


LightGBMとは
LightGBMは、Microsoftによって開発された高速で分散処理が可能な高性能勾配ブースティングライブラリで、Light Gradient Boosting Machineの略称です。大規模なデータセットと高次元の特徴空間を効率的に扱えるように設計されており、回帰、分類、ランキング問題を含む様々な機械学習タスクに最適な選択肢となります。
LightGBMのユニークな機能と利点
LightGBMは、他の勾配ブースティングライブラリに対していくつかの重要な機能と利点を提供しています。
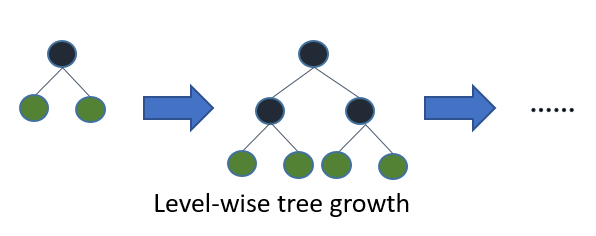
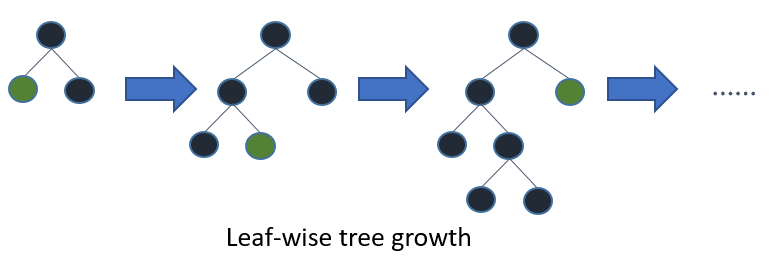
Leaf-wise Tree Growth
従来の勾配ブースティングアルゴリズムは、レベルごと(Level-wise)に木を成長させ、同じレベルの全てのノードが次のレベルのノードよりも先に分割されます。一方、LightGBMは、損失削減がもっとも高いノードを優先的に分割する葉ごと(Leaf-wise)の成長戦略を採用しています。この方法により、より高速な収束と改善されたモデルの精度が実現できますが、適切に制御されていない場合は過学習のリスクがあります。
ヒストグラムベースのアルゴリズム
LightGBMは、トレーニングプロセスの高速化にヒストグラムベースのアルゴリズムを使用しています。連続した特徴量値を離散的なビンに分割して近似し、評価する分割点の数を減らします。このアプローチにより、従来の勾配ブースティング法と比較して、トレーニング時間とメモリ使用量を大幅に削減できます。
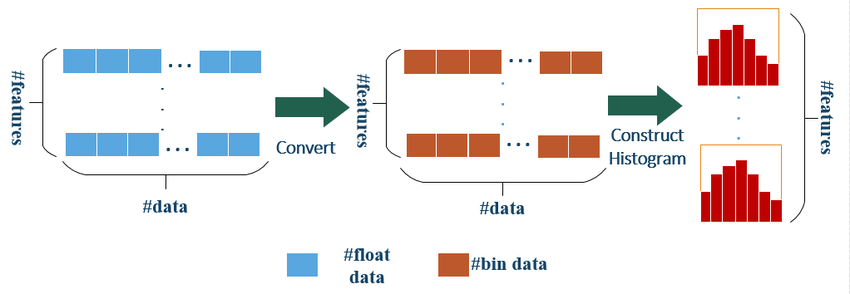
Histogram algorithm of LightGBM
カテゴリカル特徴量のサポート
他の勾配ブースティングライブラリとは異なり、LightGBMはカテゴリカル特徴量のネイティブサポートを提供しており、ワンホットエンコーディングやその他の前処理手順が不要です。最適な分割点を使用することにより、LightGBMは高基数のカテゴリカル変数を効率的に扱えるため、モデルのパフォーマンスが向上し、特徴量エンジニアリングのプロセスが簡素化されます。
効率的な並列学習
LightGBMは、データと特徴量の並列性の両方をサポートし、マルチコアCPUや分散システムで効率的な並列学習を可能にします。この機能により、LightGBMは大規模なデータセットと高次元の特徴空間にスケーリングすることができ、幅広いアプリケーションに適しています。
Gradient-based One-Side Sampling (GOSS)
トレーニングプロセスをさらに加速するために、LightGBMはGradient-based One-Side Sampling (GOSS)という新しいサンプリングテクニックを導入しています。GOSSは、勾配の大きさに基づいて各反復でトレーニングデータのサブセットを選択的にサンプリングします。全体の損失にもっとも貢献する勾配が大きいインスタンスが優先され、データの多様性を維持するために勾配が小さいインスタンスのランダムなサブセットも含まれます。このアプローチにより、もっとも情報量の高いサンプルを保持しながら、トレーニングの計算コストを削減し、より速い収束と改善されたモデルのパフォーマンスが実現できます。

An Example of Hyperparameter Optimization on XGBoost, LightGBM and CatBoost using Hyperopt
Exclusive Feature Bundling (EFB)
LightGBMのもう一つのユニークな機能は、Exclusive Feature Bundling (EFB)です。EFBは、スパースなデータセットの次元数を減らすことを目的としています。EFBは、同時に非ゼロ値を取らない特徴のセットを識別し、それらを1つの特徴としてバンドル化します。このバンドル化プロセスにより、特徴空間を情報の損失なく効果的に圧縮でき、より効率的な木の構築とメモリ使用量の削減が可能となります。EFBは、テキストやクリックスルー率予測タスクで一般的に見られる高次元スパースなデータセットを扱う場合に特に有用です。
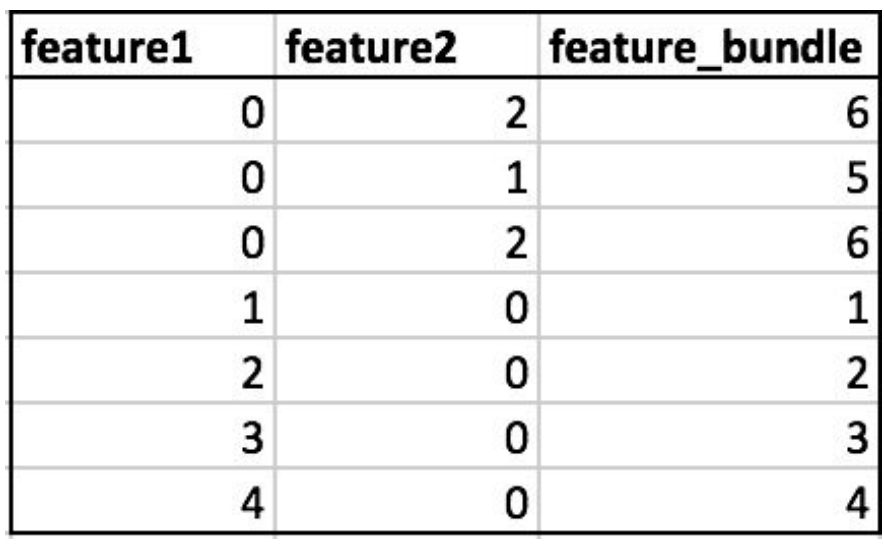
Comparing lightgbm to other R GBDT libraries
XGBoostとの比較
XGBoostとLightGBMは、大規模なデータセットに対して高性能かつスケーラブルなデータ分析を提供するように設計されています。しかし、ヒストグラムベースのアルゴリズム、葉ごとの木の成長、GOSS、EFBなどの特徴により、LightGBMはしばしばトレーニング速度とメモリ使用量でXGBoostを上回ります。これらの機能により、LightGBMはXGBoostよりも効率的に大規模なデータセットと高次元特徴空間を扱うことができます。
ただし、パフォーマンスは特定の問題やデータセットによって異なるため、場合によってはXGBoostがより高い精度を提供し、LightGBMがより速いトレーニング時間を提供することもあります。データセットに対して両方のライブラリを試して、特定のケースに最適なパフォーマンスを提供するライブラリを選択することをお勧めします。
利用のしやすさ
XGBoostとLightGBMはどちらもユーザーフレンドリーなインターフェイスを提供しており、scikit-learn、Keras、TensorFlowなどの人気のある機械学習ライブラリと簡単に統合できます。両ライブラリとも包括的なドキュメンテーションとアクティブなコミュニティサポートを提供しており、全ての経験レベルのユーザーにアクセスしやすくなっています。
ユニークな機能
両ライブラリは多くの共通の機能を共有していますが、それらを区別するユニークな機能もあります。LightGBMの主なユニークな機能には、以下が含まれます。
- Leaf-wise Tree Growth
- Gradient-based One-Side Sampling (GOSS)
- Exclusive Feature Bundling (EFB)
- カテゴリカル特徴量のネイティブサポート
一方、XGBoostは次のユニークな機能を提供しています。
- 外部メモリのためのカラムブロック
- 欠損値の組み込みサポート
- 正則化された学習目的
- 木の分割における単調制約
参考
















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS