

はじめに
言語処理100本ノックというNLPに関する問題集が東京工業大学によって作成、管理されています。
この記事では、「第5章: 係り受け解析」について回答例を紹介します。
環境設定
日本語 Wikipedia の「人工知能」に関する記事からテキスト部分を抜き出したファイルが ai.ja.zip に収録されている. この文章を CaboCha や KNP 等のツールを利用して係り受け解析を行い,その結果を ai.ja.txt.parsed というファイルに保存せよ.このファイルを読み込み,以下の問に対応するプログラムを実装せよ.
!apt install -y curl file git libmecab-dev make mecab mecab-ipadic-utf8 swig xz-utils
!pip install mecab-python3
import os
filename_crfpp = 'crfpp.tar.gz'
!wget "https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7QVR6VXJ5dWExSTQ" \
-O $filename_crfpp
!tar zxvf $filename_crfpp
%cd CRF++-0.58
!./configure
!make
!make install
%cd ..
os.environ['LD_LIBRARY_PATH'] += ':/usr/local/lib'
FILE_ID = "0B4y35FiV1wh7SDd1Q1dUQkZQaUU"
FILE_NAME = "cabocha.tar.bz2"
!wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=\
$(wget --quiet --save-cookies /tmp/cookies.txt \
--keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=$FILE_ID' -O- \
| sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=$FILE_ID" -O $FILE_NAME && rm -rf /tmp/cookies.txt
!tar -xvf cabocha.tar.bz2
%cd cabocha-0.69
!./configure --with-mecab-config=`which mecab-config` --with-charset=UTF8
!make
!make check
!make install
%cd ..
%cd cabocha-0.69/python
!python setup.py build_ext
!python setup.py install
!ldconfig
%cd ../
%cd cabocha-0.69
!make
!make check
!make install
%cd ../
!wget https://nlp100.github.io/data/ai.ja.zip
!unzip ai.ja.zip
!cabocha -f1 -o ai.ja.txt.parsed ai.ja.txt
!wc -l ./ai.ja.txt.parsed
>> 11744 ./ai.ja.txt.parsed
!head -15 ./ai.ja.txt.parsed
>> * 0 -1D 1/1 0.000000
>> 人工 名詞,一般,*,*,*,*,人工,ジンコウ,ジンコー
>> 知能 名詞,一般,*,*,*,*,知能,チノウ,チノー
>> EOS
>> EOS
>> * 0 17D 1/1 0.388993
>> 人工 名詞,一般,*,*,*,*,人工,ジンコウ,ジンコー
>> 知能 名詞,一般,*,*,*,*,知能,チノウ,チノー
>> * 1 17D 2/3 0.613549
>> ( 記号,括弧開,*,*,*,*,(,(,(
>> じん 名詞,一般,*,*,*,*,じん,ジン,ジン
>> こうち 名詞,一般,*,*,*,*,こうち,コウチ,コーチ
>> のう 助詞,終助詞,*,*,*,*,のう,ノウ,ノー
>> 、 記号,読点,*,*,*,*,、,、,、
>> 、 記号,読点,*,*,*,*,、,、,、
40. 係り受け解析結果の読み込み(形態素)
形態素を表すクラス Morph を実装せよ.このクラスは表層形(
surface),基本形(base),品詞(pos),品詞細分類 1(pos1)をメンバ変数に持つこととする.さらに,係り受け解析の結果(ai.ja.txt.parsed)を読み込み,各文をMorphオブジェクトのリストとして表現し,冒頭の説明文の形態素列を表示せよ.
class Morph:
def __init__(self, line):
surface, attr = line.split("\t")
attr = attr.split(",")
self.surface = surface
self.base = attr[-3]
self.pos = attr[0]
self.pos1 = attr[1]
sentences = []
morphs = []
with open("./ai.ja.txt.parsed") as f:
for line in f:
if line[0] == "*":
continue
elif line != "EOS\n":
morphs.append(Morph(line))
else:
sentences.append(morphs)
morphs = []
for i in sentences[0]:
print(vars(i))
{'surface': '人工', 'base': '人工', 'pos': '名詞', 'pos1': '一般'}
{'surface': '知能', 'base': '知能', 'pos': '名詞', 'pos1': '一般'}
41. 係り受け解析結果の読み込み(文節・係り受け)
40 に加えて,文節を表すクラス
Chunkを実装せよ.このクラスは形態素(Morphオブジェクト)のリスト(morphs),係り先文節インデックス番号(dst),係り元文節インデックス番号のリスト(srcs)をメンバ変数に持つこととする.さらに,入力テキストの係り受け解析結果を読み込み,1文をChunkオブジェクトのリストとして表現し,冒頭の説明文の文節の文字列と係り先を表示せよ.本章の残りの問題では,ここで作ったプログラムを活用せよ.
class Chunk:
def __init__(self, morphs, dst, chunk_id):
self.morphs = morphs
self.dst = dst
self.srcs = []
self.chunk_id = chunk_id
class Sentence:
def __init__(self, chunks):
self.chunks = chunks
for i, chunk in enumerate(self.chunks):
if chunk.dst not in [None, -1]:
self.chunks[chunk.dst].srcs.append(i)
class Morph:
def __init__(self, line):
surface, attr = line.split("\t")
attr = attr.split(",")
self.surface = surface
self.base = attr[-3]
self.pos = attr[0]
self.pos1 = attr[1]
sentences = []
chunks = []
morphs = []
chunk_id = 0
with open("./ai.ja.txt.parsed") as f:
for line in f:
if line[0] == "*":
if morphs:
chunks.append(Chunk(morphs, dst, chunk_id))
chunk_id += 1
morphs = []
dst = int(line.split()[2].replace("D", ""))
elif line != "EOS\n":
morphs.append(Morph(line))
else:
chunks.append(Chunk(morphs, dst, chunk_id))
sentences.append(Sentence(chunks))
morphs = []
chunks = []
dst = None
chunk_id = 0
for chunk in sentences[2].chunks:
print(f'chunk str: {"".join([morph.surface for morph in chunk.morphs])}\ndst: {chunk.dst}\nsrcs: {chunk.srcs}\n')
chunk str: 人工知能
dst: 17
srcs: []
chunk str: (じんこうちのう、、
dst: 17
srcs: []
chunk str: AI
dst: 3
srcs: []
chunk str: 〈エーアイ〉)とは、
dst: 17
srcs: [2]
.
.
.
42. 係り元と係り先の文節の表示
係り元の文節と係り先の文節のテキストをタブ区切り形式ですべて抽出せよ.ただし,句読点などの記号は出力しないようにせよ.
sentence = sentences[2]
for chunk in sentence.chunks:
if int(chunk.dst) == -1:
continue
else:
surf_org = "".join([morph.surface for morph in chunk.morphs if morph.pos != "記号"])
surf_dst = "".join([morph.surface for morph in sentence.chunks[int(chunk.dst)].morphs if morph.pos != "記号"])
print(surf_org, surf_dst, sep='\t')
人工知能 語
じんこうちのう 語
AI エーアイとは
エーアイとは 語
計算 という
という 道具を
概念と 道具を
コンピュータ という
という 道具を
道具を 用いて
.
.
.
43. 名詞を含む文節が動詞を含む文節に係るものを抽出
名詞を含む文節が,動詞を含む文節に係るとき,これらをタブ区切り形式で抽出せよ.ただし,句読点などの記号は出力しないようにせよ.
sentence = sentences[2]
for chunk in sentence.chunks:
if int(chunk.dst) == -1:
continue
else:
surf_org = "".join([morph.surface for morph in chunk.morphs if morph.pos != "記号"])
surf_dst = "".join([morph.surface for morph in sentences[2].chunks[int(chunk.dst)].morphs if morph.pos != "記号"])
pos_noun = [morph.surface for morph in chunk.morphs if morph.pos == "名詞"]
pos_verb = [morph.surface for morph in sentences[2].chunks[int(chunk.dst)].morphs if morph.pos == "動詞"]
if pos_noun and pos_verb:
print(surf_org, surf_dst, sep='\t')
道具を 用いて
知能を 研究する
一分野を 指す
知的行動を 代わって
人間に 代わって
コンピューターに 行わせる
研究分野とも される
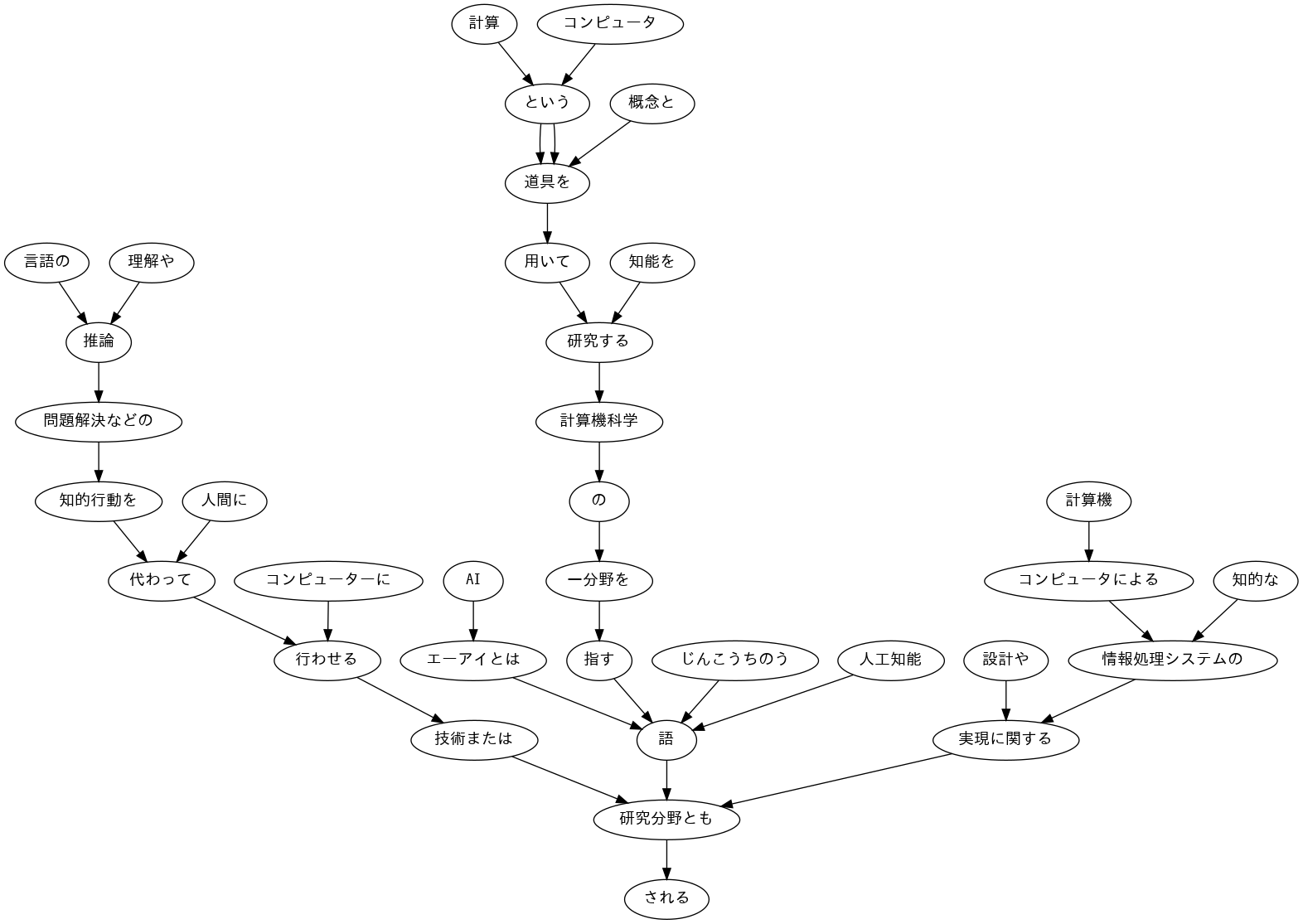
44. 係り受け木の可視化
与えられた文の係り受け木を有向グラフとして可視化せよ.可視化には,Graphviz 等を用いるとよい.
!apt install fonts-ipafont-gothic
!pip install pydot
import pydot_ng as pydot
from IPython.display import Image,display_png
edges = []
for chunk in sentences[2].chunks:
if int(chunk.dst) == -1:
continue
else:
surf_org = "".join([morph.surface for morph in chunk.morphs if morph.pos != "記号"])
surf_dst = "".join([morph.surface for morph in sentences[2].chunks[int(chunk.dst)].morphs if morph.pos != "記号"]) #文節のリストに係り先番号をindexに指定。その文節の形態素リストを取得
edges.append((surf_org, surf_dst))
img = pydot.Dot()
img.set_node_defaults(fontname="IPAGothic")
for s, t in edges:
img.add_edge(pydot.Edge(s, t))
img.write_png("./result44.png")
display_png(Image('./result44.png'))
45. 動詞の格パターンの抽出
今回用いている文章をコーパスと見なし,日本語の述語が取りうる格を調査したい. 動詞を述語,動詞に係っている文節の助詞を格と考え,述語と格をタブ区切り形式で出力せよ. ただし,出力は以下の仕様を満たすようにせよ.
- 動詞を含む文節において,最左の動詞の基本形を述語とする
- 述語に係る助詞を格とする
- 述語に係る助詞(文節)が複数あるときは,すべての助詞をスペース区切りで辞書順に並べる
このプログラムの出力をファイルに保存し,以下の事項を UNIX コマンドを用いて確認せよ.
- コーパス中で頻出する述語と格パターンの組み合わせ
- 「行う」「なる」「与える」という動詞の格パターン(コーパス中で出現頻度の高い順に並べよ)
with open("./result45.txt", "w") as f:
for i in range(len(sentences)):
for chunk in sentences[i].chunks:
for morph in chunk.morphs:
if morph.pos == "動詞":
particles = []
for src in chunk.srcs:
particles += [morph.surface for morph in sentences[i].chunks[src].morphs if morph.pos == "助詞"]
if len(particles) > 0:
particles = sorted(list(set(particles)))
print(f"{morph.base}\t{' '.join(particles)}", file=f)
!cat ./result45.txt | sort | uniq -c | sort -nr | head -n 5
!cat ./result45.txt | grep "行う" | sort | uniq -c | sort -nr | head -n 5
!cat ./result45.txt | grep "なる" | sort | uniq -c | sort -nr | head -n 5
!cat ./result45.txt | grep "与える" | sort | uniq -c | sort -nr | head -n 5
>> 49 する を
>> 19 する が
>> 15 する に
>> 15 する と
>> 12 する は を
>> 8 行う を
>> 1 行う まで を
>> 1 行う は を をめぐって
>> 1 行う は を
>> 1 行う に を
>> 4 なる に は
>> 3 なる が と
>> 2 なる に
>> 2 なる と
>> 1 異なる も
>> 1 与える に は を
>> 1 与える が に
>> 1 与える が など に
46. 動詞の格フレーム情報の抽出
45 のプログラムを改変し,述語と格パターンに続けて項(述語に係っている文節そのもの)をタブ区切り形式で出力せよ.45 の仕様に加えて,以下の仕様を満たすようにせよ.
- 項は述語に係っている文節の単語列とする(末尾の助詞を取り除く必要はない)
- 述語に係る文節が複数あるときは,助詞と同一の基準・順序でスペース区切りで並べる
with open("./result46.txt", "w") as f:
for i in range(len(sentences)):
for chunk in sentences[i].chunks:
for morph in chunk.morphs:
if morph.pos == "動詞":
particles = []
items = []
for src in chunk.srcs:
particles += [morph.surface for morph in sentences[i].chunks[src].morphs if morph.pos == "助詞"]
items += ["".join([morph.surface for morph in sentences[i].chunks[src].morphs if morph.pos != "記号"])]
if len(particles) > 0:
if len(items) > 0:
particles_form = " ".join(sorted(set(particles)))
items_form = " ".join(sorted(set(items)))
print(f"{morph.base}\t{particles_form}\t{items_form}", file=f)
!head -n 10 result46.txt
>> 用いる を 道具を
>> する て を 用いて 知能を
>> 指す を 一分野を
>> 代わる に を 人間に 知的行動を
>> 行う て に コンピューターに 代わって
>> せる て に コンピューターに 代わって
>> する と も 研究分野とも
>> れる と も 研究分野とも
>> 述べる で に の は 佐藤理史は 次のように 解説で
>> いる で に の は 佐藤理史は 次のように 解説で
47. 機能動詞構文のマイニング
動詞のヲ格にサ変接続名詞が入っている場合のみに着目したい.46 のプログラムを以下の仕様を満たすように改変せよ.
- 「サ変接続名詞+を(助詞)」で構成される文節が動詞に係る場合のみを対象とする
- 述語は「サ変接続名詞+を+動詞の基本形」とし,文節中に複数の動詞があるときは,最左の動詞を用いる
- 述語に係る助詞(文節)が複数あるときは,すべての助詞をスペース区切りで辞書順に並べる
- 述語に係る文節が複数ある場合は,すべての項をスペース区切りで並べる(助詞の並び順と揃えよ)
with open('./result47.txt', 'w') as f:
for sentence in sentences:
for chunk in sentence.chunks:
for morph in chunk.morphs:
if morph.pos == '動詞':
for i, src in enumerate(chunk.srcs):
if len(sentence.chunks[src].morphs) == 2 and sentence.chunks[src].morphs[0].pos1 == 'サ変接続' and sentence.chunks[src].morphs[1].surface == 'を':
predicate = ''.join([sentence.chunks[src].morphs[0].surface, sentence.chunks[src].morphs[1].surface, morph.base])
particles = []
items = []
for src_r in chunk.srcs[:i] + chunk.srcs[i + 1:]:
case = [morph.surface for morph in sentence.chunks[src_r].morphs if morph.pos == '助詞']
if len(case) > 0:
particles = particles + case
items.append(''.join(morph.surface for morph in sentence.chunks[src_r].morphs if morph.pos != '記号'))
if len(particles) > 0:
particles = sorted(list(set(particles)))
line = '{}\t{}\t{}'.format(predicate, ' '.join(particles), ' '.join(items))
print(line, file=f)
break
!head -n 10 result47.txt
>> 注目を集める が を ある その後 サポートベクターマシンが
>> 経験を行う に を 元に 学習を
>> 学習を行う に を 元に 経験を
>> 進化を見せる て において は を 加えて 敵対的生成ネットワークは 活躍している 特に 生成技術において
>> 進化をいる て において は を 加えて 敵対的生成ネットワークは 活躍している 特に 生成技術において
>> 開発を行う は を エイダ・ラブレスは 製作した
>> 命令をする で を 機構で 直接
>> 運転をする に を 元に 増やし
>> 特許をする が に まで を 2018年までに 日本が
>> 特許をいる が に まで を 2018年までに 日本が
48. 名詞から根へのパスの抽出
文中のすべての名詞を含む文節に対し,その文節から構文木の根に至るパスを抽出せよ. ただし,構文木上のパスは以下の仕様を満たすものとする.
- 各文節は(表層形の)形態素列で表現する
- パスの開始文節から終了文節に至るまで,各文節の表現を” -> “で連結する
sentence = sentences[2]
for chunk in sentence.chunks:
if "名詞" in [morph.pos for morph in chunk.morphs]:
path = ["".join(morph.surface for morph in chunk.morphs if morph.pos != "記号")]
while chunk.dst != -1:
path.append(''.join(morph.surface for morph in sentence.chunks[chunk.dst].morphs if morph.pos != "記号"))
chunk = sentence.chunks[chunk.dst]
print(" -> ".join(path))
人工知能 -> 語 -> 研究分野とも -> される
じんこうちのう -> 語 -> 研究分野とも -> される
AI -> エーアイとは -> 語 -> 研究分野とも -> される
エーアイとは -> 語 -> 研究分野とも -> される
計算 -> という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> の -> 一分野を -> 指す -> 語 -> 研究分野とも -> される
概念と -> 道具を -> 用いて -> 研究する -> 計算機科学 -> の -> 一分野を -> 指す -> 語 -> 研究分野とも -> される
コンピュータ -> という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> の -> 一分野を -> 指す -> 語 -> 研究分野とも -> される
道具を -> 用いて -> 研究する -> 計算機科学 -> の -> 一分野を -> 指す -> 語 -> 研究分野とも -> される
知能を -> 研究する -> 計算機科学 -> の -> 一分野を -> 指す -> 語 -> 研究分野とも -> される
.
.
.
49. 名詞間の係り受けパスの抽出
文中のすべての名詞句のペアを結ぶ最短係り受けパスを抽出せよ.ただし,名詞句ペアの文節番号が
と i ( j )のとき,係り受けパスは以下の仕様を満たすものとする. i<j
- 問題 48 と同様に,パスは開始文節から終了文節に至るまでの各文節の表現(表層形の形態素列)を” -> “で連結して表現する
- 文節
と i に含まれる名詞句はそれぞれ,X と Y に置換する j また,係り受けパスの形状は,以下の 2 通りが考えられる.
- 文節
から構文木の根に至る経路上に文節 i が存在する場合: 文節 j から文節 i のパスを表示 j - 上記以外で,文節
と文節 i から構文木の根に至る経路上で共通の文節 j で交わる場合: 文節 k から文節 i に至る直前のパスと文節 k から文節 j に至る直前までのパス,文節 k の内容を” | “で連結して表示 k
from itertools import combinations
import re
sentence = sentences[2]
nouns = []
for i, chunk in enumerate(sentence.chunks):
if [morph for morph in chunk.morphs if morph.pos == "名詞"]:
nouns.append(i)
for i, j in combinations(nouns, 2):
path_i = []
path_j = []
while i != j:
if i < j:
path_i.append(i)
i = sentence.chunks[i].dst
else:
path_j.append(j)
j = sentence.chunks[j].dst
if len(path_j) == 0:
X = "X" + "".join([morph.surface for morph in sentence.chunks[path_i[0]].morphs if morph.pos != "名詞" and morph.pos != "記号"])
Y = "Y" + "".join([morph.surface for morph in sentence.chunks[i].morphs if morph.pos != "名詞" and morph.pos != "記号"])
chunk_X = re.sub("X+", "X", X)
chunk_Y = re.sub("Y+", "Y", Y)
path_XtoY = [chunk_X] + ["".join(morph.surface for n in path_i[1:] for morph in sentence.chunks[n].morphs)] + [chunk_Y]
print(" -> ".join(path_XtoY))
else:
X = "X" + "".join([morph.surface for morph in sentence.chunks[path_i[0]].morphs if morph.pos != "名詞" and morph.pos != "記号"])
Y = "Y" + "".join([morph.surface for morph in sentence.chunks[path_j[0]].morphs if morph.pos != "名詞" and morph.pos != "記号"])
chunk_X = re.sub("X+", "X", X)
chunk_Y = re.sub("Y+", "Y", Y)
chunk_k = "".join([morph.surface for morph in sentence.chunks[i].morphs if morph.pos != "記号"])
path_X = [chunk_X] + ["".join(morph.surface for n in path_i[1:] for morph in sentence.chunks[n].morphs if morph.pos != "記号")]
path_Y = [chunk_Y] + ["".join(morph.surface for n in path_j[1: ]for morph in sentence.chunks[n].morphs if morph.pos != "記号")]
print(" | ".join([" -> ".join(path_X), " -> ".join(path_Y), chunk_k]))
X -> | Yのう -> | 語
X -> | Y -> エーアイとは | 語
X -> | Yとは -> | 語
X -> | Y -> という道具を用いて研究する計算機科学の一分野を指す | 語
X -> | Yと -> 道具を用いて研究する計算機科学の一分野を指す | 語
X -> | Y -> という道具を用いて研究する計算機科学の一分野を指す | 語
X -> | Yを -> 用いて研究する計算機科学の一分野を指す | 語
X -> | Yを -> 研究する計算機科学の一分野を指す | 語
X -> | Yする -> 計算機科学の一分野を指す | 語
X -> | Y -> の一分野を指す | 語
X -> | Yを -> 指す | 語
.
.
.
参考

















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS