
Apa itu Validasi Silang
Validasi silang adalah teknik yang digunakan dalam pembelajaran mesin dan pemodelan statistik untuk mengevaluasi kinerja suatu model prediktif pada dataset independen. Proses ini melibatkan pembagian dataset menjadi dua subset: set pelatihan, yang digunakan untuk melatih model, dan set validasi, yang digunakan untuk menguji kinerja model.
Tujuan dari validasi silang adalah untuk menilai seberapa baik model mampu melakukan generalisasi pada data baru yang belum pernah dilihat sebelumnya. Dengan menggunakan set validasi yang terpisah dari set pelatihan, validasi silang membantu mencegah overfitting, yang terjadi ketika model terlalu kompleks dan berperforma baik pada data pelatihan tetapi buruk pada data baru yang belum pernah dilihat sebelumnya.
Mengapa Validasi Silang Penting
Validasi silang adalah teknik penting dalam pembelajaran mesin dan pemodelan statistik karena beberapa alasan:
-
Seleksi Model yang Akurat
Validasi silang membantu memilih model terbaik dari sekelompok model kandidat dengan memperkirakan seberapa baik setiap model akan berperforma pada data baru yang belum pernah dilihat. Hal ini penting karena model yang berperforma baik pada data pelatihan tetapi buruk pada data baru tidak berguna dalam praktik. -
Robustness dan Generalisasi
Validasi silang membantu memastikan bahwa model tersebut robust dan mampu melakukan generalisasi pada data baru dengan mencegah overfitting. Overfitting terjadi ketika model terlalu kompleks dan mencocokkan noise pada data pelatihan, menghasilkan performa yang buruk pada data baru. -
Identifikasi Overfitting
Validasi silang membantu mengidentifikasi kapan model mengalami overfitting dengan memperkirakan varians dan bias dari model. Informasi ini dapat digunakan untuk menyesuaikan kompleksitas model dan meningkatkan performanya. -
Menghindari Data Leakage
Validasi silang membantu menghindari data leakage, yang terjadi ketika informasi dari set validasi digunakan dalam proses pelatihan. Data leakage dapat menyebabkan overestimasi performa model dan hasil yang tidak akurat.
Berikut adalah contoh dunia nyata:
Anggaplah kita sedang membangun sebuah model machine learning untuk memprediksi apakah seorang pelanggan cenderung berhenti menggunakan layanan atau tidak berdasarkan riwayat pembelian, demografi, dan faktor lainnya. Kita memiliki dataset dengan 10.000 pelanggan, di mana 1.000 di antaranya sudah berhenti menggunakan layanan.
Jika kita hanya membagi dataset menjadi set pelatihan dan pengujian secara acak, kita mungkin akan berakhir dengan set pengujian yang hanya berisi sedikit pelanggan yang sudah berhenti, sehingga menghasilkan metrik kinerja yang tidak akurat. Misalnya, jika set pengujian kita hanya berisi 5% pelanggan yang sudah berhenti, model yang hanya memprediksi bahwa tidak ada yang akan berhenti masih akan memiliki akurasi 95%, meskipun tidak berguna dalam praktiknya.
Dengan menggunakan validasi silang, kita dapat memastikan bahwa rasio pelanggan yang sudah berhenti konsisten di semua lipatan, dan bahwa metrik kinerja lebih akurat dan dapat diandalkan. Misalnya, kita dapat menggunakan validasi silang lipat k berstrata dengan 5 lipatan, memastikan bahwa setiap lipatan berisi proporsi pelanggan yang sudah berhenti yang sama.
Selain itu, dengan menggunakan validasi silang, kita dapat mengidentifikasi masalah potensial dengan overfitting atau underfitting, dan menyesuaikan model sesuai kebutuhan. Misalnya, jika kita menemukan bahwa model berperforma baik pada set pelatihan tetapi buruk pada set pengujian, kita mungkin perlu mengurangi kompleksitas model atau menambahkan regulasi untuk mencegah overfitting.
Jenis-Jenis Validasi Silang
Ada beberapa teknik validasi silang yang umum digunakan dalam machine learning dan statistical modeling.
Metode Holdout
Metode holdout adalah jenis validasi silang yang melibatkan pembagian dataset menjadi dua subset, satu untuk melatih model dan yang lainnya untuk menguji model. Metode holdout sederhana dan mudah dilaksanakan, tetapi mungkin tidak seandal seperti teknik validasi silang lainnya seperti validasi silang lipat k.
Berikut adalah contoh kode Python untuk menerapkan metode holdout menggunakan library scikit-learn:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# Load the iris dataset
iris = load_iris()
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3)
# Train a k-nearest neighbors classifier on the training set
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
# Evaluate the performance of the classifier on the testing set
score = knn.score(X_test, y_test)
print('Accuracy:', score)
Pada contoh ini, kita menggunakan fungsi load_iris() dari scikit-learn untuk memuat dataset iris. Selanjutnya, kita membagi dataset menjadi set pelatihan dan pengujian menggunakan fungsi train_test_split(), dengan ukuran pengujian sebesar 0,3 (30% dari data digunakan untuk pengujian).
Selanjutnya, kita melatih pengklasifikasi k-Nearest Neighbors pada set pelatihan menggunakan fungsi KNeighborsClassifier() dari scikit-learn. Akhirnya, kita mengevaluasi performa pengklasifikasi pada set pengujian menggunakan metode score(), yang mengembalikan akurasi pengklasifikasi pada set pengujian.
Leave-One-Out Cross Validation
Leave-One-Out Cross Validation (LOOCV) adalah jenis cross validation di mana jumlah lipatan sama dengan jumlah sampel dalam dataset. Pada LOOCV, model dilatih pada semua sampel kecuali satu, yang digunakan untuk pengujian. Proses ini diulang untuk setiap sampel dalam dataset, dan metrik performa dirata-ratakan untuk mengevaluasi performa model.
Berikut adalah contoh kode Python untuk mengimplementasikan LOOCV menggunakan library scikit-learn:
from sklearn.datasets import load_iris
from sklearn.model_selection import LeaveOneOut
from sklearn.neighbors import KNeighborsClassifier
# Load the iris dataset
iris = load_iris()
# Initialize the LOOCV iterator
loo = LeaveOneOut()
# Train and test the model on each sample
scores = []
for train_idx, test_idx in loo.split(iris.data):
# Get the training and testing data for this sample
X_train, y_train = iris.data[train_idx], iris.target[train_idx]
X_test, y_test = iris.data[test_idx], iris.target[test_idx]
# Train a k-nearest neighbors classifier on the training set
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
# Evaluate the performance of the classifier on the testing set
score = knn.score(X_test, y_test)
scores.append(score)
# Calculate the average performance metric over all samples
accuracy = sum(scores) / len(scores)
print('Accuracy:', accuracy)
Pada contoh ini, kita memuat dataset iris menggunakan fungsi load_iris() dari scikit-learn. Selanjutnya, kita menginisialisasi pengulang LOOCV dengan menggunakan fungsi LeaveOneOut().
Kemudian, kita melakukan perulangan melalui setiap sampel dalam dataset dan melatih serta menguji model pada data latih dan uji yang sesuai. Kita menggunakan metode split() dari pengulang LOOCV untuk mendapatkan indeks data latih dan uji untuk setiap sampel.
Selanjutnya, kita melatih klasifikasi k-Nearest Neighbors pada set data latih dan mengevaluasi kinerjanya pada set data uji menggunakan metode score(). Kita menambahkan metrik kinerja ke dalam daftar skor.
Terakhir, kita menghitung metrik kinerja rata-rata dari seluruh sampel dengan menjumlahkan skor dan membaginya dengan jumlah sampel dalam dataset.
K-fold Cross Validation
K-fold cross validation adalah teknik cross validation yang banyak digunakan dalam pembelajaran mesin. Pada k-fold cross validation, dataset dibagi menjadi K lipatan yang sama besar, dan model dilatih dan diuji K kali, masing-masing kali menggunakan lipatan yang berbeda untuk pengujian dan K-1 lipatan yang lain untuk pelatihan. Ini membantu untuk memastikan bahwa model dilatih dan diuji pada seluruh bagian dataset, dan bahwa metrik kinerja lebih akurat dan dapat diandalkan.
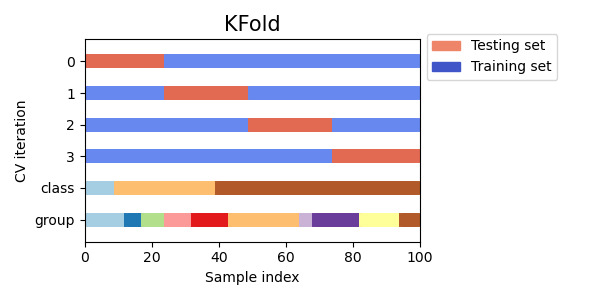
Visualizing cross-validation behavior in scikit-learn
from sklearn.datasets import load_iris
from sklearn.model_selection import KFold
from sklearn.neighbors import KNeighborsClassifier
# Load the iris dataset
iris = load_iris()
# Define the number of folds for K-fold cross validation
num_folds = 5
# Initialize the K-fold cross validation iterator
kf = KFold(n_splits=num_folds, shuffle=True)
# Train and test the model on each fold
for fold, (train_idx, test_idx) in enumerate(kf.split(iris.data)):
# Get the training and testing data for this fold
X_train, y_train = iris.data[train_idx], iris.target[train_idx]
X_test, y_test = iris.data[test_idx], iris.target[test_idx]
# Train a k-nearest neighbors classifier on the training set
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
# Evaluate the performance of the classifier on the testing set
score = knn.score(X_test, y_test)
print('Fold:', fold, 'Accuracy:', score)
Group K-fold Cross Validation
Group K-fold cross validation adalah variasi dari K-fold cross validation yang memastikan bahwa sampel data dari grup yang sama tidak hadir baik di set pelatihan maupun di set pengujian. Ini dapat berguna ketika data dibagi menjadi grup yang saling terkait, seperti saat bekerja dengan data medis dari pasien yang berbeda atau data keuangan dari perusahaan yang berbeda.
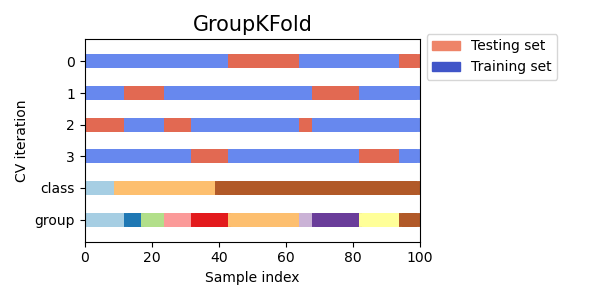
Visualizing cross-validation behavior in scikit-learn
from sklearn.model_selection import GroupKFold
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
# Generate example data with 3 groups
X, y = make_classification(n_samples=100, n_features=10, n_informative=5, n_redundant=0, n_classes=2, random_state=42)
groups = [0, 0, 0, 1, 1, 1, 2, 2, 2, 2]
# Create Group K-fold object with 3 folds
gkf = GroupKFold(n_splits=3)
# Iterate over splits and train/test the model
for train_index, test_index in gkf.split(X, y, groups=groups):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# Fit model on training data
model = LogisticRegression().fit(X_train, y_train)
# Evaluate model on testing data
score = model.score(X_test, y_test)
print("Accuracy score: ", score)
Shuffle Split Cross Validation
Shuffle Split Cross Validation adalah metode yang secara acak membagi data menjadi set pelatihan dan pengujian beberapa kali, memungkinkan pengontrolan yang lebih baik terhadap ukuran set pelatihan dan pengujian dibandingkan dengan metode cross validation lainnya.
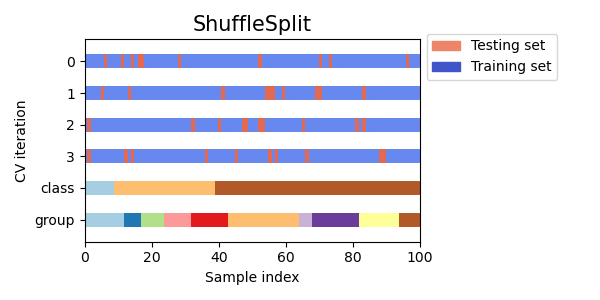
Visualizing cross-validation behavior in scikit-learn
from sklearn.model_selection import ShuffleSplit
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
# Generate example data
X, y = make_classification(n_samples=100, n_features=10, n_informative=5, n_redundant=0, n_classes=2, random_state=42)
# Create Shuffle Split object with 5 splits and a 0.5 test size
ss = ShuffleSplit(n_splits=5, test_size=0.5)
# Iterate over splits and train/test the model
for train_index, test_index in ss.split(X, y):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# Fit model on training data
model = LogisticRegression().fit(X_train, y_train)
# Evaluate model on testing data
score = model.score(X_test, y_test)
print("Accuracy score: ", score)
Stratified K-fold Cross Validation
Stratified k-fold cross validation adalah metode yang membagi data menjadi k fold, tetapi memastikan bahwa setiap fold memiliki proporsi sampel yang hampir sama dari setiap kelas seperti seluruh dataset. Hal ini sangat berguna ketika menangani dataset yang tidak seimbang, di mana satu kelas mungkin lebih banyak muncul daripada yang lain.
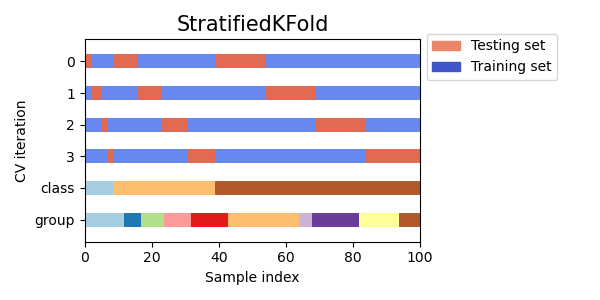
Visualizing cross-validation behavior in scikit-learn
from sklearn.model_selection import StratifiedKFold
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
# Generate example data
X, y = make_classification(n_samples=100, n_features=10, n_informative=5, n_redundant=0, n_classes=2, random_state=42)
# Create Stratified K-fold object with 5 splits
skf = StratifiedKFold(n_splits=5)
# Iterate over splits and train/test the model
for train_index, test_index in skf.split(X, y):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# Fit model on training data
model = LogisticRegression().fit(X_train, y_train)
# Evaluate model on testing data
score = model.score(X_test, y_test)
print("Accuracy score: ", score)
Stratified Group K-fold Cross Validation
Stratified group k-fold cross validation adalah variasi dari k-fold cross validation yang mempertimbangkan kelompok selain label kelas. Ini mempartisi data menjadi k fold, memastikan bahwa setiap lipatan memiliki proporsi sampel yang sama dari setiap kelas serta proporsi sampel yang sama dari setiap kelompok.
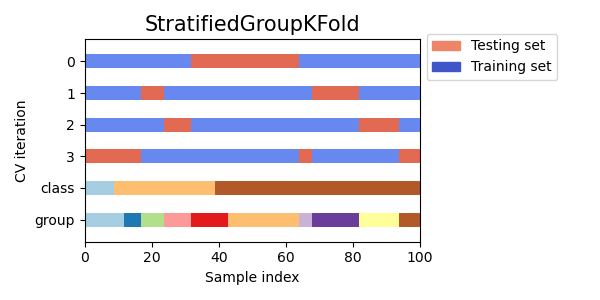
Visualizing cross-validation behavior in scikit-learn
from sklearn.model_selection import GroupKFold, StratifiedKFold
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
# Generate example data with group labels
X, y = make_classification(n_samples=100, n_features=10, n_informative=5, n_redundant=0, n_classes=2, random_state=42)
groups = [i % 5 for i in range(len(X))] # Assign groups based on remainder of index
# Create Stratified Group K-fold object with 5 splits
skf = StratifiedKFold(n_splits=5)
sgkf = [(train_index, test_index) for train_index, test_index in skf.split(X, y)]
# Use Group K-fold to ensure each fold has the same groups as in the entire dataset
sgkf = [(train_index, test_index) for train_index, test_index in GroupKFold(n_splits=5).split(X, y, groups=groups)]
# Iterate over splits and train/test the model
for train_index, test_index in sgkf:
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# Fit model on training data
model = LogisticRegression().fit(X_train, y_train)
# Evaluate model on testing data
score = model.score(X_test, y_test)
print("Accuracy score: ", score)
Group Shuffle Split Cross Validation
Group shuffle split cross validation adalah variasi dari cross validation yang mempertimbangkan kelompok selain label kelas dan mengacak data secara acak sebelum membaginya menjadi set latihan dan pengujian. Ini dapat berguna ketika menangani dataset yang tidak seimbang atau ketika urutan titik data penting, seperti dalam data deret waktu.
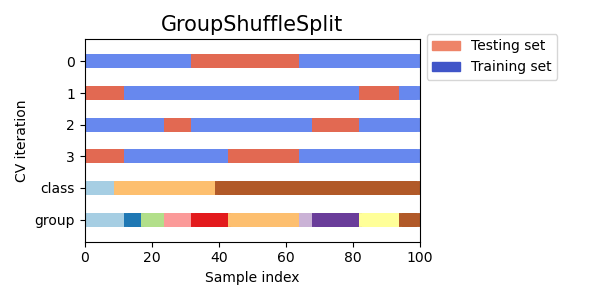
Visualizing cross-validation behavior in scikit-learn
from sklearn.model_selection import GroupShuffleSplit
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
# Generate example data with group labels
X, y = make_classification(n_samples=100, n_features=10, n_informative=5, n_redundant=0, n_classes=2, random_state=42)
groups = [i % 5 for i in range(len(X))] # Assign groups based on remainder of index
# Create Group Shuffle Split object with 80/20 split
gss = GroupShuffleSplit(n_splits=5, test_size=0.2)
# Iterate over splits and train/test the model
for train_index, test_index in gss.split(X, y, groups=groups):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# Fit model on training data
model = LogisticRegression().fit(X_train, y_train)
# Evaluate model on testing data
score = model.score(X_test, y_test)
print("Accuracy score: ", score)
Stratified Shuffle Split Cross Validation
Stratified shuffle split cross validation adalah variasi cross validation yang menggabungkan stratifikasi dan pengacakan. Stratifikasi memastikan bahwa proporsi kelas tetap terjaga pada setiap split, sedangkan pengacakan mengacak urutan sampel. Teknik ini dapat berguna untuk dataset yang tidak seimbang atau ketika urutan titik data penting.
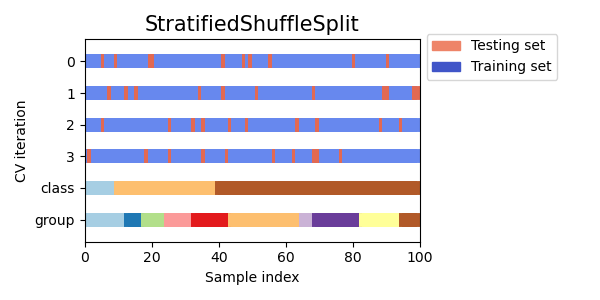
Visualizing cross-validation behavior in scikit-learn
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
# Generate example data with two classes
X, y = make_classification(n_samples=100, n_features=10, n_informative=5, n_redundant=0, n_classes=2, random_state=42)
# Create Stratified Shuffle Split object with 80/20 split
sss = StratifiedShuffleSplit(n_splits=5, test_size=0.2, random_state=42)
# Iterate over splits and train/test the model
for train_index, test_index in sss.split(X, y):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# Fit model on training data
model = LogisticRegression().fit(X_train, y_train)
# Evaluate model on testing data
score = model.score(X_test, y_test)
print("Accuracy score: ", score)
Time Series Cross Validation
Time Series Cross Validation (Validasi Silang Deret Waktu) adalah jenis validasi silang yang digunakan untuk data deret waktu, di mana tujuannya adalah untuk memprediksi nilai-nilai di masa depan berdasarkan pengamatan masa lalu. Dalam metode ini, set pelatihan terdiri dari pengamatan masa lalu dan set pengujian terdiri dari pengamatan di masa depan.
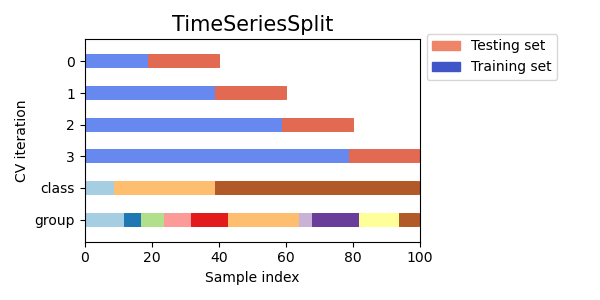
Visualizing cross-validation behavior in scikit-learn
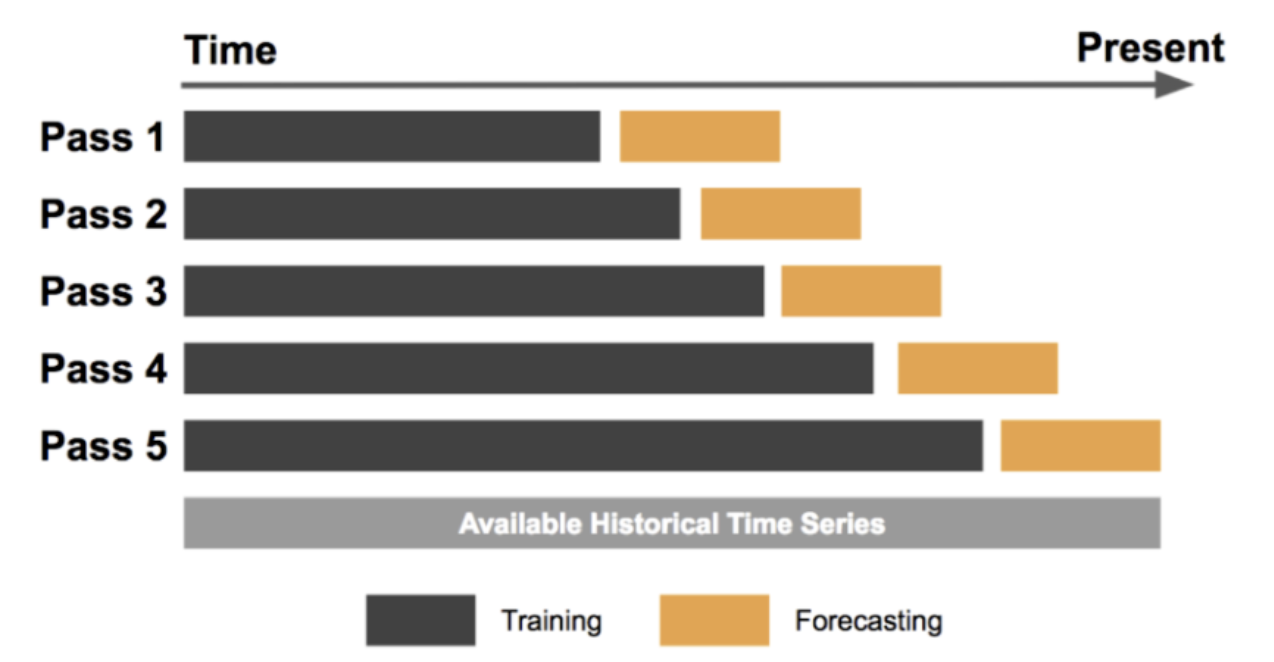
Forecasting at Uber: An Introduction
import pandas as pd
from sklearn.model_selection import TimeSeriesSplit
from sklearn.linear_model import LinearRegression
# Load the dataset
data = pd.read_csv('time_series_data.csv')
# Set the target variable
target_variable = 'sales'
# Set the number of splits
n_splits = 5
# Initialize the TimeSeriesSplit iterator
tscv = TimeSeriesSplit(n_splits=n_splits)
# Train and test the model on each split
scores = []
for train_index, test_index in tscv.split(data):
# Get the training and testing data for this split
train_data = data.iloc[train_index]
test_data = data.iloc[test_index]
# Separate the target variable from the features
X_train = train_data.drop(columns=[target_variable])
y_train = train_data[target_variable]
X_test = test_data.drop(columns=[target_variable])
y_test = test_data[target_variable]
# Train a linear regression model on the training set
model = LinearRegression()
model.fit(X_train, y_train)
# Evaluate the performance of the model on the testing set
score = model.score(X_test, y_test)
scores.append(score)
# Calculate the average performance metric over all splits
accuracy = sum(scores) / len(scores)
print('Accuracy:', accuracy)
Dalam contoh ini, kita memuat data time series dari file CSV menggunakan fungsi read_csv() dari Pandas. Kita kemudian mengatur variabel target, yang dalam hal ini adalah 'sales'. Kita juga menetapkan jumlah split menjadi 5.
Selanjutnya, kita menginisialisasi iterator TimeSeriesSplit menggunakan fungsi TimeSeriesSplit() dari scikit-learn. Kita mengulang setiap split di iterator dan melatih serta menguji model pada data pelatihan dan pengujian yang sesuai.
Untuk setiap split, kita memisahkan variabel target dari fitur dan melatih model regresi linear pada set pelatihan. Kita mengevaluasi kinerja model pada set pengujian menggunakan metode score(), yang menghitung koefisien determinasi (
Terakhir, kita menghitung rata-rata metrik kinerja dari semua split dengan menjumlahkan skor dan membaginya dengan jumlah split. Ini memberi kita perkiraan kinerja model pada data masa depan. Time Series Cross Validation sangat berguna untuk mengevaluasi kinerja model pada data time series, di mana tujuannya adalah untuk membuat prediksi akurat nilai-nilai masa depan berdasarkan pengamatan masa lalu.
Sliding Window Cross Validation
Sliding window cross validation adalah jenis time series cross validation di mana set pengujian terdiri dari jendela ukuran tetap yang meluncur di atas seluruh data time series. Pendekatan ini dapat berguna untuk mengevaluasi kinerja model time series pada data yang berkembang dari waktu ke waktu.
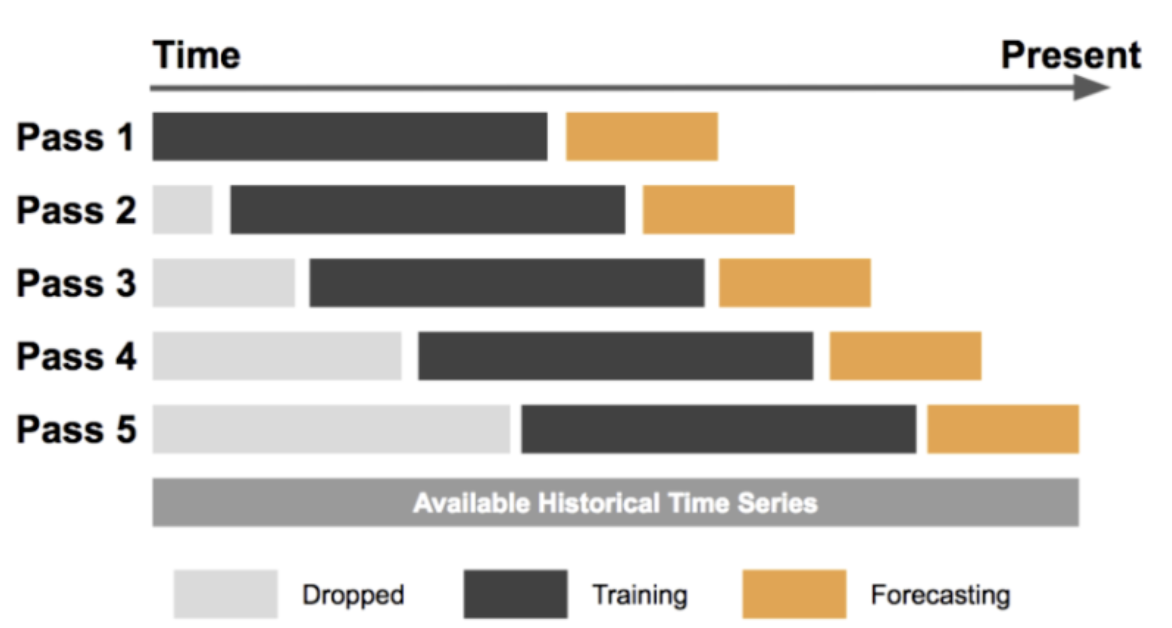
Forecasting at Uber: An Introduction
import numpy as np
from sklearn.model_selection import TimeSeriesSplit
from sklearn.linear_model import LinearRegression
# Generate example time series data
data = np.random.rand(100)
# Specify window size
window_size = 10
# Create sliding window iterator
tscv = TimeSeriesSplit(n_splits=len(data)-window_size+1)
# Iterate over sliding windows and train/test the model
for train_index, test_index in tscv.split(data):
X_train, X_test = data[train_index], data[test_index]
y_train, y_test = data[train_index+window_size], data[test_index+window_size]
# Fit model on training data
model = LinearRegression().fit(X_train.reshape(-1, 1), y_train.reshape(-1, 1))
# Evaluate model on testing data
score = model.score(X_test.reshape(-1, 1), y_test.reshape(-1, 1))
print("R-squared score: ", score)
Pada contoh ini, kita membuat data time series acak dengan panjang 100, dan mengatur ukuran jendela menjadi 10. Kemudian kita membuat objek TimeSeriesSplit dengan jumlah split yang sama dengan jumlah jendela yang mungkin. Kita kemudian mengulang setiap jendela geser menggunakan metode split, dan membagi data menjadi set pelatihan dan pengujian. Kita kemudian melatih model regresi linear pada data pelatihan, dan mengevaluasi kinerjanya pada data pengujian menggunakan skor R-squared. Akhirnya, kita mencetak skor untuk setiap jendela geser.
Sliding window cross validation dapat menjadi teknik yang berguna untuk mengevaluasi kinerja model time series pada data yang berkembang seiring waktu. Dengan menggeser jendela berukuran tetap di seluruh data time series, kita dapat melatih dan menguji model pada periode waktu yang berbeda dan memperoleh estimasi kinerja yang andal.
Jenis Cross Validation Mana yang Harus Dipilih
Memilih jenis cross validation terbaik untuk masalah tertentu tergantung pada beberapa faktor, seperti ukuran dan kompleksitas dataset, jenis model yang dilatih, dan tujuan spesifik dari analisis tersebut. Berikut beberapa contoh bagaimana memilih jenis cross validation terbaik untuk skenario dunia nyata yang berbeda:
-
Dataset kecil dengan sampel terbatas
Pada skenario ini, leave-one-out cross validation mungkin menjadi pilihan terbaik, karena memaksimalkan penggunaan data yang tersedia dan memberikan estimasi kinerja model yang andal. Ini bisa berguna untuk studi medis dengan ukuran sampel terbatas, di mana setiap titik data sangat berharga. -
Dataset besar dengan model kompleks
Pada skenario ini, k-fold cross validation mungkin menjadi pilihan yang baik, karena seimbang antara efisiensi komputasi dan akurasi. Misalnya, pada tugas pemrosesan bahasa alami di mana model memiliki banyak fitur, k-fold cross validation dapat membantu mengevaluasi kinerja model pada subset data yang berbeda. -
Data time series
Time series cross validation adalah pilihan terbaik untuk data yang bergantung pada waktu, karena memperhitungkan struktur temporal data. Misalnya, dalam keuangan, ketika memprediksi harga saham, penting untuk menggunakan time series cross validation untuk memastikan bahwa model dinilai pada data yang independen secara temporal dari data pelatihan. -
Dataset yang tidak seimbang
Pada tugas klasifikasi dengan data yang tidak seimbang, stratified cross validation mungkin menjadi pilihan terbaik, karena memastikan bahwa setiap lipatan berisi sampel representatif dari kedua kelas positif dan negatif. Misalnya, dalam diagnosis medis, suatu penyakit mungkin jarang terjadi, namun penting untuk mengidentifikasi kasus positif dengan benar, sehingga stratified cross validation penting untuk memastikan bahwa model tidak condong ke kelas mayoritas.
Secara kesimpulan, memilih jenis validasi silang terbaik tergantung pada karakteristik khusus dari dataset dan tujuan analisis. Dengan mempertimbangkan ukuran, kompleksitas, dan sifat data, serta memilih jenis validasi silang yang sesuai, kita dapat memperoleh estimasi kinerja model yang dapat diandalkan dan menghindari kesalahan umum.
Referencsi


















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS