

はじめに
言語処理100本ノックというNLPに関する問題集が東京工業大学によって作成、管理されています。
この記事では、「第4章: 形態素解析」について回答例を紹介します。
環境設定
夏目漱石の小説『吾輩は猫である』の文章(neko.txt)を MeCab を使って形態素解析し,その結果を neko.txt.mecab というファイルに保存せよ.このファイルを用いて,以下の問に対応するプログラムを実装せよ.
なお,問題 37, 38, 39 は matplotlib もしくは Gnuplot を用いるとよい.
$ wget https://nlp100.github.io/data/neko.txt
$ apt install mecab libmecab-dev mecab-ipadic-utf8
$ mecab -o ./neko.txt.mecab ./neko.txt
$ wc -l ./neko.txt.mecab
226266 ./neko.txt.mecab
$ head -n 5 ./neko.txt.mecab
一 名詞,数,*,*,*,*,一,イチ,イチ
記号,一般,*,*,*,*,*
EOS
記号,一般,*,*,*,*,*
EOS
記号,空白,*,*,*,*, , ,
吾輩 名詞,代名詞,一般,*,*,*,吾輩,ワガハイ,ワガハイ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
猫 名詞,一般,*,*,*,*,猫,ネコ,ネコ
で 助動詞,*,*,*,特殊・ダ,連用形,だ,デ,デ
ある 助動詞,*,*,*,五段・ラ行アル,基本形,ある,アル,アル
。 記号,句点,*,*,*,*,。,。,。
記号,一般,*,*,*,*,*
EOS
名前 名詞,一般,*,*,*,*,名前,ナマエ,ナマエ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
まだ 副詞,助詞類接続,*,*,*,*,まだ,マダ,マダ
無い 形容詞,自立,*,*,形容詞・アウオ段,基本形,無い,ナイ,ナイ
。 記号,句点,*,*,*,*,。,。,。
記号,一般,*,*,*,*,*
30. 形態素解析結果の読み込み
形態素解析結果(neko.txt.mecab)を読み込むプログラムを実装せよ.ただし,各形態素は表層形(surface),基本形(base),品詞(pos),品詞細分類 1(pos1)をキーとするマッピング型に格納し,1 文を形態素(マッピング型)のリストとして表現せよ.第 4 章の残りの問題では,ここで作ったプログラムを活用せよ.
sentences = []
morphs = []
with open('./neko.txt.mecab', mode='r') as f:
for line in f:
if line != 'EOS\n':
fields = line.split('\t')
if fields[0] == '' or len(fields) != 2:
continue
else:
attrs = fields[1].split(',')
morph = {
'surface': fields[0],
'base': attrs[6],
'pos': attrs[0],
'pos1': attrs[1]
}
morphs.append(morph)
else:
if len(morphs) > 0:
sentences.append(morphs)
morphs = []
from pprint import pprint
for morpheme in sentences[:3]:
pprint(morpheme)
[{'base': '一', 'pos': '名詞', 'pos1': '数', 'surface': '一'}]
[{'base': '\u3000', 'pos': '記号', 'pos1': '空白', 'surface': '\u3000'},
{'base': '吾輩', 'pos': '名詞', 'pos1': '代名詞', 'surface': '吾輩'},
{'base': 'は', 'pos': '助詞', 'pos1': '係助詞', 'surface': 'は'},
{'base': '猫', 'pos': '名詞', 'pos1': '一般', 'surface': '猫'},
{'base': 'だ', 'pos': '助動詞', 'pos1': '*', 'surface': 'で'},
{'base': 'ある', 'pos': '助動詞', 'pos1': '*', 'surface': 'ある'},
{'base': '。', 'pos': '記号', 'pos1': '句点', 'surface': '。'}]
[{'base': '名前', 'pos': '名詞', 'pos1': '一般', 'surface': '名前'},
{'base': 'は', 'pos': '助詞', 'pos1': '係助詞', 'surface': 'は'},
{'base': 'まだ', 'pos': '副詞', 'pos1': '助詞類接続', 'surface': 'まだ'},
{'base': '無い', 'pos': '形容詞', 'pos1': '自立', 'surface': '無い'},
{'base': '。', 'pos': '記号', 'pos1': '句点', 'surface': '。'}]
31. 動詞
動詞の表層形をすべて抽出せよ.
result = set()
for sentence in sentences:
for morph in sentence:
if morph['pos'] =='動詞':
result.add(morph['surface'])
print(list(result)[:5])
['歌っ', '清め', '飛び降り', '溺れ', '弾き']
32. 動詞の基本形
動詞の基本形をすべて抽出せよ.
result = set()
for sentence in sentences:
for morph in sentence:
if morph['pos'] =='動詞':
result.add(morph['base'])
print(list(result)[:5])
['絞る', '騒ぎ出す', '惹く', '取り扱う', 'そり返る']
33. 「A の B」
2 つの名詞が「の」で連結されている名詞句を抽出せよ.
result = set()
for sentence in sentences:
for i in range(1, len(sentence) - 1):
if sentence[i - 1]['pos'] == '名詞' and sentence[i]['surface'] == 'の' and sentence[i + 1]['pos'] == '名詞':
result.add(sentence[i - 1]['surface'] + sentence[i]['surface'] + sentence[i + 1]['surface'])
print(list(result)[:5])
['古人のうち', '姿の三', '年の後', '輩の機能', 'リーシャスの援']
34. 名詞の連接
名詞の連接(連続して出現する名詞)を最長一致で抽出せよ.
result = set()
for sentence in sentences:
nouns = ''
count = 0
for morph in sentence:
if morph['pos'] == '名詞':
nouns = ''.join([nouns, morph['surface']])
count += 1
elif count >= 2:
result.add(nouns)
nouns = ''
count = 0
else:
nouns = ''
count = 0
if count >= 2:
result.add(nouns)
print(list(result)[:5])
['物騒', '今度寒月', '令嬢阿倍川', '人魚', '藁店']
35. 単語の出現頻度
文章中に出現する単語とその出現頻度を求め,出現頻度の高い順に並べよ.
from collections import defaultdict
result = defaultdict(int)
for sentence in sentences:
for morph in sentence:
if morph['pos'] != '記号':
result[morph['base']] += 1
result = sorted(result.items(), key=lambda x: x[1], reverse=True)
for res in result[:5]:
print(res)
('の', 9194)
('て', 6848)
('は', 6420)
('に', 6243)
('を', 6071)
36. 頻度上位 10 語
出現頻度が高い 10 語とその出現頻度をグラフ(例えば棒グラフなど)で表示せよ.
$ pip install japanize_matplotlib
import matplotlib.pyplot as plt
import japanize_matplotlib
plt.style.use('ggplot')
plt.figure(figsize=(12, 8))
plt.bar([res[0] for res in result[0:10]], [res[1] for res in result[0:10]], alpha=0.5)
plt.show()
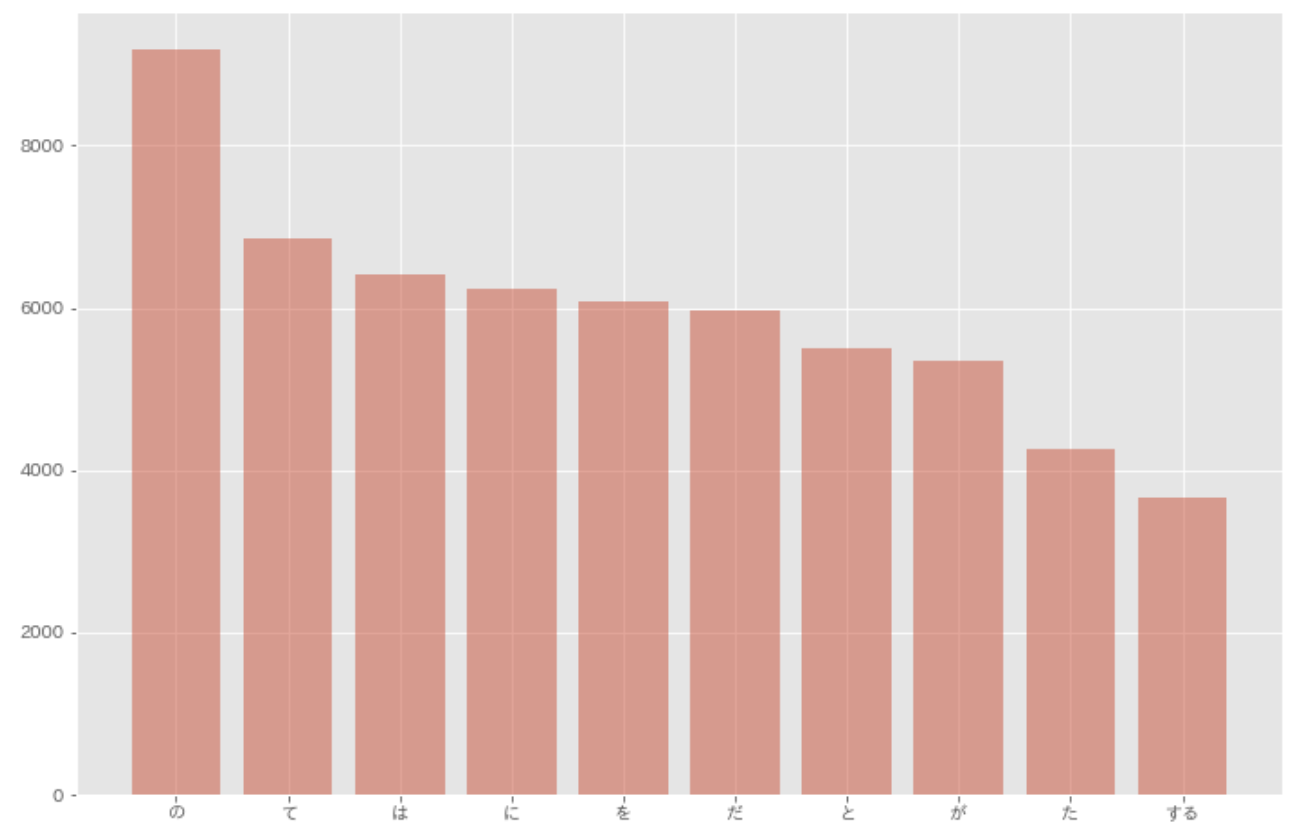
37. 「猫」と共起頻度の高い上位 10 語
「猫」とよく共起する(共起頻度が高い)10 語とその出現頻度をグラフ(例えば棒グラフなど)で表示せよ.
result = defaultdict(int)
for sentence in sentences:
if '猫' in [morph['surface'] for morph in sentence]:
for morph in sentence:
if morph['pos'] not in ['記号', '猫']:
result[morph['base']] += 1
result = sorted(result.items(), key=lambda x: x[1], reverse=True)
plt.figure(figsize=(12, 8))
plt.bar([res[0] for res in result[0:10]], [res[1] for res in result[0:10]], alpha=0.5)
plt.show()
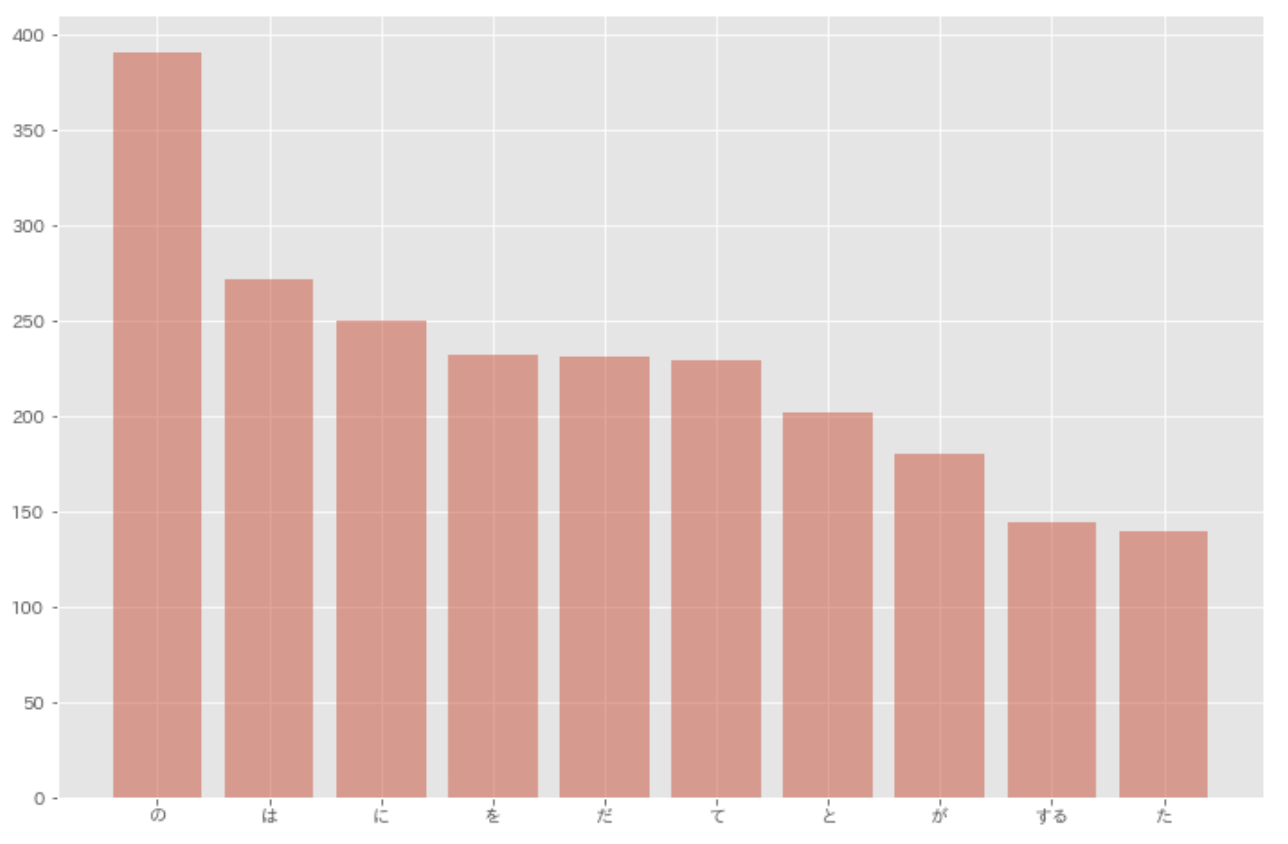
38. ヒストグラム
単語の出現頻度のヒストグラムを描け.ただし,横軸は出現頻度を表し,1 から単語の出現頻度の最大値までの線形目盛とする.縦軸は x 軸で示される出現頻度となった単語の異なり数(種類数)である.
result = defaultdict(int)
for sentence in sentences:
for morph in sentence:
if morph['pos'] != '記号':
result[morph['base']] += 1
result = result.values()
plt.figure(figsize=(12, 8))
plt.hist(result, bins=100, alpha=0.5)
plt.xlabel('frequency')
plt.ylabel('number of words')
plt.show()
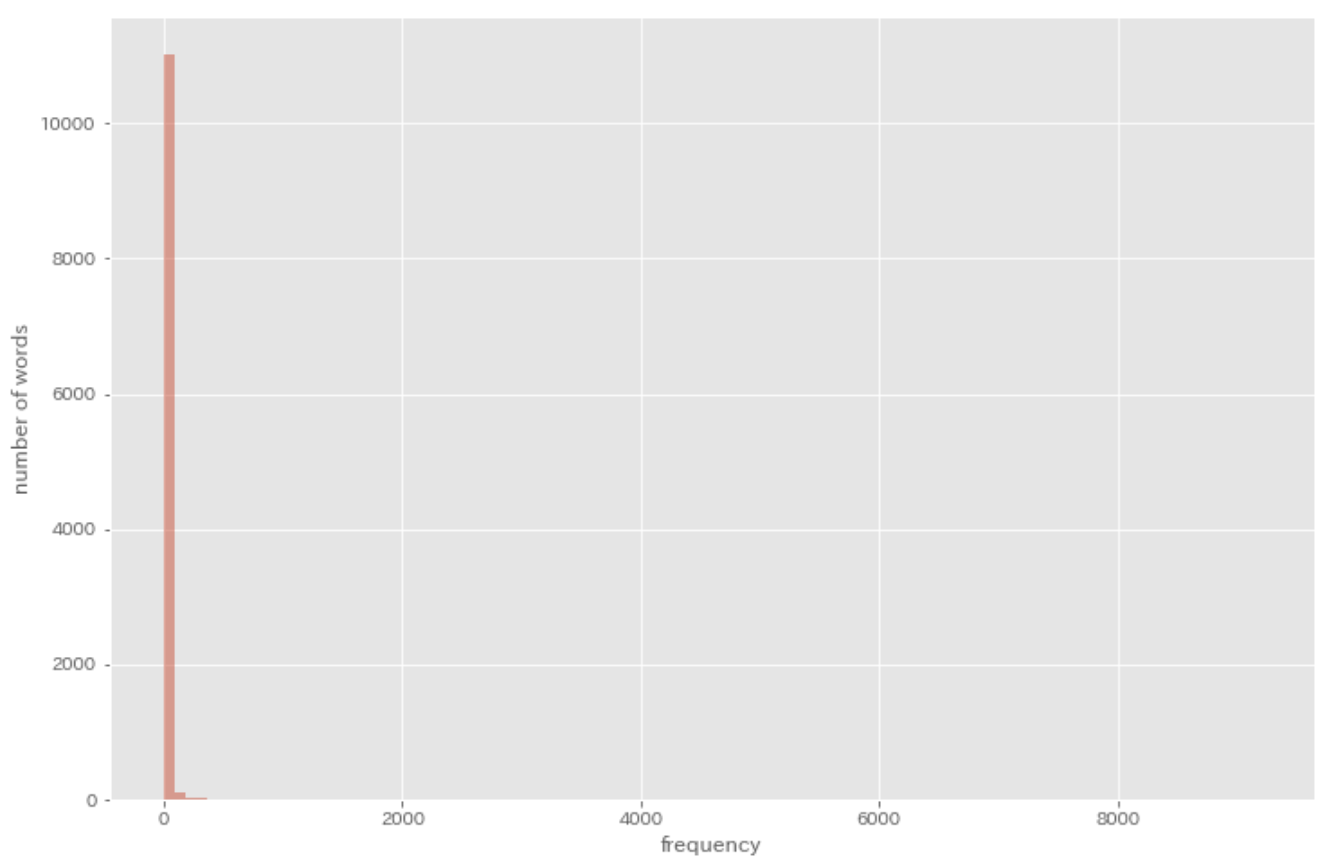
39. Zipf の法則
単語の出現頻度順位を横軸,その出現頻度を縦軸として,両対数グラフをプロットせよ.
result = defaultdict(int)
for sentence in sentences:
for morph in sentence:
if morph['pos'] != '記号':
result[morph['base']] += 1
result = sorted(result.items(), key=lambda x: x[1], reverse=True)
ranks = [res + 1 for res in range(len(result))]
values = [res[1] for res in result]
plt.figure(figsize=(12, 8))
plt.scatter(ranks, values, alpha=0.5)
plt.xscale('log')
plt.yscale('log')
plt.xlabel('log(rank)')
plt.ylabel('log(frequency)')
plt.show()
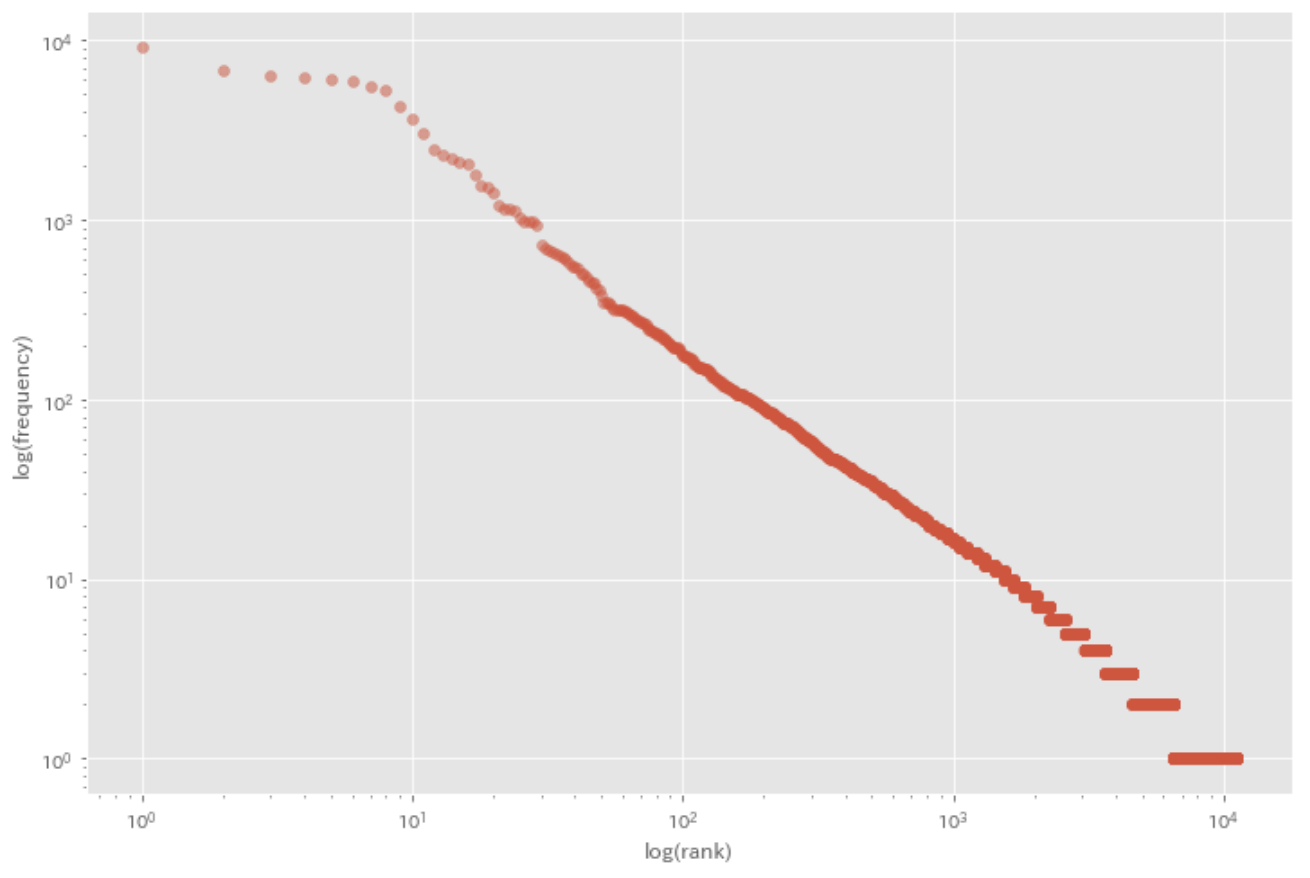
参考

















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS