


What is DistilBERT
DistilBERT is a model appeared in a paper called DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter.
DistilBERT is a Transformer model based on BERT. It has 40% fewer parameters, runs 60% faster, and can maintain 97% of the performance of BERT as measured by the GLUE Benchmark.
DistilBERT is trained using Distillation Knowledge, a technique that compresses a large model called Teacher into a smaller model called Student. Distilling BERT yields a Transformer model that has many similarities to the original BERT model, but is lighter and faster to run.
Background of DistilBERT
In recent NLP, it has become a mainstream practice to create highly accurate language models by pre-training a large number of parameters on unlabeled data. The BERT and GPT series, for example, are becoming larger and larger, and the computation of a single sample takes so long that it is too computationally intensive for the average user.
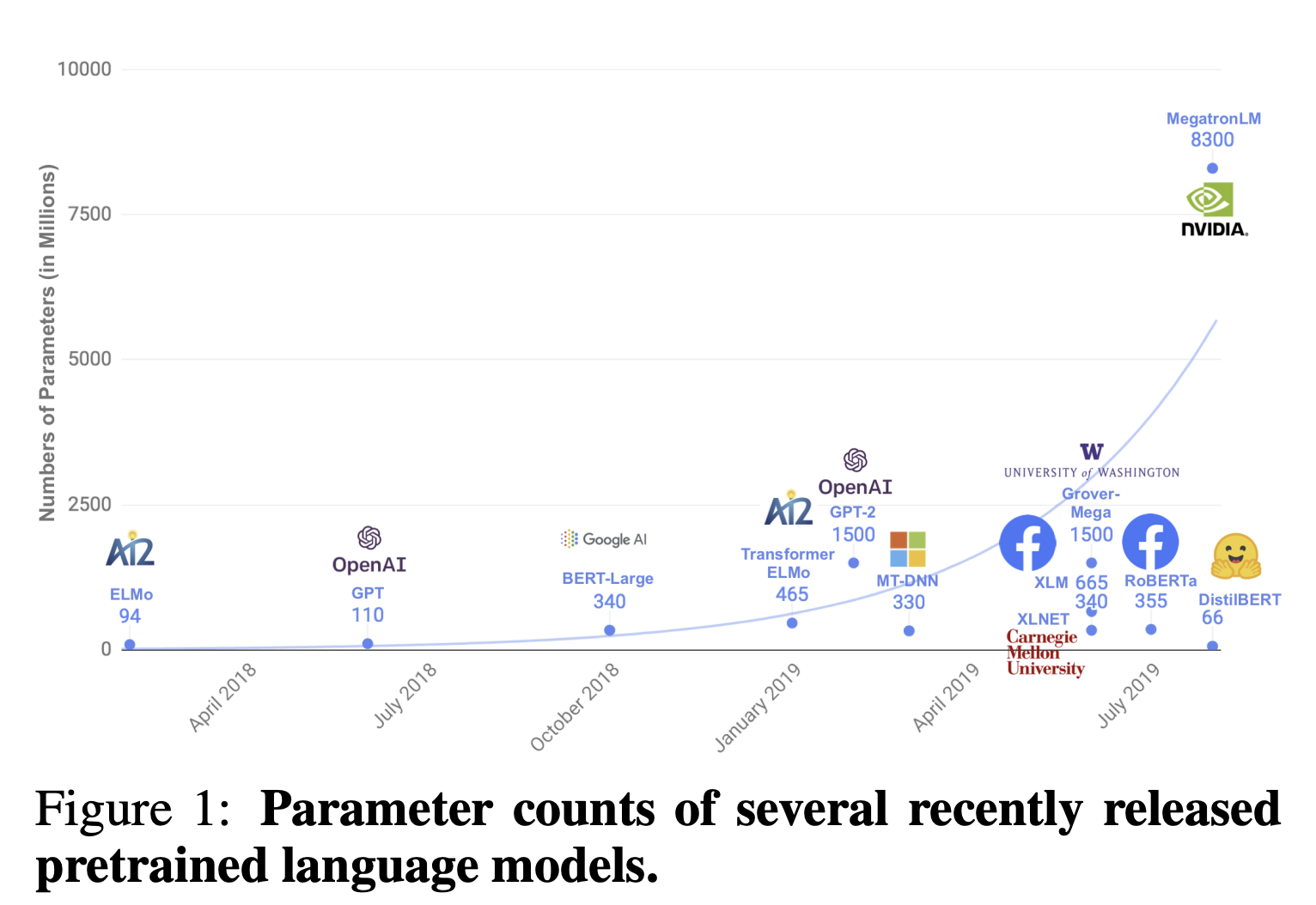
Therefore, the goal of this paper is to create a more lightweight model while maintaining accuracy.
Knowledge Distillation
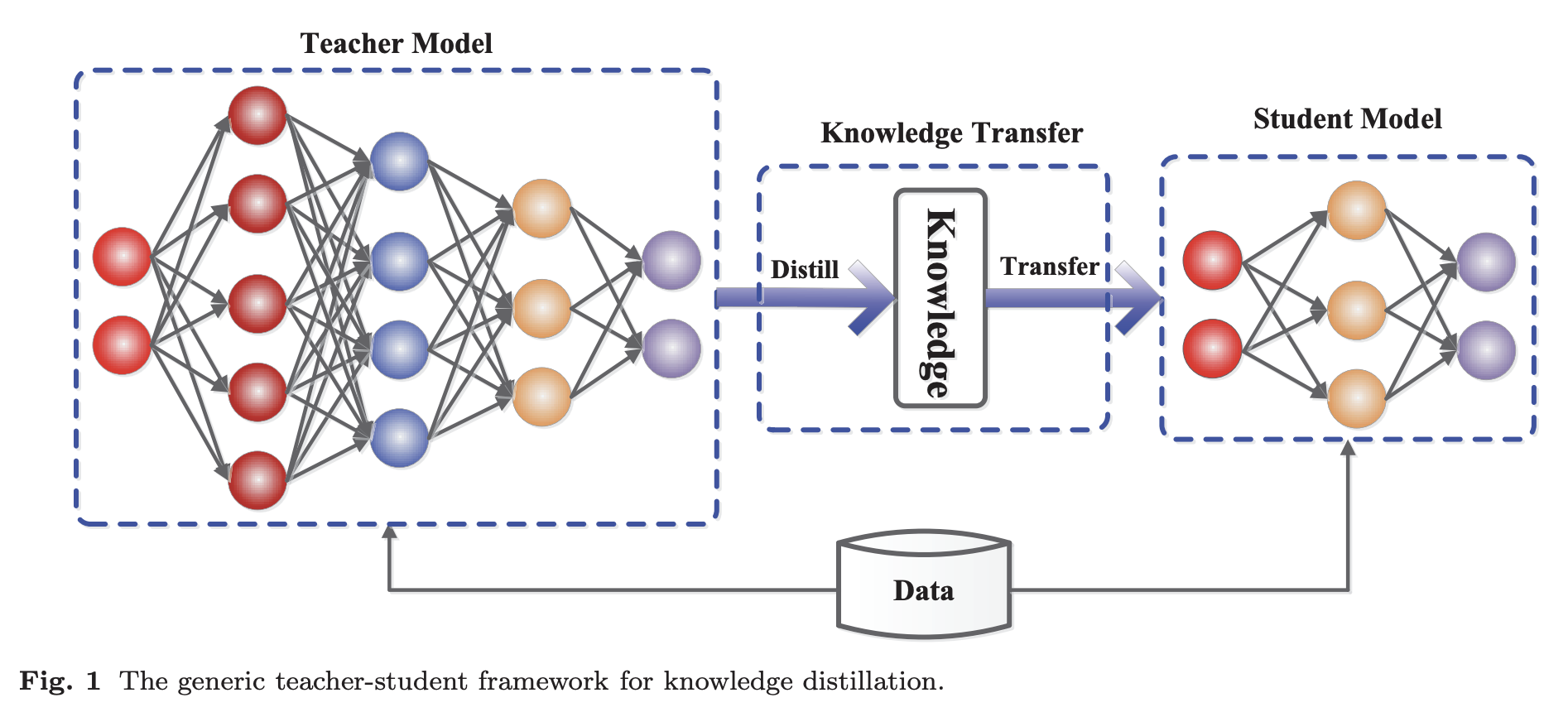
Knowledge Distillation is a technique that appeared in 2015 in the paper Distilling the Knowledge in a Neural Network. The idea is to compress and transfer knowledge from a large, computationally expensive model (Teacher model) to a smaller model (Student model) while maintaining validity.
Students are trained to reproduce the behavior of the Teacher. However, the Student model does not have as large a memory (number of parameters) as the Teacher model, so it tries to be as close to the Teacher model as possible with its small memory.
-
Teacher Model
Ensembles of very large models or individually trained models with strong regularization, such as dropouts. -
Student Model
Small models that rely on the distilled knowledge of the Teacher model
Knowledge Distillation: A Survey
In DistilBERT, Teacher refers to BERT and Student refers to DistilBERT.
Structure of DistilBERT
Student architecture
DistilBERT as Student follows the same general architecture as BERT. DistilBERT takes the following measures to reduce parameters:
- Removal of the Token embeddings layer
- Removal of the Pooler layer (the layer for classification after the Transformer Encoder)
- Halving the number of Transformer layers (BERT_BASE: 12, DistilBERT: 6)
These measures will result in a 40% reduction in the number of parameters.
Initial values for Student
The parameters of BERT, the Teacher, are used as the initial values for Student. However, since the number of Student layers is half the number of Teacher layers, one of the two corresponding layers is used as the initial value.
Distillation
DistilBERT sets up the learning method as follows:
- Increase batch size to 4,000
- Masking is done dynamically
- Next Sentence Prediction is not performed
Training Loss Function
The loss function of DistilBERT is a linear combination of Distillation Loss (
Distillation Loss
Distillation Loss (
where
The loss function in the above equation allows us to mimic not only the word with the highest probability of prediction, but also the word with the next highest probability of prediction, etc., thus learning the distribution predicted by the Teacher.
For example, consider the following sentence.
I watched [MASK] yesterday.
Suppose that the predicted probability of BERT, the Teacher, is as follows
| Predicted words | Predicted probability |
|---|---|
| movie | 0.8 |
| TV | 0.1 |
| baseball | 0.05 |
| MMA | 0.05 |
In this case, the Student learns not only "movie" but also "TV", "MMA", and "baseball" so that the prediction probabilities are closer to that of the Teacher, BERT.
However, here the prediction probability softmax-temperature.
If
By using softmax-temperature, the function learns to predict words with low probability.
Masked Language Model Loss
Masked Language Modelling Loss (
Cosine Embedding Loss
Cosine Embedding Loss (
References
















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS