

決定係数(R2)とは
決定係数(
ここで、
y_i i \hat{y_i} i \bar{y}
R2と適合度
適合度は、統計モデルが観測データにどの程度フィットしているかを示す指標です。より高い
R2と相関係数
相関係数(
調整済みR2
調整済み
ここで、
調整済み
Pythonを使用したR2の計算
この章では、Pythonを使用して、カリフォルニア住宅データセットを使用して、
まず、必要なライブラリをインポートし、カリフォルニア住宅データセットを読み込みます。これは、回帰分析に広く使用されている一般的なパブリックデータセットです。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
from sklearn.model_selection import train_test_split
from sklearn.datasets import fetch_california_housing
# Load the California Housing dataset
california = fetch_california_housing()
data = pd.DataFrame(california.data, columns=california.feature_names)
data['Price'] = california.target
次に、scikit-learnのLinearRegressionクラスを使用して、線形回帰分析を実行し、r2_score関数を使用してMedIncと悪い独立変数であるHouseAgeを使用して、2つの別々の線形回帰モデルを作成し、両方のモデルの
# Good regression (MedInc vs. Price)
X_good = data[['MedInc']]
y_good = data['Price']
model_good = LinearRegression()
model_good.fit(X_good, y_good)
y_pred_good = model_good.predict(X_good)
r_squared_good = R2_score(y_good, y_pred_good)
print(f'R2 (Good Regression - MedInc vs. Price): {r_squared_good:.2f}')
# Bad regression (HouseAge vs. Price)
X_bad = data[['HouseAge']]
y_bad = data['Price']
model_bad = LinearRegression()
model_bad.fit(X_bad, y_bad)
y_pred_bad = model_bad.predict(X_bad)
r_squared_bad = R2_score(y_bad, y_pred_bad)
print(f'R2 (Bad Regression - HouseAge vs. Price): {r_squared_bad:.2f}')
R2 (Good Regression - MedInc vs. Price): 0.47
R2 (Bad Regression - HouseAge vs. Price): 0.01
期待通り、良い回帰(MedInc vs. Price)のHouseAge変数がデータに適合していないことを示しています。
最後に、従属変数であるPriceと良い独立変数であるMedInc、そして悪い独立変数であるHouseAgeの間の関係を視覚化します。
# Good regression (MedInc vs. Price)
plt.figure(figsize=(10, 6))
sns.regplot(x='MedInc', y='Price', data=data, scatter_kws={'alpha': 0.3}, line_kws={'color': 'red'})
plt.title('Good Regression: MedInc vs. Price')
plt.xlabel('Median Income')
plt.ylabel('Price')
plt.show()
# Bad regression (HouseAge vs. Price)
plt.figure(figsize=(10, 6))
sns.regplot(x='HouseAge', y='Price', data=data, scatter_kws={'alpha': 0.3}, line_kws={'color': 'red'})
plt.title('Bad Regression: HouseAge vs. Price')
plt.xlabel('House Age')
plt.ylabel('Price')
plt.show()
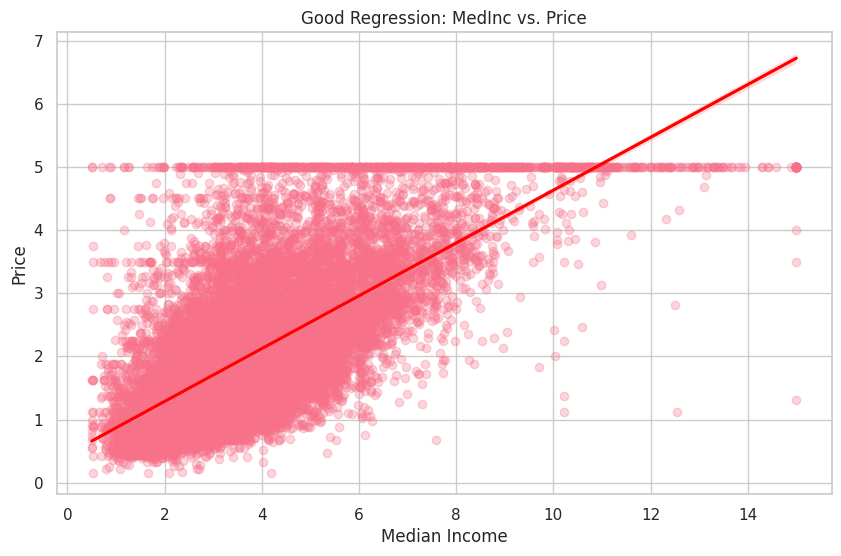
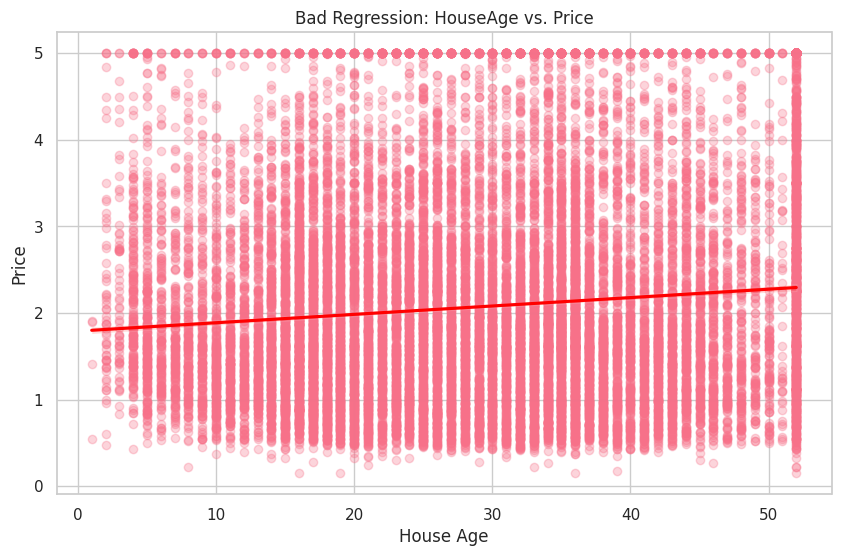
最初のプロットでは、MedIncとPriceの間に明確な正の関係が見られます。一方、2番目のプロットは、HouseAgeとPriceの間の関係が弱いことを示しています。

















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS