



Hugging Face Transformers Tokenizer
The Transformer model does not allow direct input of raw text data, so text must be converted to numerical data. The Tokenizer performs this conversion.
The Tokenizer performs the following processing on the input text:
- Separates text into the smallest units such as words, sub-words, symbols, etc.
- Assign an ID to each token
- Add special tokens to the input text that provide information needed to populate the model
- For example, BERT requires tokens such as
<CLS>to indicate the beginning of a sentence and<EOS>to indicate the end of a sentence.
- For example, BERT requires tokens such as
You can use the from_pretrained method of the AutoTokenizer class to use a Tokenizer of the specified model.
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
encoded_input = tokenizer("Do not meddle in the affairs of wizards, for they are subtle and quick to anger.")
print(encoded_input)
>> {'input_ids': [101, 2079, 2025, 19960, 10362, 1999, 1996, 3821, 1997, 16657, 1010, 2005, 2027, 2024, 11259, 1998, 4248, 2000, 4963, 1012, 102],
>> 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
The meaning of the return value is as follows
| Return | Description |
|---|---|
| input_ids | Input text divided into tokens, each replaced by an ID |
| attention_mask | An indication of whether the input token is eligible for Attention |
| token_type_ids | A statement indicating which sentence each token belongs to, when a single input consists of multiple sentences |
Basic usage
Use the AutoTokenizer class to instantiate a Tokenizer as follows.
from transformers import AutoTokenizer
checkpoint = "bert-base-cased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
You can encode text using Tokenizer as follows.
text = "The quick brown fox jumps over the lazy dog."
encoded_text = tokenizer(text)
print(encoded_text)
>> {
>> 'input_ids': [101, 1109, 3613, 3058, 17594, 15457, 1166, 1204, 1103, 16688, 3676, 119, 102],
>> 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
>> }
The convert_ids_to_tokens method can also be used to convert from IDs to tokens.
tokens = tokenizer.convert_ids_to_tokens(encoded_text.input_ids)
print(tokens)
['[CLS]', 'The', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog', '.', '[SEP]']
[CLS] refers to tokens that indicate sentence beginnings in the BERT model, and [SEP] refers to tokens that indicate sentence breaks. In inputs_ids, 101 refers to [CLS] and 102 refers to [SEP].
The convert_tokens_to_string method can be used to convert from IDs to text.
print(tokenizer.convert_tokens_to_string(tokens))
[CLS] The quick brown fox jumps over the lazy dog. [SEP]
Conversion from ID to text is performed as follows.
decoded_string = tokenizer.decode(encoded_text["input_ids"])
print(decoded_string)
The quick brown fox jumps over the lazy dog.
Special tokens, etc., are automatically removed, making the form easy to utilize when outputting inference results.
Encoding of multiple sentences
Multiple sentences can be encoded together by passing them to Tokenizer as a list.
batch_sentences = [
"But what about second breakfast?",
"Don't think he knows about second breakfast, Pip.",
"What about elevensies?",
]
encoded_inputs = tokenizer(batch_sentences)
print(encoded_inputs)
>> {'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102],
>> [101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
>> [101, 1327, 1164, 5450, 23434, 136, 102]],
>> 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0],
>> [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> [0, 0, 0, 0, 0, 0, 0]],
>> 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1],
>> [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
>> [1, 1, 1, 1, 1, 1, 1]]}
The following options can be set for encoding:
- Padding each sentence to the maximum length of sentences in the batch
- Truncate each sentence to the maximum length allowed by the model
- Return tensor
Padding
The tensor, which is the input to the model, must have a uniform shape. Therefore, different lengths of sentences can be problematic. Padding is a strategy to ensure that the tensor is rectangular by adding a special padding token to short sentences.
If padding=True is set, the short sequences in a batch are padded to match the longest sequence.
batch_sentences = [
"But what about second breakfast?",
"Don't think he knows about second breakfast, Pip.",
"What about elevensies?",
]
encoded_input = tokenizer(batch_sentences, padding=True)
print(encoded_input)
>> {'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
>> [101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
>> [101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
>> 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
>> 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
>> [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
>> [1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
Truncation
On the other hand, there are cases where the sequence is too long for the model to handle. In this case, the sequence must be truncated to a shorter length.
Setting truncation=True will truncate the sequence to the maximum length the model will accept.
batch_sentences = [
"But what about second breakfast?",
"Don't think he knows about second breakfast, Pip.",
"What about elevensies?",
]
encoded_input = tokenizer(batch_sentences, padding=True, truncation=True)
print(encoded_input)
>> {'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
>> [101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
>> [101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
>> 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
>> 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
>> [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
>> [1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
Return tensor
Returns the actual tensors given to the model to the Tokenizer.
Set the return_tensors parameter to pt for PyTorch or tf for TensorFlow.
batch_sentences = [
"But what about second breakfast?",
"Don't think he knows about second breakfast, Pip.",
"What about elevensies?",
]
encoded_input = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="pt")
print(encoded_input)
>> {'input_ids': tensor([[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
>> [101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
>> [101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]]),
>> 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]),
>> 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
>> [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
>> [1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]])}
batch_sentences = [
"But what about second breakfast?",
"Don't think he knows about second breakfast, Pip.",
"What about elevensies?",
]
encoded_input = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="tf")
print(encoded_input)
>> {'input_ids': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
>> array([[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
>> [101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
>> [101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
>> dtype=int32)>,
>> 'token_type_ids': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
>> array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], dtype=int32)>,
>> 'attention_mask': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
>> array([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
>> [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
>> [1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]], dtype=int32)>}
Recommended Options
The following table summarizes the recommended options for padding and truncation.
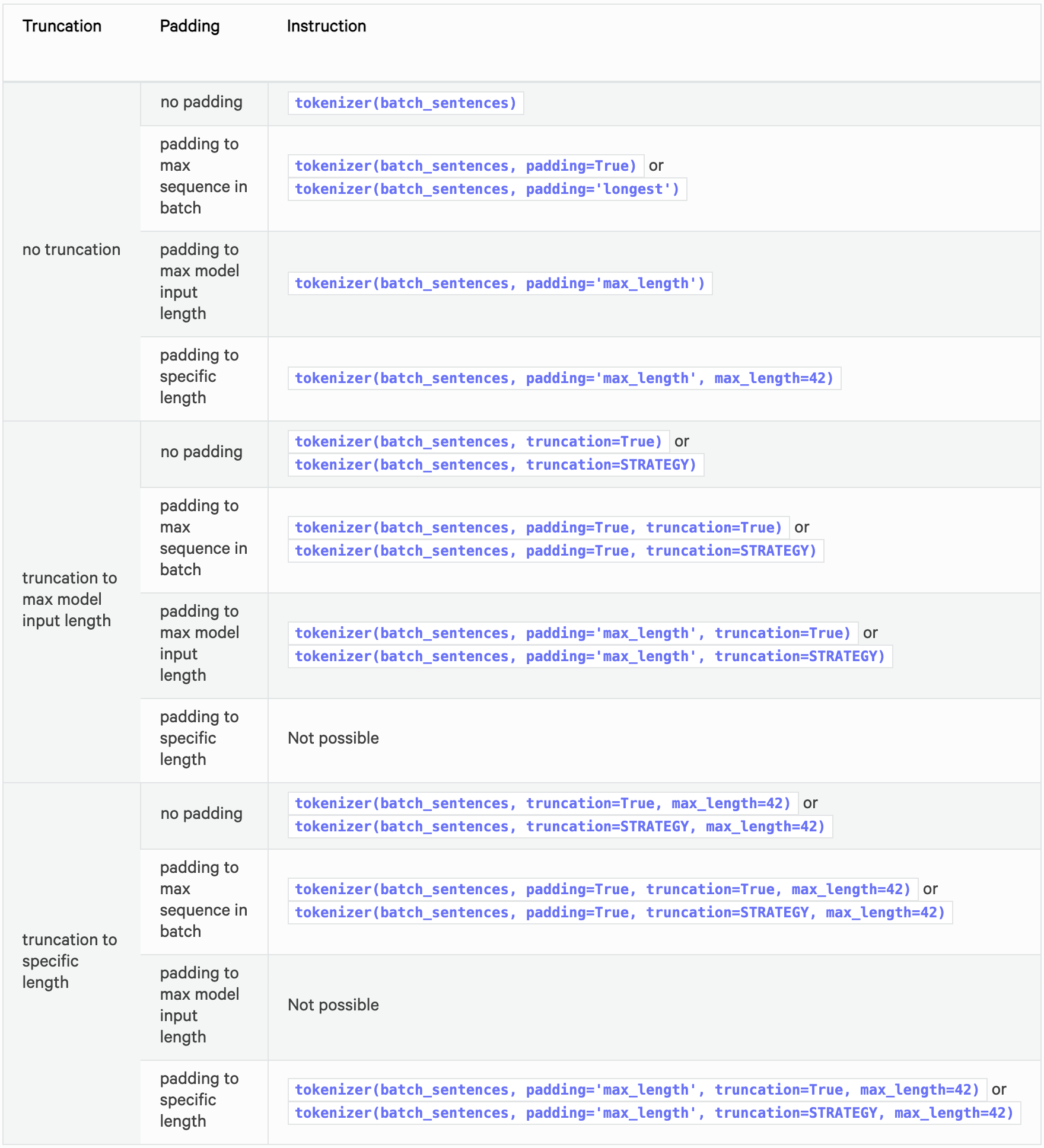
See below for detailed specifications of padding and truncation.
Sentence pairs
Sometimes it is necessary to provide sentence pairs to the model, such as when one wants to classify whether two sentences are similar.
In BERT, the input is represented as follows.
[CLS] Sequence A [SEP] Sequence B [SEP]
Two sentences can be given as two arguments to encode a pair of sentences in the format expected by the model.
encoded_input = tokenizer("How old are you?", "I'm 6 years old")
print(encoded_input)
>> {'input_ids': [101, 1731, 1385, 1132, 1128, 136, 102, 146, 112, 182, 127, 1201, 1385, 102],
>> 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1],
>> 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
The token_type_ids is used to determine which part is sentence A and which part is sentence B. Therefore, token_type_ids is not required for all models.
By default, Tokenizer tokenization returns only the input expected by the associated model. You can use return_input_ids or return_token_type_ids to force the return or non-return of one of these special arguments.
Decoding the retrieved token ID will show that the special token has been properly added.
tokenizer.decode(encoded_input["input_ids"])
>> "[CLS] How old are you? [SEP] I'm 6 years old [SEP]"
If you have a list of sentence pairs you wish to process, pass those two lists to the Tokenizer.
batch_sentences = ["Hello I'm a single sentence",
"And another sentence",
"And the very very last one"]
batch_of_second_sentences = ["I'm a sentence that goes with the first sentence",
"And I should be encoded with the second sentence",
"And I go with the very last one"]
encoded_inputs = tokenizer(batch_sentences, batch_of_second_sentences)
print(encoded_inputs)
>> {'input_ids': [[101, 8667, 146, 112, 182, 170, 1423, 5650, 102, 146, 112, 182, 170, 5650, 1115, 2947, 1114, 1103, 1148, 5650, 102],
>> [101, 1262, 1330, 5650, 102, 1262, 146, 1431, 1129, 12544, 1114, 1103, 1248, 5650, 102],
>> [101, 1262, 1103, 1304, 1304, 1314, 1141, 102, 1262, 146, 1301, 1114, 1103, 1304, 1314, 1141, 102]],
>> 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
>> [0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
>> [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1]],
>> 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
>> [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
>> [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
It is also possible to decode the list of input_ids one by one to check the ones given in the model.
for ids in encoded_inputs["input_ids"]:
print(tokenizer.decode(ids))
>> [CLS] Hello I'm a single sentence [SEP] I'm a sentence that goes with the first sentence [SEP]
>> [CLS] And another sentence [SEP] And I should be encoded with the second sentence [SEP]
>> [CLS] And the very very last one [SEP] And I go with the very last one [SEP]
Pre-Tokenized input
You can also pass pre-tokenized input to the Tokenizer.
If you want to use pre-tokenized input, specify is_pretokenized=True when passing input to Tokenizer.
encoded_input = tokenizer(["Hello", "I'm", "a", "single", "sentence"], is_pretokenized=True)
print(encoded_input)
>> {'input_ids': [101, 8667, 146, 112, 182, 170, 1423, 5650, 102],
>> 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0],
>> 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
Note that Tokenizer will add special tokens unless you specify add_special_tokens=False.
A batch of statements can be encoded as follows.
batch_sentences = [["Hello", "I'm", "a", "single", "sentence"],
["And", "another", "sentence"],
["And", "the", "very", "very", "last", "one"]]
encoded_inputs = tokenizer(batch_sentences, is_pretokenized=True)
You can also encode sentence pairs as follows.
batch_of_second_sentences = [["I'm", "a", "sentence", "that", "goes", "with", "the", "first", "sentence"],
["And", "I", "should", "be", "encoded", "with", "the", "second", "sentence"],
["And", "I", "go", "with", "the", "very", "last", "one"]]
encoded_inputs = tokenizer(batch_sentences, batch_of_second_sentences, is_pretokenized=True)
References















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS