


指数分布とは
指数分布とは単位時間当たりに平均
- 1時間に平均20回電話が鳴るコールセンターで、次に電話が鳴るまでの時間
- 2年間に1回発生する災害が次に発生するまでの時間
指数分布の確率密度関数は次のように表すことができます。
指数分布の期待値と分散
指数分布の期待値、分散はそれぞれ以下になります。
指数分布の無記憶性
確率変数
上式は将来の事象発生までの時間がその過去の事象の有無に依存しないということを意味しています。この性質を無記憶性(Memoryless)といいます。指数分布は無記憶性を持つ唯一の連続分布になります。
ポアソン分布との関係
指数分布はある事象が起こるまでの時間が従う確率分布であり、ポアソン分布は単位時間内に事象が起こる回数が従う確率分布です。つまり、同じ事象を指数分布は「時間」で捉え、ポアソン分布は「回数」で捉えます。
Python コード
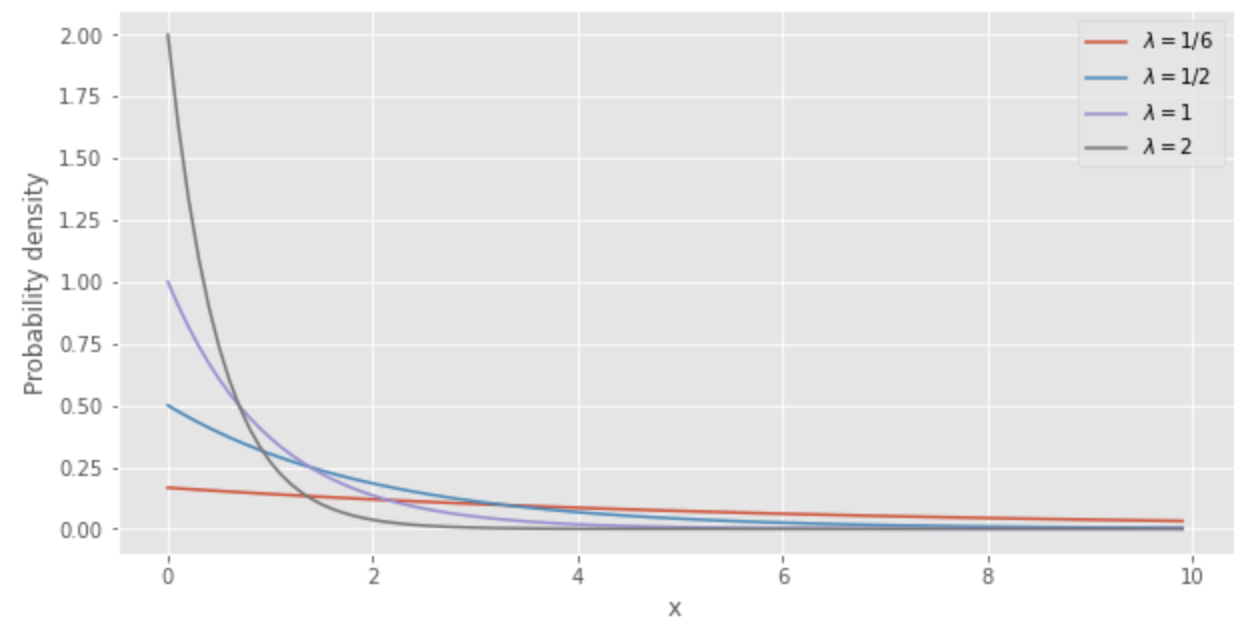
次のPythonコードで指数分布を描画することができます。
from scipy.stats import expon
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('ggplot')
plt.figure(figsize=(10,5))
x = np.arange(0, 10, 0.1)
y_1_6 = expon.pdf(x=x, scale=6)
y_1_2 = expon.pdf(x=x, scale=2)
y_1 = expon.pdf(x=x, scale=1)
y_2 = expon.pdf(x=x, scale=1/2)
plt.plot(x, y_1_6, label='$\lambda=1/6$')
plt.plot(x, y_1_2, label='$\lambda=1/2$')
plt.plot(x, y_1, label='$\lambda=1$')
plt.plot(x, y_2, label='$\lambda=2$')
plt.legend()
plt.xlabel("x")
plt.ylabel("Probability density")
AlloyDB

Amazon Cognito

Amazon EC2

Amazon ECS

Amazon QuickSight

Amazon RDS

Amazon Redshift

Amazon S3

API

Autonomous Vehicle

AWS

AWS API Gateway

AWS Chalice

AWS Control Tower

AWS IAM

AWS Lambda

AWS VPC

BERT

BigQuery

Causal Inference

ChatGPT

Chrome Extension

CircleCI

Classification

Cloud Functions

Cloud IAM

Cloud Run

Cloud Storage

Clustering

CSS

Data Engineering

Data Modeling

Database

dbt

Decision Tree

Deep Learning

Descriptive Statistics

Differential Equation

Dimensionality Reduction

Discrete Choice Model

Docker

Economics

FastAPI

Firebase

GIS

git

GitHub

GitHub Actions

Google

Google Cloud

Google Search Console

Hugging Face

Hypothesis Testing

Inferential Statistics

Interval Estimation

JavaScript

Jinja

Kedro

Kubernetes

LightGBM

Linux

LLM

Mac

Machine Learning

Macroeconomics

Marketing

Mathematical Model

Meltano

MLflow

MLOps

MySQL

NextJS

NLP

Nodejs

NoSQL

ONNX

OpenAI

Optimization Problem

Optuna

Pandas

Pinecone

PostGIS

PostgreSQL

Probability Distribution
Product

Project

Psychology

Python
PyTorch

QGIS

R

ReactJS

Regression

Rideshare

SEO

Singer

sklearn

Slack

Snowflake

Software Development

SQL

Statistical Model

Statistics
Streamlit

Tabular

Tailwind CSS

TensorFlow

Terraform

Transportation

TypeScript

Urban Planning

Vector Database

Vertex AI

VSCode

XGBoost

Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS