


はじめに
XGBoostは、勾配ブースティングアルゴリズムの効率的で使いやすい実装を提供するオープンソースのソフトウェアライブラリです。スケーラブルで高パフォーマンスで設計されており、XGBoostはデータサイエンティストや機械学習実践者の間で人気が高まり、機械学習のさまざまな問題に対して最先端の結果を提供する能力で知られています。
この記事では、XGBoostのインストールとセットアップの手順、基本的なワークフローとAPIの紹介、そしてXGBoostモデルにおける特徴の重要性の探索について説明します。
インストールとセットアップ
XGBoostをインストールする前に、システムに次のソフトウェアがインストールされていることを確認してください。
- Python 3.6以降
- NumPy
- SciPy
- scikit-learn
XGBoostをインストールするには、ターミナルまたはコマンドプロンプトで次のコマンドを実行するだけです。
$ pip install xgboost
基本的なXGBoostワークフロー
この章では、基本的なXGBoostワークフローについて説明します。公開データセットを読み込み、データの前処理、トレーニングおよびテスト分割の作成、モデルの定義とトレーニング、そしてパフォーマンスの評価を含みます。
公開データセットの読み込み
XGBoostの実装には、scikit-learnに含まれる有名なアヤメデータセットを使用します。このデータセットには、アヤメの花のサンプルが150個含まれており、それぞれが4つの特徴(がくの長さ、がくの幅、花弁の長さ、花弁の幅)と対応するクラスラベル(setosa、versicolor、またはvirginica)を持っています。
まず、必要なライブラリをインポートし、データセットを読み込みます。
import numpy as np
import pandas as pd
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
データの前処理
XGBoostモデルに進む前に、データの前処理が重要です。この場合、対象変数(クラスラベル)のラベルエンコーディングのみを実行して、整数値に変換します。
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
y_encoded = encoder.fit_transform(y)
トレーニングおよびテスト分割の作成
XGBoostモデルのパフォーマンスを評価するために、データセットをトレーニングセットとテストセットに分割する必要があります。トレーニングにはデータの80%、テストには残りの20%を使用します。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y_encoded, test_size=0.2, random_state=42)
モデルの定義とトレーニング
データが準備できたので、XGBoostモデルを定義できます。この問題は分類問題なので、XGBClassifierクラスを使用します。
from xgboost import XGBClassifier
model = XGBClassifier()
model.fit(X_train, y_train)
モデルの評価と予測
XGBoostモデルがトレーニングされたので、テストデータセットでのパフォーマンスを評価し、予測を行うことができます。評価メトリックには正解率を使用します。
from sklearn.metrics import accuracy_score
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Model accuracy: {accuracy:.2f}")
Model accuracy: 1.00
XGBoostのAPI
この章では、XGBoostのAPIに深く入り込んで、XGBClassifierおよびXGBRegressorクラス、DMatrixデータ構造、クロスバリデーション、早期停止、およびカスタム評価メトリックなど、いくつかの強力な機能を紹介します。
XGBClassifierおよびXGBRegressorクラス
XGBoostでは、勾配ブースティングモデルを実装するための2つの主要なクラスが用意されています。分類問題にはXGBClassifier、回帰問題にはXGBRegressorを使用します。両方のクラスには、次のようなハイパーパラメータが用意されており、モデルのパフォーマンスを微調整することができます。
n_estimators: ブースティングラウンドの回数(デフォルト: 100)learning_rate: 過剰適合を防止するために使用される更新ステップの縮小サイズ(デフォルト: 0.3)max_depth: ツリーの最大深度(デフォルト: 6)subsample: 個々の基本学習者に適合するために使用されるサンプルの割合(デフォルト: 1)colsample_bytree: ブースティングラウンドごとに選択する特徴量の割合(デフォルト: 1)
DMatrixデータ構造
XGBoostは、データセットを内部的に保存するためにDMatrixと呼ばれるカスタムデータ構造を使用しています。 DMatrixフォーマットは、メモリ効率とトレーニング速度の両方に最適化されています。DMatrixを作成するには、次のコードを使用できます。
import xgboost as xgb
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)
DMatrixフォーマットを使用する場合、XGBoostのネイティブAPIを使用してトレーニングと予測を行うことができます。
params = {'objective': 'multi:softmax', 'num_class': 3}
model = xgb.train(params, dtrain, num_boost_round=100)
y_pred = model.predict(dtest)
XGBoostにおけるクロスバリデーション
XGBoostは、k分割交差検証を実行するための組み込み機能を提供しており、モデルのハイパーパラメータを微調整し、そのパフォーマンスを評価するのに役立ちます。クロスバリデーションを実行するには、cv関数を使用します。
cv_results = xgb.cv(params, dtrain, num_boost_round=100, nfold=5, metrics='merror', early_stopping_rounds=10)
ここで、nfoldはクロスバリデーションのフォールド数を指定し、metricsは使用する評価メトリックで、early_stopping_roundsは指定されたラウンド数の性能が向上しない場合にトレーニングを停止します。
早期停止とカスタム評価メトリック
早期停止は、検証セット上でのモデルのパフォーマンスが指定されたラウンド数で改善しない場合にトレーニングプロセスを停止する便利なテクニックです。トレーニング中に検証セットを提供し、トレーニング中にearly_stopping_roundsパラメータを指定することで、XGBoostで早期停止を使用することができます。
model = xgb.train(params, dtrain, num_boost_round=100, evals=[(dtest, 'validation')], early_stopping_rounds=10)
XGBoostはまた、カスタム評価メトリックを定義することもできます。カスタムメトリックを実装するには、予測値とDMatrixオブジェクトを受け取るPython関数を作成する必要があります。関数は、メトリックの名前と値を含むタプルを返す必要があります。例えば、次のようにしてカスタム精度メトリックを作成できます。
def accuracy_metric(preds, dmatrix):
labels = dmatrix.get_label()
return 'accuracy', accuracy_score(labels, preds)
model = xgb.train(params, dtrain, num_boost_round=100, evals=[(dtest, 'validation')], feval=accuracy_metric, early_stopping_rounds=10)
このコードスニペットは、fevalパラメータとして渡すことによって、トレーニング中にカスタムaccuracy_metricを使用する方法を示しています。モデルは今後、カスタム精度メトリックを使用して評価され、そのパフォーマンスに基づいて早期停止が適用されます。
XGBoostにおけるFeature Importance
Feature Importanceは、データセットの中で、それらがモデルの予測にどのような影響を与えるかをランク付けする技術です。Feature Importanceを理解することで、特徴とターゲット変数の関係を理解し、モデルの解釈性を高めることができます。この章では、XGBoostにおけるさまざまなタイプのFeature Importanceを探索し、結果をプロットして解釈する方法を学びます。
Feature Importanceの種類
XGBoostでは、異なる基準に基づいて特徴量をランク付けするために、いくつかの重要度の種類が提供されています。もっとも一般的な重要度の種類は次のとおりです。
weight: ブースティングラウンド全体で特徴がツリーに出現した回数。gain: ツリーで使用された場合の特徴の平均ゲイン(分割基準の改善)cover: ツリーで使用された場合の特徴の平均カバレッジ
Feature Importanceのプロット
例えば、アヤメデータセットに対してゲインベースの特徴重要度をプロットするには、次のコードを使用します。
import seaborn as sns
import xgboost as xgb
# Set Seaborn's plotting style and color palette
sns.set_style("whitegrid")
sns.set_palette("husl")
# Obtain feature importance values
importance_df = pd.DataFrame(model.get_booster().get_score(importance_type='gain').items(),
columns=['Feature', 'Importance'])
# Sort dataframe by importance values
importance_df = importance_df.sort_values(by='Importance', ascending=False)
# Plot the feature importance using Seaborn's barplot
plt.figure(figsize=(10, 6))
sns.barplot(x='Importance', y='Feature', data=importance_df)
plt.title('Gain-based Feature Importance for Iris Dataset', fontsize=18)
plt.xlabel('Importance (F score)', fontsize=14)
plt.ylabel('Feature', fontsize=14)
plt.show()
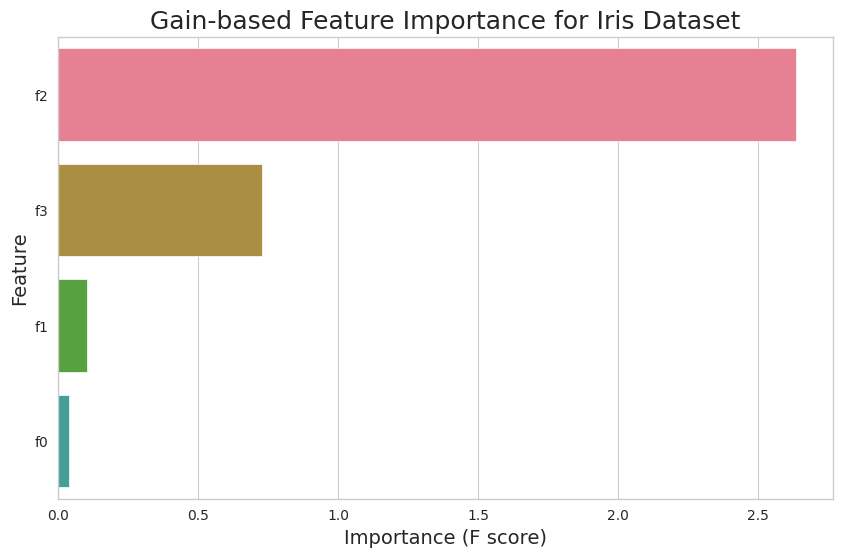
このコードスニペットは、アヤメデータセットの各特徴のゲインベースの重要度を示す棒グラフを生成します。'gain'を'weight'または'cover'に置き換えることで、対応する重要度の種類をプロットすることができます。
結果の解釈
Feature Importanceプロットは、特徴量とターゲット変数の関係に関する貴重な洞察を提供します。重要度の値が高い特徴量ほど、モデルの予測に対して大きな影響を与えます。一方、重要度の値が低い特徴量は、寄与が少ないことを示します。
参考
















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS