


What is BERT
BERT stands for Bidirectional Encoder Representations from Transformers and is a natural language processing model announced by Google on October 11, 2018.
BERT is a pre-training model by Transformer that is bidirectional using large unsupervised datasets. BERT is a pre-training model, not a predictive model, so BERT by itself cannot do anything. Fine tuning for individual tasks such as document classification or sentiment analysis makes it a predictive model.
BERT features
BERT has the following features:
- Contextual understanding
- High versatility
- Overcoming data shortages
Contextual understanding
Before BERT, there were language processing models such as ELMo and OpenAI GPT, which could not understand context because ELMo was a shallow bidirectional model and OpenAI GPT was a unidirectional model. Here is an example from Google.
Prior to the introduction of BERT, Google searches could not process words like "to" that formed a sentence-to-sentence relationship. For example, suppose we have the following search terms.
2019 brazil traveler to usa need a visa
In the case of the above search term, what the user wants to know is whether a traveler from Brazil needs a visa to go to the United States. However, prior to the introduction of BERT, the word "to" could not be processed, so it could be interpreted as "American traveler to Brazil," resulting in search results that did not match the need.
BERT is a context-aware model using an interactive Transformer, and after BERT was implemented, "Brazilian travelers to the U.S." could be interpreted and the U.S. Embassy's visa information page for Brazilian travelers could be displayed at the top of the results. The model is now interpreted as "Brazilian travelers to the U.S.".
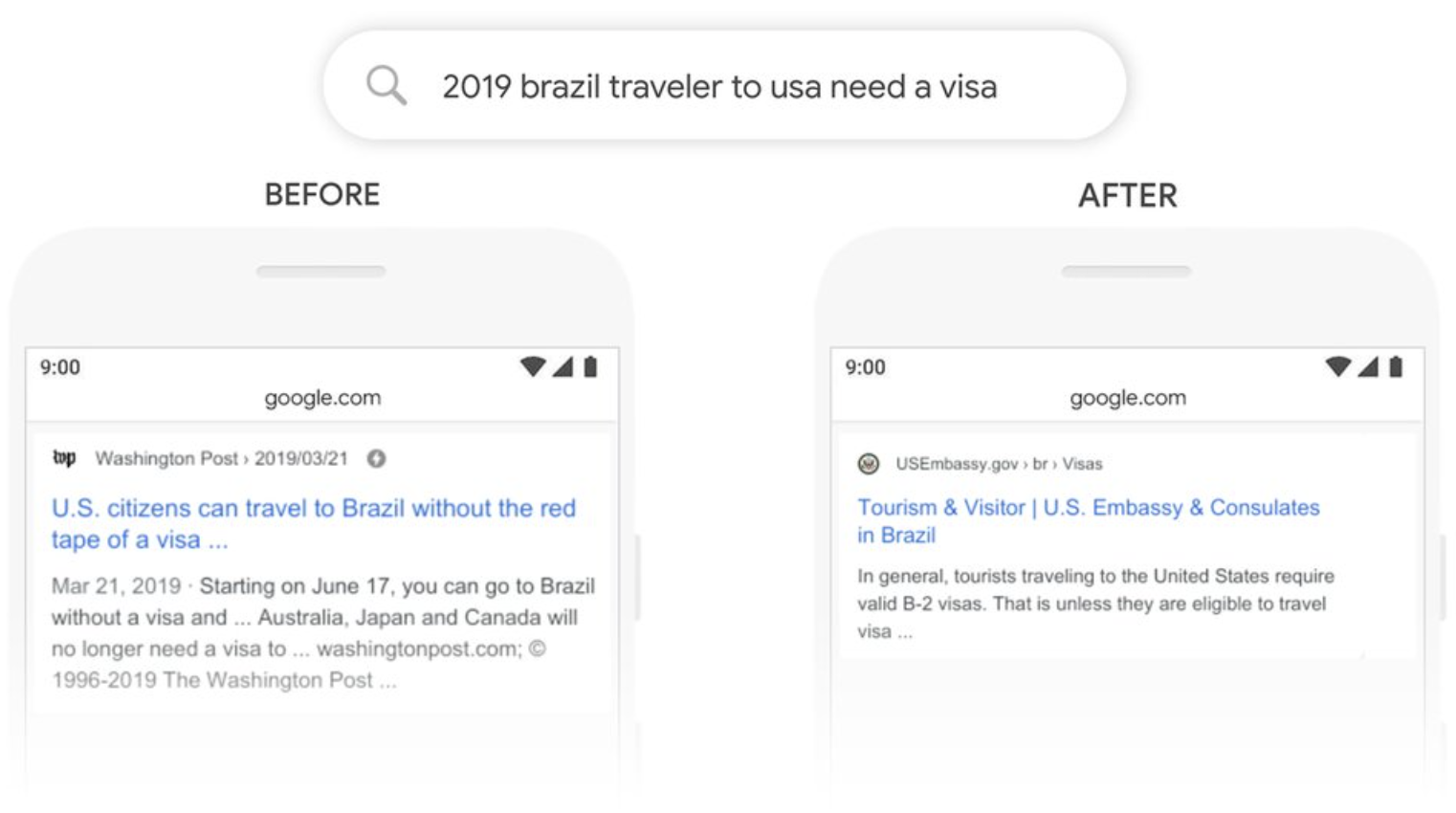
Understanding searches better than ever before
High versatility
BERT can pre-train large amounts of text data from Wikipedia, BooksCorpus, and other sources, and then apply it to various tasks such as sentiment analysis and translation through fine tuning.
Overcoming data shortages
Unlike traditional models, BERT can process unlabeled data sets. Labeled data sets are often difficult to obtain; BERT can overcome the lack of data by allowing unlabeled data to be used as material for processing.
How BERT works
Learning BERT involves the following two steps:
- Pre-training
Pre-training with unlabeled data - Fine tuning
Fine tuning with labeled data using the pre-trained weights as initial values
As an example, the spam classification task is illustrated below.
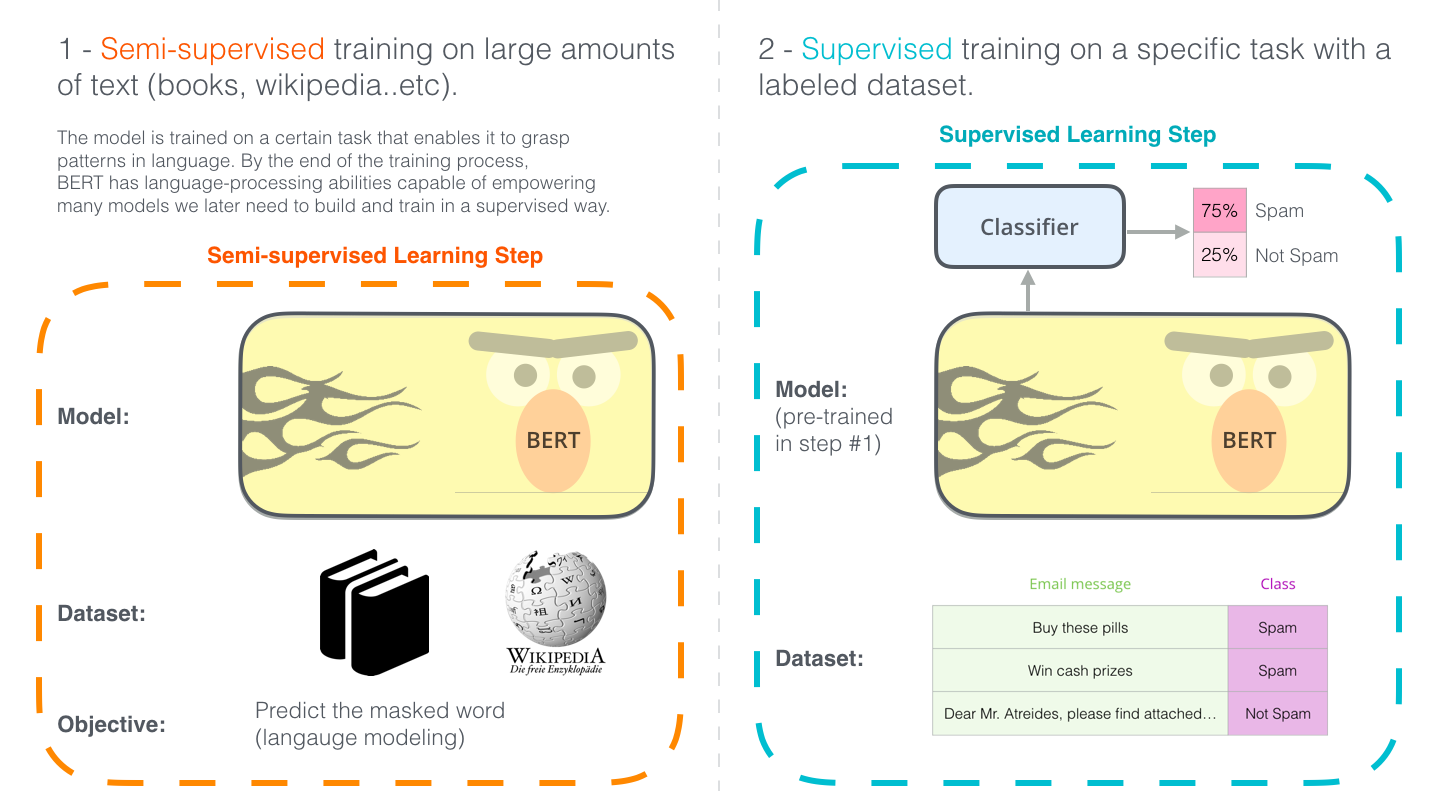
The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)
BERT has the architecture of a Transformer Encoder only, and there are BASE and LARGE models.
| Model | L (# of Transformer blocks) | H (hidden layer size) | A (# of Self-Attention head) | # parameters |
|---|---|---|---|---|
| 12 | 768 | 12 | 110M | |
| 24 | 1024 | 16 | 340M |
Pre-training
The data used in BERT pre-training is unlabeled raw text data.
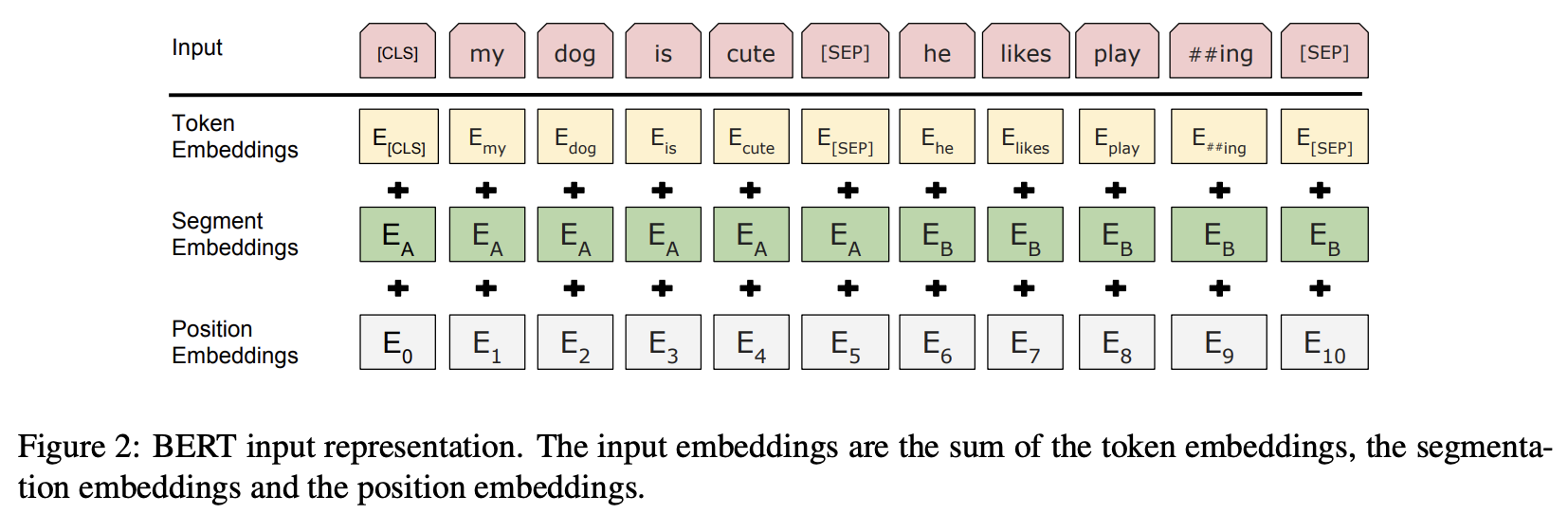
The document data is converted to a sequence of vectors as shown in the figure below.
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
In the top row, "Input," the structure is one input sequence, consisting of a special token [CLS] at the beginning and two sentences A and B concatenated by inserting the special token [SEP] at the end of each sentence.
In the second and subsequent stages, immediately after the input sequence is submitted, the three Embeddings replace the tokens, sentence categories, and positions in the sequence with H-dimensional embedded representations that are learned in the pre-training process, and the vector sequence obtained by adding these tokens becomes the input to the Transformer.
- Token Embeddings: Token ID
- Segment Embeddings: Segments of sentences A and B
- Position Embeddings: Position in the sequence
BERT performs pre-training on this input, combining the following two objective functions
- Masked language Model
- Next Sentence Prediction
Masked Language Model
Conventional natural language processing models can only process sentences from a single direction and must make predictions based on data from sentences preceding the target word. BERT, however, training using a bidirectional Transformer, resulting in a significant improvement in accuracy over conventional methods. This is made possible by the Masked Language Model.
The Masked Language Model process works by probabilistically replacing 15% of the words in the input sentence with another word and predicting the word before the replacement based on the context. Of the 15% selected, 80% are masked to be replaced by [MASK], 10% by another random word, and the remaining 10% are left unchanged.
- 80% of the 15% selected words are converted to [MASK].
- my dog is hairy ➡︎ my dog is [MASK]
- 10% of the 15% selected words are converted to random words.
- my dog is hairy ➡︎ my dog is apple
- 10% of 15% selected words are kept same.
- my dog is hairy ➡︎ my dog is hairy
By solving the task of guessing these substituted words from the surrounding context, the contextual information corresponding to the words can be learned.
Next Sentence Prediction
While the Masked Language Model can learn words, it cannot learn sentences. Next Sentence Prediction can learn the relationship between two sentences.
Next Sentence Prediction learns by replacing one of the sentences with the other with 50% probability and determining whether they are adjacent (isNext or notNext) or not (isNext or notNext). A token called [CLS] is provided for classification.
| Example sentence | Judgement |
|---|---|
| [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP] | isNext |
| [CLS] the man went to [MASK] store [SEP] penguin [MASK] are flightless birds [SEP] | notNext |
In this way, BERT is able to learn not only about words, but also about the expression of whole sentences.
Fine tuning
BERT's pre-trained models are fine-tuned according to the task to be solved. Fine tuning involves learning on a relatively small amount of labeled data.
When fine tuning is performed, the parameters obtained from the pre-training are used as the initial values of the model, and the parameters are learned using the labeled data.
Thus, by using the parameters obtained in the pre-training as initial values during fine tuning, a model with high performance can be obtained even with a relatively small number of training data.
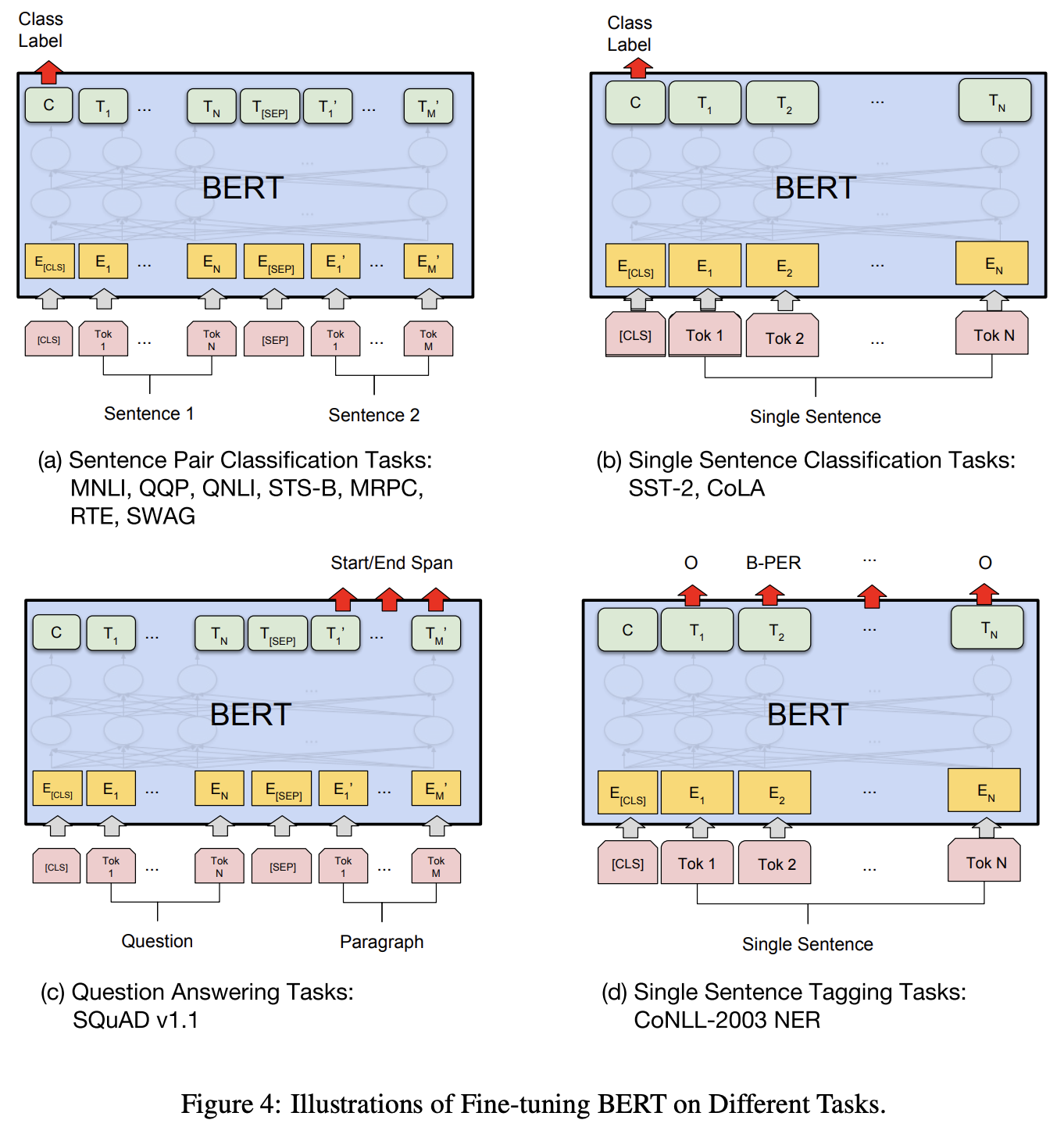
The figure below shows an example of fine tuning.
- (a) Sentence Pair Classification Tasks
- (b) Single Sentence Classification Tasks
- (c) Question Answering Tasks
- (d) Single Sentence Tagging Tasks
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT performance benchmarks
The performance of natural language processing models is measured by GLUE (The General Language Understanding Evaluation), a benchmark that calculates scores on all natural language processing tasks. The following table shows the GLUE results described in the paper.
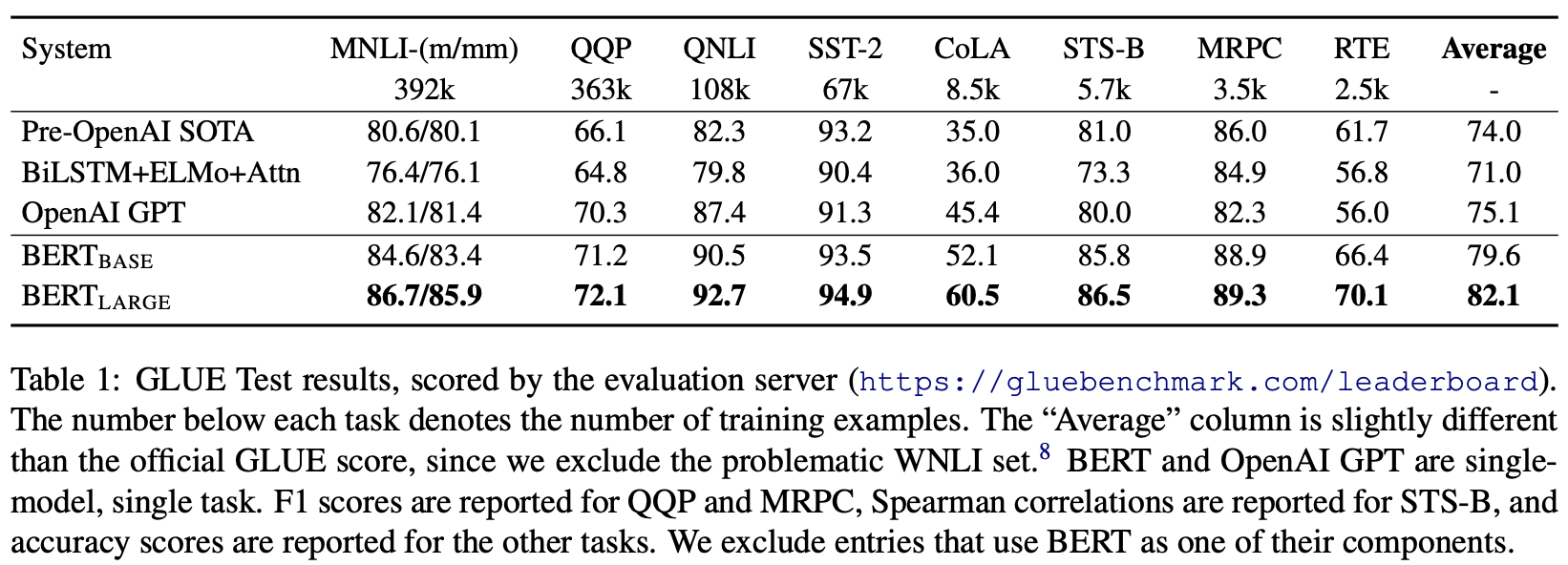
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT scores higher than existing models such as OPEN AI on all datasets.
References
















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS