



はじめに
近年、機械学習と自然言語処理の分野は急速に進歩しています。その中でも、Large Language Model (LLM)は、研究者や開発者から注目を集めています。
独自のドキュメントやウェブスクレイピングで得られた最新の情報をデータベースに保存し、LLMと統合することにより、システムが最新情報を含んだ応答を提供できます。この記事では、Vector DBと独自データを使用してLLMシステムを構築する方法について説明します。
システムアーキテクチャ
ドキュメントの取り込み
独自データを使用したLLMシステムのドキュメント取り込みシステムのアーキテクチャは、次のようになります。
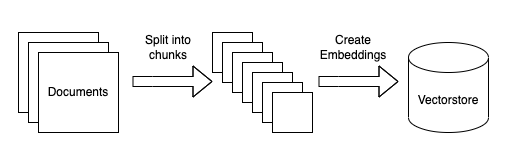
一連のドキュメントの取り込み
LLMシステムに独自データを埋め込む最初の段階では、必要なドキュメントを取得します。このためには、APIアクセスやウェブスクレイピングなど、さまざまな方法が利用できます。
ドキュメントを小さなチャンクに分割
LLMシステムがデータを効果的に処理できるようにするために、大きなドキュメントをパラグラフや文のような扱いやすいセグメントに細分化することが有益です。このセグメンテーションプロセスにより、後の段階で重要なデータを効率的に抽出することが可能となります。
各ドキュメントのベクトル表現を作成
各チャンクは高次元のベクトル表現に変換されます。これらのベクトルは、後のクエリ処理で使用するためにベクトルに保存されます。
クエリ
LLMシステムのクエリは、以下に示すアーキテクチャ設計に従います。
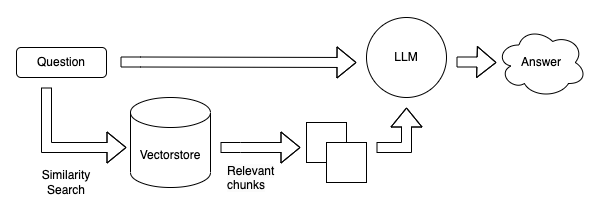
クエリのためのベクトル生成
ユーザーからのクエリが送信されると、システムは迅速にそれのベクトル表現を作成します。このステップにより、クエリと保存されたドキュメントのチャンクとの類似度スコアを効率的に計算することが可能となります。
ベクトルDBでもっとも類似度の高いドキュメントを検索
ベクトルDBを活用して、システムはクエリベクトルにもっとも類似したドキュメントベクトルを探します。この検索手法により、システムは迅速にユーザーのクエリに関連するドキュメントを特定することができます。
ドキュメントと元のクエリをLLMに供給して応答を生成
最後に、ベクトルDBから選択されたドキュメントと元のクエリがLLMシステムに入力されます。このシステムは、与えられた入力に基づいて適切な応答を生成し、ユーザーに伝えます。
参考















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS