


Pendahuluan
Dalam artikel ini, saya akan membahas proses instalasi, alur kerja dasar, dan fitur-fitur canggih dari LightGBM.
Instalasi dan Konfigurasi
Sebelum menginstal LightGBM, pastikan sistem Anda memenuhi persyaratan berikut:
- Python 3.6 atau yang lebih baru
- NumPy dan SciPy
- scikit-learn (opsional, untuk fungsionalitas tambahan)
Anda dapat menginstal LightGBM melalui pip:
$ pip install lightgbm
Alur Kerja Dasar LightGBM
Kita akan menjelajahi alur kerja dasar menggunakan LightGBM untuk melatih model pada dataset publik. Kita akan menggunakan dataset Iris, yang tersedia melalui library scikit-learn:
from sklearn import datasets
iris = datasets.load_iris()
X, y = iris.data, iris.target
Menggunakan scikit-learn, kita dapat membagi data menjadi set pelatihan dan pengujian:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Membuat Dataset LightGBM
Kita perlu mengonversi data pelatihan menjadi objek Dataset LightGBM. Objek ini dirancang khusus untuk digunakan dengan LightGBM dan memungkinkan penanganan efisien dari dataset besar.
import lightgbm as lgb
train_data = lgb.Dataset(X_train, label=y_train)
Menetapkan Parameter Model
Sebelum melatih model, kita perlu menetapkan parameter model. Parameter-parameter ini mengontrol berbagai aspek model, seperti fungsi tujuan, jumlah kelas, tipe boosting, dan tingkat pembelajaran.
params = {
'objective': 'multiclass',
'num_class': 3,
'metric': 'multi_logloss',
'boosting_type': 'gbdt',
'learning_rate': 0.05,
}
Melatih Model
Kita sekarang dapat melatih model LightGBM menggunakan data pelatihan dan parameter yang ditentukan. Parameter num_boost_round mengontrol jumlah putaran boosting, yang mempengaruhi kompleksitas dan kinerja model.
model = lgb.train(params, train_data, num_boost_round=100)
Evaluasi Kinerja Model
Evaluasi kinerja model pada set pengujian:
from sklearn.metrics import accuracy_score
import numpy as np
y_pred = model.predict(X_test)
y_pred = [np.argmax(row) for row in y_pred]
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
Accuracy: 1.0
Melakukan Prediksi
Lakukan prediksi menggunakan model yang telah dilatih:
sample = X_test[0]
predicted_class = model.predict([sample])
print("Predicted class:", np.argmax(predicted_class))
Predicted class: 1
Menjelajahi API LightGBM
Dalam bab ini, saya akan menelusuri API LightGBM dan menjelajahi beberapa fungsionalitas kuncinya. Kita akan membahas LightGBM Classifier dan Regressor, penyetelan hiperparameter, cross-validation, penanganan data yang tidak seimbang, dan early stopping.
LightGBM Classifier
LightGBM Classifier adalah implementasi algoritma GBDT untuk tugas klasifikasi. Ini tersedia dalam API LightGBM sebagai LGBMClassifier. Untuk menggunakannya, impor kelas dan buat instance dengan parameter model yang diinginkan.
from lightgbm import LGBMClassifier
clf = LGBMClassifier(boosting_type='gbdt', num_leaves=31, learning_rate=0.05, n_estimators=100)
clf.fit(X_train, y_train)
LightGBM Regressor
Untuk tugas regresi, LightGBM menyediakan kelas LGBMRegressor. Sama seperti LGBMClassifier, Anda dapat membuat instance regressor dengan parameter model yang diinginkan.
from lightgbm import LGBMRegressor
reg = LGBMRegressor(boosting_type='gbdt', num_leaves=31, learning_rate=0.05, n_estimators=100)
reg.fit(X_train, y_train)
Cross-Validation
Cross validation adalah teknik yang digunakan untuk menilai kinerja model machine learning dengan lebih dapat diandalkan. LightGBM menyediakan fungsi cv, yang melakukan cross validation dengan k-fold menggunakan dataset dan parameter model yang diberikan.
from sklearn.model_selection import KFold
kf = KFold(n_splits=5, shuffle=True, random_state=42)
lgb_cv = lgb.cv(params, train_data, num_boost_round=100, folds=kf, early_stopping_rounds=10)
Penanganan Data yang Tidak Seimbang
LightGBM memiliki dukungan bawaan untuk menangani data yang tidak seimbang dengan menyesuaikan parameter class_weight. Anda dapat menetapkan bobot kelas menjadi 'balanced' untuk secara otomatis menyesuaikan bobot berdasarkan jumlah sampel untuk setiap kelas.
clf = LGBMClassifier(boosting_type='gbdt', class_weight='balanced')
clf.fit(X_train, y_train)
Early Stopping
Untuk menghindari overfitting dan mengurangi waktu pelatihan, Anda dapat menggunakan early stopping. Early stopping akan menghentikan proses pelatihan jika kinerja pada set validasi tidak meningkat selama sejumlah putaran boosting yang ditentukan.
model = lgb.train(params, train_data, num_boost_round=1000, valid_sets=[train_data], early_stopping_rounds=10)
Akselerasi GPU
LightGBM mendukung akselerasi GPU, yang dapat signifikan mempercepat proses pelatihan. Untuk mengaktifkan akselerasi GPU, Anda perlu menginstal versi GPU yang sesuai dari LightGBM dan menyetel parameter device menjadi 'gpu' pada parameter model Anda.
params = {
'device': 'gpu',
# Other parameters...
}
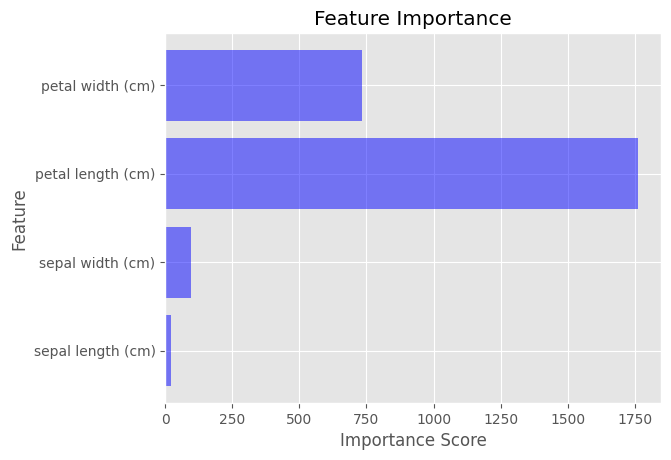
Feature Importance di LightGBM
Setelah melatih model LightGBM, Anda dapat menghitung feature importance menggunakan metode feature_importance(). Metode ini mengembalikan array skor penting untuk setiap fitur dalam dataset.
importance_scores = model.feature_importance(importance_type='gain')
Untuk memvisualisasikan feature importance, kita dapat menggunakan diagram batang yang menunjukkan skor penting untuk setiap fitur. Ini dapat dilakukan dengan mudah menggunakan Matplotlib.
import matplotlib.pyplot as plt
plt.style.use('ggplot')
feature_names = iris.feature_names
plt.barh(feature_names, importance_scores, color='blue', alpha=0.5)
plt.xlabel('Importance Score')
plt.ylabel('Feature')
plt.title('Feature Importance')
plt.show()
Distributed Learning
Distributed learning memungkinkan Anda untuk melatih model LightGBM pada beberapa mesin, yang dapat berguna ketika menangani dataset yang sangat besar. LightGBM mendukung berbagai pengaturan distributed learning, seperti MPI, socket, dan Hadoop. Untuk mengaktifkan distributed learning, Anda perlu menyetel parameter machines pada parameter model Anda dan menggunakan pengaturan distributed learning tertentu.
Untuk informasi lebih lanjut tentang mengatur distributed learning dengan LightGBM, lihat dokumentasi resmi:
















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS