

What is Attention
Attention is a score that indicates which words in a sentence to pay attention to in NLP. Attention was first introduced in the paper Neural Machine Translation by Jointly Learning to Align and Translate, and is described as "soft align" or "soft search" in the paper.
Consider the following English text translated into Japanese.
I like apple.
This English sentence can be translated as follows.
私はりんごが好きです。
When we humans translate "apple" into "りんご", we focus on the word "apple" and the word "like" immediately preceding it.
In this way, we humans pay attention to some words in a sentence when we translate. Attention applies this idea to neural network models.
Understanding Attention
We will try to understand Attention visually. The following article is very easy to understand, so I will refer to it and supplement it as needed.
Conventional Encoder-Decoder model
Attention emerged due to the limitations of the Encoder-Decoder model (Seq2seq).
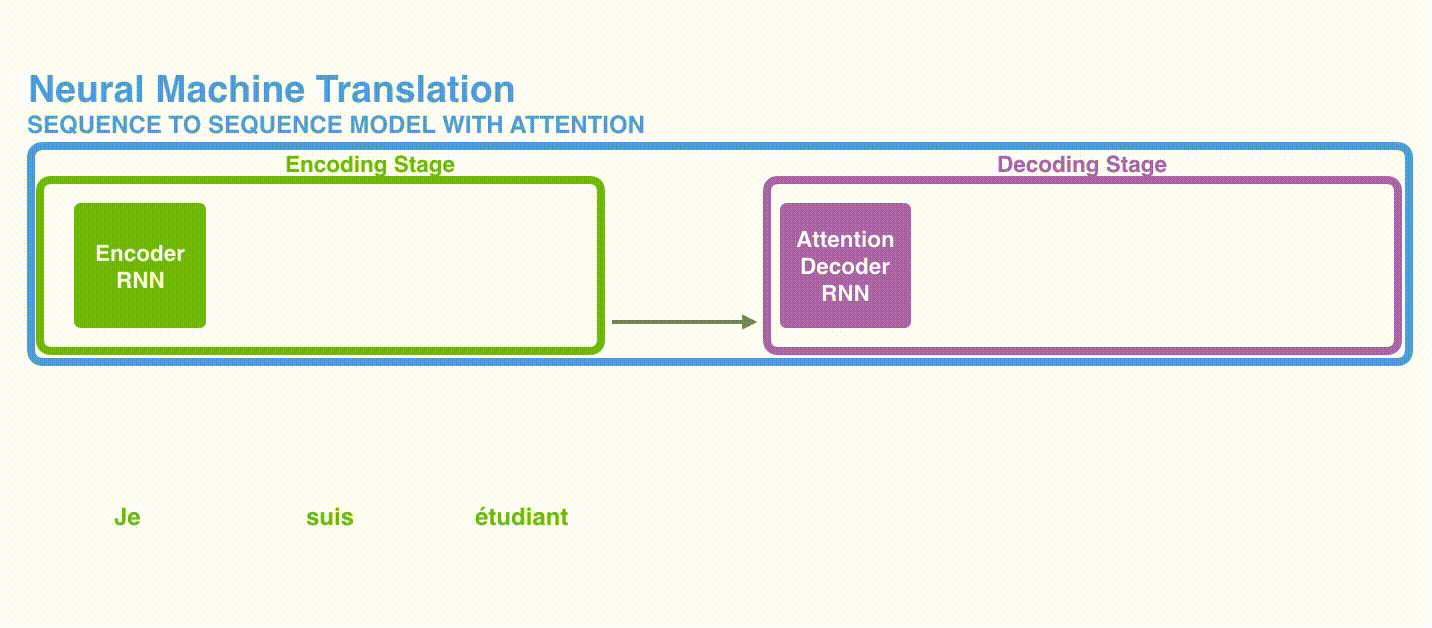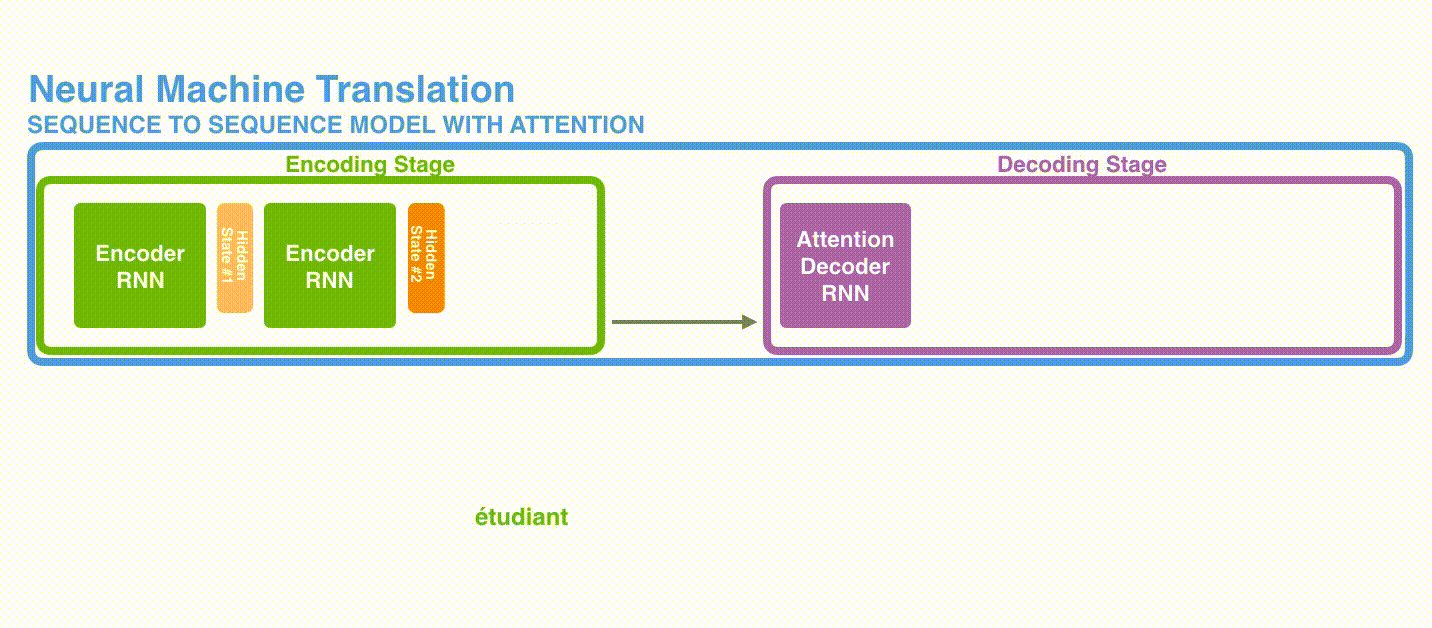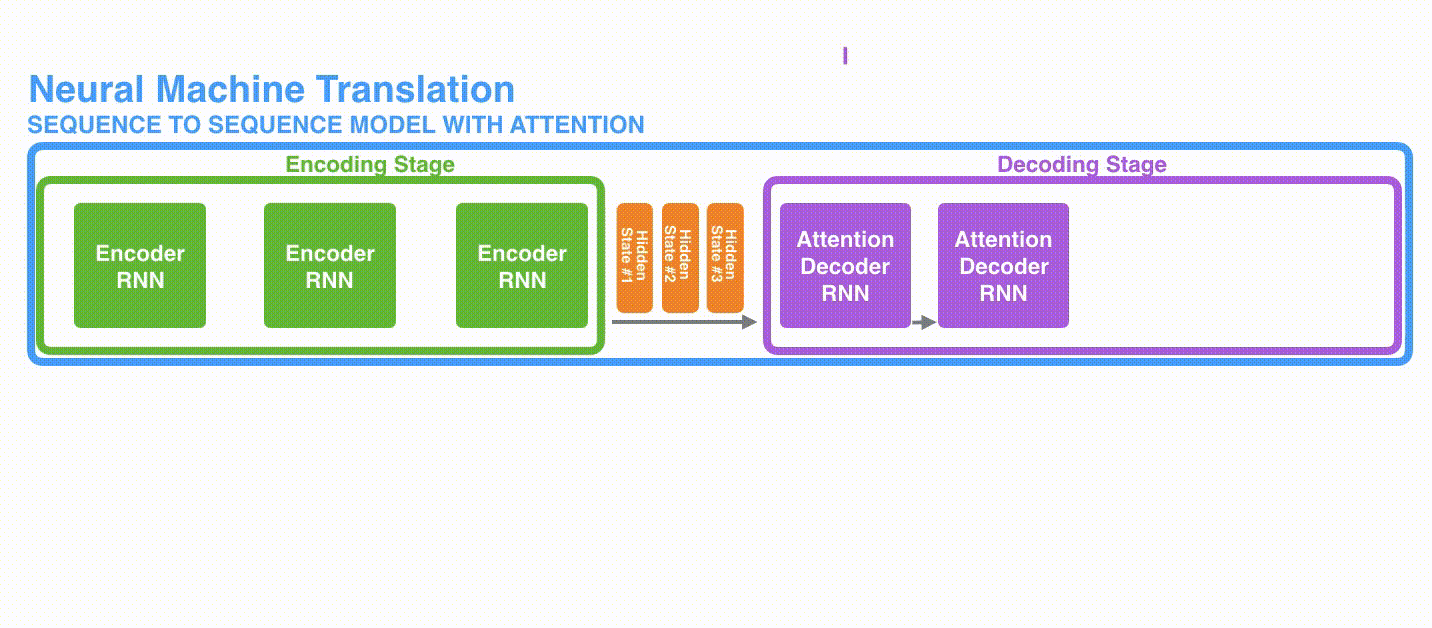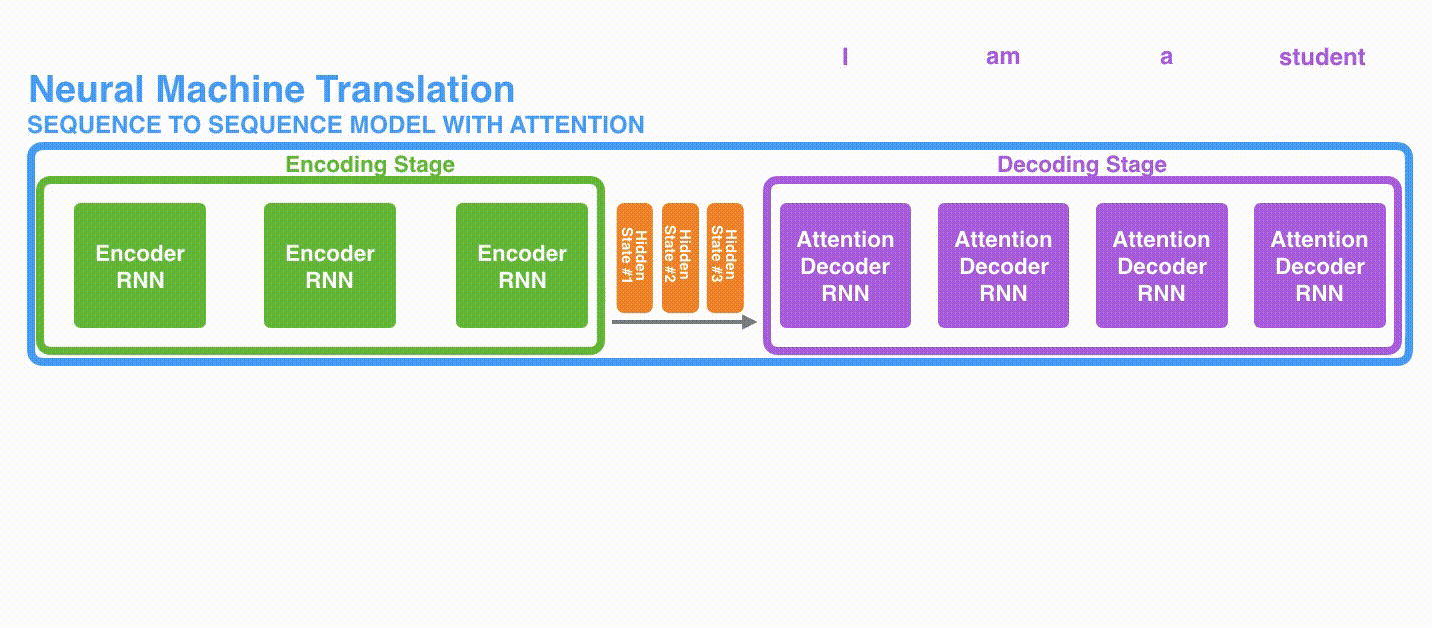
The Encoder-Decoder model consists of two RNNs, Encoder and Decoder, which process each element of input and compile the captured information into a fixed-dimensional context vector. After processing all the input, the Encoder sends the context vector to the Decoder, which takes the context vector, the hidden state, and the previous output as input and outputs each element one after the other.
- Encoder: Convert input word
x c - Decoder: outputs word
y_i c h_i y_{i-1}
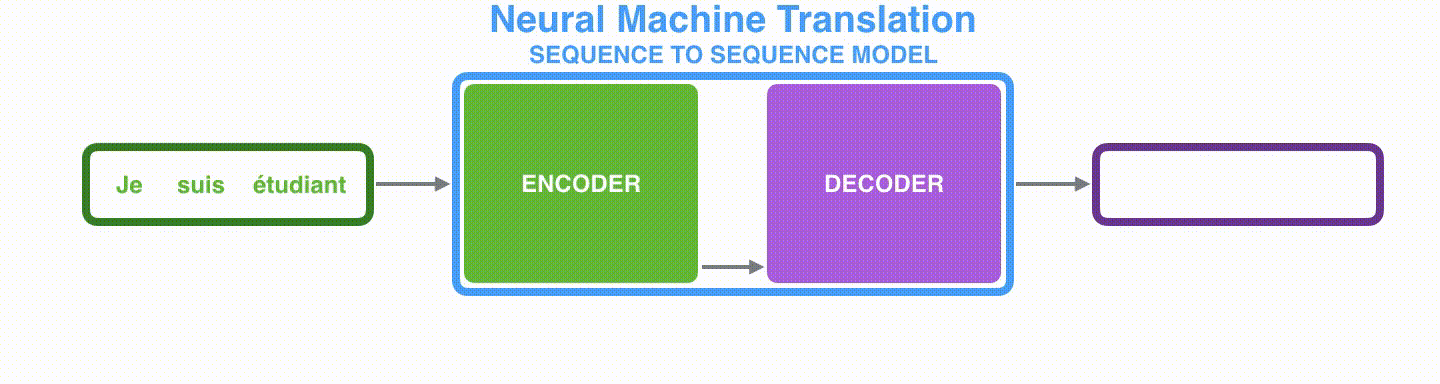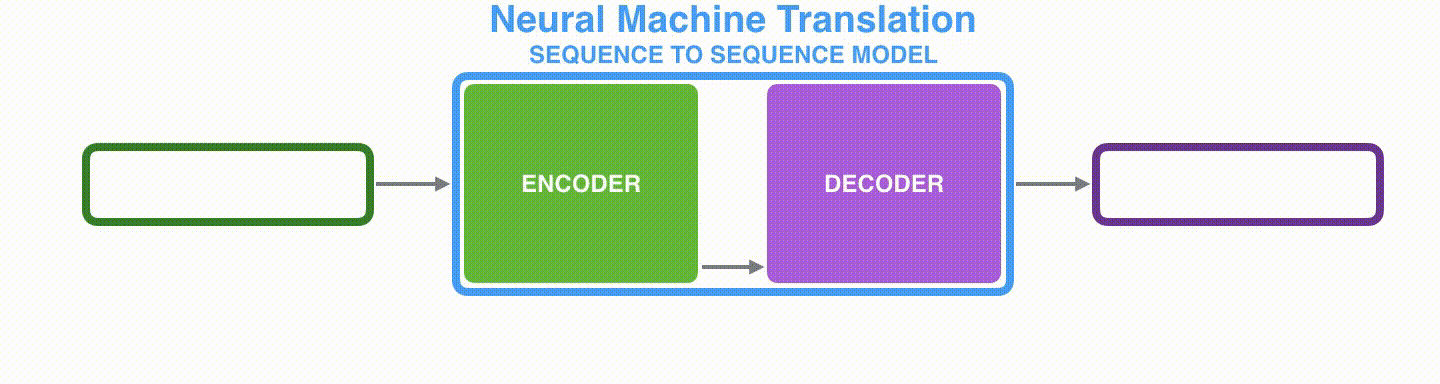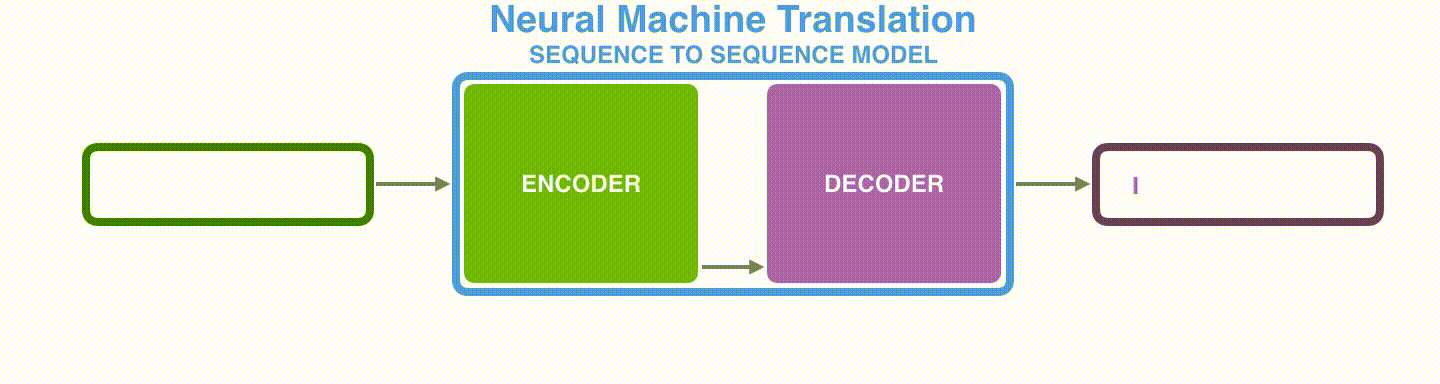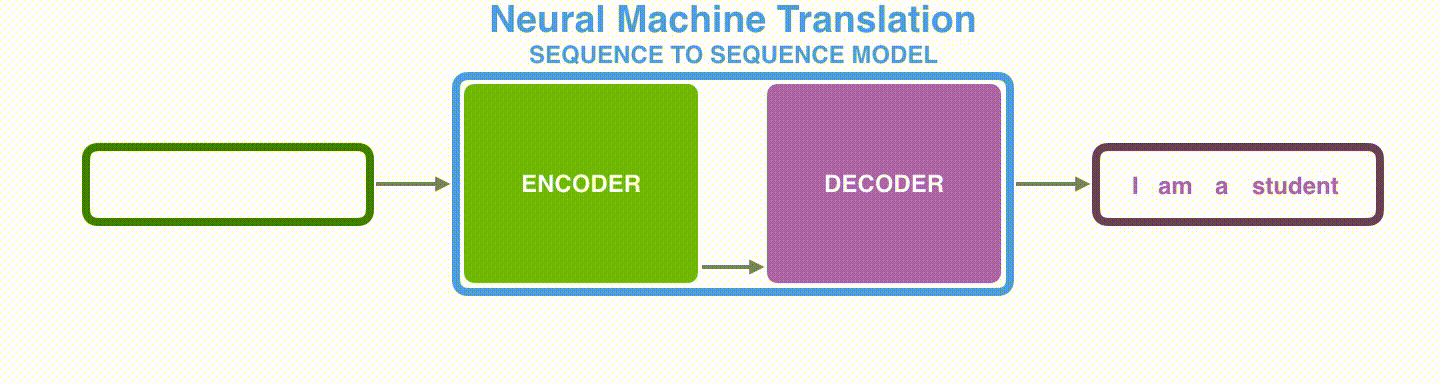
Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
The size of the context vector can be set when designing the model. Basically, it should be the same as the dimension of the hidden layer of RNN (256, 512, or 1024 dimensions). In the figure below, it is set to 4 dimensions.

Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
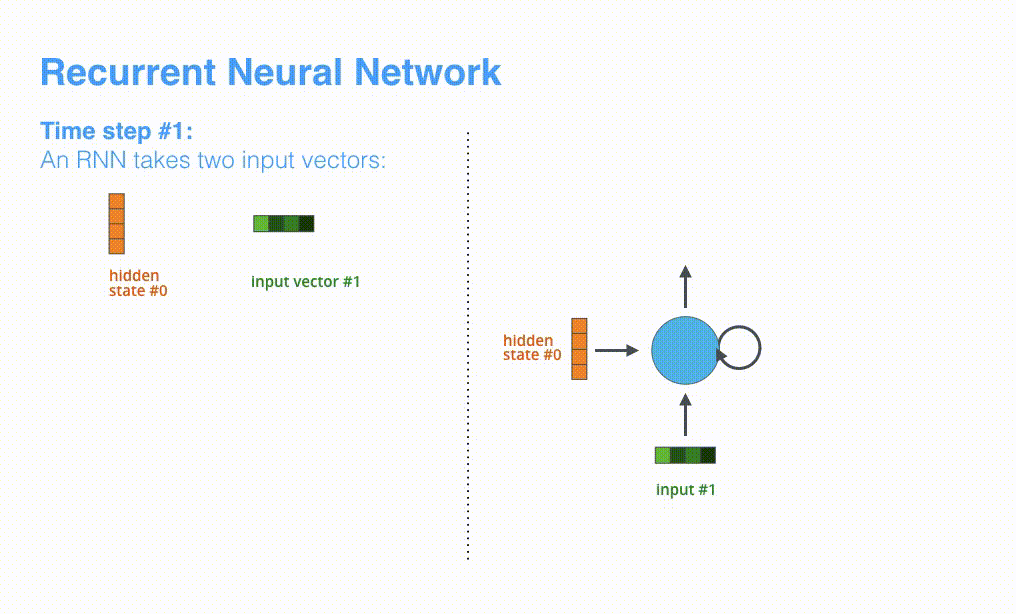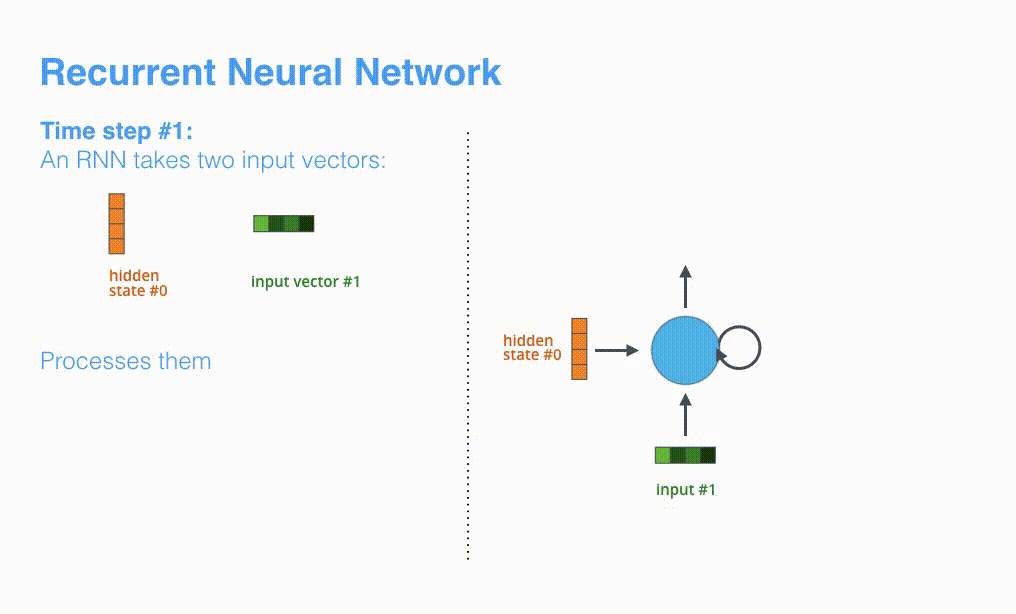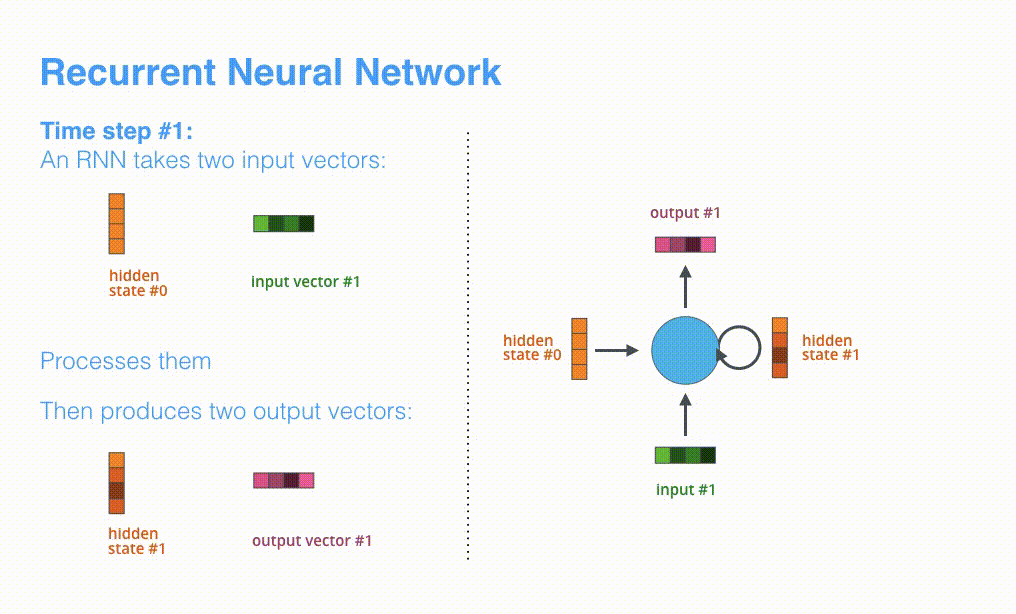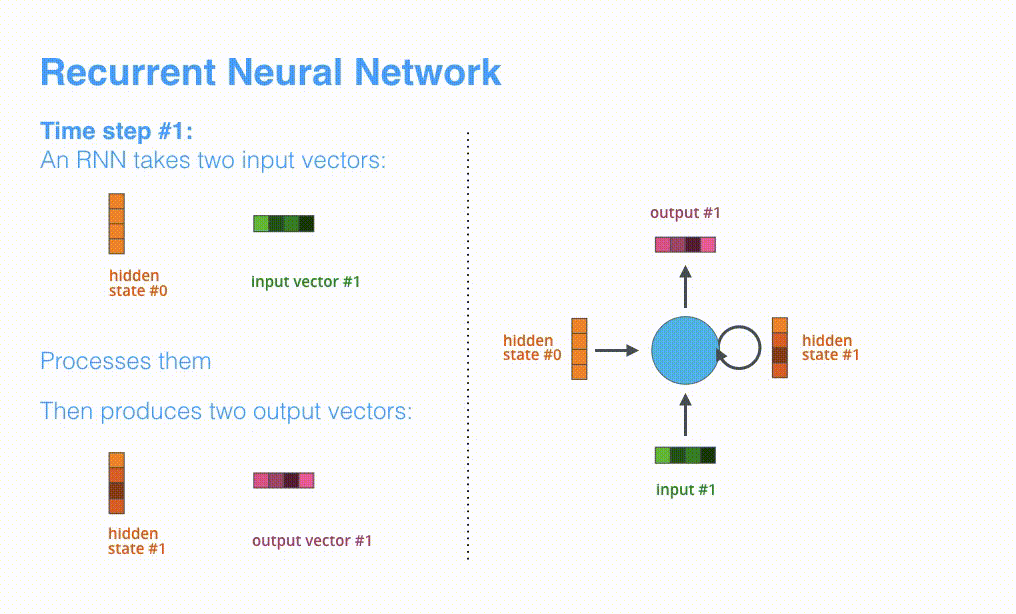
The RNN receives an input and a hidden state at each time step; in the case of Encoder, it receives a single word as input. The received word is converted into a word vector using an algorithm called word embedding. The word embedding model can be either an independently trained model or a pre-trained model. The dimension of the embedding vector is typically 200 or 300. The figure below shows a 4-dimensional vector.

Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
RNN receives hidden state #0 and input vector #1 at the first time step, processes them, and outputs hidden state #1 and input vector #2.
Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
The next timestep receives input #2 and hidden state #1. The next timestep receives input #3 and hidden state #2.
The Encoder-Decoder model of RNN behaves as shown in the figure below: the last hidden state processed by the Encoder (hidden state #3) is passed to the Decoder as a context vector.
Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
Decoder similarly maintains a hidden state for each time step and outputs a word using the context vector, hidden state, and one previous output as input.
Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
Encoder-Decoder model with Attention
In the Encoder-Decoder model, the context vector has a fixed dimension. This means that they are always converted to a vector representation of the same length by the Encoder. For short sentences, the converted vector representation is considered to retain information well, but the longer the sentence, the less information can fit into the vector representation. Therefore, the longer the sentence, the less accurate the vector representation becomes.
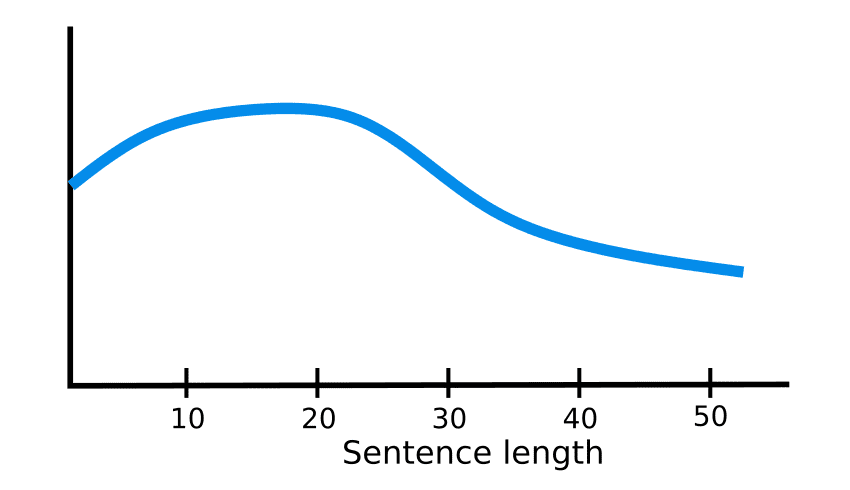
How Attention works in Deep Learning: understanding the attention mechanism in sequence models
The Attention architecture was created as a solution to this problem.
In Time Step 7, Attention allows the Decoder to focus on the étudiant before generating an English translation. Through a mechanism that amplifies the information in the input, the model with the addition of Attention performs better.
Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
The Encoder-Decoder model (seq2seq) with Attention differs from the traditional model in the following two ways
- The Encoder passes more information to the Decoder
- The Decoder focuses on the elements of the input that are relevant at each timestep
The first difference is that Encoder passes all hidden states to Decoder instead of passing the last hidden state.
The second difference is that the Decoder with Attention does the following at each time step before producing output
- look at all the hidden states of the incoming Encoder
- give each hidden state a score
- weight the hidden states by multiplying each hidden state by its score through softmax (amplify high-scoring hidden states and drown out low-scoring hidden states)

Attention works as follows:
- Decoder's RNN receives
<END>token and initial value of hidden state - RNN generates new hidden state (h4)
- Attention: Generate a context vector (C4) at each time step using all the hidden states of the Encoder and the hidden states generated by the Decoder (h4)
- Combine the Decoder's hidden state (h4) with the context vector (C4)
- Pass combined vectors through affine layers
- Outputs of the affine layer are output at each time step
- Repeat the above for each time step
The following is a look at what part of the input is being focused on at each timestep of the Decoder.
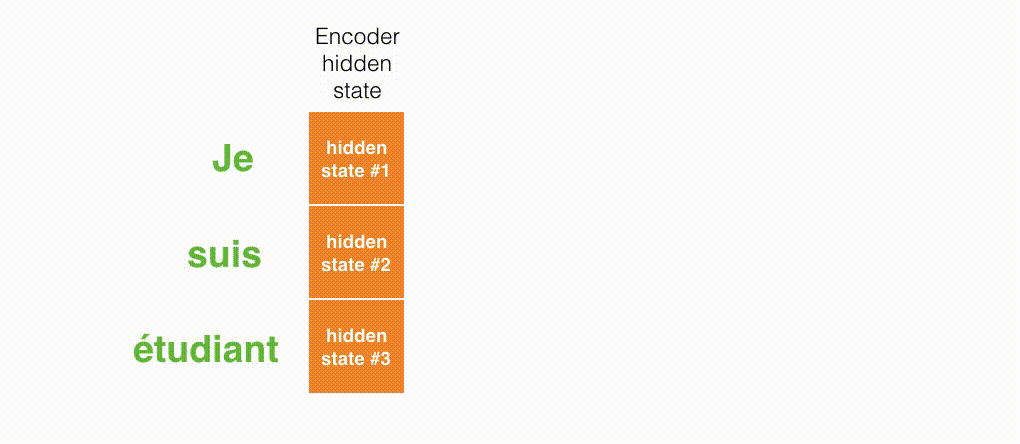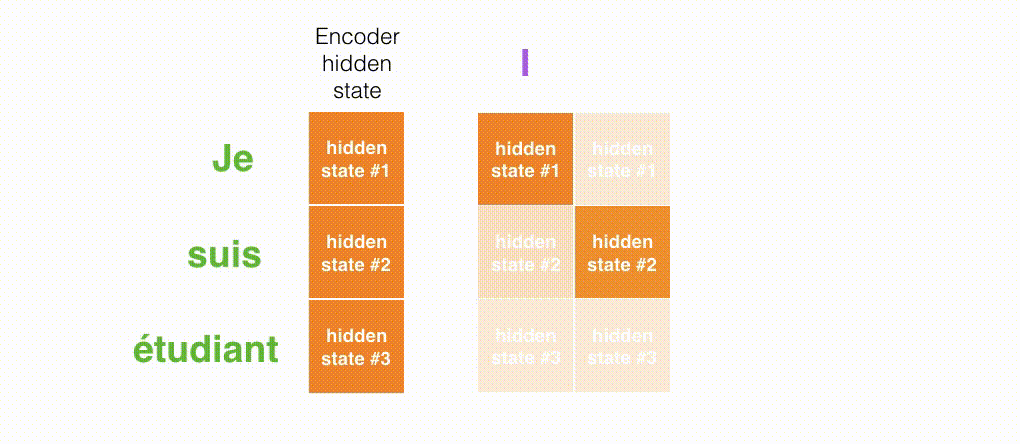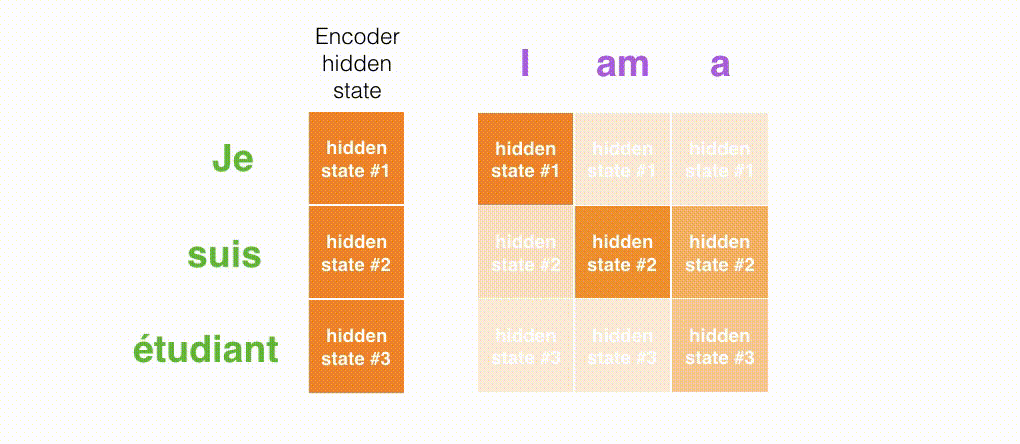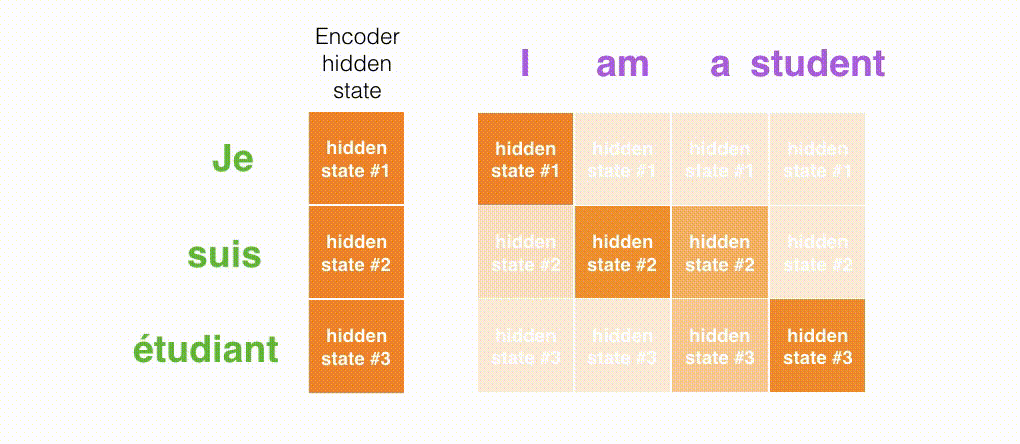
The figure below is from the paper Neural Machine Translation by Jointly Learning to Align and Translate. The whiter the color, the more Attention is focused. For example, when generating the word "agreement," it is clear that Attention is focused on the input word "accord".

References

















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS