



Hugging Face Transformers Model
The Hugging Face Transformers library provides many pre-trained models that can be easily used and applied to new tasks. At the same time, you can register your own pre-trained models in the Model Hub and share them with other users.
This article describes Models.
Derivative model of Transformer
The architecture of Transformer is shown in the figure below.
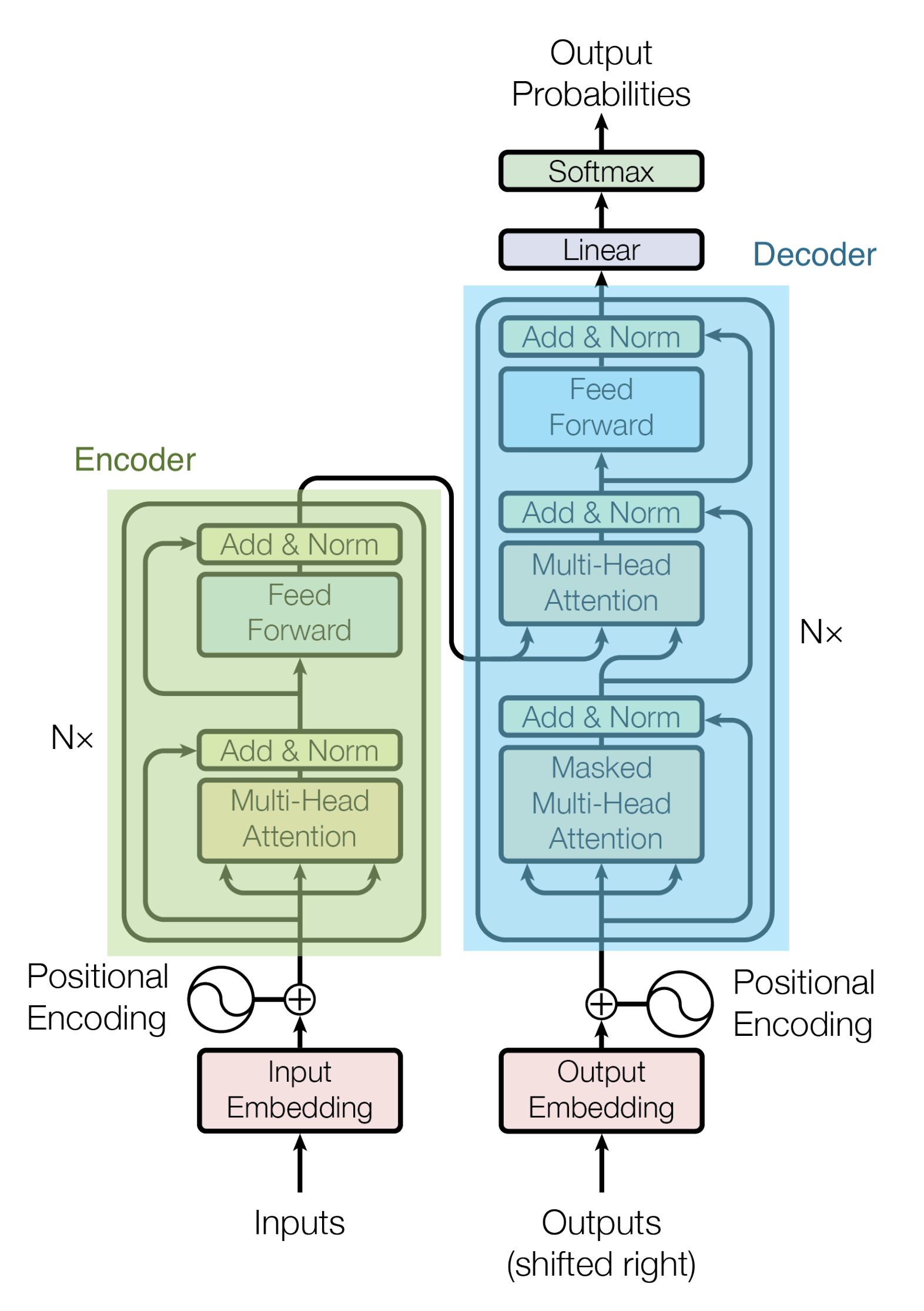
As a derivative model of Transformer, the following models use Encoder and Decoder separately.
- Encoder model
- BERT
- ALBERT
- RoBERTa
- DistilBERT
- XLM
- XLM-RoBERTa
- ELECTRA
- Decoder model
- GPT
- GPT-2
- CTRL
- Reformer
- XLNet
- Encoder-Decoder model
- BART
- T5
- MBart
Encoder model
The Encoder model uses only the Encoder portion of the Transformer. The Attention layer is a bidirectional Attention that can attend to all words in the input series data and can also attend to words before and after each word.
Since the Encoder model outputs a feature representation of the input data, it is suitable for tasks that can be modeled by passing it to a classifier. For example, it is good at document classification, unique expression recognition, and question answering in which the answer portion is extracted from the target document.
BERT
BERT is an bi-directional Transformer pre-trained on a large corpus consisting of Wikipedia and Bookcorpus.
ALBERT
ALBERT is a model for BERT with the following tweaks:
- Decouples the embedding dimension of tokens from the dimension of the hidden layer, reducing the embedding dimension
- Reducing the number of parameters by having all layers share the same parameters
- Next sentence prediction is replaced by sentence order prediction
RoBERTa
RoBERTa is a BERT-based model with more training data and larger batches trained for longer periods of time.
DistilBERT
DistilBERT is a distillation of BERT by using Knowledge Distillation in the pre-training phase, achieving 97% of BERT's performance while using 40% less memory and 60% faster. 97% of BERT's performance, while using 40% less memory and 60% faster.
XLM
XLM is a multi-lingual learned Transformer. There are three different types of training for this model:
- Causal language modeling (CLM)
- Masked language modeling (MLM)
- Combination of MLM and Translation language modeling (Translation language modeling, TLM)
XLM-RoBERTa
XLM-RoBERTa is a model trained on a 2.5TB dataset using the Common Crawl corpus. The translated language model used in XLM has been removed because this dataset does not include translations.
ELECTRA
ELECTRA is a new pre-training approach that trains two transformers: a Generator and a Discriminator. The role of the Generator is to replace tokens in a sequence and is therefore trained as a masked language model. The Discriminator, on the other hand, is a model that attempts to identify which tokens in a sequence have been replaced by the Generator.
Decoder model
The Decoder model uses only the Decoder portion of the Transformer. It is trained by setting up a task to predict the next word for each word in the input sequence data, and the Attention layer focuses only on the words that precede each word in the input data.
The Attention layer focuses only on the words that precede each word in the input data, making the Decoder model suitable for tasks such as text generation.
GPT
GPT is a large-scale language model proposed by OpenAI in 2018 called Generative Pre-trained Transformer, which features the ability to generate natural sentences without task-specific training GPT uses a model to predict the next word based on the previous word GPT uses pre-training to predict the next word based on the previous word.
GPT is pre-trained on the Book Corpus dataset.
GPT-2
GPT-2 is the successor to GPT proposed by OpenAI in 2019; GPT2 was created by scaling up GPT's model and training dataset.
CTRL
CTRL is a model that allows control over the style of the generated series by adding a control token at the beginning of the series.
Reformer
Reformer is a Decoder model with many improvements to reduce memory footprint and computation time.
XLNet
XLNet is a model that pre-trains using an autoregressive method and learns bidirectional context by maximizing the expected likelihood for all permutations of the decomposition order of the input sequence.
Encoder-Decoder model
The Encoder-Decoder model leverages the entire Transformer architecture.
The Encoder part focuses on all words in the input sequence data, while the Decoder part focuses only on the words that precede each word; training proceeds by setting up both the task of solving fill-in-the-blanks problems in the Encoder model and predicting the next word in the Decoder model.
The Encoder-Decoder model is suitable for tasks such as machine translation and dialogue systems that input text and output different text depending on its content.
BART
BART combines BERT and GPT pre-training within the Encoder and Decoder architecture.
T5
T5 is a model proposed by Google in 2020 and stands for Text-to-Text Transfer Transformer; T5 can transform all natural language understanding and natural language generation tasks into text transformation tasks and solve them in a unified way.
MBart
MBART is a model pre-trained on a large monolingual corpus of 25 languages with BART objectives. MBART is one of the first methods to pre-train a model between complete sequences by denoising complete texts in multiple languages.
How to use Model
Install the Transformer library.
$ pip install transformers
Load a model
The AutoModel class allows you to easily use a model by specifying the checkpoint of the model you want to use. In the example below, the model bert-base-uncased is specified.
from transformers import AutoModel
checkpoint = 'bert-base-uncased'
model = AutoModel.from_pretrained(checkpoint)
Many pre-trained models are available on Hugging Face Transformers. The models can be viewed in detail at the following link.
Model structure
For example, if you use BERT, you may read as follows.
from transformers import BertConfig, BertModel
config = BertConfig()
model = BertModel(config)
print(config)
BertConfig {
"attention_probs_dropout_prob": 0.1,
"classifier_dropout": null,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"position_embedding_type": "absolute",
"transformers_version": "4.24.0",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 30522
}
The meaning of each attribute can be found at the following link.
Save the model
You can save your model with the following code. If the destination directory does not exist, a folder will be automatically created.
model.save_pretrained("./tmp")
When you save the file, the following two types of files are saved.
config.jsonpytorch_model.bin
Load a saved model
To load a saved model, write the following code
saved_model = model.from_pretrained("./tmp")
Cautions when using pre-trained Transformer models
It is important to note that pre-trained models contain a certain amount of bias.
Using BERT's fill-mask Pipeline, I will prepare two types of occupational sentences, one with the subject as male and one with the subject as female, and let the model output word candidates by masking the part of the sentence that corresponds to the name of the occupation.
from transformers import pipeline
unmasker = pipeline("fill-mask", model="bert-base-uncased")
result = unmasker("This man works as a [MASK].")
print("man:", [r["token_str"] for r in result])
result = unmasker("This woman works as a [MASK].")
print("woman:", [r["token_str"] for r in result])
man: ['carpenter', 'lawyer', 'farmer', 'businessman', 'doctor']
woman: ['nurse', 'maid', 'teacher', 'waitress', 'prostitute']
In both cases, the results show that there is no overlap between the two, indicating that there are differences depending on the gender. Furthermore, the fifth candidate, prostitute, a word with pejorative connotations, is output when the subject is female.
The BERT model was pre-trained on Wikipedia and Bookcorpus, two datasets that may not contain much prejudice. But it may produce results like this in some cases.
References















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS