

What is Transformer
Transformer is a deep learning model that first appeared in a paper on NLP called Attention Is All You Need published by Google in 2017. Transformer is an Encoder-Decoder model using only Attention, unlike the Encoder-Decoder models using RNNs that had been mainstream in the NLP world until then.
Transformer is an important basic model used in current state-of-the-art NLP models. Recently, Transformer is also starting to be used in the area of image recognition.
Features of Transformer
Transformer has the following features:
- Built only with Attention layer without RNN
- It achieves parallel computation, which is not possible when RNN is used together, and speeds up the computation.
- Adoption of Positional Encoding layer
- The input word data can retain contextual information by embedding the positional information of words in the whole sentence.
- Adoption of Query-Key-Value model in the Attention layer
- It improves accuracy by more accurately reflecting word-word correspondence
Transformer development history
Historically, Transformer was born from the following model development flow.
- RNN
- Seq2seq
- Seq2seq with Attention
- Transformer
RNN
The language model requires contextual processing. For example, suppose we have the following sentence.
Bob gets an apple. He eats it.
Here, it is impossible to know who "he" is and what "it" is without understanding the context.
This is where recursive models that can retain dependency information for entire sentences, such as RNNs, come into being. The idea is that when the input data is transformed into a fixed-length vector, the information from previous words is also taken into account; in RNNs, the same function is used recursively to output sequentially, and the previous output is included as part of the data used for the next input.
RNNs are now able to reflect context, but RNNs are computed sequentially and cannot parallelize the computation, which leaves the problem that it is difficult to speed up the computation.
Seq2seq
The Seq2seq model (RNN with Encoder-Decoder) is devised to utilize different time series data, such as machine translation.
In Seq2seq, the input data is converted to a single fixed-length vector in the Encoder-Decoder and used in the same way as in RNNs. While Seq2seq has achieved great results in terms of converting different time series data, the following issues become apparent:
- Compression into a fixed-length vector prevents the information from being fully contained in long sentences.
- The use of collocations between words and sentences is not possible.
The use of correlations is especially important when dealing with different time-series data, such as in translation tasks. For example, it means that a more accurate translation will be possible if you use the correspondence between "water" and "eau (water in French)" rather than just vaguely searching for what "water" means.
Seq2seq with Attention
Seq2seq with Attention solved the problem of Seq2seq by using the fixed-length vector created from the Encoder portion of Seq2seq, but only the last part of the vector was used. By using all of the fixed-length vectors output when each word is input, the following is possible
- The same number of fixed-length context vectors as the number of words can be acquired (the amount of information corresponding to the length of the sentence can be acquired).
- Attention allows for the acquisition of correspondence between words.
Transformer
Although the accuracy was improved by using Attention, it had the problem of not being able to parallelize and accelerate the computation, which was caused by using RNN in combination.
Therefore, Transformer, which uses only the Attention layer without RNN, was born, solving the problems of RNN and Seq2seq with Attention, such as lack of parallelization and inability to build accurate dependency models. Transformer has succeeded in solving the problems of RNN and Seq2seq with Attention.
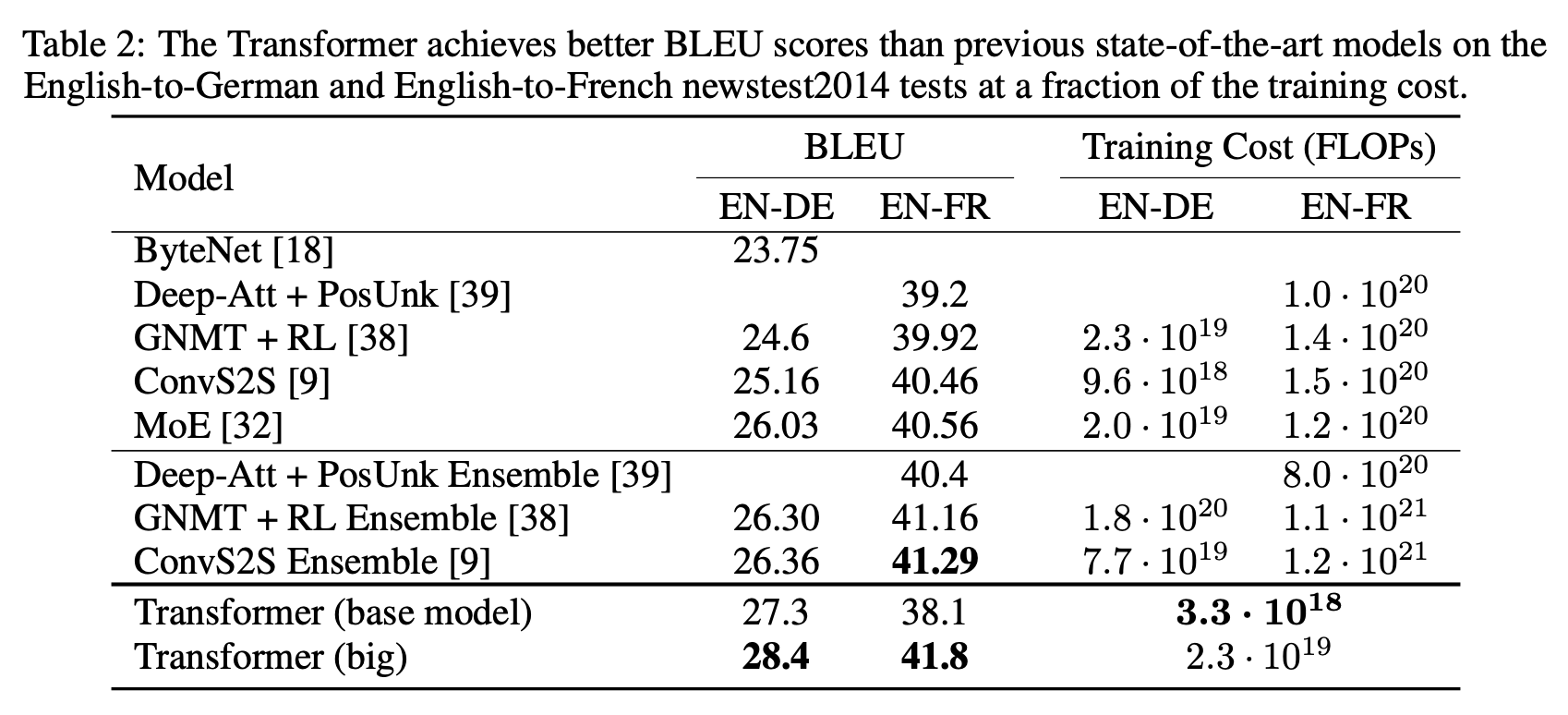
Transformer achieved the following in the WMT 2014 English-German (EN-DE) and English-French (EN-FR) translation tasks
- Established the highest BLEU score at the time
- and kept training costs to a fraction of competitive models
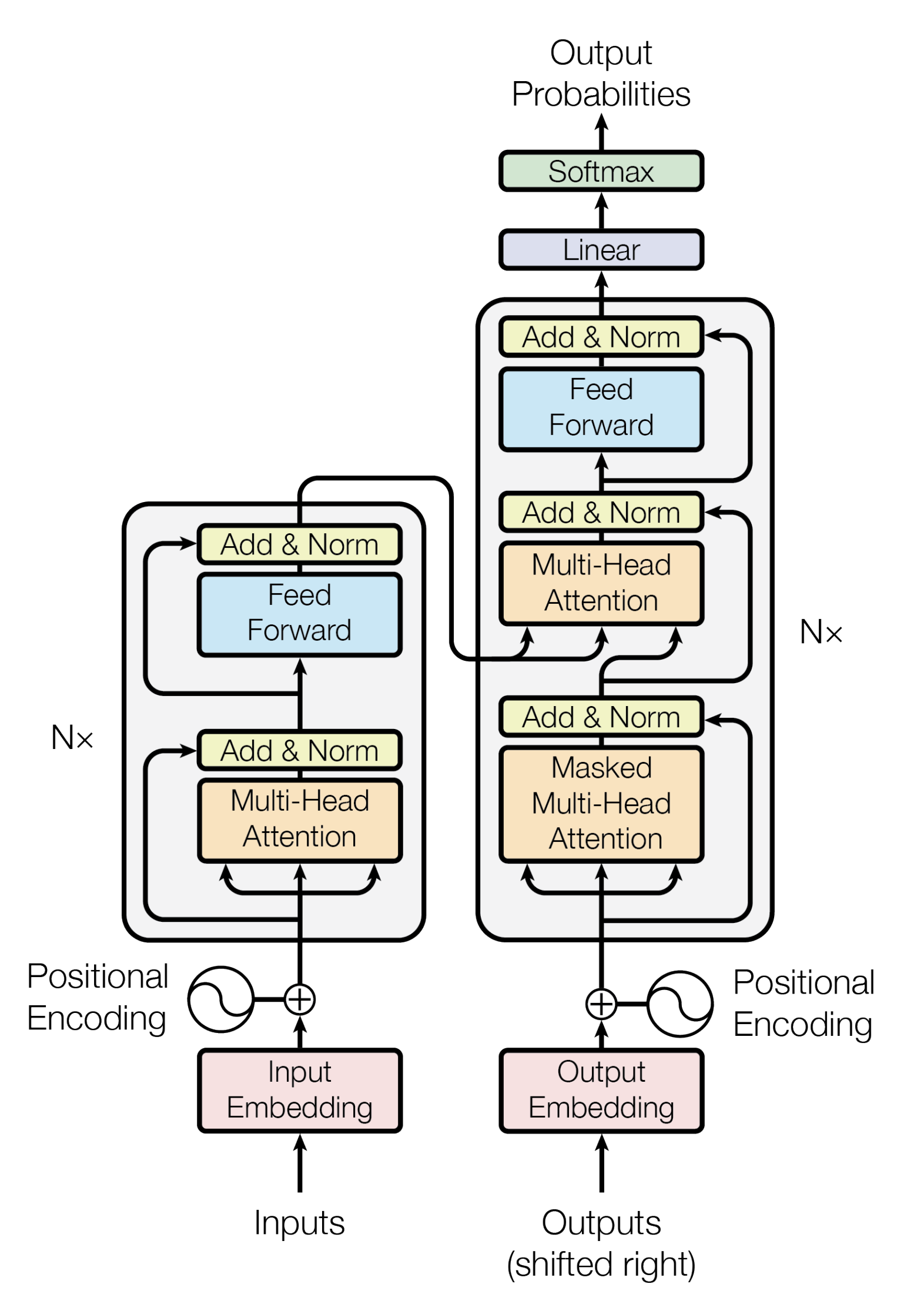
Transformer Architecture
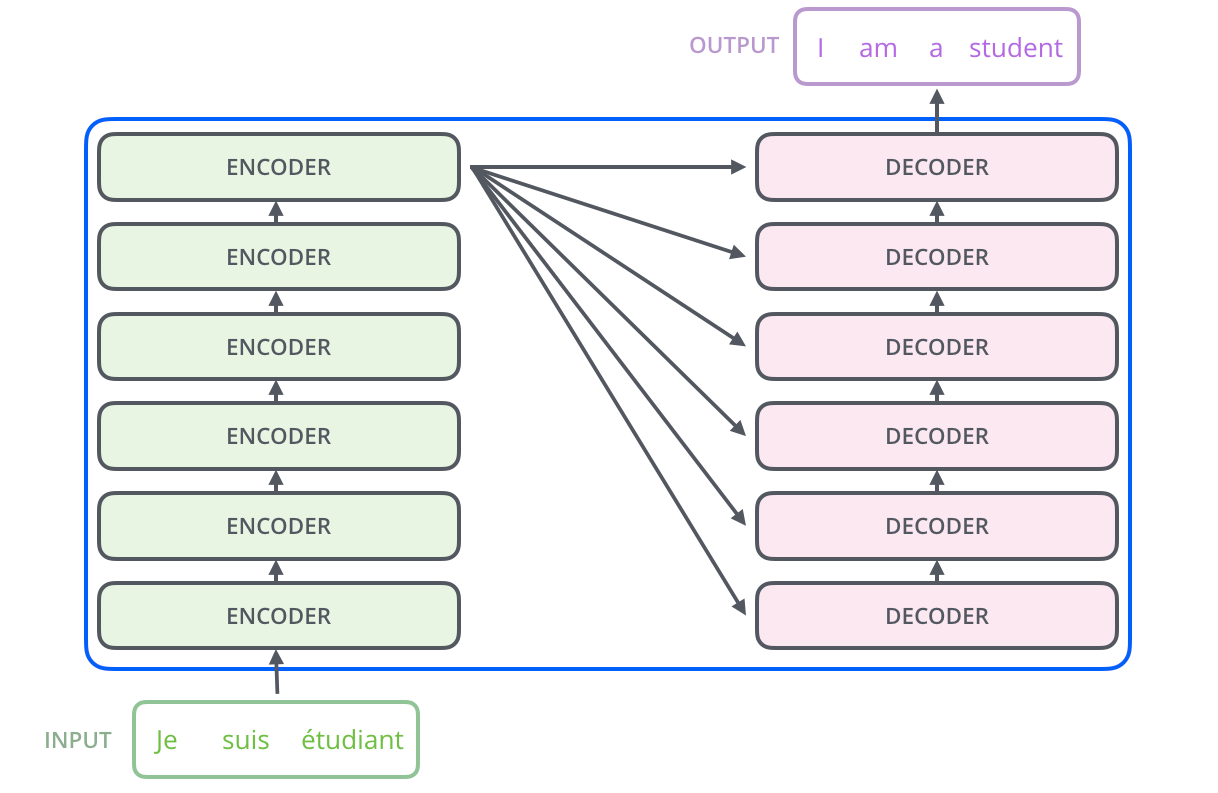
The following is the architecture of the Transformer during a translation task.
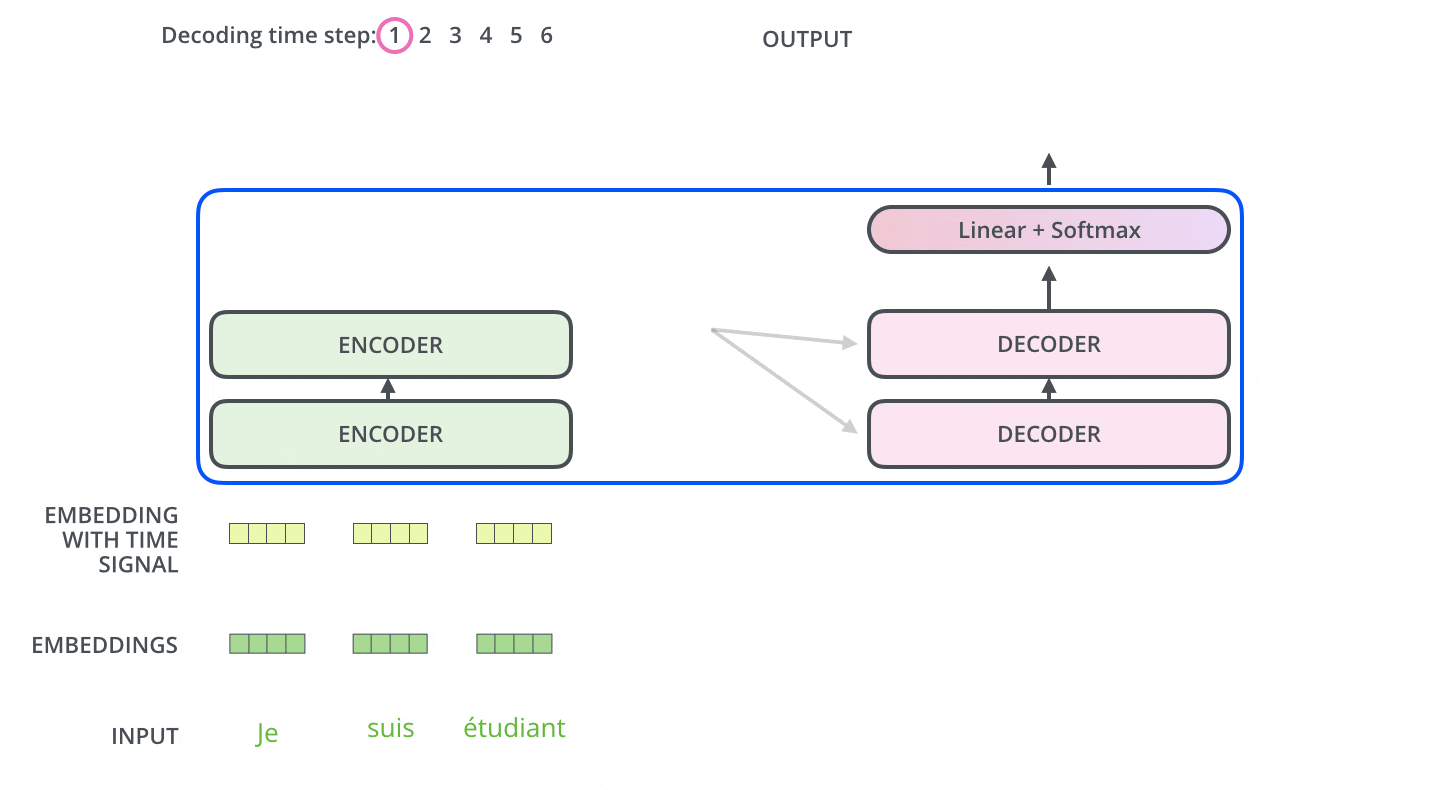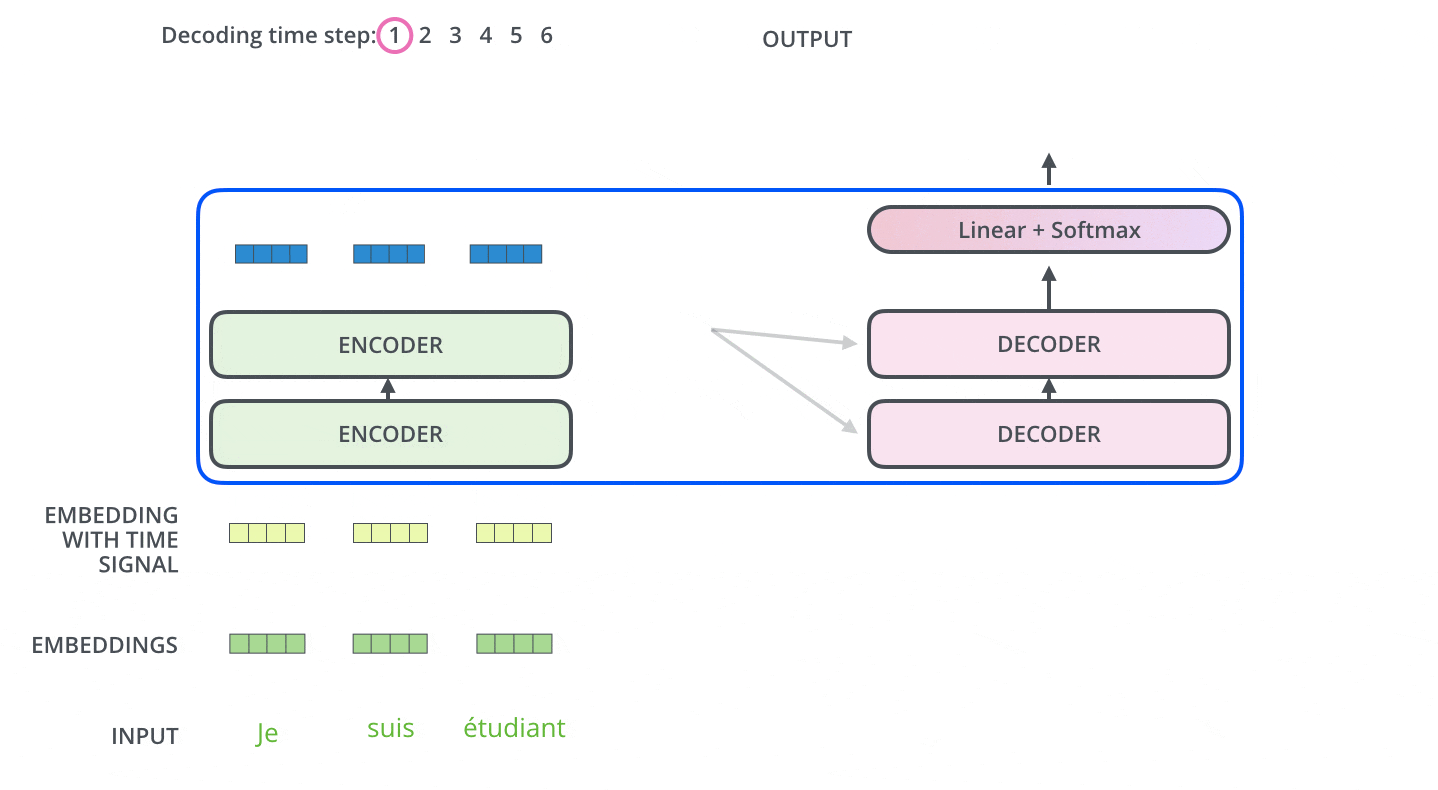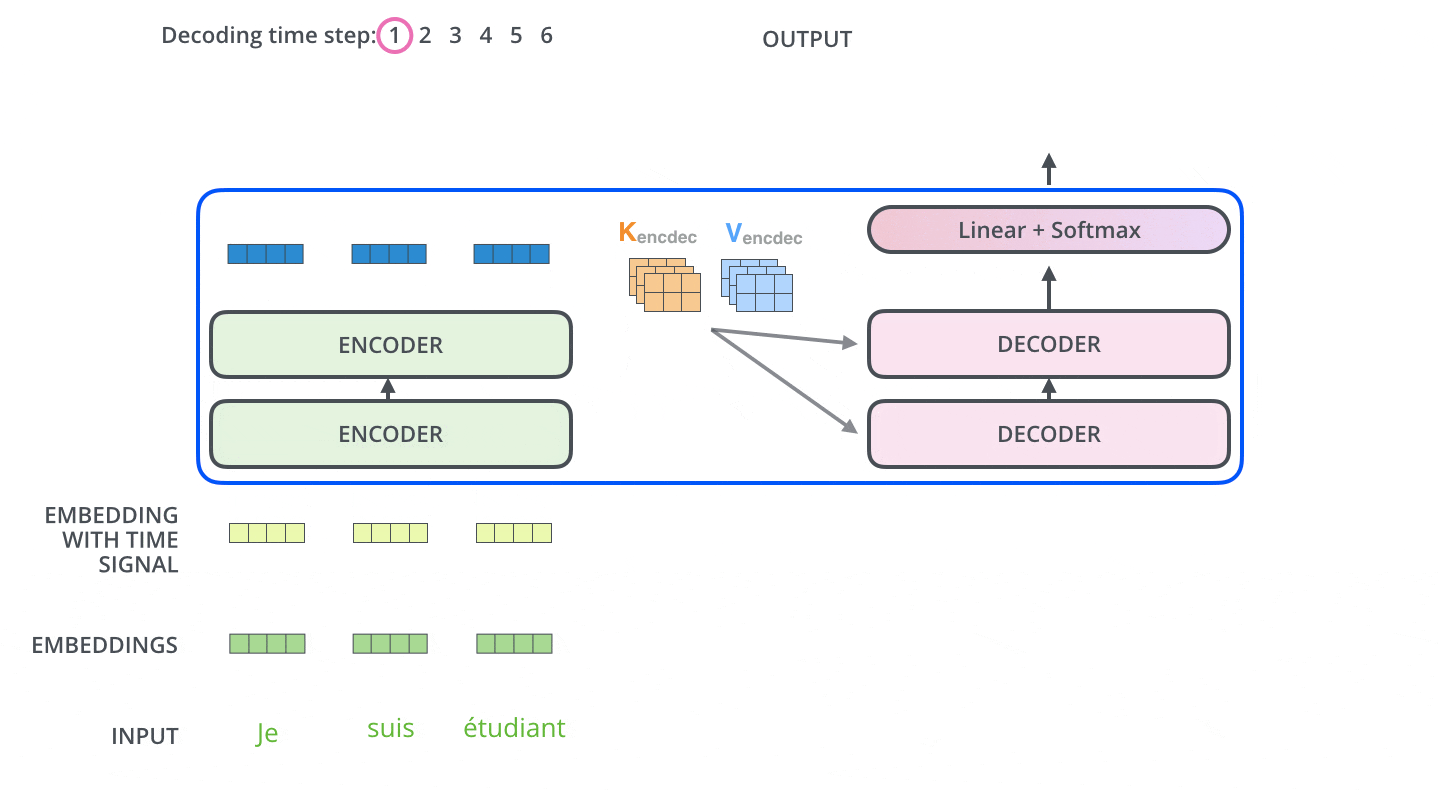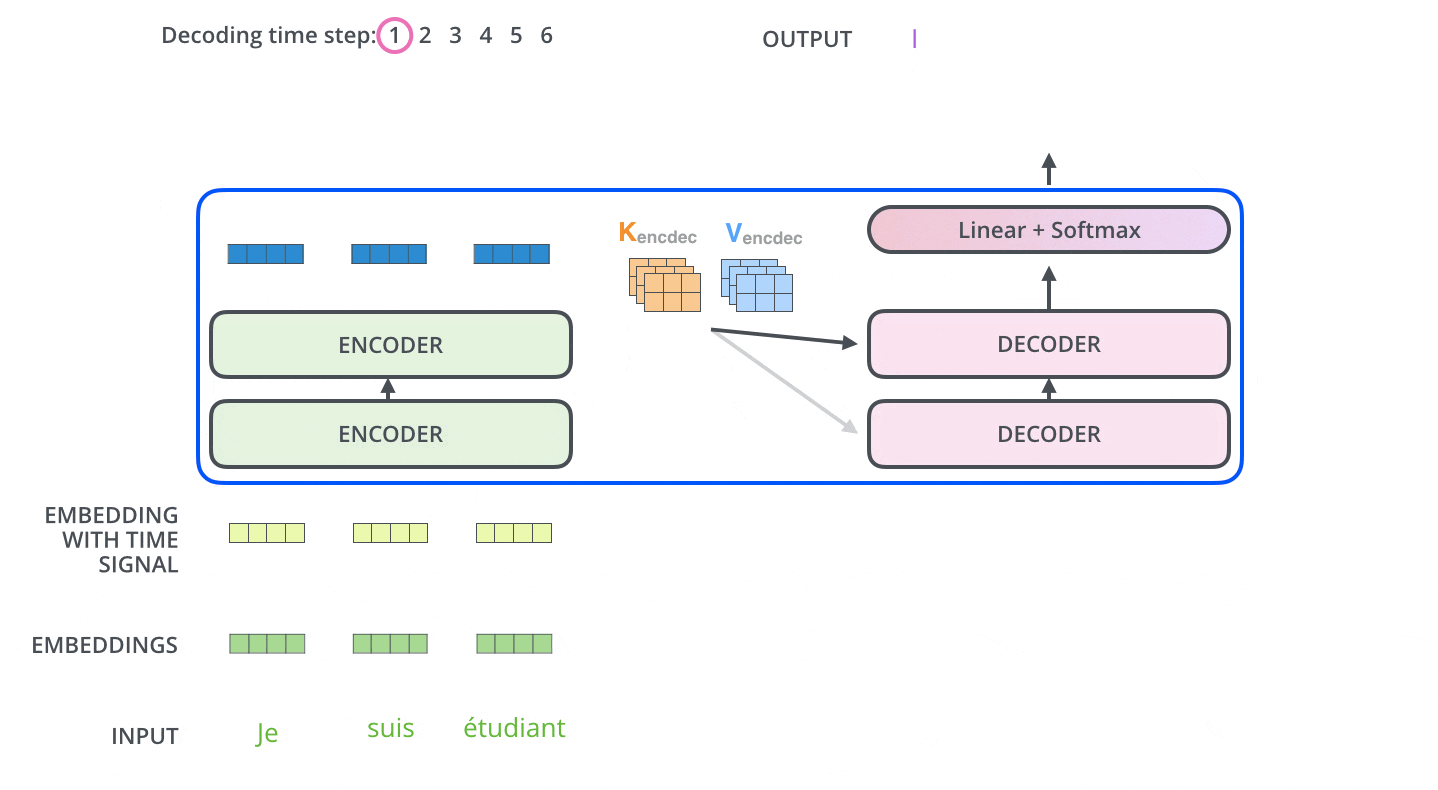
Transformer is based on the Encoder-Decoder model.
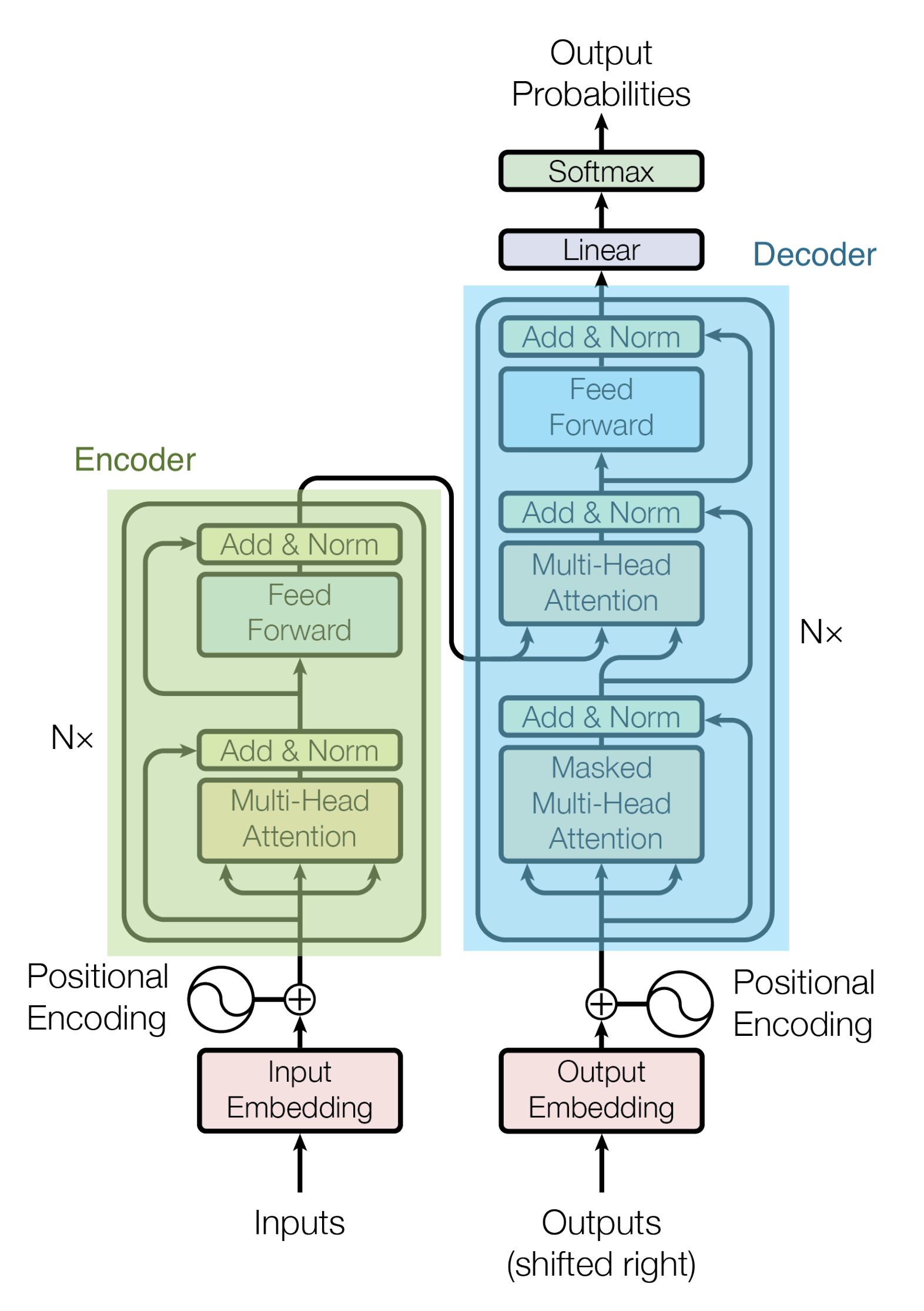
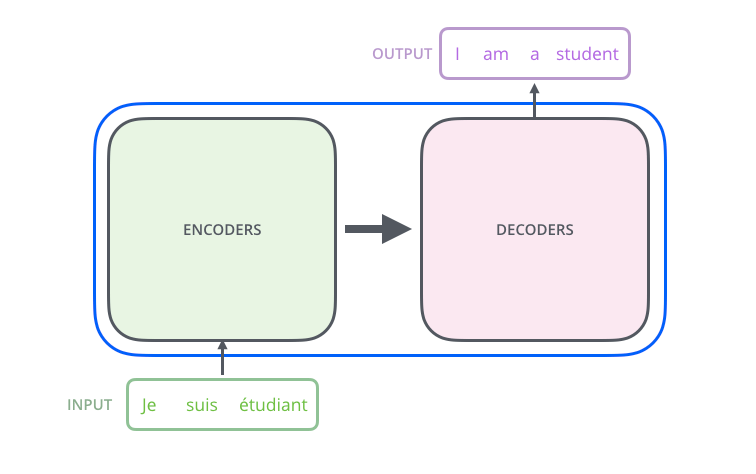
An Encoder consists of a stack of Encoders. In the paper, six Encoders are stacked. (Other numbers can be experimented with.) A Decoder also consists of a stack of 6 Decoders.
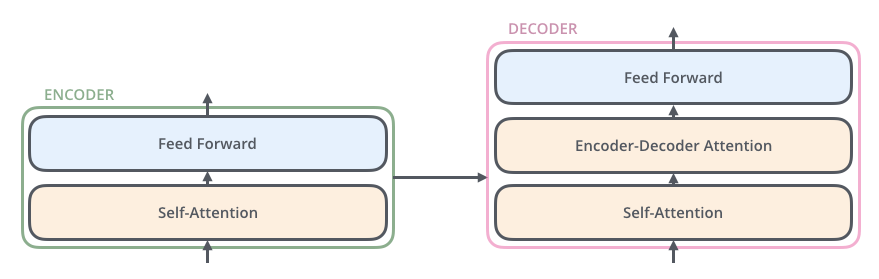
The Encoder and Decoder are composed of Multi-Head Attention and Feed Forward (affine layer).
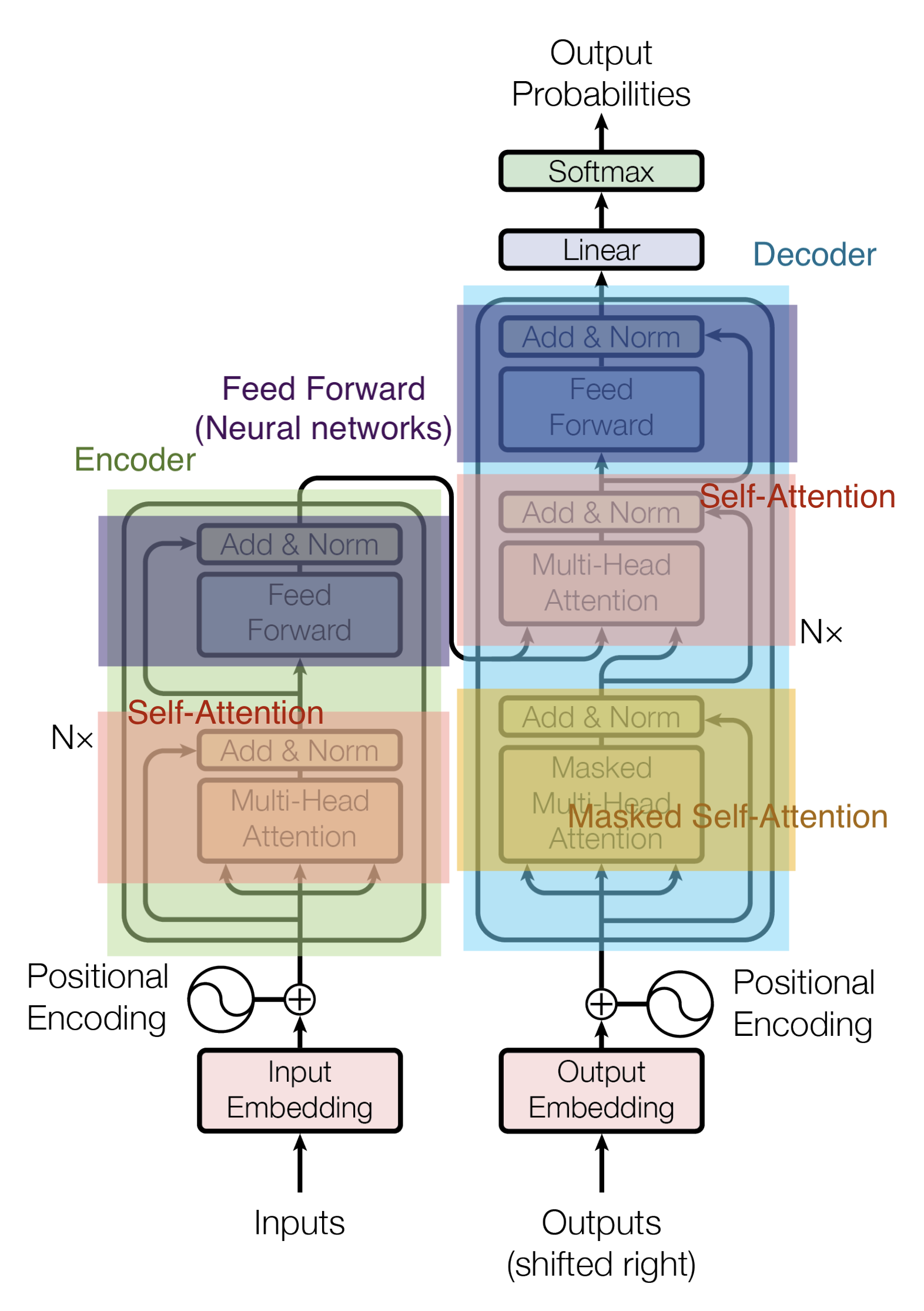
The input to the Encoder first passes through the Self-Attention and then through the Feed Forward layer.
The Decoder contains both the Self-Attention and Feed Forward layers, but in between is the Attention, which helps to determine where in the input sequence to focus attention. (The Encoder-Decoder Attention in the figure below plays the same role as the Attention in the Seq2seq model.)
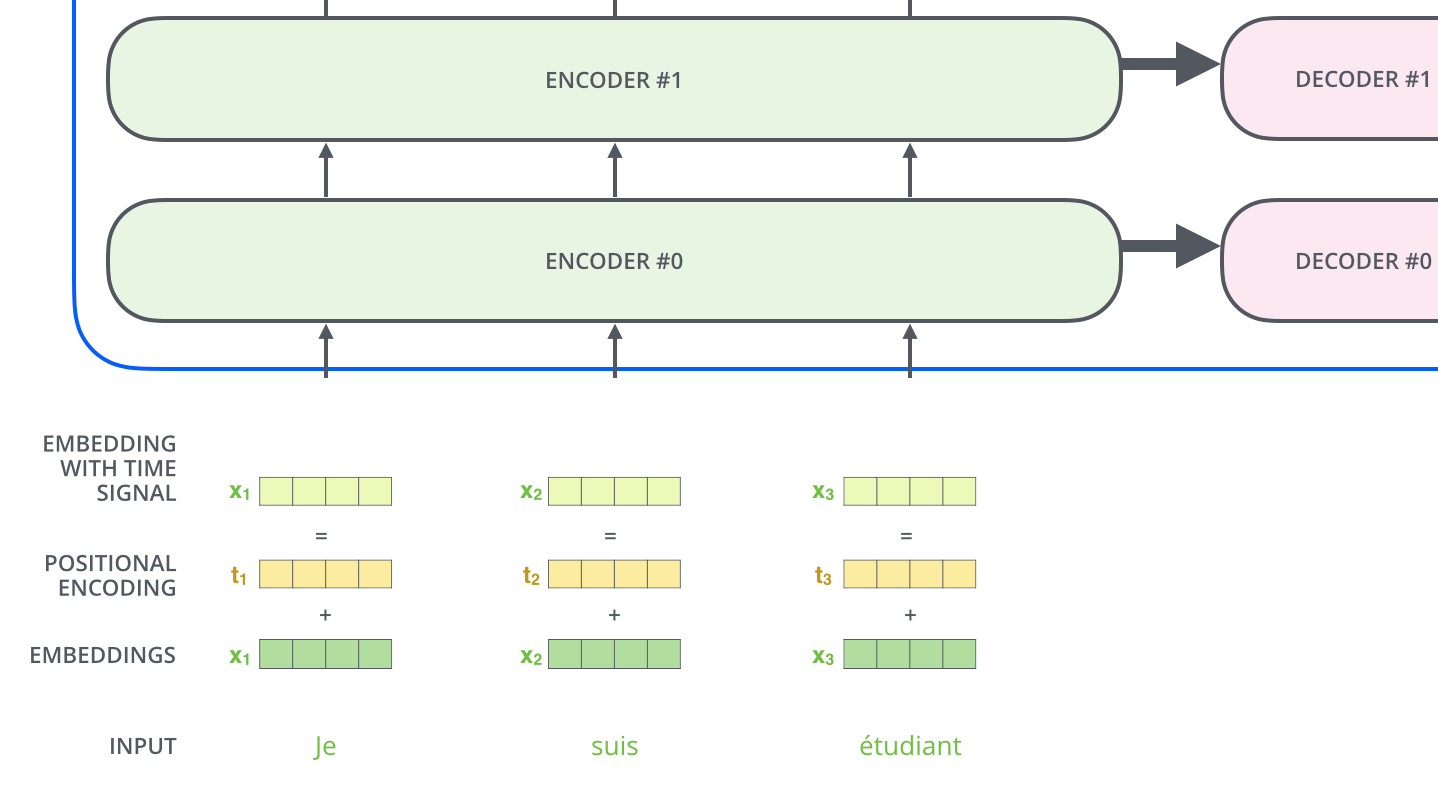
Here, each input word is turned into an embedding vector of size 512 before being passed to the Encoder or Decoder. In the following, the embedding vector is represented by four simple boxes.

The process of embedding words takes place before the bottom row of Encoders. In common, all Encoders receive a list of vectors, each of size 512. The size of this list is configurable as a hyperparameter and is basically the length of the longest sentence in the training data set.
Each word embedding vector passes through the Encoder.
Here, one of the important properties of the Transformer is that the words in each position flow through their respective paths in the Encoder; in the Self-Attention layer, there is a dependency between these paths, while in the Feed Forward layer there is no such dependency. Therefore, the various paths can be executed in parallel while flowing through the Feed Forward Layer.
Encoder
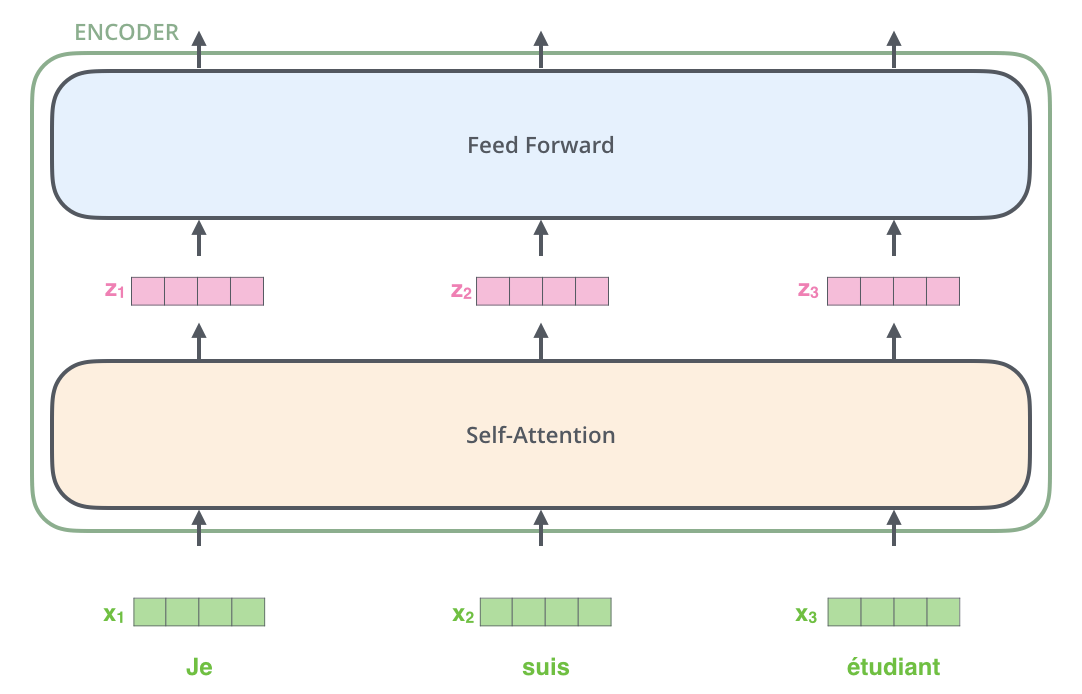
An Encoder takes as input a list of word embedding vectors, which it passes to the Self-Attention layer, then to the Feed Forward layer, and then to the next Encoder for output.
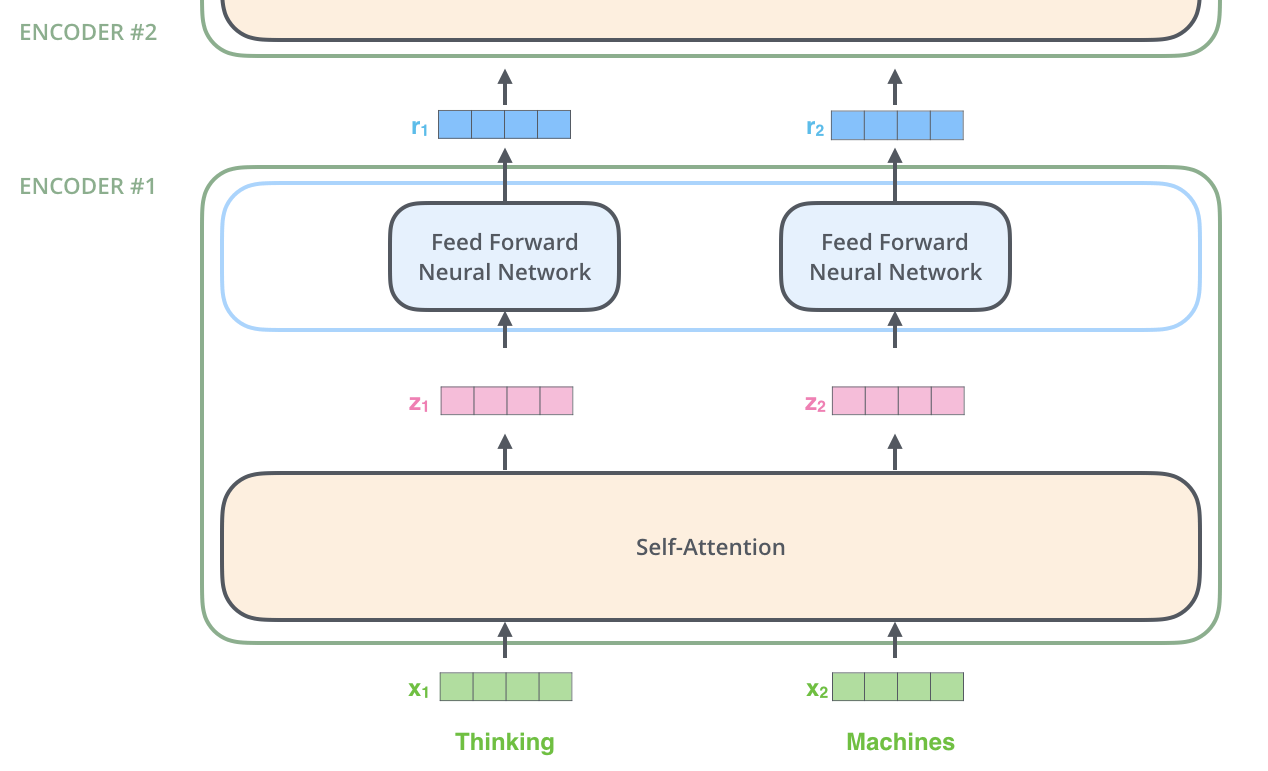
Self-Attention
Unlike the Attention layer used in Seq2seq (which acquires the correspondence between different data), the Self-Attention layer acquires information on the correspondence between words in the input data.
| Correspondence | Attention | |
|---|---|---|
| Conventional Attention | I am a student <=> Je suis un étudiant | The "I" acquires a correspondence between "Je" and "étudiant" in particular |
| Self-Attention | I am a student <=> I am a student | The "I" acquires an correspondence between "I" and "have" in particular |
For example, suppose you want to translate the following input sentence
The animal didn't cross the street because it was too tired
Understanding what "it" refers to in the above sentence is easy for humans but difficult for machines.
Self-Attention allows the model to associate "it" with "animal" when it is processing the word "it".
For example, Encoder#5 (the top Encoder) encodes the word "it"; part of Attention focuses most on "animal" and incorporates some of its representations into the encoding of "it".

Thus, Self-Attention allows us to acquire similarity within the same sentence and to correctly understand what is being referred to, especially in terms of polysemy and pronouns.
In addition, Self-Attention requires less computation. Below is the table used in the paper. Where

Self-Attention is implemented in the following sequence.
- Create a Query vector, a Key vector, and a Value vector
- Calculate the score of the input word embedding vector
- Divide the score by the square root of the dimension of the Key vector
- Calculate the Softmax score
- Multiply each Value vector by the Softmax score
- Add the weighted Value vectors
The first step in implementing Self-Attention is to create the following three vectors for each word from each Encoder input vector (the embedding of each word)
- Query vector
- Key vector
- Value vector
These vectors are created by multiplying the embedding vector matrix
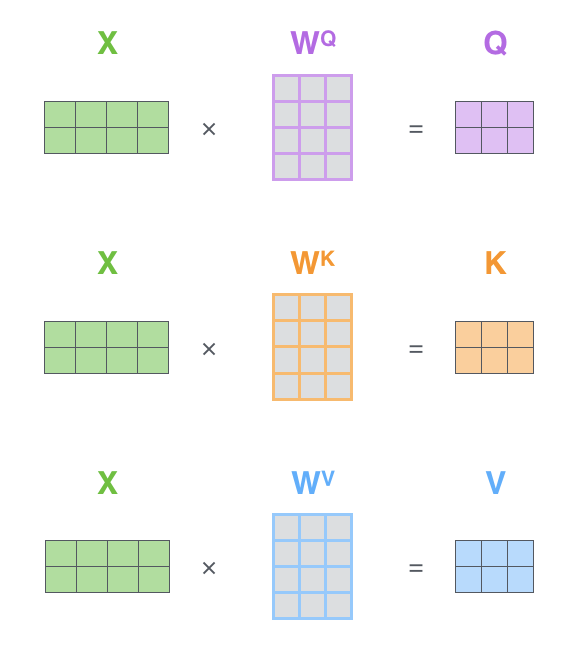
These new vectors have smaller dimensions than the embedded vectors. The dimension of the embedded vectors and Encoder input/output vectors is 512, while the dimension of the newly created vectors is 64. This is an architecture to keep the computation of Multi-Head Attention constant.
In the figure below, the dimension of the new vectors is 3.
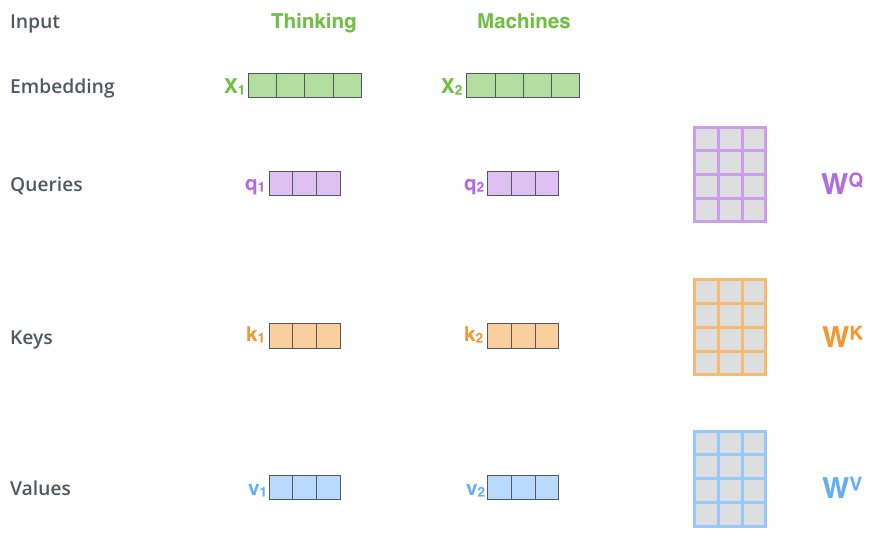
Multiplying
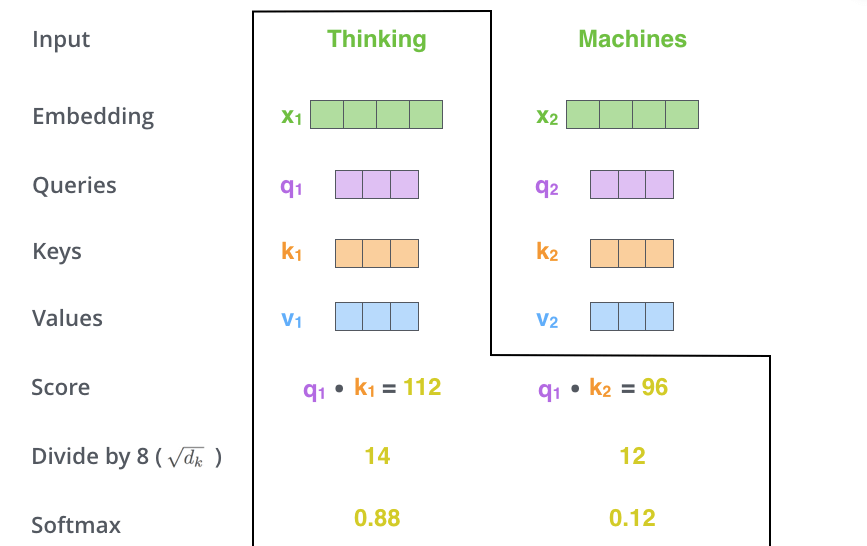
The second step in implementing Self-Attention is to compute the score. In our example, we want to calculate the Self-Attention for the first word "Thinking". For this word, we need to score each word in the input sentence. The score determines how much focus is given to other parts of the input sentence when encoding a word in a certain position.
The score is computed by taking the inner product of the Query vector and the Key vector of the word of interest. That is, if we are processing Self-Attention for the word at position 1, the first score is the inner product of
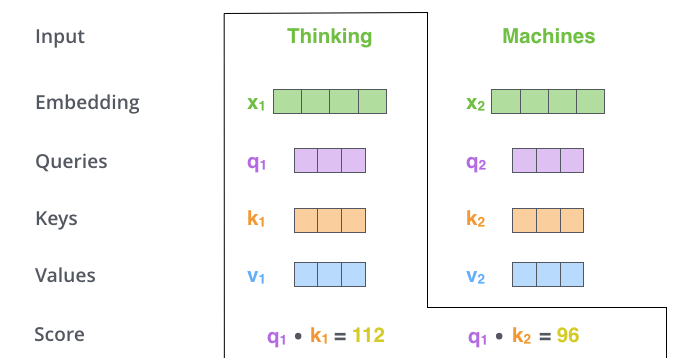
In the third and fourth steps, the score is divided by 8. The number 8 comes from the square root of the dimension of the Key vector used in the paper. This process allows for a more stable gradient to hold. Other values can be specified, but the square root of the dimension of the Key vector is the default. The result is then passed to Softmax, which takes all positive values and normalizes the scores so that they add up to 1.
This Softmax score determines how well each word is represented in this position. Most of the time, the word in the position currently being processed will have the highest Softmax score, but sometimes it is useful to focus on another word related to the current word.
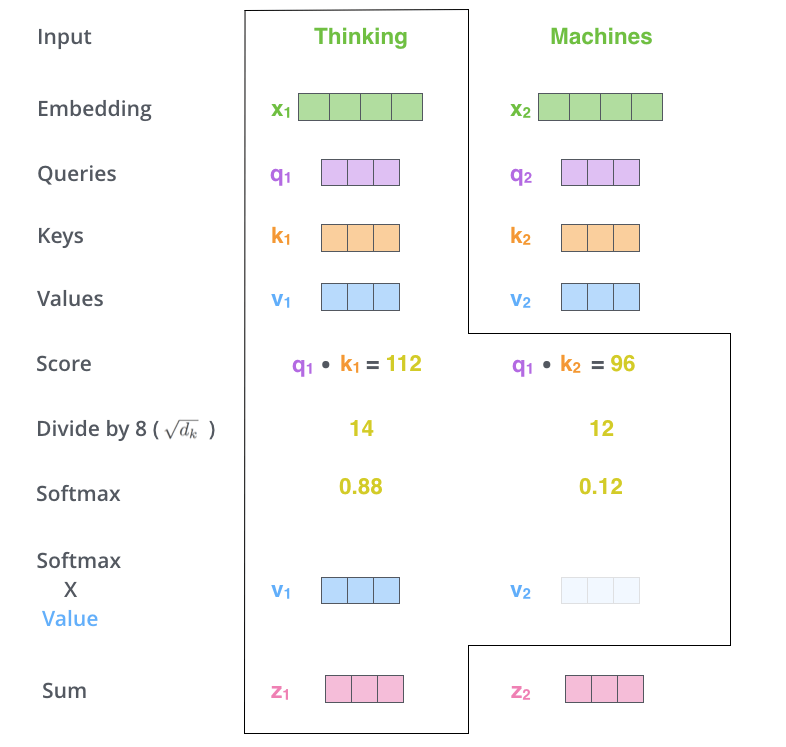
In the fifth step, each Value vector is multiplied by its Softmax score. This process leaves the value of the word of interest intact and drowns out the irrelevant words.
In the last step, the weighted Value vectors are added together. This process produces the output of the Self-Attention layer for the position currently being processed (for the first word in the example below).
These resulting vectors
Multi-Head Attention
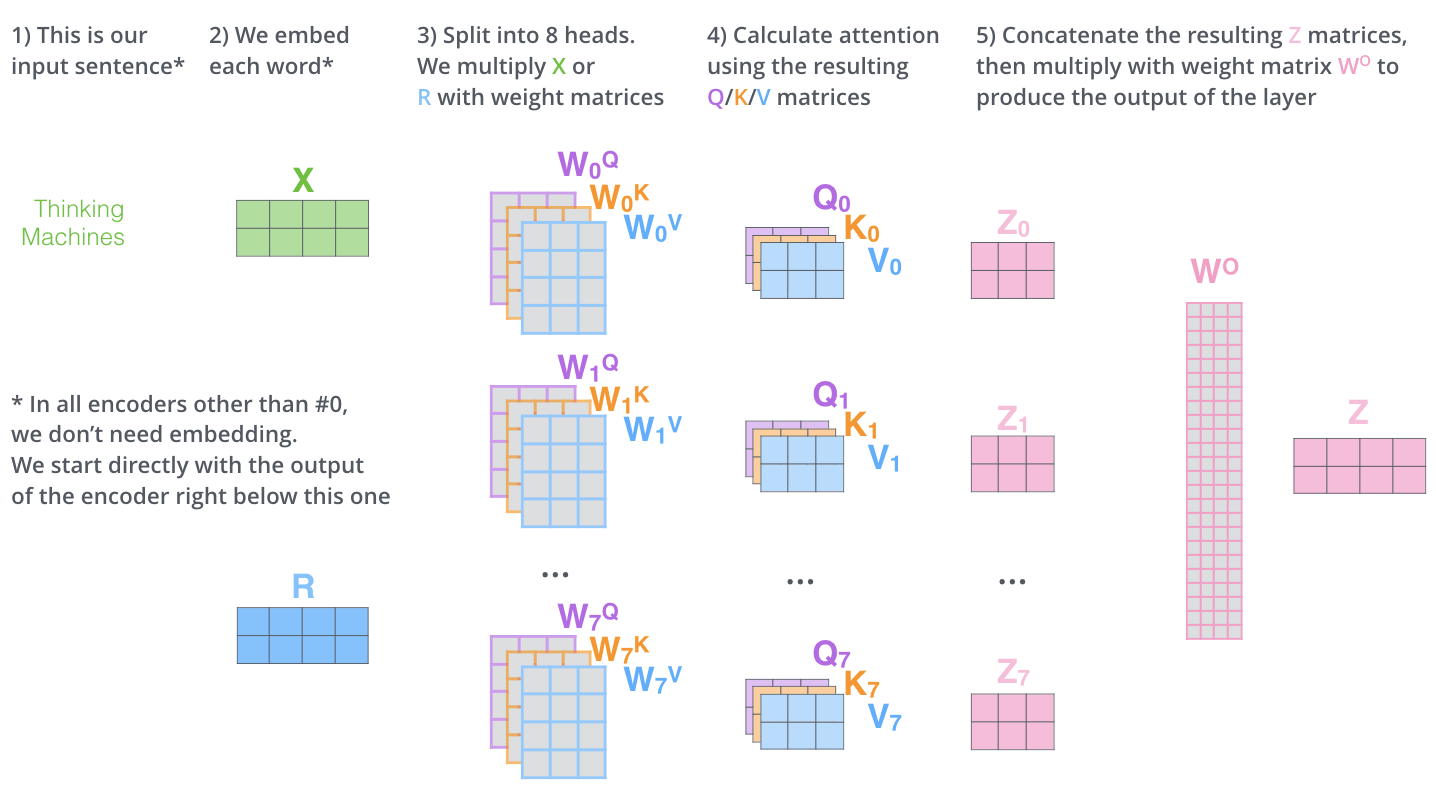
The paper further refines the Self-Attention layer by adding a mechanism called Multi-Head Attention, which is the most important part of the Transformer mechanism. This mechanism solves the two problems of the conventional model: "no long-term memory" and "no parallelization.
Multi-Head Attention extends the ability to focus on different locations in the model. In the example above,
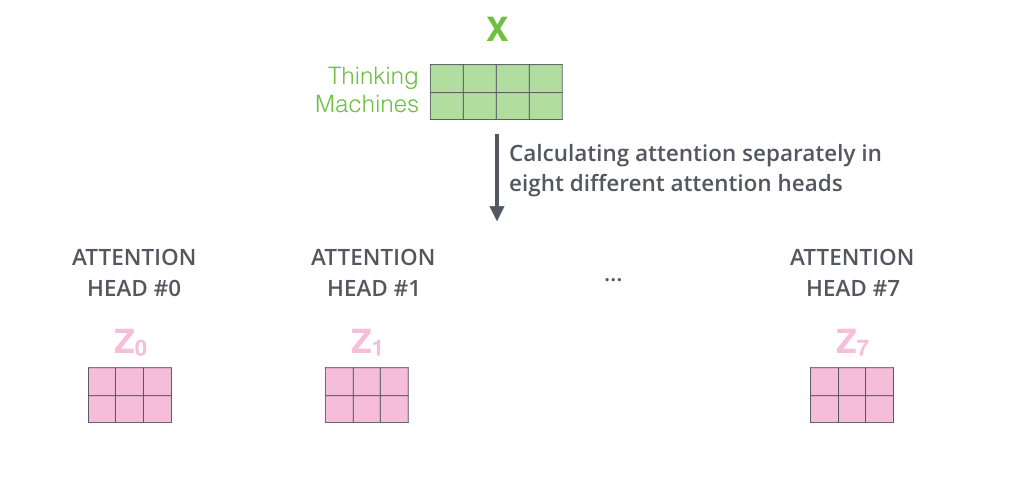
Also, Multi-Head Attention maintains separate Query/Key/Value weight matrices, resulting in different Query/Key/Value matrices. Since the Transformer uses eight Attentions, eight Query/Key/Value sets are required for each Encoder and Decoder.
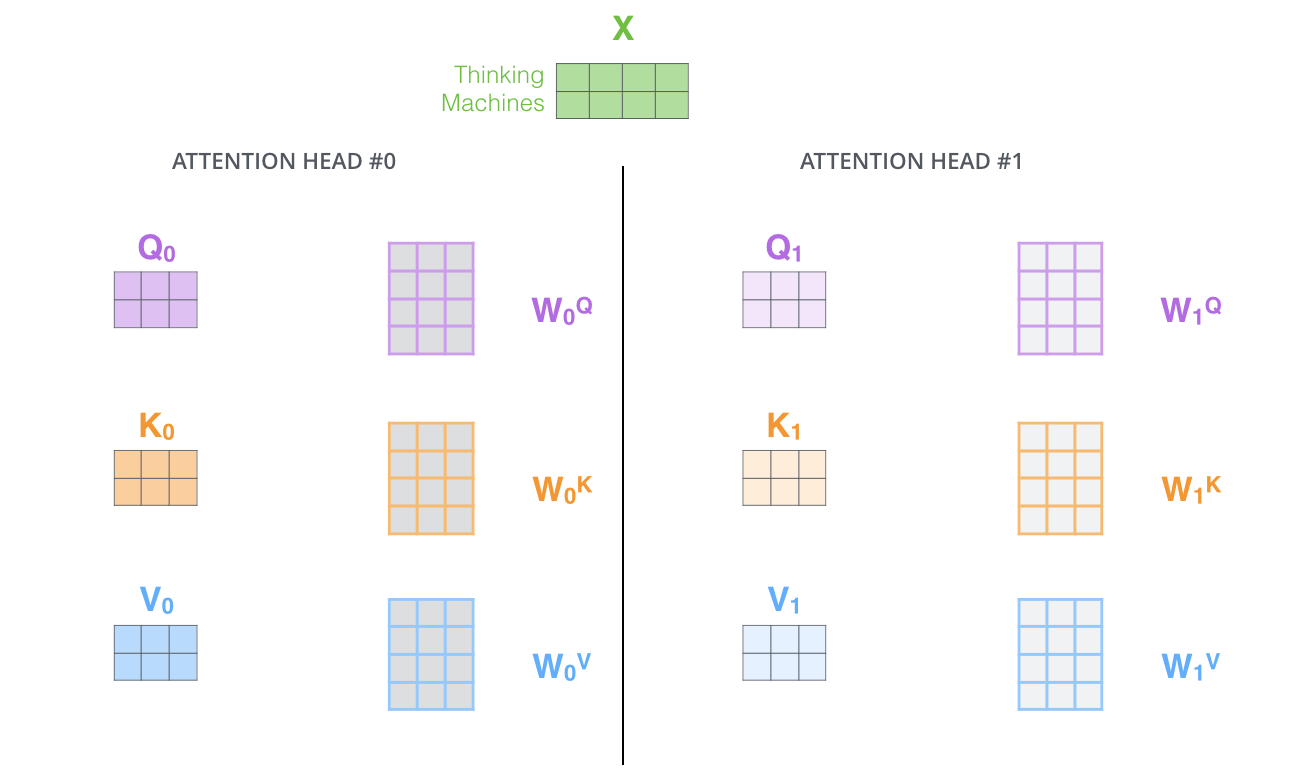
Performing the Self-Attention calculation eight times with different weight matrices yields eight different
The Feed Forward layer expects one matrix (a vector of each word) instead of 8 matrices. Therefore, concatenate the matrices and multiply them by adding the weight matrix
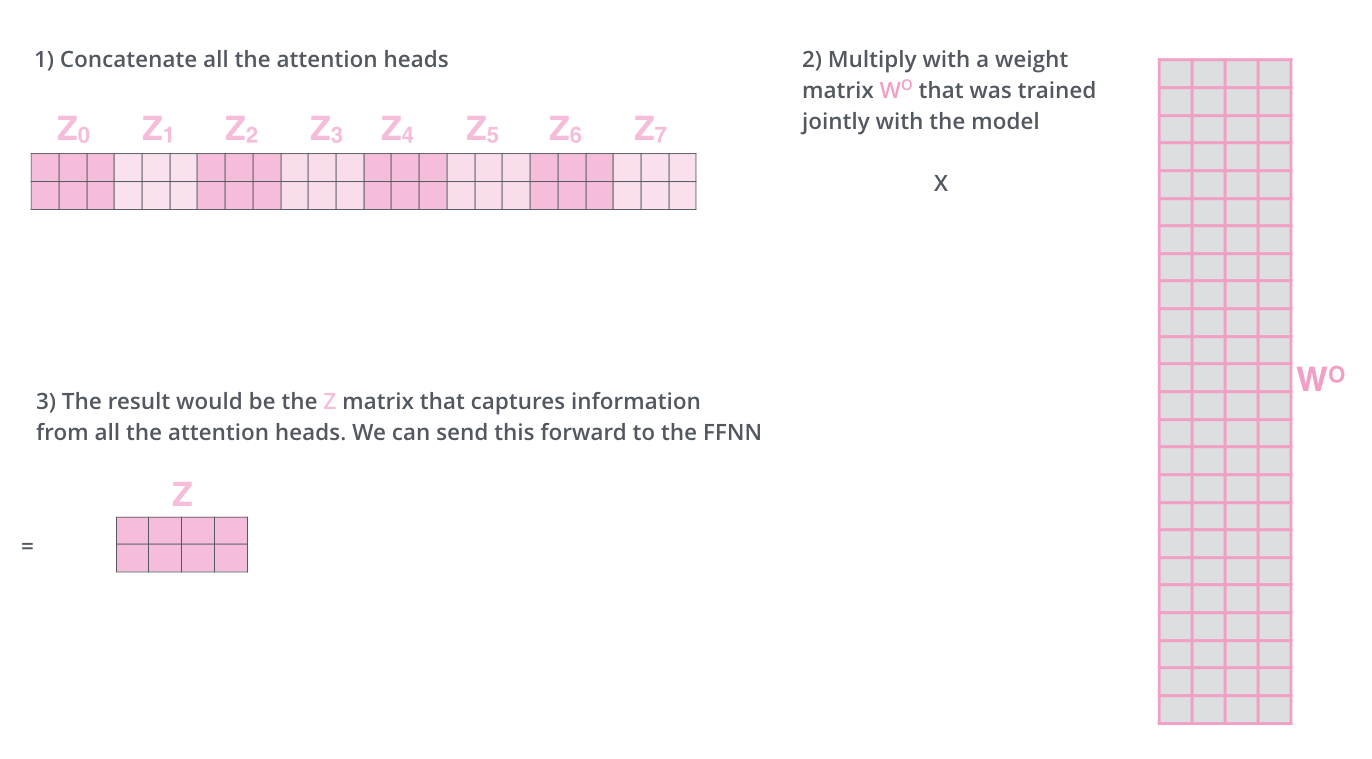
The operations of the Multi-Head Attention matrix can be summarized in one visual as follows
See where the different Self-Attention is focused when encoding the word "it" in the previous example sentence.

When encoding the word "it," one Self-Attention (Self-Attention in red) pays most attention to "animal" and another Self-Attention (Self-Attention in green) pays most attention to "tired". In a sense, the model's representation of the word "it" can be interpreted as incorporating parts of both "animal" and "tired" representations.
Feed Forward
The Feed Forward layer is a two-layer affine neural network consisting of a 2048-dimensional intermediate layer and a 512-dimensional output layer that is activated by ReLU. The equations are as follows
Positional Encoding
Since Transformer does not employ RNNs, it will no longer be able to obtain the "context" that RNNs were previously responsible for. For example, "I love cats" and "cats love I" become the same thing.
The Positional Encoding layer is a mechanism introduced to solve the above problem and adds positional information to each element in a sentence. By adding positional information, even if each element data is processed in parallel, it is possible to maintain the relationship information with the previous and next elements in the sentence that the input data originally had.
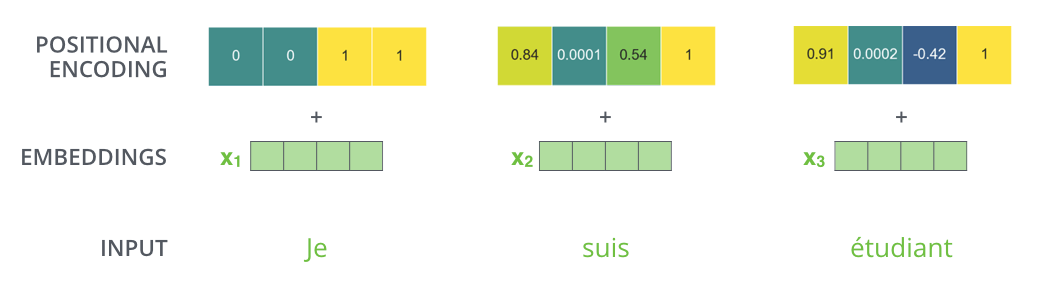
In practice, Positional Encoding gives positional information by embedding the values of the sin and cos functions, which have different frequencies, into a vector.
Assuming that the number of dimensions of the embedding is 4, the actual values of the Positional Encoding vector are as follows.
Decoder
In the Decoder, the input series is first processed. The output of the topmost Encoder is subsequently transformed into a set of key and Value vectors. These are used by each Decoder for Encoder-Decoder Attention and help the Decoder to focus on the proper place in the input series.
After encoding is completed, decoding begins. Each step of decoding outputs one element of the output series (in this case, the English translation).
In the next step, the Transformer's Decoder repeats the process until it reaches a special symbol indicating that the output is complete. The output of each step is fed to the bottom Decoder at the next time step, which then sends the decoded result to the top Decoder. In doing so, it adds a position encoding vector to the Decoder's input to indicate the position of each word, similar to what it did with the Encoder's input.
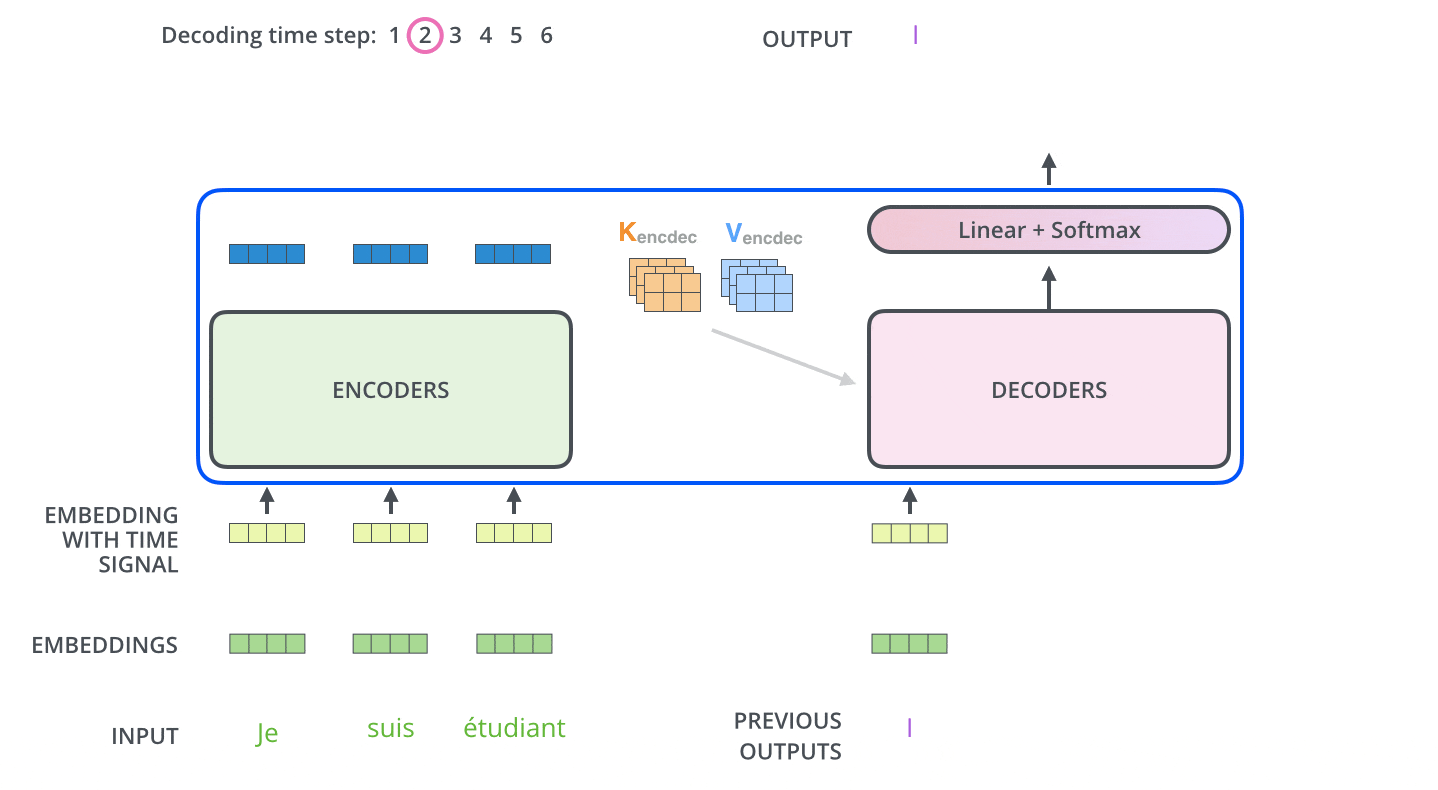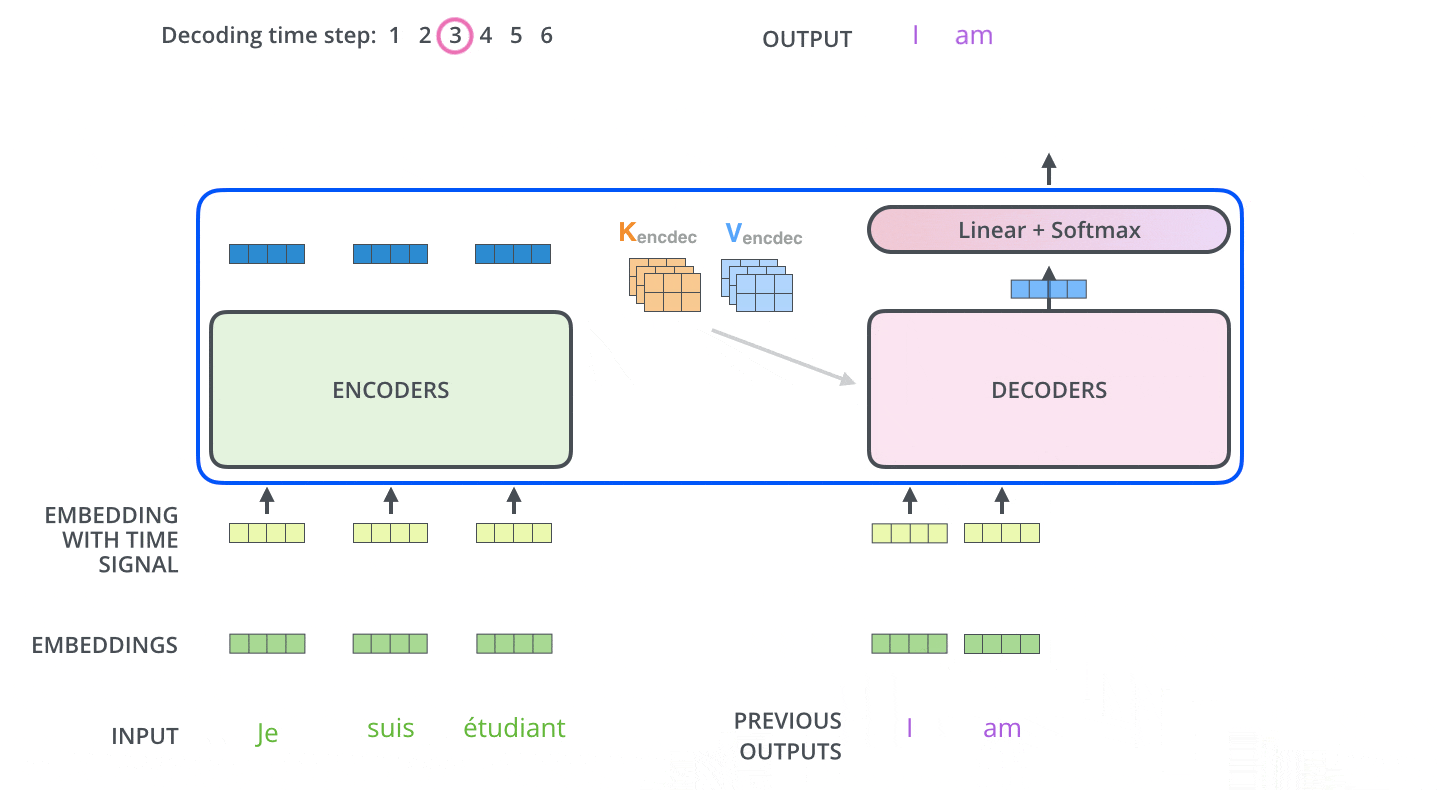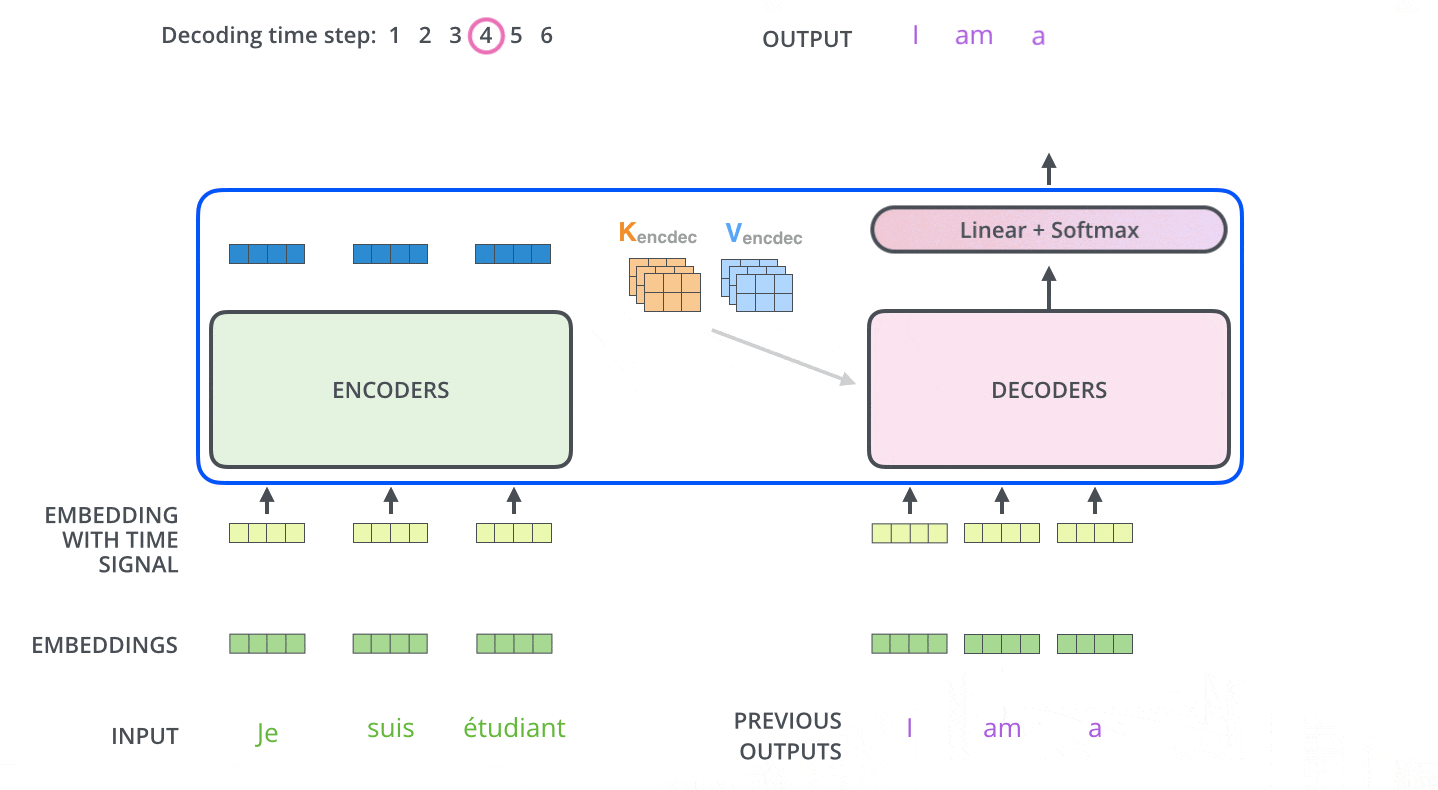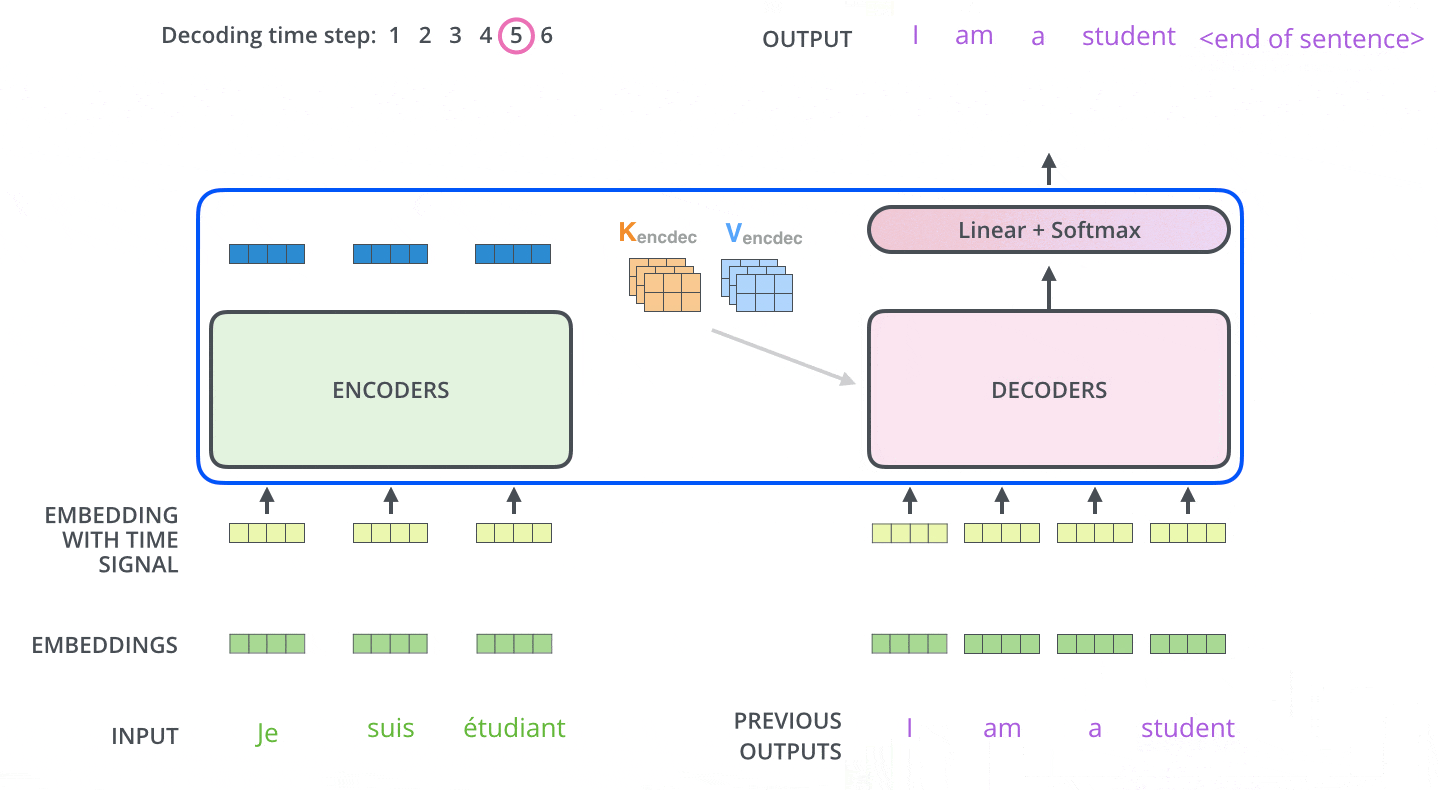
Masked Multi-Head Attention
Decoder's first Multi-Head Attention is a Masked Self-Attention, masking out information that should not be used (e.g., replacing some of the words in the input sentence with hyphens).
The input to the Decoder during training is a sequence of translated words, but the sequence of translated words must be created in order from the front, and when predicting the
Without masking, this would be cheating, as the guesser would have to look at the answer to the earlier word as well as the word before that word.
Linear and Softmax
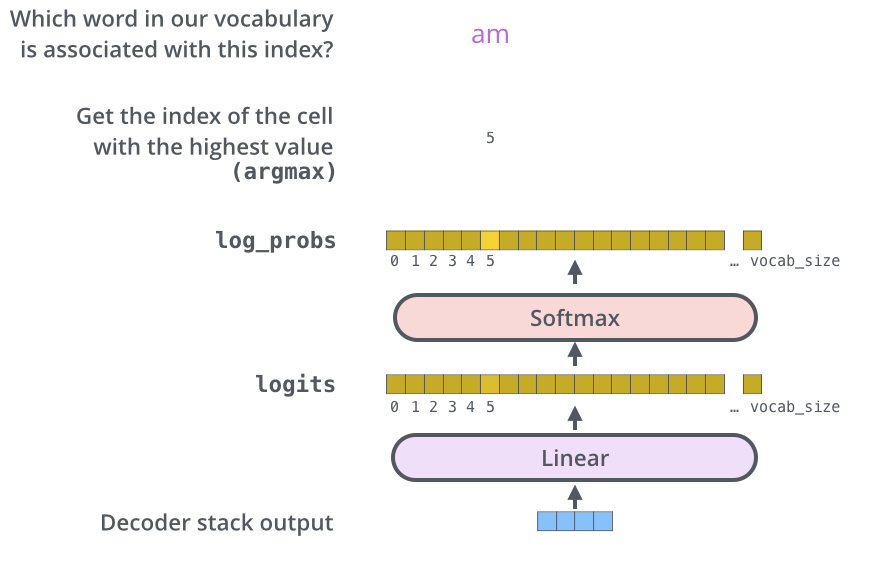
A vector is output by the Decoder. This vector is converted into words by the Linear and Softmax layers.
The Linear layer is a simple all-join network that converts the vector output from the Decoder into a vector called a logit vector. For example, assuming the model has learned 10,000 English words from the training dataset, the logit vector will be 10,000 cells wide.
The Softmax layer converts the logit vector into a probability. The cell with the highest probability is selected and the associated word is generated as the output for this time step.
Transformer framework
Transformer models can be easily implemented using the Transformers framework provided by Hugging Face.
Transformers` is a Python module for popular deep learning libraries such as PyTorch and TensorFlow.
Transformer advancements
There are two main language understanding AI models based on the Transformer.
- BERT
- GPT series
Colab notebook for Transformer
The following Google Colab notebooks provide a visual understanding of which words Transformer's Attention is focused on.
Notebooks included with Tensorflow
VizBERT
References

















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS