

Kedro のモジュール化パイプライン
Kedroでは、パイプラインをモジュール化することで、再利用可能なパイプラインを作成することができます。例えば、特徴量のみが異なる複数のパイプラインを実行したりすることができます。モジュール化されたパイプラインは、開発、テスト、保守が容易であり、移植性が高くなります。
モジュール化パイプラインによるプロジェクトの拡張
Kedroが提供している spaceflights Starter のパイプラインを拡張してみます。まずはspaceflightsプロジェクトの準備をします。
$ kedro new --starter=spaceflights
$ cd spaceflights
$ pip install -r src/requirements.txt
これから、データサイエンスパイプラインのモデリングのコンポーネントに次の異なるパラメータを持つ名前空間を追加していきます。
active_modelling_pipelinecandidate_modelling_pipeline
conf/base/parameters/data_science.ymlを次のように編集します。
conf/base/parameters/data_science.yml
- model_options:
- test_size: 0.2
- random_state: 3
- features:
- - engines
- - passenger_capacity
- - crew
- - d_check_complete
- - moon_clearance_complete
- - iata_approved
- - company_rating
- - review_scores_rating
+ active_modelling_pipeline:
+ model_options:
+ test_size: 0.2
+ random_state: 3
+ features:
+ - engines
+ - passenger_capacity
+ - crew
+ - d_check_complete
+ - moon_clearance_complete
+ - iata_approved
+ - company_rating
+ - review_scores_rating
+
+ candidate_modelling_pipeline:
+ model_options:
+ test_size: 0.2
+ random_state: 8
+ features:
+ - engines
+ - passenger_capacity
+ - crew
+ - review_scores_rating
conf/base/catalog.ymlを次のように編集します。
conf/base/catalog.yml
- regressor:
- type: pickle.PickleDataSet
- filepath: data/06_models/regressor.pickle
- versioned: true
+ active_modelling_pipeline.regressor:
+ type: pickle.PickleDataSet
+ filepath: data/06_models/regressor_active.pickle
+ versioned: true
+
+ candidate_modelling_pipeline.regressor:
+ type: pickle.PickleDataSet
+ filepath: data/06_models/regressor_candidate.pickle
+ versioned: true
pipelines/data_science/pipeline.pyを次のように編集します。
pipelines/data_science/pipeline.py
from kedro.pipeline import Pipeline, node
- from kedro.pipeline import pipeline
+ from kedro.pipeline.modular_pipeline import pipeline
from .nodes import evaluate_model, split_data, train_model
def create_pipeline(**kwargs) -> Pipeline:
- return pipeline(
- [
- node(
- func=split_data,
- inputs=["model_input_table", "params:model_options"],
- outputs=["X_train", "X_test", "y_train", "y_test"],
- name="split_data_node",
- ),
- node(
- func=train_model,
- inputs=["X_train", "y_train"],
- outputs="regressor",
- name="train_model_node",
- ),
- node(
- func=evaluate_model,
- inputs=["regressor", "X_test", "y_test"],
- outputs=None,
- name="evaluate_model_node",
- ),
- ]
- )
+ pipeline_instance = pipeline(
+ [
+ node(
+ func=split_data,
+ inputs=["model_input_table", "params:model_options"],
+ outputs=["X_train", "X_test", "y_train", "y_test"],
+ name="split_data_node",
+ ),
+ node(
+ func=train_model,
+ inputs=["X_train", "y_train"],
+ outputs="regressor",
+ name="train_model_node",
+ ),
+ node(
+ func=evaluate_model,
+ inputs=["regressor", "X_test", "y_test"],
+ outputs=None,
+ name="evaluate_model_node",
+ ),
+ ]
+ )
+ ds_pipeline_1 = pipeline(
+ pipe=pipeline_instance,
+ inputs="model_input_table",
+ namespace="active_modelling_pipeline",
+ )
+ ds_pipeline_2 = pipeline(
+ pipe=pipeline_instance,
+ inputs="model_input_table",
+ namespace="candidate_modelling_pipeline",
+ )
+
+ return ds_pipeline_1 + ds_pipeline_2
kedro runを実行すると、active_modelling_pipelineとcandidate_modelling_pipelineの両方のパイプラインが走っていることが分かります。
$ kedro run
[11/02/22 10:41:06] WARNING /Users/<username>/opt/anaconda3/envs/py38/lib/python3.8/site-packages/plotly/graph_objects/ warnings.py:109
__init__.py:288: DeprecationWarning: distutils Version classes are deprecated. Use
packaging.version instead.
if LooseVersion(ipywidgets.__version__) >= LooseVersion("7.0.0"):
[11/02/22 10:41:07] INFO Kedro project kedro-tutorial session.py:340
[11/02/22 10:41:08] INFO Loading data from 'companies' (CSVDataSet)... data_catalog.py:343
INFO Running node: preprocess_companies_node: preprocess_companies([companies]) -> node.py:327
[preprocessed_companies]
INFO Saving data to 'preprocessed_companies' (ParquetDataSet)... data_catalog.py:382
INFO Completed 1 out of 9 tasks sequential_runner.py:85
INFO Loading data from 'shuttles' (ExcelDataSet)... data_catalog.py:343
[11/02/22 10:41:13] INFO Running node: preprocess_shuttles_node: preprocess_shuttles([shuttles]) -> node.py:327
[preprocessed_shuttles]
WARNING /Users/<username>/Documents/kedro-projects/kedro-tutorial/src/kedro_tutorial/pipelines/data warnings.py:109
_processing/nodes.py:19: FutureWarning: The default value of regex will change from True to
False in a future version. In addition, single character regular expressions will *not* be
treated as literal strings when regex=True.
x = x.str.replace("$", "").str.replace(",", "")
INFO Saving data to 'preprocessed_shuttles' (ParquetDataSet)... data_catalog.py:382
INFO Completed 2 out of 9 tasks sequential_runner.py:85
INFO Loading data from 'preprocessed_shuttles' (ParquetDataSet)... data_catalog.py:343
INFO Loading data from 'preprocessed_companies' (ParquetDataSet)... data_catalog.py:343
INFO Loading data from 'reviews' (CSVDataSet)... data_catalog.py:343
INFO Running node: create_model_input_table_node: node.py:327
create_model_input_table([preprocessed_shuttles,preprocessed_companies,reviews]) ->
[model_input_table]
^[[B[11/02/22 10:41:14] INFO Saving data to 'model_input_table' (ParquetDataSet)... data_catalog.py:382
[11/02/22 10:41:15] INFO Completed 3 out of 9 tasks sequential_runner.py:85
INFO Loading data from 'model_input_table' (ParquetDataSet)... data_catalog.py:343
INFO Loading data from 'params:active_modelling_pipeline.model_options' (MemoryDataSet)... data_catalog.py:343
INFO Running node: split_data_node: node.py:327
split_data([model_input_table,params:active_modelling_pipeline.model_options]) ->
[active_modelling_pipeline.X_train,active_modelling_pipeline.X_test,active_modelling_pipeline.y_t
rain,active_modelling_pipeline.y_test]
INFO Saving data to 'active_modelling_pipeline.X_train' (MemoryDataSet)... data_catalog.py:382
INFO Saving data to 'active_modelling_pipeline.X_test' (MemoryDataSet)... data_catalog.py:382
INFO Saving data to 'active_modelling_pipeline.y_train' (MemoryDataSet)... data_catalog.py:382
INFO Saving data to 'active_modelling_pipeline.y_test' (MemoryDataSet)... data_catalog.py:382
INFO Completed 4 out of 9 tasks sequential_runner.py:85
INFO Loading data from 'model_input_table' (ParquetDataSet)... data_catalog.py:343
INFO Loading data from 'params:candidate_modelling_pipeline.model_options' (MemoryDataSet)... data_catalog.py:343
INFO Running node: split_data_node: node.py:327
split_data([model_input_table,params:candidate_modelling_pipeline.model_options]) ->
[candidate_modelling_pipeline.X_train,candidate_modelling_pipeline.X_test,candidate_modelling_pip
eline.y_train,candidate_modelling_pipeline.y_test]
INFO Saving data to 'candidate_modelling_pipeline.X_train' (MemoryDataSet)... data_catalog.py:382
INFO Saving data to 'candidate_modelling_pipeline.X_test' (MemoryDataSet)... data_catalog.py:382
INFO Saving data to 'candidate_modelling_pipeline.y_train' (MemoryDataSet)... data_catalog.py:382
INFO Saving data to 'candidate_modelling_pipeline.y_test' (MemoryDataSet)... data_catalog.py:382
INFO Completed 5 out of 9 tasks sequential_runner.py:85
INFO Loading data from 'active_modelling_pipeline.X_train' (MemoryDataSet)... data_catalog.py:343
INFO Loading data from 'active_modelling_pipeline.y_train' (MemoryDataSet)... data_catalog.py:343
INFO Running node: train_model_node: node.py:327
train_model([active_modelling_pipeline.X_train,active_modelling_pipeline.y_train]) ->
[active_modelling_pipeline.regressor]
INFO Saving data to 'active_modelling_pipeline.regressor' (PickleDataSet)... data_catalog.py:382
INFO Completed 6 out of 9 tasks sequential_runner.py:85
INFO Loading data from 'candidate_modelling_pipeline.X_train' (MemoryDataSet)... data_catalog.py:343
INFO Loading data from 'candidate_modelling_pipeline.y_train' (MemoryDataSet)... data_catalog.py:343
INFO Running node: train_model_node: node.py:327
train_model([candidate_modelling_pipeline.X_train,candidate_modelling_pipeline.y_train]) ->
[candidate_modelling_pipeline.regressor]
INFO Saving data to 'candidate_modelling_pipeline.regressor' (PickleDataSet)... data_catalog.py:382
INFO Completed 7 out of 9 tasks sequential_runner.py:85
INFO Loading data from 'active_modelling_pipeline.regressor' (PickleDataSet)... data_catalog.py:343
INFO Loading data from 'active_modelling_pipeline.X_test' (MemoryDataSet)... data_catalog.py:343
INFO Loading data from 'active_modelling_pipeline.y_test' (MemoryDataSet)... data_catalog.py:343
INFO Running node: evaluate_model_node: node.py:327
evaluate_model([active_modelling_pipeline.regressor,active_modelling_pipeline.X_test,active_model
ling_pipeline.y_test]) -> None
INFO Model has a coefficient R^2 of 0.462 on test data. nodes.py:60
INFO Completed 8 out of 9 tasks sequential_runner.py:85
INFO Loading data from 'candidate_modelling_pipeline.regressor' (PickleDataSet)... data_catalog.py:343
INFO Loading data from 'candidate_modelling_pipeline.X_test' (MemoryDataSet)... data_catalog.py:343
INFO Loading data from 'candidate_modelling_pipeline.y_test' (MemoryDataSet)... data_catalog.py:343
INFO Running node: evaluate_model_node: node.py:327
evaluate_model([candidate_modelling_pipeline.regressor,candidate_modelling_pipeline.X_test,candid
ate_modelling_pipeline.y_test]) -> None
INFO Model has a coefficient R^2 of 0.449 on test data. nodes.py:60
INFO Completed 9 out of 9 tasks sequential_runner.py:85
INFO Pipeline execution completed successfully.
pipeline() ラッパー
次のimportにより、動的な入出力やパラメータを持つパイプラインの複数のインスタンスを作成することができます。
from kedro.pipeline.modular_pipeline import pipeline
pipeline()の引数は次のとおりです。
| Keyword argument | Description |
|---|---|
pipe |
The Pipeline object you want to wrap |
inputs |
Any overrides provided to this instance of the underlying wrapped Pipeline object |
outputs |
Any overrides provided to this instance of the underlying wrapped Pipeline object |
parameters |
Any overrides provided to this instance of the underlying wrapped Pipeline object |
namespace |
The namespace that will be encapsulated by this pipeline instance |
パイプラインのリネージはkedro vizコマンドで確認することができます。
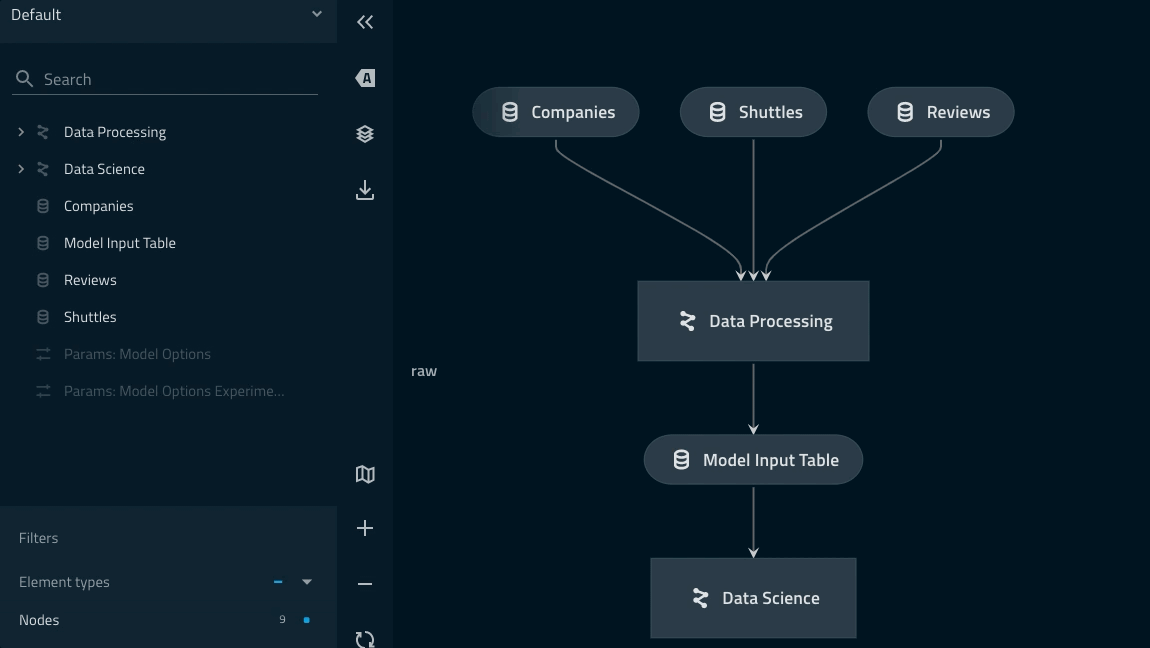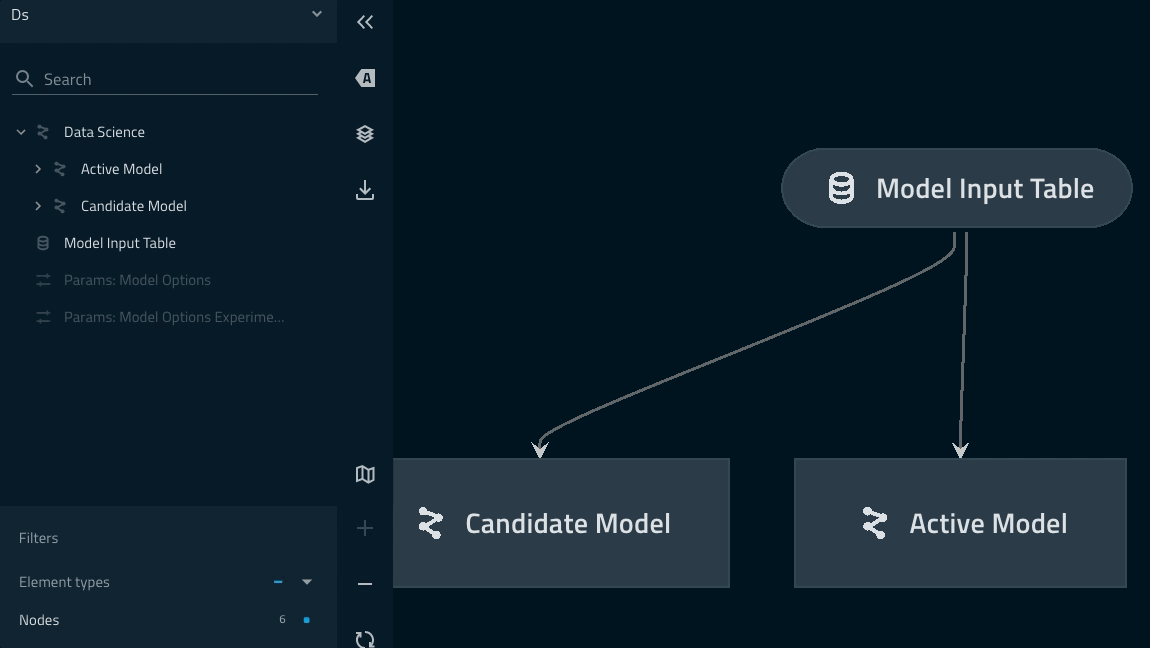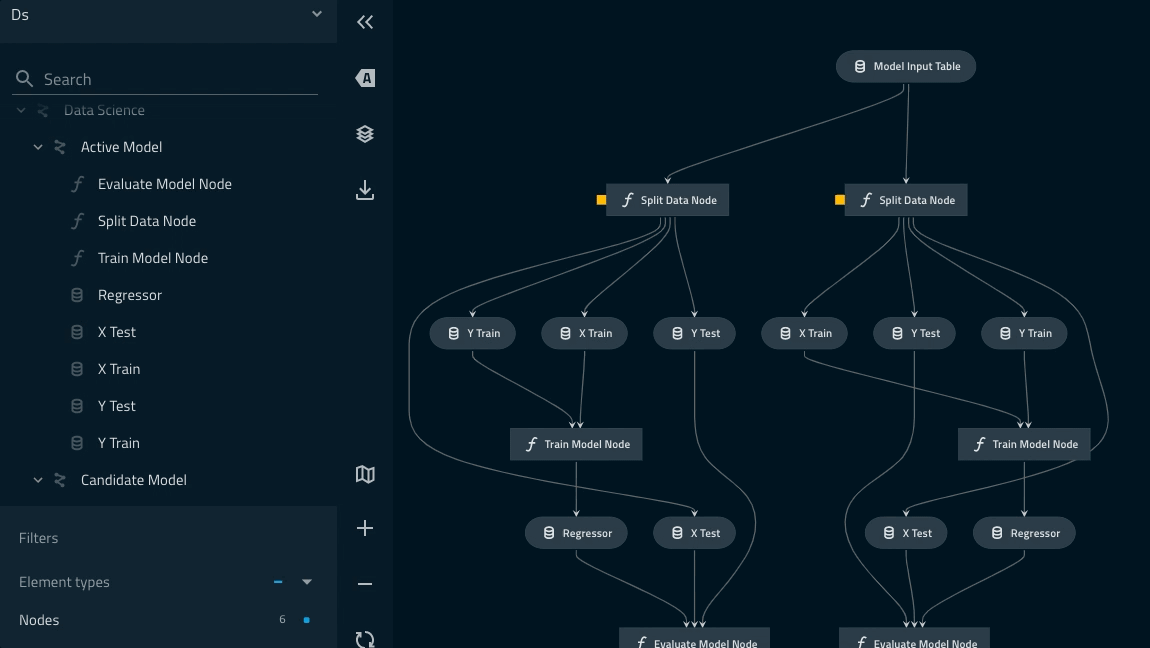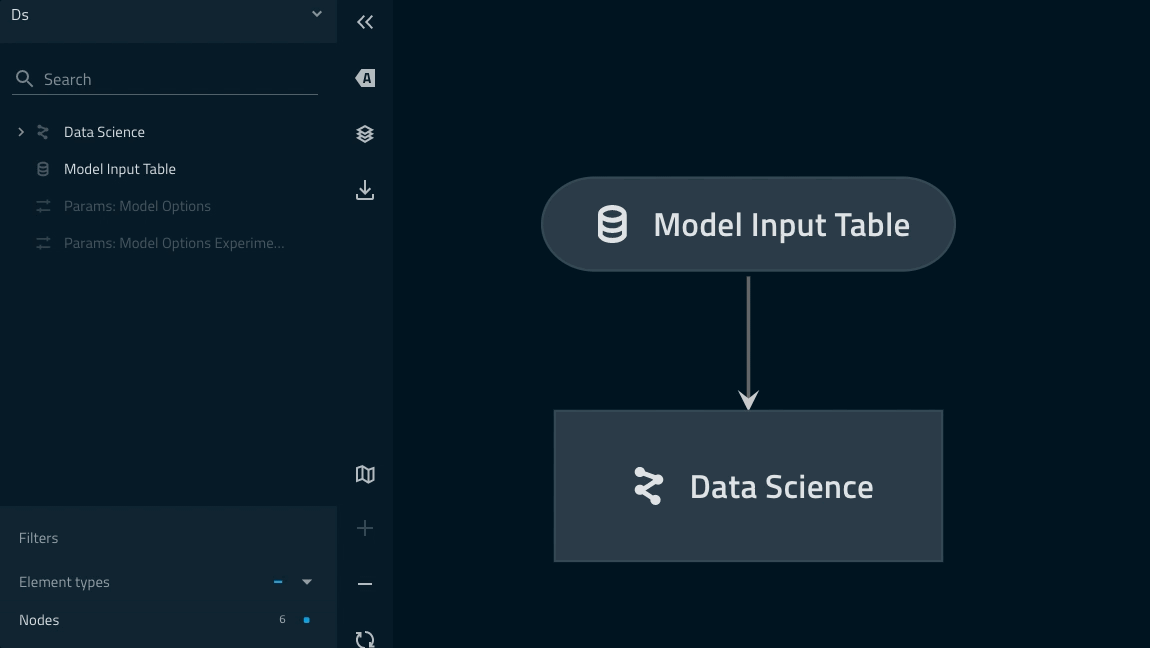
参考
AlloyDB

Amazon Cognito

Amazon EC2

Amazon ECS

Amazon QuickSight

Amazon RDS

Amazon Redshift

Amazon S3

API

Autonomous Vehicle

AWS

AWS API Gateway

AWS Chalice

AWS Control Tower

AWS IAM

AWS Lambda

AWS VPC

BERT

BigQuery

Causal Inference

ChatGPT

Chrome Extension

CircleCI

Classification

Cloud Functions

Cloud IAM

Cloud Run

Cloud Storage

Clustering

CSS

Data Engineering

Data Modeling

Database

dbt

Decision Tree

Deep Learning

Descriptive Statistics

Differential Equation

Dimensionality Reduction

Discrete Choice Model

Docker

Economics

FastAPI

Firebase

GIS

git

GitHub

GitHub Actions

Google

Google Cloud

Google Search Console

Hugging Face

Hypothesis Testing

Inferential Statistics

Interval Estimation

JavaScript

Jinja

Kedro
Kubernetes

LightGBM

Linux

LLM

Mac

Machine Learning

Macroeconomics

Marketing

Mathematical Model

Meltano

MLflow

MLOps
MySQL

NextJS

NLP

Nodejs

NoSQL

ONNX

OpenAI

Optimization Problem

Optuna

Pandas

Pinecone

PostGIS

PostgreSQL

Probability Distribution

Product

Project

Psychology

Python

PyTorch

QGIS

R

ReactJS

Regression

Rideshare

SEO

Singer

sklearn

Slack

Snowflake

Software Development

SQL

Statistical Model

Statistics

Streamlit

Tabular

Tailwind CSS

TensorFlow

Terraform

Transportation

TypeScript

Urban Planning

Vector Database

Vertex AI

VSCode

XGBoost

Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS