMClassifier(boosting_type='gbdt', num_leaves=31, learning_rate=0.05, n_estimators=100)
clf.fit(X_train, y_train)
LightGBM回帰器
回帰タスクの場合、LightGBMはLGBMRegressorクラスを提供しています。LGBMClassifierに似て、回帰器のインスタンスを所望のモデルパラメータで作成できます。
from lightgbm import LGBMRegressor
reg = LGBMRegressor(boosting_type='gbdt', num_leaves=31, learning_rate=0.05, n_estimators=100)
reg.fit(X_train, y_train)
クロスバリデーション
クロスバリデーションは、機械学習モデルのパフォーマンスをより信頼性の高い方法で評価するために使用されるテクニックです。LightGBMは、与えられたデータセットとモデルパラメータを使用してk分割交差検証を実行するcv関数を提供します。
from sklearn.model_selection import KFold
kf = KFold(n_splits=5, shuffle=True, random_state=42)
lgb_cv = lgb.cv(params, train_data, num_boost_round=100, folds=kf, early_stopping_rounds=10)
不均衡なデータの処理
LightGBMは、class_weightパラメータの調整によって不均衡なデータの処理を組み込んでいます。クラスの重みを'balanced'に設定することで、クラスごとのサンプル数に基づいて重みを自動的に調整できます。
clf = LGBMClassifier(boosting_type='gbdt', class_weight='balanced')
clf.fit(X_train, y_train)
早期停止
過学習を避け、トレーニング時間を短縮するために、早期停止を使用することができます。早期停止は、検証セットでのパフォーマンスが指定されたブースティングラウンドの数の間改善しなかった場合、トレーニングプロセスを停止します。
model = lgb.train(params, train_data, num_boost_round=1000, valid_sets=[train_data], early_stopping_rounds=10)
GPUアクセラレーション
LightGBMは、トレーニングプロセスを大幅に高速化できるGPUアクセラレーションをサポートしています。GPUアクセラレーションを有効にするには、適切なGPUバージョンのLightGBMをインストールし、モデルパラメータでdeviceパラメータを'gpu'に設定する必要があります。
params = {
'device': 'gpu',
# Other parameters...
}
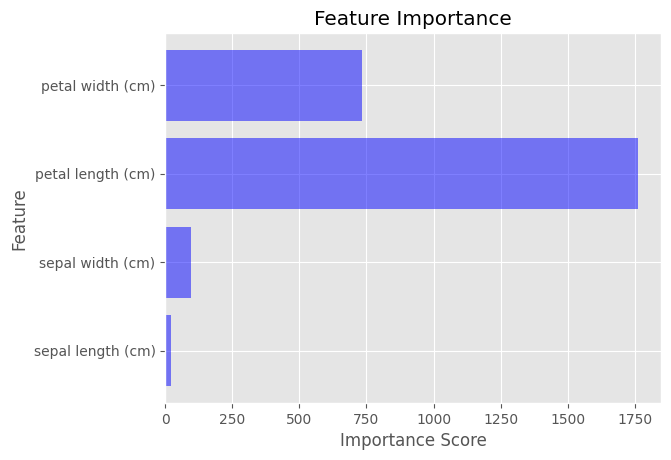
LightGBMのFeature Importance
LightGBMモデルをトレーニングした後、feature_importance()メソッドを使用してFeature Importanceを計算できます。このメソッドは、データセット内の各Feature Importanceスコアの配列を返します。
importance_scores = model.feature_importance(importance_type='gain')
Feature Importanceを視覚化するには、Matplotlibを使用して、各Feature Importanceスコアを示す棒グラフを作成できます。
import matplotlib.pyplot as plt
plt.style.use('ggplot')
feature_names = iris.feature_names
plt.barh(feature_names, importance_scores, color='blue', alpha=0.5)
plt.xlabel('Importance Score')
plt.ylabel('Feature')
plt.title('Feature Importance')
plt.show()
分散学習
分散学習により、複数のマシンでLightGBMモデルをトレーニングすることができます。これは、非常に大きなデータセットを扱う場合に役立ちます。LightGBMは、MPI、ソケット、Hadoopなど、さまざまな分散学習セットアップをサポートしています。分散学習を有効にするには、モデルパラメータでmachinesパラメータを設定し、特定の分散学習セットアップを使用する必要があります。
LightGBMで分散学習を設定する詳細については、公式ドキュメントを参照してください。
















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS