


はじめに
この記事では、Optuna と MLflow Tracking を組み合わせて実験管理する例を紹介します。
LightGBM の例
ライブラリをインストールします。
$ pip install mlflow
$ pip install optuna
$ pip install scikit-learn
$ pip install lightgbm
次のLightGBMのコードをmlflow_lightgbm.pyに記述します。
mlflow_lightgbm.py
import lightgbm as lgb
import numpy as np
import sklearn.datasets
import sklearn.metrics
from sklearn.model_selection import train_test_split
import optuna
import mlflow
def mlflow_callback(study: optuna.Study, trial: optuna.Trial):
mlflow.set_experiment("LightGBM")
trial_value = trial.value if trial.value is not None else float("nan")
with mlflow.start_run(run_name=str(trial.number)):
mlflow.log_params(trial.params)
mlflow.log_metrics({"accuracy": trial_value})
def objective(trial: optuna.Trial):
data, target = sklearn.datasets.load_breast_cancer(return_X_y=True)
train_x, test_x, train_y, test_y = train_test_split(data, target, test_size=0.25)
dtrain = lgb.Dataset(train_x, label=train_y)
param = {
"objective": "binary",
"metric": "binary_logloss",
"verbosity": -1,
"boosting_type": "gbdt",
"lambda_l1": trial.suggest_loguniform("lambda_l1", 1e-8, 10.0),
"lambda_l2": trial.suggest_loguniform("lambda_l2", 1e-8, 10.0),
"num_leaves": trial.suggest_int("num_leaves", 2, 256),
"feature_fraction": trial.suggest_uniform("feature_fraction", 0.4, 1.0),
"bagging_fraction": trial.suggest_uniform("bagging_fraction", 0.4, 1.0),
"bagging_freq": trial.suggest_int("bagging_freq", 1, 7),
"min_child_samples": trial.suggest_int("min_child_samples", 5, 100),
}
gbm = lgb.train(param, dtrain)
preds = gbm.predict(test_x)
pred_labels = np.rint(preds)
accuracy = sklearn.metrics.accuracy_score(test_y, pred_labels)
return accuracy
if __name__ == "__main__":
study = optuna.create_study(
direction="maximize",
)
study.optimize(
objective,
n_trials=100,
callbacks=[mlflow_callback]
)
print("Number of finished trials: {}".format(len(study.trials)))
print("Best trial:")
trial = study.best_trial
print(" Value: {}".format(trial.value))
print(" Params: ")
for key, value in trial.params.items():
print(" {}: {}".format(key, value))
次のコマンドを実行します。
$ python mlflow_lightgbm.py
Optunaの試行の結果が返ってきます。
Number of finished trials: 100
Best trial:
Value: 0.993006993006993
Params:
lambda_l1: 0.06612656999057859
lambda_l2: 2.052197523772018
num_leaves: 119
feature_fraction: 0.4295597947409407
bagging_fraction: 0.8875131492710178
bagging_freq: 2
min_child_samples: 24
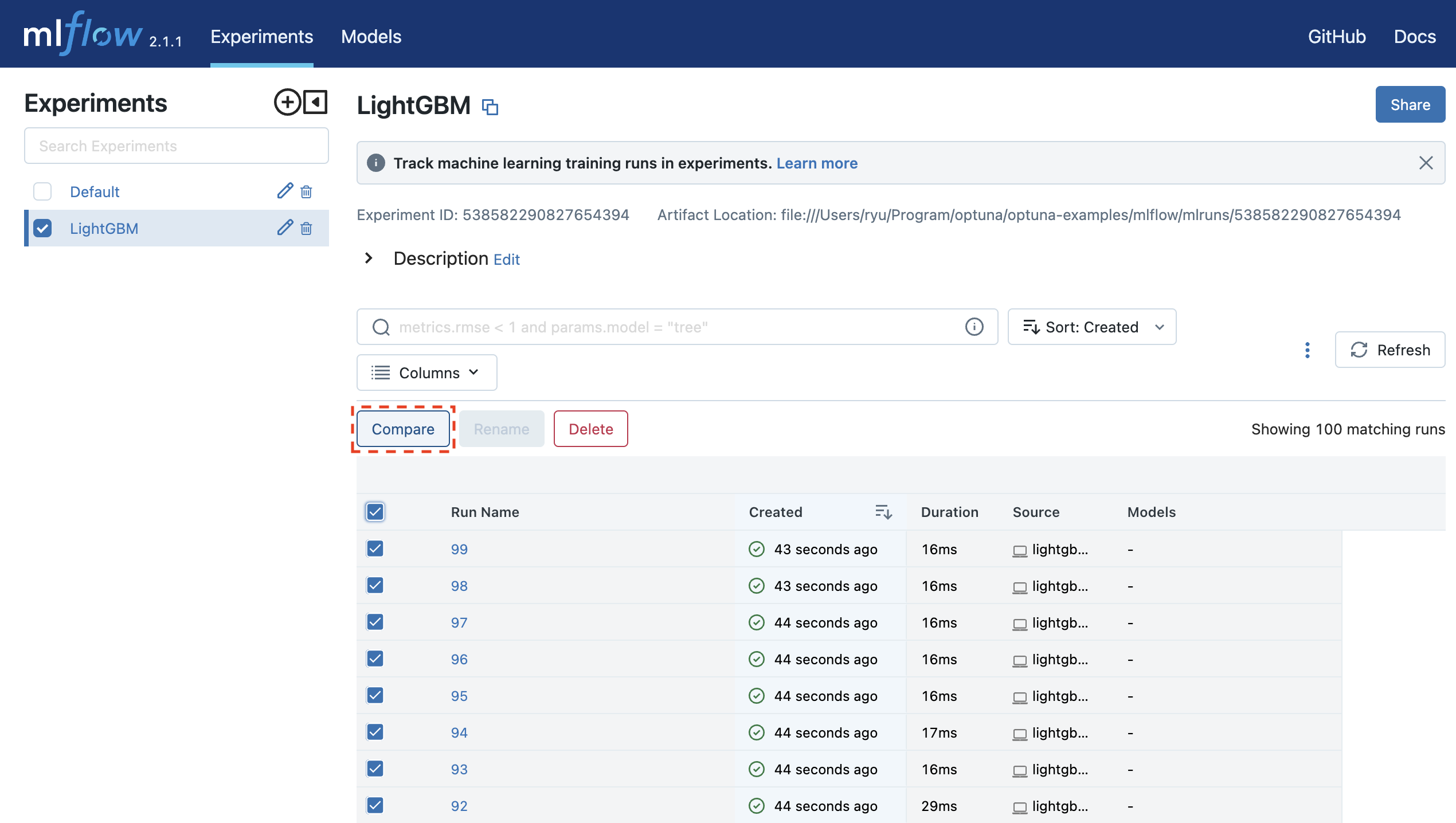
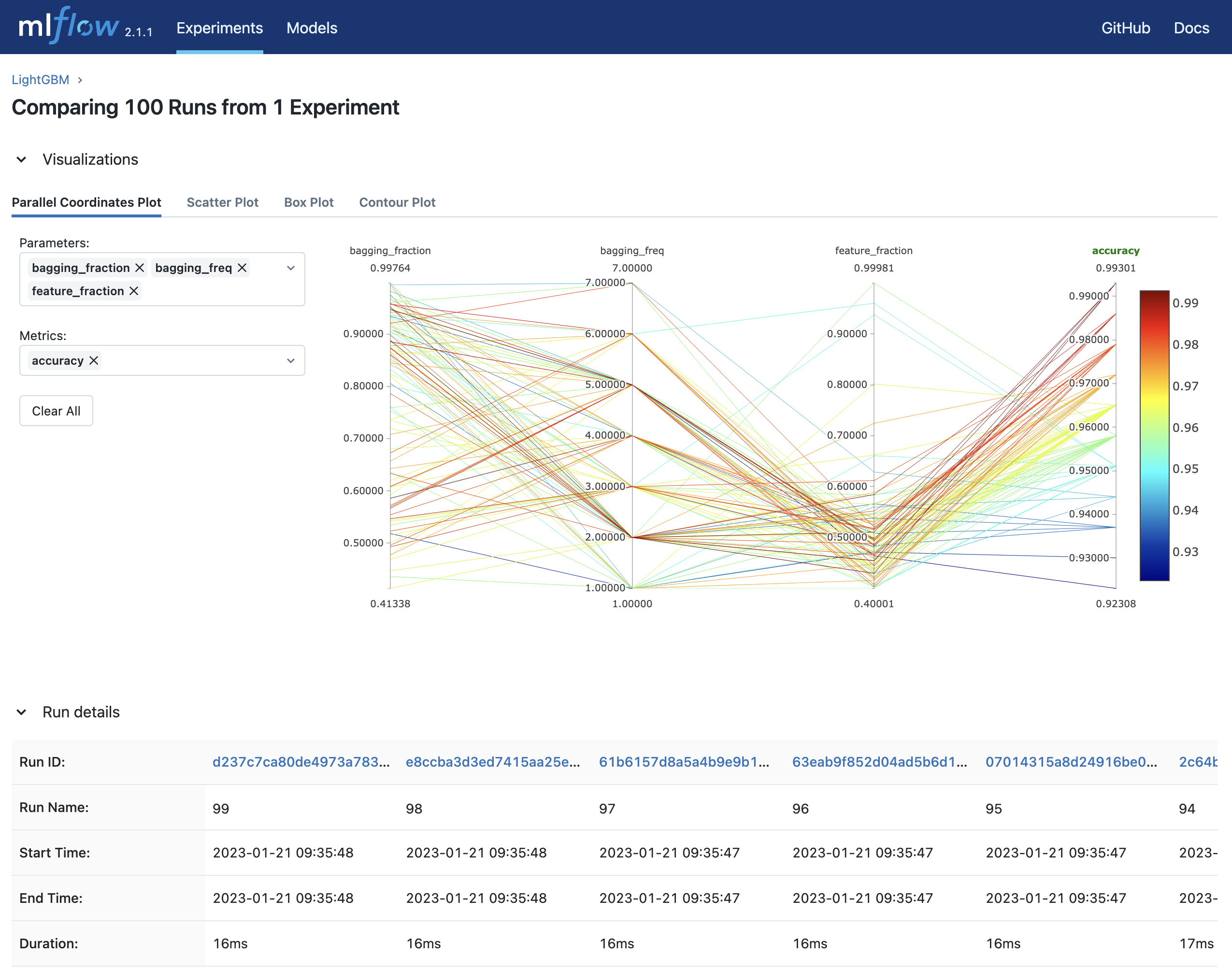
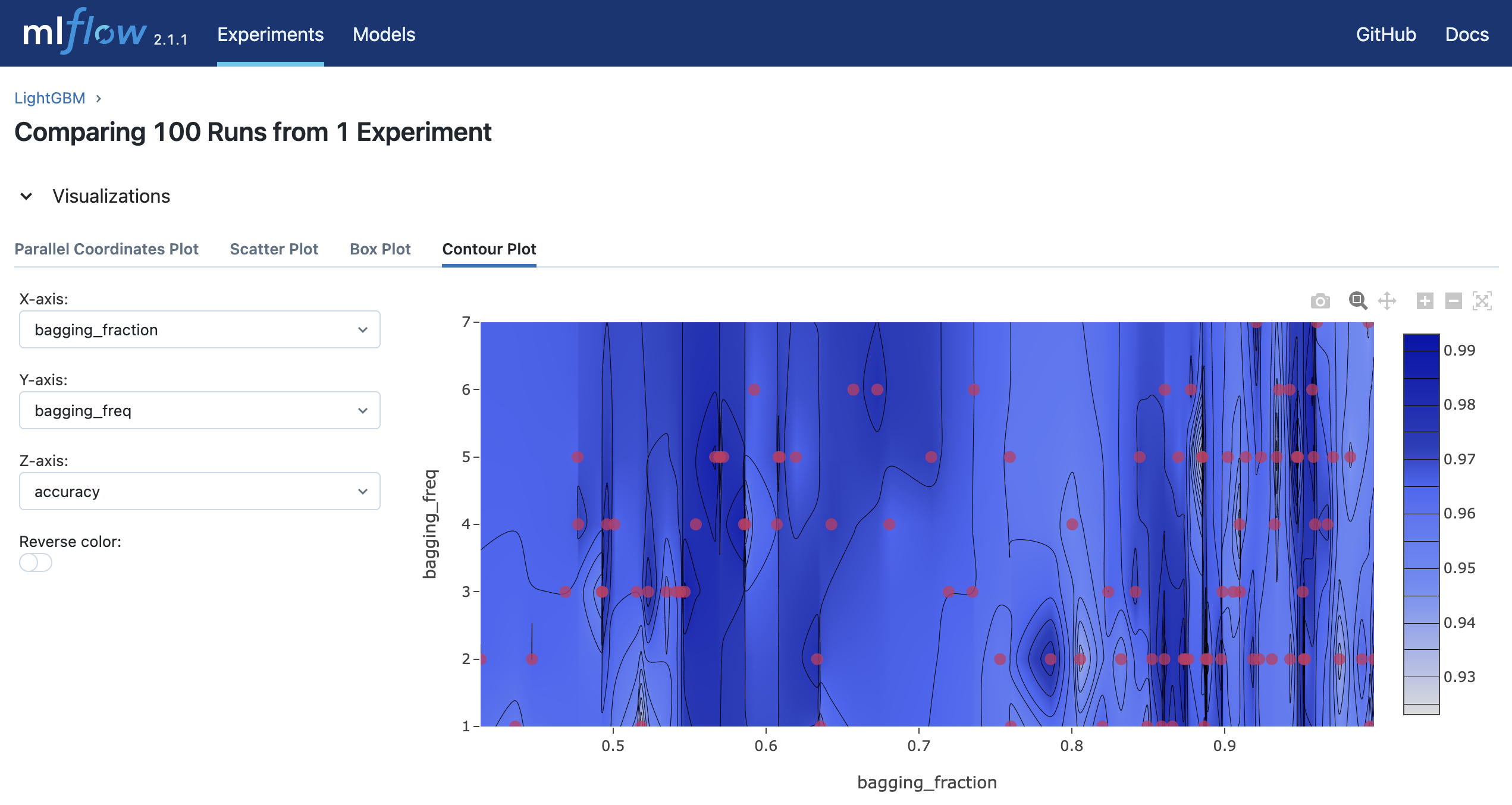
mlflow uiを実行し、 http://127.0.0.1:5000にアクセスするとブラウザ上で実験結果を確認することができます。
$ mlflow ui
Keras の例
ライブラリをインストールします。
$ pip install mlflow
$ pip install optuna
$ pip install scikit-learn
$ pip install tensorflow
次のKerasのコードをmlflow_keras.pyに記述します。Optunaは、optuna.integration.MLflowCallback というMLflowとの統合機能を提供しています。以下では、optuna.integration.MLflowCallbackを使った場合のコードを記述しています。
mlflow_keras.py
import optuna
from optuna.integration.mlflow import MLflowCallback
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from tensorflow.keras.backend import clear_session
from tensorflow.keras.layers import Dense
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import SGD
TEST_SIZE = 0.25
BATCHSIZE = 16
EPOCHS = 100
def standardize(data):
return StandardScaler().fit_transform(data)
def create_model(num_features: int, trial: optuna.Trial):
model = Sequential()
model.add(
Dense(
num_features,
activation="relu",
kernel_initializer="normal",
input_shape=(num_features,),
)
),
model.add(Dense(16, activation="relu", kernel_initializer="normal"))
model.add(Dense(16, activation="relu", kernel_initializer="normal"))
model.add(Dense(1, kernel_initializer="normal", activation="linear"))
optimizer = SGD(
learning_rate=trial.suggest_float("learning_rate", 1e-5, 1e-1, log=True),
momentum=trial.suggest_float("momentum", 0.0, 1.0),
)
model.compile(loss="mean_squared_error", optimizer=optimizer)
return model
def objective(trial: optuna.Trial):
# Clear clutter from previous Keras session graphs.
clear_session()
X, y = load_wine(return_X_y=True)
X = standardize(X)
X_train, X_valid, y_train, y_valid = train_test_split(
X, y, test_size=TEST_SIZE, random_state=42
)
model = create_model(X.shape[1], trial)
model.fit(X_train, y_train, shuffle=True, batch_size=BATCHSIZE, epochs=EPOCHS, verbose=False)
return model.evaluate(X_valid, y_valid, verbose=0)
if __name__ == "__main__":
mlflc = MLflowCallback(metric_name="mean_squared_error")
study = optuna.create_study(
study_name="Keras",
)
study.optimize(objective, n_trials=100, timeout=600, callbacks=[mlflc])
print("Number of finished trials: {}".format(len(study.trials)))
print("Best trial:")
trial = study.best_trial
print(" Value: {}".format(trial.value))
print(" Params: ")
for key, value in trial.params.items():
print(" {}: {}".format(key, value))
次のコマンドを実行します。
$ python mlflow_keras.py
Optunaの試行の結果が返ってきます。
Number of finished trials: 100
Best trial:
Value: 0.0008772228611633182
Params:
learning_rate: 0.046622562292222114
momentum: 0.9013368782978584
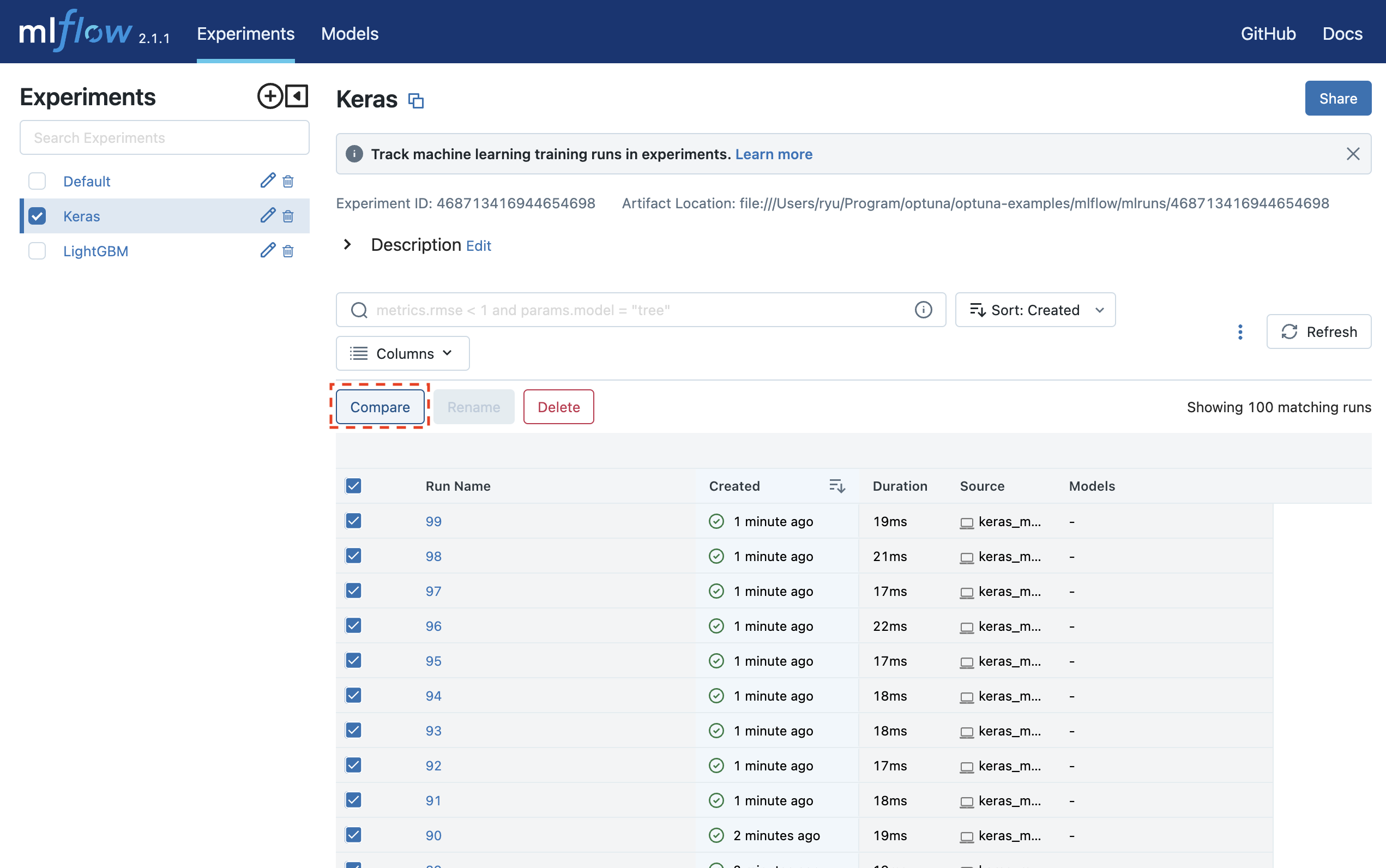
mlflow uiを実行し、 http://127.0.0.1:5000にアクセスするとブラウザ上で実験結果を確認することができます。
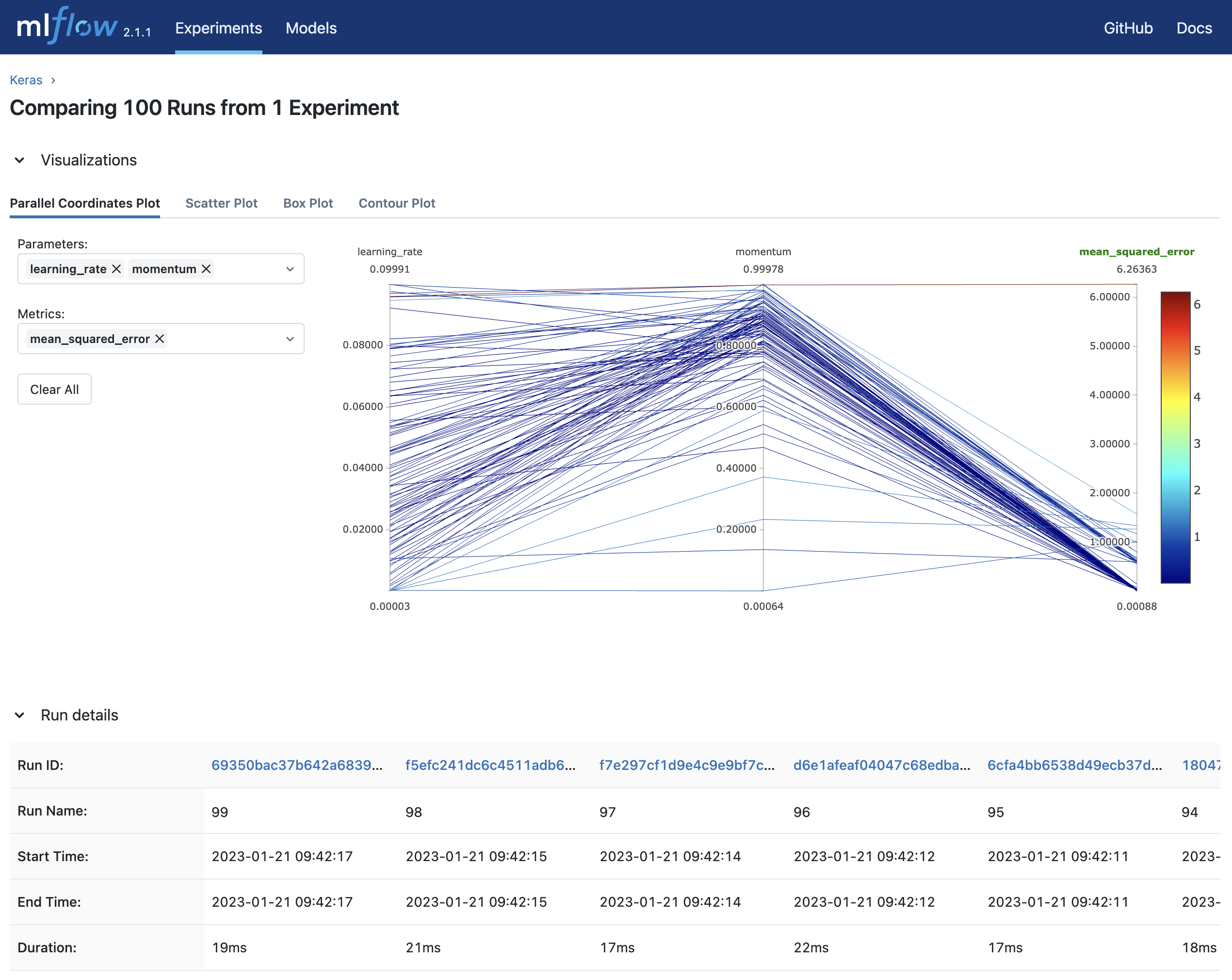
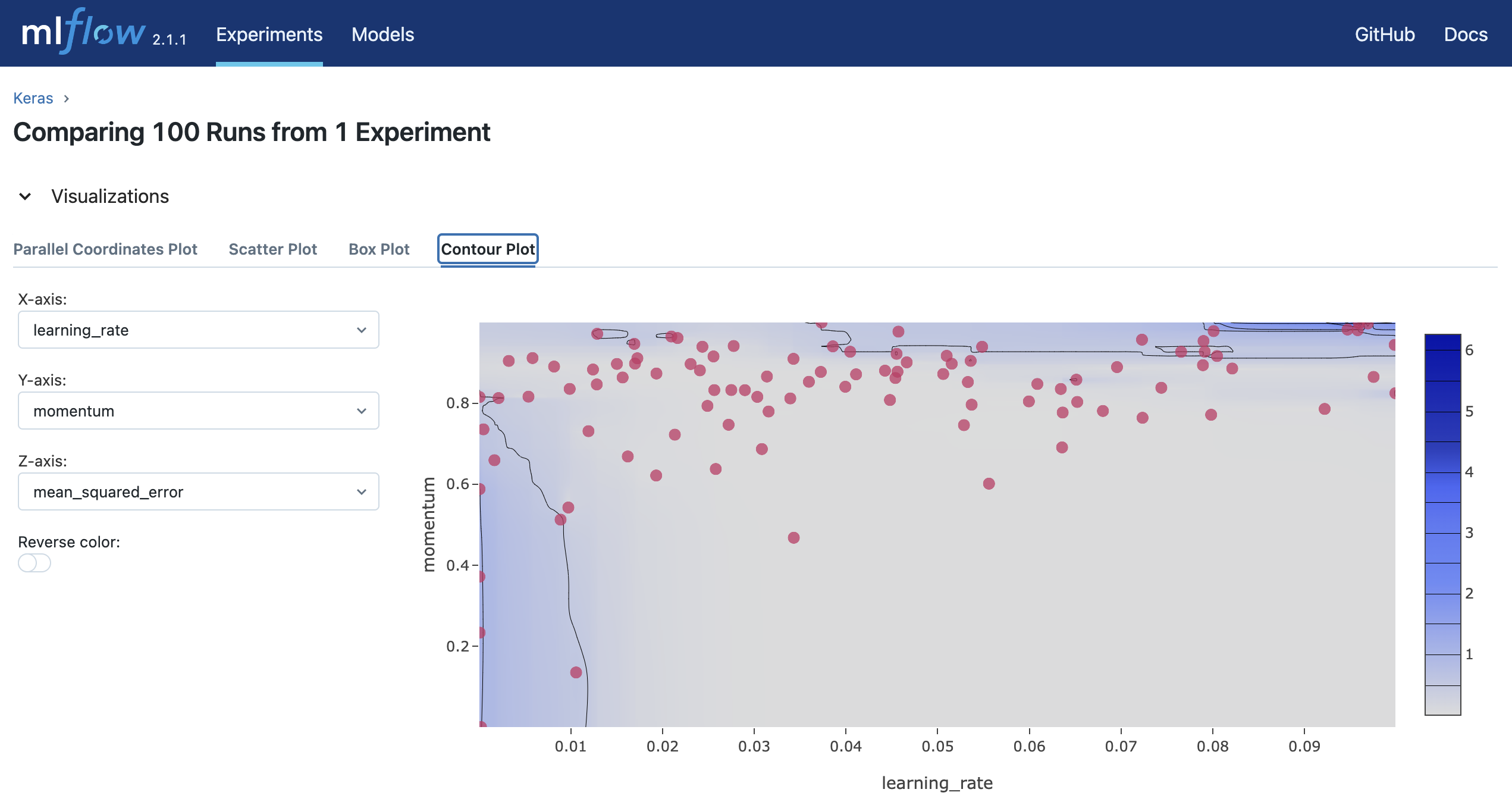
参考
AlloyDB

Amazon Cognito

Amazon EC2

Amazon ECS

Amazon QuickSight

Amazon RDS

Amazon Redshift

Amazon S3

API

Autonomous Vehicle

AWS

AWS API Gateway

AWS Chalice

AWS Control Tower

AWS IAM

AWS Lambda

AWS VPC

BERT

BigQuery

Causal Inference

ChatGPT

Chrome Extension

CircleCI

Classification

Cloud Functions

Cloud IAM

Cloud Run

Cloud Storage

Clustering

CSS

Data Engineering

Data Modeling

Database

dbt

Decision Tree

Deep Learning

Descriptive Statistics

Differential Equation

Dimensionality Reduction

Discrete Choice Model

Docker

Economics

FastAPI

Firebase

GIS

git

GitHub

GitHub Actions

Google

Google Cloud

Google Search Console

Hugging Face

Hypothesis Testing

Inferential Statistics

Interval Estimation

JavaScript

Jinja

Kedro

Kubernetes

LightGBM

Linux

LLM

Mac

Machine Learning

Macroeconomics

Marketing

Mathematical Model

Meltano

MLflow
MLOps
MySQL

NextJS

NLP

Nodejs

NoSQL

ONNX

OpenAI

Optimization Problem

Optuna
Pandas

Pinecone

PostGIS

PostgreSQL

Probability Distribution

Product

Project

Psychology

Python

PyTorch

QGIS

R

ReactJS

Regression

Rideshare

SEO

Singer

sklearn

Slack

Snowflake

Software Development

SQL

Statistical Model

Statistics

Streamlit

Tabular

Tailwind CSS

TensorFlow

Terraform

Transportation

TypeScript

Urban Planning

Vector Database

Vertex AI

VSCode

XGBoost

Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS