
はじめに
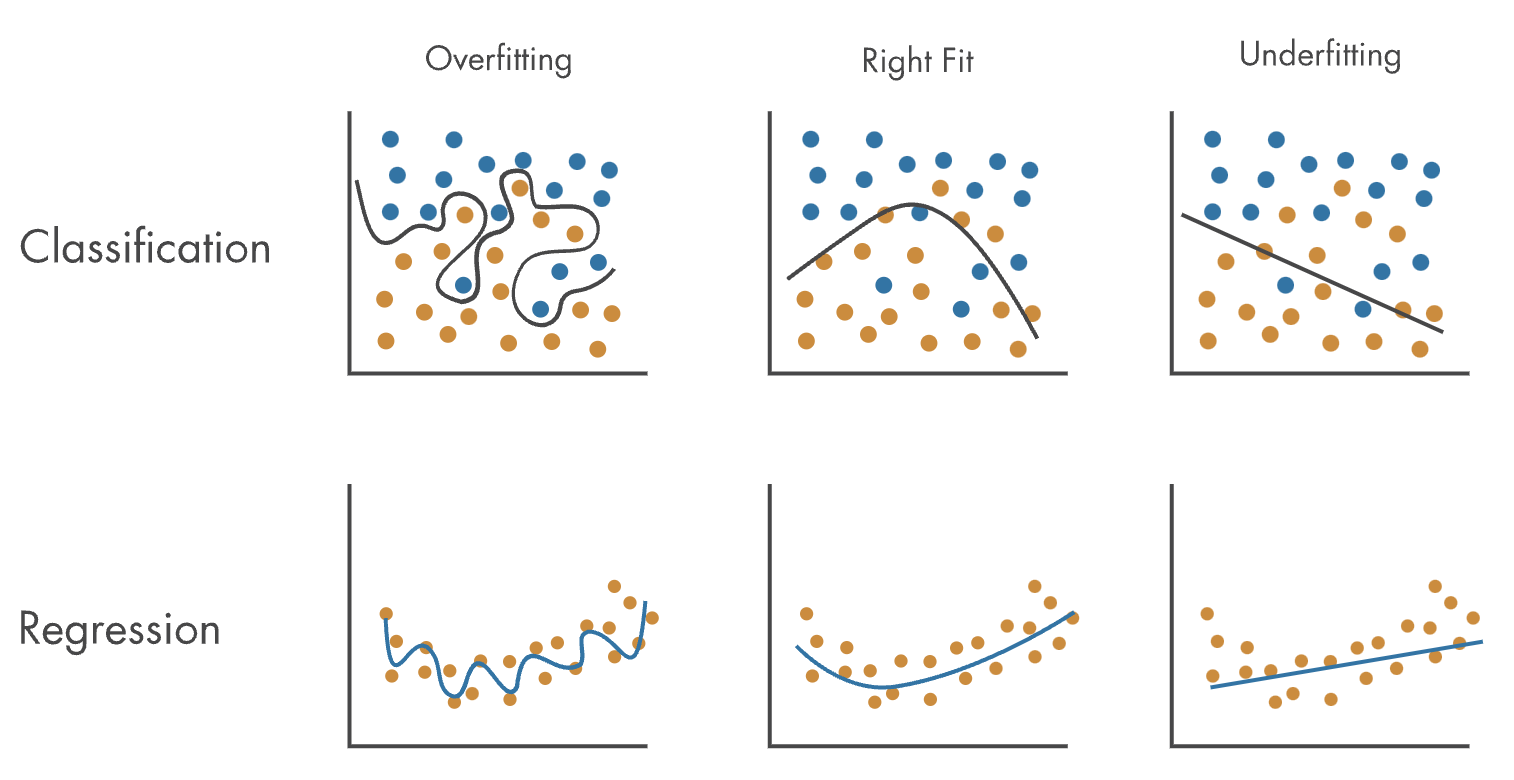
機械学習モデルの成功は、入力データに基づいて正確な予測を行う能力によって決まります。成功したモデルは、新しい未知のデータにも適応でき、データの基本的な構造を捉えつつ、オーバーフィッティングやアンダーフィッティングを避けるためにモデルの性能を最適化する必要があります。
Avoid overfitting machine learning models
アンダーフィッティング(過小適合)とは
アンダーフィッティングとは、機械学習モデルがトレーニングデータの基本的な構造やパターンを捉えられない状態のことを指します。つまり、モデルが入力特徴量と出力予測の間の関係を正確に表現するために十分な複雑性を持っていないため、訓練データおよびテストデータの両方でパフォーマンスが低下します。
アンダーフィッティングの原因
機械学習モデルでアンダーフィッティングが起こる原因としては、次のものが挙げられます。
-
モデルの複雑性不足
モデルが入力特徴量と出力予測の間の真の関係を表現するための十分な複雑性を持っていない場合、アンダーフィッティングが生じます。例えば、非線形な関係を持つ問題に対して線形回帰モデルを使用した場合などが該当します。 -
不十分な特徴量エンジニアリング
入力特徴量が出力予測に関する十分な情報を提供しない場合、モデルはそれらの間の関係を学習するのが難しくなり、アンダーフィッティングにつながります。これは、関連する特徴量が欠けているか、特徴量表現が不十分である場合があります。 -
過剰な正則化
正則化は、損失関数にペナルティ項を追加することで、オーバーフィッティングを防ぐためのテクニックです。しかし、正則化項が大きすぎると、モデルを制限しすぎてデータにアンダーフィットさせることがあります。
アンダーフィッティングがモデルのパフォーマンスに与える影響
アンダーフィッティングは、機械学習モデルのパフォーマンスにいくつかの負の影響を与えます。
-
低い訓練およびテスト精度
アンダーフィットしたモデルは、データの基本的な構造を捉えることができないため、トレーニングデータでのパフォーマンスが低下します。このパフォーマンスの低さは、テストデータでも観察され、予測精度が低下します。 -
高いバイアス
アンダーフィットは、高いバイアスとして特徴付けられることが多く、つまりモデルが真の値から大きく外れた予測を一貫して出力することを示します。高いバイアスは、モデルのデータに関する仮定が不正確または過剰に簡略化されていることを示します。 -
不十分な汎化性能
アンダーフィットしたモデルは、トレーニングデータの基本的な関係を捉えていないため、新しい未知のデータに対して汎化することができません。
オーバーフィッティング(過剰適合)とは
オーバーフィッティングとは、機械学習モデルがトレーニングデータの基本的な構造やパターンだけでなく、ノイズやランダムな変動も学習してしまう状態のことを指します。つまり、モデルが過度に複雑であり、トレーニングデータに適合しすぎて新しい未知のデータに対する汎化性能が低下することになります。オーバーフィットしたモデルは、トレーニングデータでは優れたパフォーマンスを示しますが、テストデータでは性能が低下します。
オーバーフィッティングの原因
機械学習モデルでオーバーフィッティングが起こる原因としては、次のものが挙げられます。
-
過度なモデルの複雑性
モデルがあまりに複雑すぎる場合、トレーニングデータのノイズや変動にも適応してしまい、オーバーフィッティングにつながります。例えば、限られたトレーニングデータに対して多数のレイヤーとニューロンを持つディープニューラルネットワークを使用する場合があります。 -
不十分なトレーニングデータ
トレーニングデータが小さすぎる場合や、人口集団を適切に代表していない場合、モデルはトレーニングデータに適合しすぎてしまい、オーバーフィッティングにつながります。 -
適切な正則化が行われていない
正則化項が小さすぎる場合、モデルがあまりに複雑になり、オーバーフィッティングにつながります。
オーバーフィッティングがモデルのパフォーマンスに与える影響
オーバーフィッティングは、機械学習モデルのパフォーマンスにいくつかの負の影響を与えます。
-
高い訓練精度、低いテスト精度
オーバーフィットしたモデルは、トレーニングデータの基本的な構造やノイズを学習しているため、トレーニングデータで優れたパフォーマンスを示します。しかし、この高い精度は、テストデータでは性能が低下することになります。 -
高い分散
オーバーフィットは、高い分散として特徴付けられることが多く、つまり、モデルの予測が入力データの小さな変化に非常に敏感であることを示します。高い分散は、モデルが過度に複雑であり、新しいデータに対して十分に汎化できないことを示します。 -
不十分な汎化性能
オーバーフィットしたモデルは、トレーニングデータのノイズを学習してしまっているため、新しい未知のデータに対して十分に汎化できないことがあります。そのため、オーバーフィットしたモデルは、実際の問題に対する予測を行うために使用されることはできません。
参考


















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS