



Apa itu Gradient Boosting Decision Trees (GBDT)
Gradient Boosting Decision Trees (GBDT) adalah metode ensemble learning yang kuat yang menggabungkan kekuatan dari decision trees dan teknik gradient boosting. Metode ini semakin populer belakangan ini karena kemampuannya untuk menghasilkan model dengan performa tinggi yang dapat menangani berbagai masalah kompleks di berbagai domain, termasuk keuangan, kesehatan, dan pemasaran.
GBDT bekerja dengan cara membangun serangkaian decision trees secara iteratif, di mana setiap tree mencoba untuk memperbaiki kesalahan yang dibuat oleh pendahulunya. Proses ini berlanjut sampai jumlah tree yang ditentukan telah dibuat atau tingkat performa yang telah ditentukan tercapai. Dengan menggabungkan prediksi dari beberapa tree, GBDT sering dapat mencapai akurasi dan generalisasi yang lebih baik dibandingkan dengan decision tree tunggal.
Algoritma GBDT
Di bagian ini, saya akan menjelajahi algoritma GBDT, fokus pada kasus regresi dan klasifikasi. Ide utama di balik GBDT adalah membangun urutan decision tree lemah, di mana setiap tree dilatih untuk memperbaiki kesalahan yang dibuat oleh pendahulunya. Dengan secara iteratif meningkatkan model, GBDT dapat mencapai akurasi dan generalisasi yang tinggi. Mari kita telusuri komponen utama dari algoritma GBDT.
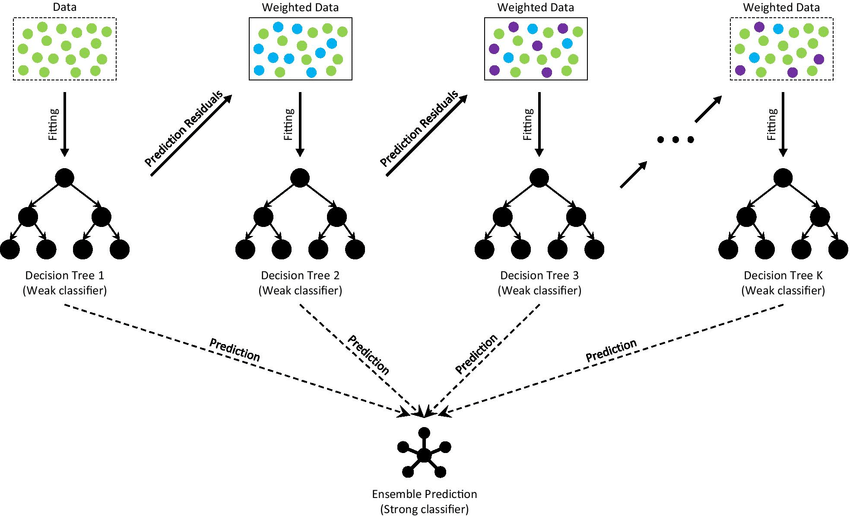
The architecture of Gradient Boosting Decision Tree
- Inisialisasi model dengan prediksi konstan
GBDT memulai dengan menginisialisasi model dengan nilai prediksi konstan. Untuk masalah regresi, konstan ini biasanya berupa mean dari nilai target, sedangkan untuk masalah klasifikasi, bisa berupa log-odds dari kelas mayoritas.
Untuk regresi, prediksi awal
Untuk klasifikasi biner, prediksi awal
di mana
- Membangun decision tree secara iteratif
GBDT membangun urutan decision tree dengan secara iteratif membangun tree baru ke pseudo-residual (gradien) dari fungsi loss. Pseudo-residual dihitung sebagai gradien negatif dari fungsi loss terhadap prediksi model saat ini. Ini membimbing algoritma ke arah penaksiran yang lebih baik dari fungsi target dengan meminimalkan loss.
Untuk regresi dengan fungsi loss kuadrat terkecil, pseudo-residual
Untuk klasifikasi biner dengan fungsi loss logistik, pseudo-residual
- Memperbarui model dengan prediksi tree berbobot
Setelah membangun decision tree baru
- Menghentikan proses
Algoritma terus membangun dan menambahkan decision tree sampai jumlah tree yang telah ditentukan tercapai atau peningkatan performa menjadi tidak signifikan.
GBDT vs. Random Forest
Kedua GBDT dan Random Forest adalah metode ensemble yang menggunakan decision tree sebagai pembelajaran dasar, tetapi ada beberapa perbedaan kunci antara keduanya:
-
Boosting vs Bagging
GBDT adalah algoritma boosting, di mana setiap tree dibangun secara berurutan untuk memperbaiki kesalahan pendahulunya. Sebaliknya, Random Forest adalah algoritma bagging, di mana tree dibangun secara independen menggunakan sampel bootstrapped dari dataset. -
Struktur tree
GBDT biasanya menggunakan tree dangkal, yang merupakan pembelajar lemah, sementara Random Forest menggunakan tree yang dalam dan sepenuhnya tumbuh. -
Kompleksitas model
Model GBDT dapat lebih kompleks dari Random Forest karena sifat iteratif boosting. Ini dapat mengarah pada performa yang lebih baik tetapi juga meningkatkan risiko overfitting. -
Kecepatan pelatihan
Melatih model GBDT dapat lebih lambat daripada melatih Random Forest, karena tree harus dibangun secara berurutan. Namun, model GBDT sering dapat mencapai performa yang sama atau lebih baik dengan lebih sedikit tree, yang dapat menutupi waktu pelatihan yang lebih lama. -
Interpretabilitas
Model GBDT dan Random Forest keduanya kurang dapat diinterpretasikan dibandingkan dengan decision tree tunggal, tetapi model GBDT dapat lebih sulit diinterpretasikan karena konstruksi tree secara berurutan dan penggunaan informasi gradien. -
Keberlanjutan pada data berisik
Random Forest umumnya lebih tahan terhadap data berisik, karena membangun beberapa tree independen dan mengambil rata-rata dari prediksi mereka. GBDT, di sisi lain, mungkin lebih sensitif terhadap noise, karena setiap tree dipengaruhi oleh kesalahan pendahulunya. -
Penyetelan hyperparameter
GBDT biasanya memerlukan penyetelan hyperparameter yang lebih banyak daripada Random Forest untuk mencapai performa yang optimal, karena melibatkan parameter tambahan seperti learning rate dan regularisasi.
GBDT dalam Python
Berikut adalah skrip Python untuk mengimplementasikan model GBDT. Dataset California Housing untuk regresi dan dataset Iris untuk klasifikasi digunakan sebagai contoh.
Regresi: Dataset California Housing
import numpy as np
import pandas as pd
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_squared_error
data = fetch_california_housing()
X, y = data.data, data.target
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create and train the GBDT model
gbdt_regressor = GradientBoostingRegressor(
n_estimators=100,
max_depth=3,
learning_rate=0.1,
random_state=42
)
gbdt_regressor.fit(X_train, y_train)
# Evaluate the model
y_pred = gbdt_regressor.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print(f'Mean Squared Error: {mse:.4f}')
Mean Squared Error: 0.2940
klasifikasi: Dataset Iris
from sklearn.datasets import load_iris
data = load_iris()
X, y = data.data, data.target
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import accuracy_score
# Create and train the GBDT model
gbdt_classifier = GradientBoostingClassifier(
n_estimators=100,
max_depth=3,
learning_rate=0.1,
random_state=42
)
gbdt_classifier.fit(X_train, y_train)
# Evaluate the model
y_pred = gbdt_classifier.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy:.4f}')
Accuracy: 1.0000
Referensi















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS