
MLOps とは
MLOpsとは機械学習(ML)とDevOpsを掛け合わせた造語で、データ前処理、モデル開発、デプロイ、運用などを含む機械学習のライフサイクルを管理するための実践手法です。
MLシステムにおいて、 MLコードの割合はごく一部です。
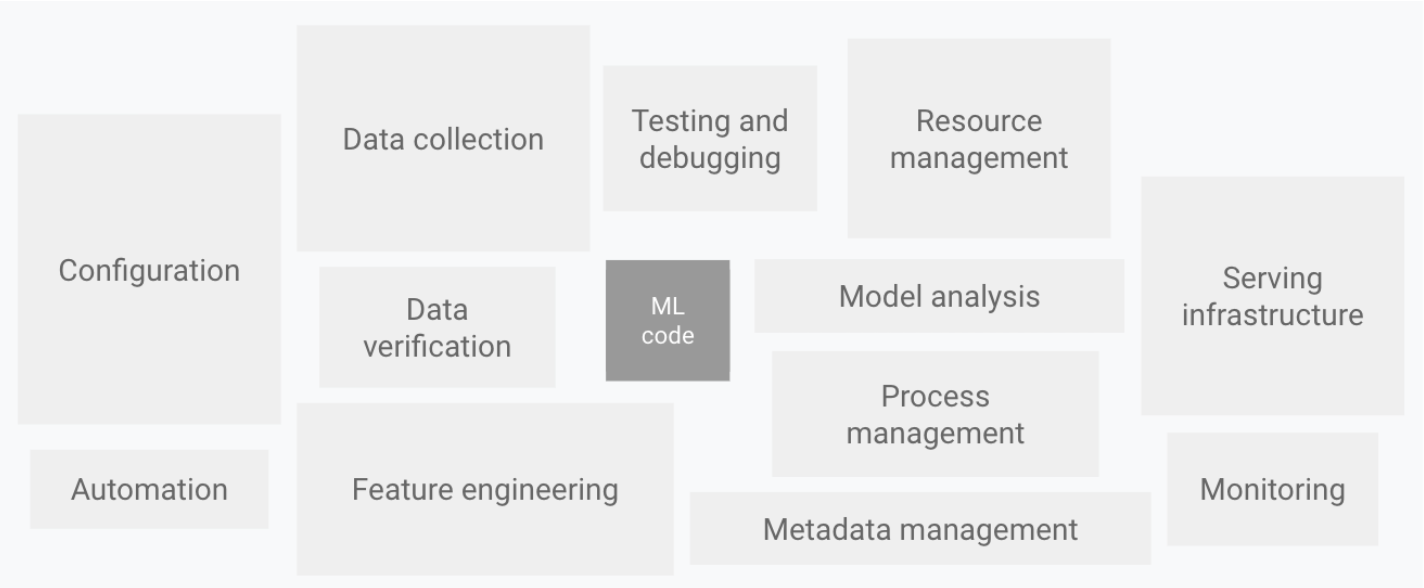
MLOps: Machine Learning Operations
機械学習の価値を実現するには、MLコードを含む複雑なMLシステムを本稼働環境で運用する必要があります。このような複雑なシステムに対処して持続的に開発や運用を行うためにMLOpsというワードが生まれました。
ML システムの課題
MLシステムの構築には次のような特有の課題があります。
-
機械学習以外の開発に工数がかかる
機械学習システムには、アプリケーションへの組み込みやデータパイプラインの構築など、機械学習以外の開発や運用の工数が必要です。 -
実用レベルに達するまでに時間がかかる
機械学習は技術が複雑で曖昧な面も多く、開発環境で実証できたものでも本番環境でトラブルが生じ、PoCでとどまってしまうケースも少なくありません。 -
実験の再現性が担保されない
モデルの開発段階では問題なく稼動していたコードを本番環境へ搭載するとエラーになることがあります。また、同じデータで同じモデルを学習させた場合でも違う結果が出力されることがあります。 -
モデルの品質を保ちにくい
モデルはリリースした時点で高品質であったとしても、何らかの予期せぬ変化により、時間の経過とともに品質は劣化していきます。モデルをリリースして終わりではなく、継続的な改善を重ねて最新の状態に保つ必要があります。 -
チーム間で対立しやすい
機械学習システムにはデータエンジニア、データサイエンティスト、機械学習エンジニア、システムエンジニアなどの様々な専門家が加わります。多様な人材でチームが構成されるため、トラブルが生じたときにチーム内で衝突しやすくなります。
MLOps の原則
機械学習パイプラインは、データ、機械学習モデル、コードの3つ観点で変化が起こります。MLOpsは原則として、次の点に着目します。
- 自動化
- Continuous X
- バージョン管理
- 実験の追跡
- テスト
- モニタリング
- 再現性
自動化
データ、モデル、パイプラインの自動化レベルは、MLプロセスの成熟度を決定します。成熟度が上がれば、新しいモデルのトレーニングの速度も上がります。MLモデルのシステムへのデプロイメントを手動で介入することなく自動化することが重要になります。
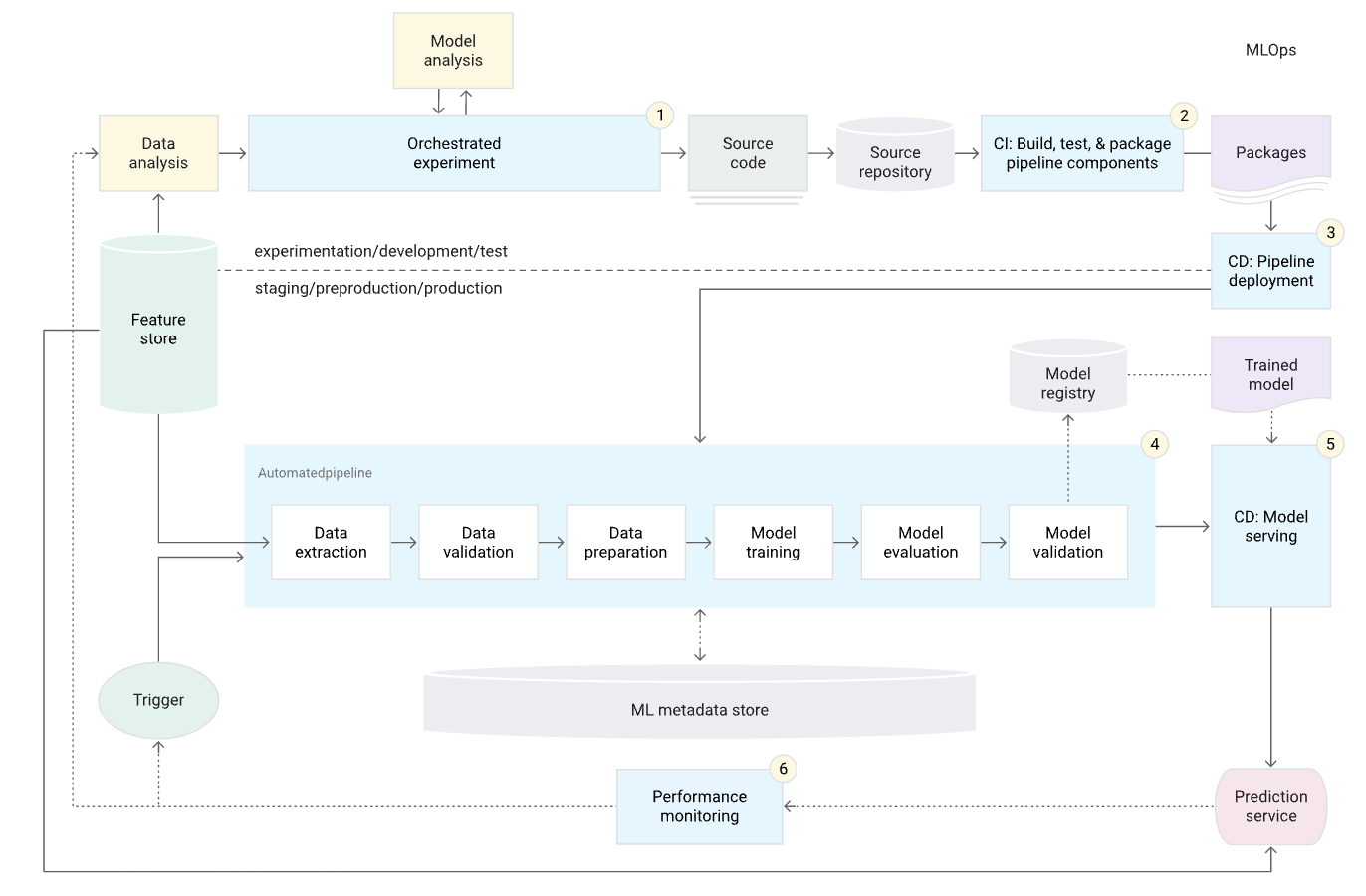
MLOps: Machine Learning Operations
Continuous X
MLOpsは次のようなプラクティスを含みます。
-
Continuous Integration (CI)
コード、データ、モデルのテスト -
Continuous Delivery (CD)
自動的に別のMLモデルをデプロイするMLトレーニングパイプラインのデリバリー -
Continuous Training (CT)
MLモデルを自動的に再トレーニングして再デプロイ -
Continuous Monitoring (CM)
本番環境のデータおよびモデルのパフォーマンスをモニタリング
バージョン管理
MLスクリプト、モデル、データセットをDevOpsプロセスの本質的な部分として扱います。MLモデルやデータは変更される場合があるため、バージョン管理システムでそれらを追跡することが重要です。MLモデルやデータが変更される一般的な理由は次のとおりです。
- モデルが新しいトレーニングデータに基づいて再トレーニングされる
- モデルが新しい学習方法に基づいて再学習される
- モデルが時間の経過とともに劣化する
- モデルが新しいアプリケーションで展開される
- モデルは攻撃され、改訂が必要になる
- データが何らかの理由で消える
- データの所有権が問題になる
- データの統計的分布が変化する
実験の追跡
機械学習の開発は反復的で研究中心的なプロセスです。従来のソフトウェア開発プロセスとは対照的に、ML開発では、どのモデルを本番に昇格させるかを決定する前に、モデルの学習に関する複数の実験を並行して実行します。それらの実験の内容を追跡しておく必要があります。
テスト
ML開発パイプラインは次の3つの要素で構成されています。
- データパイプライン
- MLモデルパイプライン
- アプリケーションパイプライン
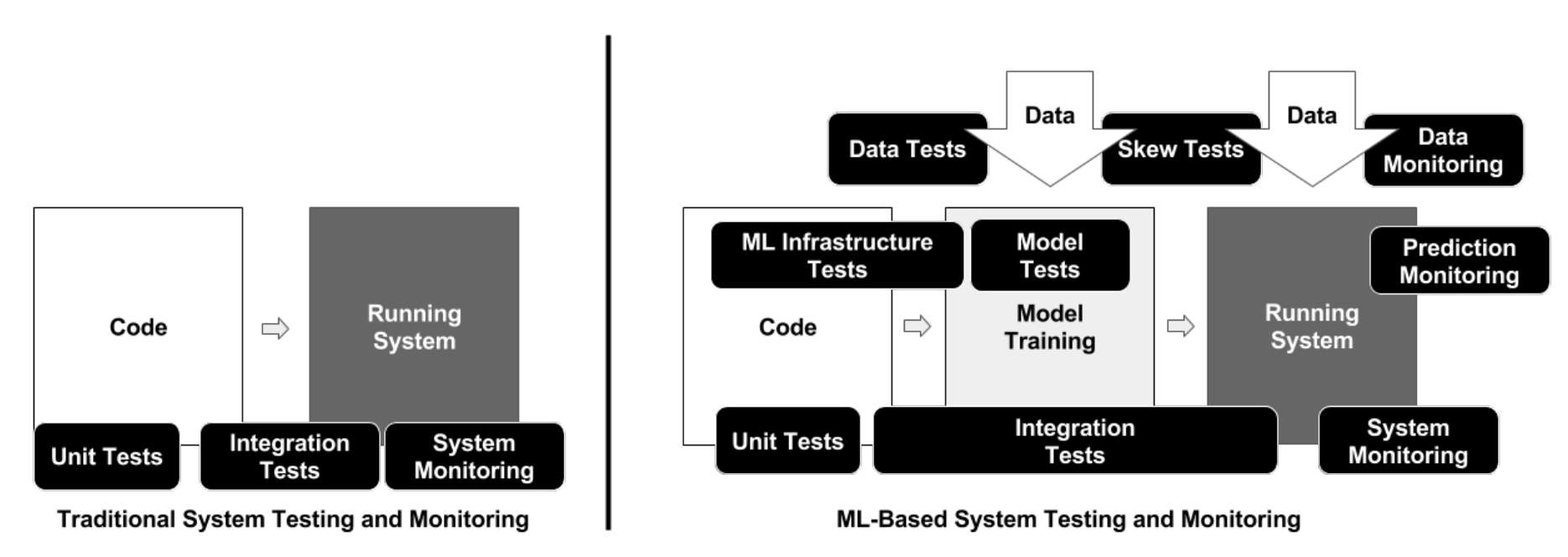
The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction
この分離に従って、MLシステムにおけるテストを次の3つのスコープに区別します。
- 特徴量とデータのテスト
- モデル開発のテスト
- MLインフラストラクチャのテスト
特徴量とデータのテスト
-
データと特徴量のスキーマを自動チェック
- スキーマを構築するために、学習データから統計値を計算する
-
新しい特徴量が予測力を高めるかどうかを理解するために特徴量重要度テストを実施
- 特徴列の相関係数を計算する
- 1つまたは2つの特徴量でモデルを学習する
- 新しい特徴量のデータ依存性、推論レイテンシ、RAM使用量を測定する
- インフラストラクチャから未使用や非推奨の特徴量を削除し、それを文書化する
-
特徴量とデータパイプラインは、GDPR などのポリシーに準拠しているか確認
-
特徴量作成コードのユニットテストを実施
モデル開発のテスト
-
ML アルゴリズムの損失指標(MSE など)とビジネスインパクト指標(収益、ユーザーエンゲージメントなど)との相関をチェック
- 意図的に劣化させたモデルを使用した小規模なA/Bテストを行う
-
モデルの陳腐化テストを実施
- 古いモデルでA/Bテストを行う
-
モデルの性能を検証
- トレーニングセットとバリデーションセットから切り離された追加のテストセットを使用する
-
ML モデルの性能の公平性やバイアスのテストを実施
- 潜在的に過小評価されているカテゴリを含むより多くのデータを収集する
ML インフラストラクチャのテスト
-
ML モデルの学習の再現性を担保
- モデル学習コードベースで非決定的な部分を特定し、非決定性を最小化するよう努力する
-
ML API のストレステストを実施
- 入力データをランダムに生成し、モデルを学習させるユニットテストを行う
- モデル学習のためのクラッシュテストを行う(学習途中でのクラッシュの後、チェックポイントからMLモデルを復元できるかどうかをテストする)
-
アルゴリズムの正しさをチェック
- MLモデルの学習を完了させるのではなく、数回繰り返し学習させ、学習中に損失が減少することを確認するユニットテストを行う
-
ML パイプライン全体の統合テストを実施
- MLパイプライン全体を定期的にトリガーする完全自動化テストを作成する
-
ML モデルをサービングする前に検証
- 閾値を設定し、バリデーションセットの多くのバージョンに渡ってモデルの品質がゆっくりと劣化していくことをテストする
- 閾値を設定し、新しいバージョンのMLモデルで突然の性能低下をテストする
モニタリング
デプロイしたMLモデルが期待通りに動作していることを保証するために次のモニタリングする必要があります。
-
パイプライン全体を通して依存関係の変更を監視し、その結果を通知
- データのバージョン変更
- ソースシステムの変更
- 依存関係のアップグレード
-
トレーニングとサービングのインプットのデータ不変量を監視
- サービング時のデータがトレーニング時で指定されたスキーマと一致しない場合にアラートを出す
-
トレーニング時とサービング時の特徴量が同じ値を算出するかどうかを監視
- サービングトラフィックのサンプルをログに記録する
- トレーニング時の特徴量とサンプルされたサービングの特徴量の記述統計(最小、最大、平均、値、欠損値の割合など)を計算し、それらが一致することを確認する
-
本番環境のシステムがどの程度古くなっているかを監視
- 本番環境にデプロイする前に、監視ための要素を特定し、モデルの監視のための戦略を作成する
-
ML システムの計算性能を監視
- 警告の閾値を事前に設定し、コード、データ、モデルのバージョンとコンポーネントのパフォーマンスを測定する
- GPUメモリの割り当て、ネットワークトラフィック、ディスク使用量などのシステム使用量のメトリクスを収集する å
-
特徴量生成のプロセスを監視
- 特徴量生成を頻繁に再実行する
-
ML モデルの予測性能の劇的な劣化と緩やかな劣化を監視
- 予測値の統計的バイアス(データのスライスにおける予測値の平均値)を測定する
- 予測直後にラベルがある場合はリアルタイムで予測の品質を測定する
再現性
MLパイプラインにおける再現性とは、MLモデル開発の各フェーズで、同じ入力があれば同じ結果が得られることを意味します。再現性はMLOpsの重要な原則です。次のフェーズにおいて再現性を持たせるために実施すべきことを紹介します。
- データ収集のフェーズ
- 特徴量エンジニアリングのフェーズ
- モデルの学習やビルドのフェーズ
- モデルのデプロイのフェーズ
データ収集のフェーズ
学習データ生成の再現性を持たせるために次のことを実施します。
- 常にデータのバックアップを取る
- データセットのスナップショットを保存する
- データソースはタイムスタンプを使用して設計する
- データのバージョニングをする
特徴量エンジニアリングのフェーズ
特徴量エンジニアリングの再現性を持たせるために次のことを実施します。
- 特徴量生成コードをバージョン管理下に置く
モデルの学習やビルドのフェーズ
モデルの学習やビルドの再現性を持たせるために次のことを実施します。
- 特徴量の順序が常に同じになるようにする
- 正規化などの特徴量変換を文書化し、自動化する
- ハイパーパラメータの選択を文書化し、自動化する
モデルのデプロイのフェーズ
モデルのデプロイの再現性を持たせるために、次のことを実施します。
- ソフトウェアのバージョンや依存関係は本番環境と一致させる
- Dockerを使用し、イメージバージョンなどその仕様を文書化する
MLOps を実現するツール
MLOpsの実現には次のようなツールが有効です。
- バージョン管理: GitHub、GitLab
- コンテナ: Docker
- コンテナオーケストレーション: Kubernetes, Mesos
- CI: Circle CI, Jenkins, GitHub Actions, Gitlab CI
- Infrastructure as Code (IaC): Terraform, Ansible, Pupet
- 監視: Sentry, Datadog, Prometheus, Deequ
- モデルサービング: FastAPI, KFServing, BentoML, Vertex AI, Sagemaker
- 機械学習プラットフォーム: Sagemaker, Vertex AI
- 特徴量ストア: Feast, Hopworks, Rasgo, Vertex AI, SageMaker, Databricks, Tecton, Zipline
- 実験管理: Weights & Biases, MLFlow, Trains, Comet, Neptune, TensorBoard
- パイプライン管理: Airflow, Argo, Digdag, Metaflow, Kubeflow, Kedro, TFX, Prefect
- ハイパーパラメータ最適化: Scikit-Optimize, Optuna, Hydra
参考


















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS