


単語埋め込みとは
自然言語をコンピュータに認識させるためには、単語や文書の持つ性質や意味を反映しつつそれらを数値化する必要があります。単語の数値化として、単語を固定長のベクトルで表現することを単語埋め込み(Word Embedding)と言います。
単語をベクトルで表現することで、例えば、意味的に類似した単語(「boat」と「ship」など)や意味的に関連した単語(「boat」と「water」など)がベクトル空間上でより近くなります。意味的な関連性を捉えるには文書を文脈として用い、意味的な類似性を捉えるには単語を文脈として用います。
単語をベクトルで表現する方法として次のような手法が提案されてきました。
- One-hotベクトル
- Word2Vec
- fastText
- GloVe
- ELMo
- BERT
One-hot ベクトル
単語をベクトル化する手法の一つとして、One-hotベクトルがあります。One-hotベクトルは、ベクトルの全ての要素のうち一つだけが1であり、残りは全て0であるベクトルを意味します。
例えば、次のように単語ごとにベクトルを割り当てます。
| 単語 | One-hot ベクトル |
|---|---|
| I | |
| play | |
| basketball |
この手法では、機械的にベクトルを割り当てることができる一方、次の課題があります。
- 次元が大きすぎる
100万の単語があるとすると、次元は100万となり計算負荷が大きいです。 - 意味をエンコードできない
同一単語であるかどうかの判定はできますが、単語の意味を含んだベクトルにはなっていません。
単語埋め込み
ベクトルの次元が膨大になるという課題を解決するために提案された手法が単語埋め込みです。単語をベクトル空間に埋め込み、その空間上のひとつの点として捉えることを単語埋め込みと言います。単語埋め込みにより、単語の意味を含めたベクトルとして表現できるようになったことで、意味の異なる単語同士でのベクトルの計算ができるようになります。
単語埋め込みの方法として、次のような手法が提案されてきました。
- Word2Vec
- fastText
- GloVe
- ELMo
- BERT
Word2vec
One-hotベクトルの課題である次元が大きすぎる点、意味をエンコードできない点を克服する手法がword2vecです。Word2vecはGoogleの研究チームによって2013年に公開されました。
Word2vecはSkip-gramとCBOW(Continuous Bag-Of-Words)の2つのアーキテクチャの集合です。
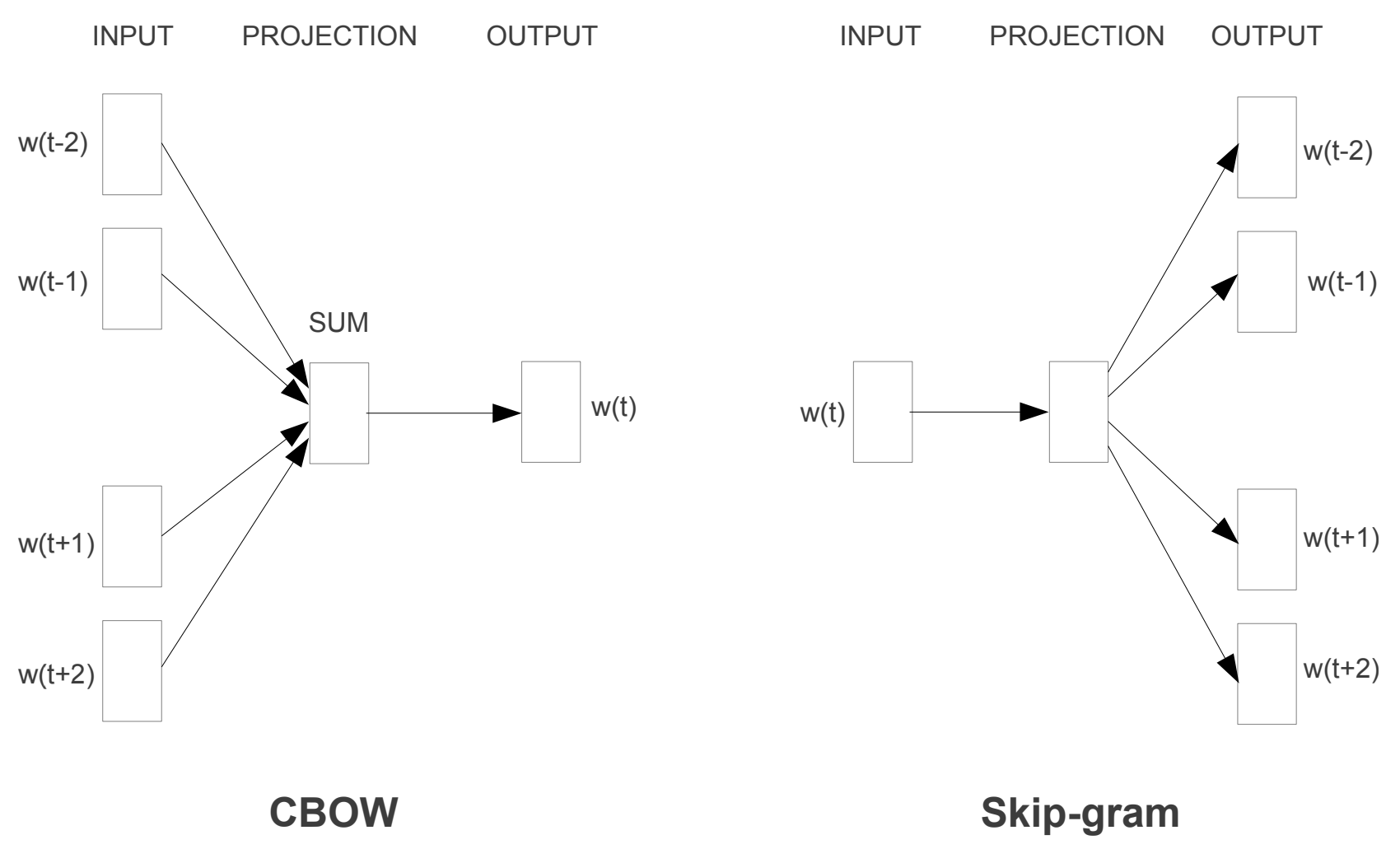
Efficient Estimation of Word Representations in Vector Space
| アーキテクチャ | 内容 |
|---|---|
| Skip-gram | ある単語から周辺の単語を予測 |
| CBOW | 周辺の単語からある単語を予測 |
Word2vecはgensimというライブラリを使うと簡単に実装することができます。
import gensim
import gensim.downloader as gendl
corpus = gendl.load("text8")
model = gensim.models.Word2Vec(corpus, size=200, window=5, iter=10, min_count=1)
「tea」という単語は次の200次元のベクトルで表現されています。
model.wv['tea']
array([ 1.0338242 , -0.5497605 , 0.85095 , -1.9308733 , 0.02577365,
-0.04760092, -0.11763089, -0.88888925, 1.0477808 , -0.8593776 ,
-0.18352145, 0.44907862, 0.7292549 , -0.989956 , -0.31382865,
-0.326568 , 1.0326288 , -1.015825 , 1.1364412 , 2.2554684 ,
-0.46170548, -0.87449044, -0.92171615, 1.3384876 , 0.71479833,
1.5579652 , -0.79532343, -0.01963346, -0.09595346, 0.2980923 ,
-0.77367973, -0.21674974, -0.16363882, 0.7561723 , -0.9837275 ,
0.7700488 , 0.31943208, 1.1382285 , 0.7920231 , 0.4009208 ,
-0.12014329, 0.45739177, -0.8750017 , 0.9846294 , 1.0761734 ,
0.9916462 , -1.9893979 , 0.63205105, 1.6679561 , 0.23037305,
-0.09124516, 0.20652458, 2.5330052 , 0.46803576, -0.52581394,
-0.04794846, -0.8805762 , -0.19912305, 0.4005117 , -0.7323035 ,
1.1342882 , -2.2171109 , 2.2963653 , 0.30365032, 1.0434904 ,
-0.04669679, 0.4062761 , 0.5528872 , 0.47095624, -1.6239247 ,
1.557434 , -0.9619251 , 0.9666863 , -0.2241764 , -0.75970024,
1.8893499 , -1.0962995 , -1.0411807 , 0.4480955 , 0.5210397 ,
1.6454376 , 0.65203476, -0.04012801, -0.40056226, 2.852509 ,
-0.32553425, -0.20229222, 0.7245843 , -1.9557822 , -0.12104818,
0.28175735, -0.895713 , 0.58786476, 1.3742826 , -0.41480052,
0.07302658, 0.09337772, -0.34411722, -0.00724911, -0.9056035 ,
0.12258726, -0.15003532, 0.04658122, -2.2854378 , 0.28233293,
0.77172595, 1.3786261 , -1.2632967 , -1.426814 , -0.51365477,
-1.2197368 , 0.04790526, 0.62031317, 1.1224078 , -0.1804243 ,
0.49400517, -0.02745727, -1.0031232 , -0.10298221, 0.91482383,
0.98645395, 0.2342329 , 0.02064842, -0.33413368, -1.1859212 ,
1.1475669 , -1.0501987 , -0.7069197 , -0.12736289, 1.7058631 ,
-0.74710023, 0.48769948, -0.7129323 , 0.49225873, -1.3105804 ,
-2.1176062 , 0.5835398 , -0.01676613, 0.40714362, 1.6942219 ,
0.8474393 , -0.7914968 , 1.8470286 , 0.4587502 , -1.2789383 ,
0.48545036, -0.50352156, -0.04223507, -0.35754788, -0.60754126,
0.05735195, 0.32261458, -0.09268601, 0.702604 , 1.1815772 ,
0.17023656, -0.46019134, -1.0920937 , 0.26714015, -0.06735314,
-0.16602936, 0.6498549 , -0.35616133, 0.20689702, 0.7797428 ,
0.14901382, -0.71886814, 1.2617997 , 0.43995163, 1.0300183 ,
-0.81545556, -0.06593582, -0.23527797, -1.3182799 , 0.41896763,
1.8256154 , -0.04706338, -1.106722 , -0.47043508, -0.30877873,
0.27309516, -0.5845974 , 0.12854019, 0.44951373, 0.46647298,
-0.30743253, -0.7417909 , 1.0234478 , -1.4167138 , -0.6474553 ,
0.9093568 , 0.17825471, -1.3186976 , -1.7007768 , -1.4912218 ,
0.02761938, -1.5523437 , -0.30878946, -0.5883677 , 0.35952488],
dtype=float32)
len(model.wv['tea'])
200
このように、Word2vecはある単語のベクトル表現を数百万次元から200次元に削減することができています。
「tea」という単語に類似している単語は次のようになります。
model.wv.most_similar("tea")
[('coffee', 0.7221519947052002),
('beef', 0.6720874309539795),
('roast', 0.6600600481033325),
('spices', 0.653677225112915),
('drinks', 0.6486484408378601),
('sweets', 0.6478144526481628),
('cheese', 0.6444395780563354),
('pork', 0.6424828767776489),
('sausage', 0.6399528980255127),
('vegetables', 0.6373381614685059)]
このように、Word2vecは単語の意味を理解することができています。
次の単語を組み合わせるとどのようになるのかを確認します。
queen + man - woman
```python
model.wv.most_similar(positive=['queen', 'man'], negative=['woman'])
[('king', 0.5715309977531433),
('lord', 0.5021377801895142),
('crown', 0.4470388889312744),
('wight', 0.43937280774116516),
('prince', 0.43743711709976196),
('duke', 0.43583834171295166),
('regent', 0.4239676296710968),
('valdemar', 0.4121330976486206),
('scotland', 0.4113471210002899),
('vii', 0.3981912136077881)]
「king」という結果が返ってきました。
GloVe
Word2Vecのアーキテクチャはいずれも予測型であり、ある文脈の単語が他の文脈より多く出現するという事実を無視しています。また、局所的な文脈のみを考慮しているため、グローバルな文脈を捉えることができません。
GloVe(Global Vectors for Word Representation)は単語の共起性に関するグローバルな統計量を利用して、単語のベクトル表現を学習します。
以下はGloVeの実装のサンプルコードです。
!wget http://nlp.stanford.edu/data/glove.6B.zip
!unzip glove*.zip
import numpy as np
embeddings_dict = {}
with open("glove.6B.50d.txt", 'r') as f:
for line in f:
values = line.split()
word = values[0]
vector = np.asarray(values[1:], "float32")
embeddings_dict[word] = vector
embeddings_dict['water']
array([ 0.53507 , 0.5761 , -0.054351, -0.208 , -0.7882 , -0.17592 ,
-0.21255 , -0.14388 , 1.0344 , -0.079253, 0.27696 , 0.37951 ,
1.2139 , -0.34032 , -0.18118 , 0.72968 , 0.89373 , 0.82912 ,
-0.88932 , -1.4071 , 0.55571 , -0.017453, 1.2524 , -0.57916 ,
0.43 , -0.77935 , 0.4977 , 1.2746 , 1.0448 , 0.36433 ,
3.7921 , 0.083653, -0.45044 , -0.063996, -0.19866 , 0.75252 ,
-0.27811 , 0.42783 , 1.4755 , 0.37735 , 0.079519, 0.024462,
0.5013 , 0.33565 , 0.051406, 0.39879 , -0.35603 , -0.78654 ,
0.61563 , -0.95478 ], dtype=float32)
fastText
Word2VecやGloVeでは、未知の単語や語彙のない単語を符号化できないという課題がありました。この課題に対処するために、FacebookはFastTextというモデルを提案しました。
Word2Vecが個々の単語のベクトルを学習するのに対し、fastTextでは単語をいくつかのサブワード(n-gram)に分割し学習されます。
例えば、「what」という単語を考えた場合、tri-gram(
"wh", "wha", "hat", "at"
この概念に基づき、FastTextは学習テキストに含まれない単語の埋め込みベクトルを、その文字埋め込みを用いて生成することができます。例えば、「googling」という未知語があっても、「google」と「ing」というように分割されるようになり、ベクトル表現が可能となります。
以下はfastTextの実装のサンプルコードです。
!wget https://dl.fbaipublicfiles.com/fasttext/vectors-english/wiki-news-300d-1M.vec.zip
!unzip wiki-news-300d-1M.vec.zip
import io
def load_vectors(word):
fin = io.open('wiki-news-300d-1M.vec', 'r', encoding='utf-8', newline='\n', errors='ignore')
for line in fin:
tokens = line.rstrip().split(' ')
if target_word == tokens[0]:
return [float(s) for s in tokens[1:]]
load_vectors('googling')
[-0.1151,
0.2652,
-0.13,
.
.
.
0.123,
0.2461,
0.0373]
ELMo
Word2vec、GloVe、fastTextはいづれも1単語を1ベクトルに変換するという性質があります。そのため、多義語を表現することができません。例えば「bank」という言葉は、金融機関だけでなく、川沿いの土手も指すこともあります。
そこで、ELMoというある単語の意味が文脈に依存することに対処するモデルが開発されました。
ELMoは1つの単語に対して固定的なベクトル表現を生成しません。その代わりに、ELMoは文中の各単語の埋め込みを生成する前に、文全体を考慮します。この文脈依存の埋め込みフレームワークは、単語が実際に使用される文脈を加味した単語のベクトル表現を生成します。
ELMoはディープ双方向LSTM言語モデルを用いており、次の単語だけでなく、前の単語もよりよく理解することができます。
以下はELMoの実装のサンプルコードです。
!pip install allennlp
from allennlp.modules.elmo import Elmo, batch_to_ids
options_file = "https://s3-us-west-2.amazonaws.com/allennlp/models/elmo/2x4096_512_2048cnn_2xhighway/elmo_2x4096_512_2048cnn_2xhighway_options.json"
weight_file = "https://s3-us-west-2.amazonaws.com/allennlp/models/elmo/2x4096_512_2048cnn_2xhighway/elmo_2x4096_512_2048cnn_2xhighway_weights.hdf5"
elmo = Elmo(options_file, weight_file, 2, dropout=0)
sentences = ['By working faithfully eight hours a day, you may eventually get to be a boss and work twelve hours a day.'.split(' ')]
character_ids = batch_to_ids(sentences)
embeddings = elmo(character_ids)
print(embeddings['elmo_representations'])
[tensor([[[ 0.2935, 0.2494, -0.4810, ..., -0.2546, -0.2394, 0.2540],
[ 0.2875, 0.2179, -0.2757, ..., 0.0597, -0.1851, -0.2132],
[-0.4081, 0.1770, 0.5752, ..., -0.3343, 0.4417, 0.6988],
...,
[ 0.2734, 0.0159, -0.1510, ..., -0.0459, -0.0769, 0.8115],
[ 0.0628, -0.0689, -0.3339, ..., -0.1212, -0.0101, 0.0247],
[-0.0577, 0.8521, -0.3685, ..., 0.0323, -0.1151, 0.2783]]],
grad_fn=<CopySlices>), tensor([[[ 0.2935, 0.2494, -0.4810, ..., -0.2546, -0.2394, 0.2540],
[ 0.2875, 0.2179, -0.2757, ..., 0.0597, -0.1851, -0.2132],
[-0.4081, 0.1770, 0.5752, ..., -0.3343, 0.4417, 0.6988],
...,
[ 0.2734, 0.0159, -0.1510, ..., -0.0459, -0.0769, 0.8115],
[ 0.0628, -0.0689, -0.3339, ..., -0.1212, -0.0101, 0.0247],
[-0.0577, 0.8521, -0.3685, ..., 0.0323, -0.1151, 0.2783]]],
grad_fn=<CopySlices>)]
BERT
BERT は2018年10月11日にGoogleが発表したMLPモデルです。BERTは翻訳や分類問題を解くためのアルゴリズムとしてだけではなく、単語の分散表現としても利用することができます。具体的には、BERTの中ではMasked Language Model(MLM))というマスクされた単語を推定するモデルがあり、その中で単語の分散表現が学習されます。
ELMoは単語を推定する際に順方向と逆方向でそれぞれ独立に学習するのに対して、BERTのMLMは順方向と逆方向を同時に学習します。そのため、理論上はELMoよりもBERTの分散表現の方が精度は高いです。
以下はBERTの実装のサンプルコードです。
!pip install transformers
import torch
from transformers import BertTokenizer, BertModel
model = BertModel.from_pretrained('bert-base-uncased')
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
input_ids = torch.tensor(tokenizer.encode('The optimist sees the doughnut, the pessimist sees the hole.', add_special_tokens=True)).unsqueeze(0)
outputs = model(input_ids)
last_hidden_states = outputs[0]
print(last_hidden_states)
tensor([[[-0.4030, 0.3356, -0.0636, ..., -0.6573, 0.6247, 0.6181],
[-0.6247, 0.1251, -0.3543, ..., 0.0818, 1.1095, 0.0013],
[-0.1742, -0.0781, 0.4559, ..., -0.3268, 0.2127, 0.1130],
...,
[ 0.3077, 0.2755, -0.1591, ..., 0.3503, 0.3849, 0.6388],
[ 0.6037, 0.0777, -0.2810, ..., 0.1952, -0.3510, -0.3897],
[ 0.7766, 0.1315, -0.1458, ..., 0.1757, -0.4855, -0.3783]]],
grad_fn=<NativeLayerNormBackward0>)
まとめ
単語のベクトル表現の手法をまとめると次の表のようになります。
| 手法(大分類) | 手法(小分類) | 意味理解 | 文脈理解 | 次元数 |
|---|---|---|---|---|
| One-hot 表現 | One-hot ベクトル | × | × | 1M |
| 文脈を加味しない単語埋め込み | Word2vec Glove fastText |
● | × | 100~300 |
| 文脈を加味する単語埋め込み | ELMo BERT |
● | ● | 100~1000 |
参考
















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS