



Hugging Face Transformers Model
Perpustakaan Hugging Face Transformers menyediakan banyak model yang sudah dilatih sebelumnya, yang bisa dengan mudah digunakan dan diterapkan pada tugas-tugas baru. Pada saat yang sama, Anda dapat mendaftarkan model pra-latihan Anda sendiri di Model Hub dan membaginya dengan pengguna lain.
Artikel ini menjelaskan tentang Model.
Model turunan dari Transformer
Arsitektur Transformer ditunjukkan pada gambar di bawah ini.
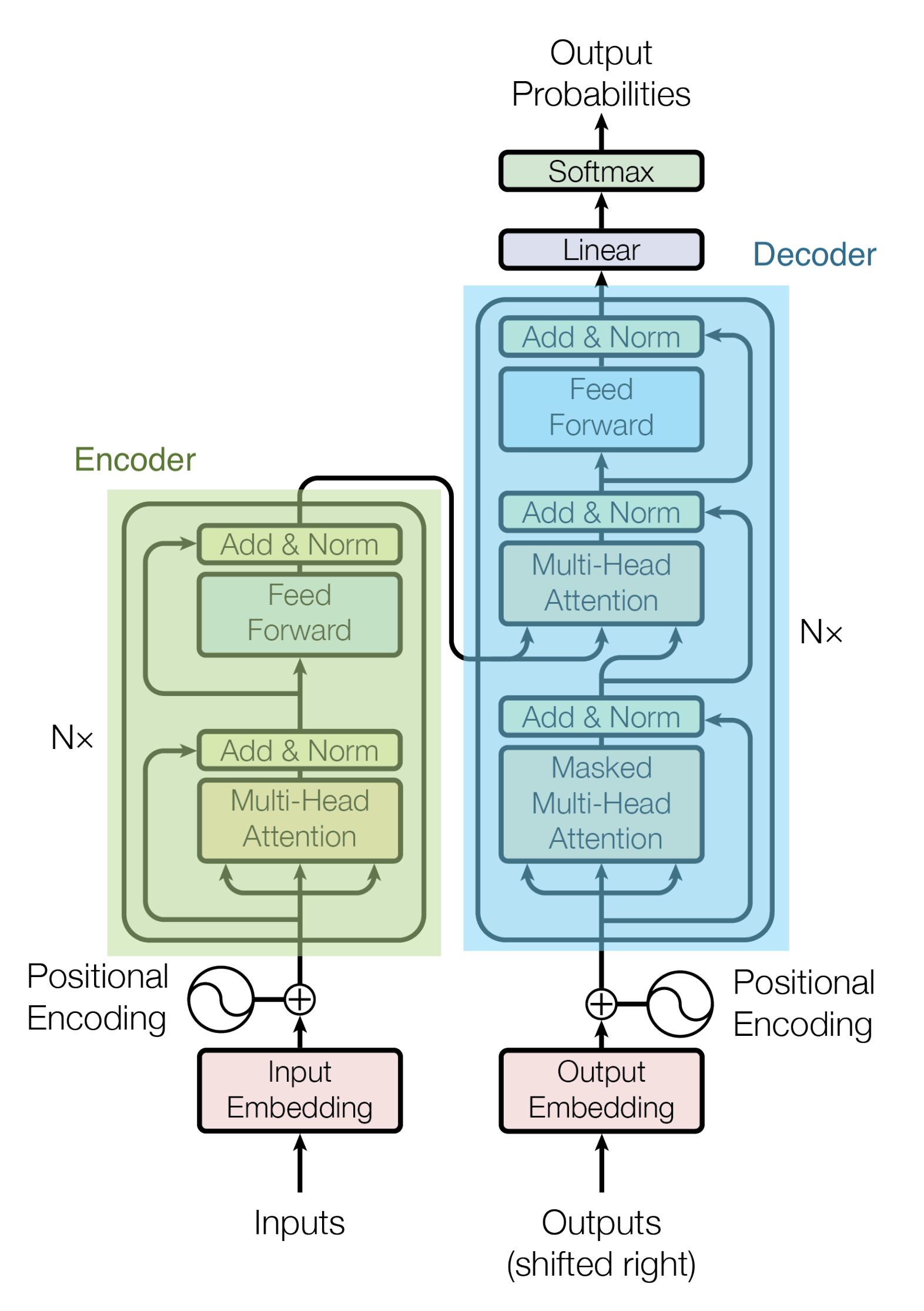
Sebagai model turunan dari Transformer, model berikut ini menggunakan Encoder dan Decoder secara terpisah.
- Encoder model
- BERT
- ALBERT
- RoBERTa
- DistilBERT
- XLM
- XLM-RoBERTa
- ELECTRA
- Decoder model
- GPT
- GPT-2
- CTRL
- Reformer
- XLNet
- Encoder-Decoder model
- BART
- T5
- MBart
Encoder model
Model Encoder hanya menggunakan bagian Encoder dari Transformer. Lapisan Attention adalah Attenton dua arah yang dapat memperhatikan semua kata dalam data seri input dan juga dapat memperhatikan kata sebelum dan sesudah setiap kata.
Karena model Encoder menghasilkan representasi fitur dari data input, model ini cocok untuk tugas-tugas yang dapat dimodelkan dengan meneruskannya ke pengklasifikasi. Sebagai contoh, model ini baik dalam klasifikasi dokumen, pengenalan ekspresi unik, dan menjawab pertanyaan yang bagian jawabannya diekstrak dari dokumen target.
BERT
BERT adalah Transformator dua arah yang telah dilatih sebelumnya pada sebuah korpus besar yang terdiri dari Wikipedia dan Bookcorpus.
ALBERT
ALBERT adalah sebuah model untuk BERT dengan beberapa penyesuaian berikut:
- Memisahkan dimensi penyematan token dari dimensi lapisan tersembunyi, mengurangi dimensi penyematan
- Mengurangi jumlah parameter dengan membuat semua lapisan memiliki parameter yang sama
- Prediksi kalimat berikutnya diganti dengan prediksi urutan kalimat
RoBERTa
RoBERTa adalah model berbasis BERT dengan lebih banyak data pelatihan dan kelompok yang lebih besar yang dilatih untuk periode waktu yang lebih lama.
DistilBERT
DistilBERT adalah penyulingan BERT dengan menggunakan Knowledge Distillation pada fase pra-pelatihan, mencapai 97% kinerja BERT dengan menggunakan memori 40% lebih sedikit dan 60% lebih cepat. 97% dari kinerja BERT, dengan menggunakan memori 40% lebih sedikit dan 60% lebih cepat.
XLM
XLM adalah Transformer yang dapat dipelajari dalam berbagai bahasa. Ada tiga jenis pelatihan yang berbeda untuk model ini:
- Causal language modeling (CLM)
- PMasked language modeling (MLM)
- Kombinasi pemodelan bahasa MLM dan pemodelan bahasa terjemahan (TRanslation language modeling, TLM)
XLM-RoBERTa
XLM-RoBERTa adalah model yang dilatih pada dataset sebesar 2,5TB menggunakan korpus [Common Crawl] (https://commoncrawl.org/). Model bahasa terjemahan yang digunakan dalam XLM telah dihapus karena dataset ini tidak menyertakan terjemahan.
ELECTRA
ELECTRA adalah pendekatan pra-pelatihan baru yang melatih dua transformator: Generator dan Diskriminator. Peran Generator adalah untuk mengganti token dalam sebuah urutan dan oleh karena itu dilatih sebagai model bahasa bertopeng. Diskriminator, di sisi lain, adalah model yang mencoba mengidentifikasi token mana dalam urutan yang telah diganti oleh Generator.
Decoder model
Model Decoder hanya menggunakan bagian Decoder dari Transformer. Model ini dilatih dengan menyiapkan tugas untuk memprediksi kata berikutnya untuk setiap kata dalam data urutan input, dan lapisan Perhatian hanya berfokus pada kata-kata yang mendahului setiap kata dalam data input.
Lapisan Attention hanya berfokus pada kata-kata yang mendahului setiap kata dalam data input, membuat model Decoder cocok untuk tugas-tugas seperti pembuatan teks.
GPT
GPT adalah model bahasa berskala besar yang diusulkan oleh OpenAI pada tahun 2018 yang disebut Generative Pre-trained Transformer, yang menampilkan kemampuan untuk menghasilkan kalimat alami tanpa pelatihan khusus tugas GPT menggunakan model untuk memprediksi kata berikutnya berdasarkan kata sebelumnya GPT menggunakan pra-pelatihan untuk memprediksi kata berikutnya berdasarkan kata sebelumnya.
GPT telah dilatih sebelumnya pada kumpulan data Book Corpus.
GPT-2
GPT-2 adalah penerus GPT yang diusulkan oleh OpenAI pada tahun 2019; GPT2 dibuat dengan meningkatkan model dan set data pelatihan GPT.
CTRL
CTRL adalah model yang memungkinkan kontrol atas gaya rangkaian yang dihasilkan dengan menambahkan token kontrol di awal rangkaian.
Reformer
Reformer adalah model Decoder dengan banyak peningkatan untuk mengurangi jejak memori dan waktu komputasi.
XLNet
XLNet adalah model yang melakukan pra-pelatihan menggunakan metode autoregresif dan mempelajari konteks dua arah dengan memaksimalkan kemungkinan yang diharapkan untuk semua permutasi dari urutan penguraian urutan input.
Encoder-Decoder model
Model Encoder-Decoder memanfaatkan seluruh arsitektur Transformer.
Bagian Encoder berfokus pada semua kata dalam data urutan input, sedangkan bagian Decoder hanya berfokus pada kata yang mendahului setiap kata; pelatihan dilanjutkan dengan menyiapkan tugas untuk menyelesaikan masalah isi-isi-kosong pada model Encoder dan memprediksi kata berikutnya pada model Decoder.
Model Encoder-Decoder cocok untuk tugas-tugas seperti penerjemahan mesin dan sistem dialog yang memasukkan teks dan mengeluarkan teks yang berbeda tergantung pada isinya.
BART
BART menggabungkan pra-pelatihan BERT dan GPT dalam arsitektur Encoder dan Decoder.
T5
T5 adalah model yang diusulkan oleh Google pada tahun 2020 dan merupakan singkatan dari Text-to-Text Transfer Transformer; T5 dapat mengubah semua tugas pemahaman bahasa alami dan pembuatan bahasa alami menjadi tugas transformasi teks dan menyelesaikannya dengan cara yang terpadu.
MBart
MBART adalah model yang telah dilatih sebelumnya pada korpus monolingual besar yang terdiri dari 25 bahasa dengan tujuan BART. MBART adalah salah satu metode pertama yang melatih model di antara sekuens lengkap dengan melakukan denoising pada teks lengkap dalam berbagai bahasa.
Cara menggunakan Model
Instal perpustakaan Transformer.
$ pip install transformers
Memuat sebuah model
Kelas AutoModel memungkinkan Anda menggunakan model dengan mudah dengan menentukan checkpoint model yang ingin Anda gunakan. Pada contoh di bawah ini, model bert-base-uncased ditentukan.
from transformers import AutoModel
checkpoint = 'bert-base-uncased'
model = AutoModel.from_pretrained(checkpoint)
Banyak model yang sudah dilatih sebelumnya tersedia di Hugging Face Transformers. Model-model tersebut dapat dilihat secara detail di tautan berikut ini.
Model structure
Sebagai contoh, jika Anda menggunakan BERT, Anda dapat membaca sebagai berikut.
from transformers import BertConfig, BertModel
config = BertConfig()
model = BertModel(config)
print(config)
BertConfig {
"attention_probs_dropout_prob": 0.1,
"classifier_dropout": null,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"position_embedding_type": "absolute",
"transformers_version": "4.24.0",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 30522
}
Arti setiap atribut dapat ditemukan di tautan berikut.
Menyimpan model
Anda dapat menyimpan model Anda dengan kode berikut. Jika direktori tujuan tidak ada, sebuah folder akan secara otomatis dibuat.
model.save_pretrained("./tmp")
Apabila Anda menyimpan file, dua jenis file berikut ini akan disimpan.
config.jsonpytorch_model.bin
Memuat model yang disimpan
Untuk memuat model yang telah disimpan, tulis kode berikut
saved_model = model.from_pretrained("./tmp")
Perhatian saat menggunakan model Transformer yang telah dilatih sebelumnya
Penting untuk diperhatikan bahwa model yang sudah dilatih mengandung sejumlah bias.
Dengan menggunakan BERT's fill-mask Pipeline, saya akan menyiapkan dua jenis kalimat pekerjaan, satu dengan subjek laki-laki dan satu dengan subjek perempuan, dan membiarkan model mengeluarkan kandidat kata dengan menyamarkan bagian kalimat yang sesuai dengan nama pekerjaan.
from transformers import pipeline
unmasker = pipeline("fill-mask", model="bert-base-uncased")
result = unmasker("This man works as a [MASK].")
print("man:", [r["token_str"] for r in result])
result = unmasker("This woman works as a [MASK].")
print("woman:", [r["token_str"] for r in result])
man: ['carpenter', 'lawyer', 'farmer', 'businessman', 'doctor']
woman: ['nurse', 'maid', 'teacher', 'waitress', 'prostitute']
Pada kedua kasus tersebut, hasilnya menunjukkan bahwa tidak ada tumpang tindih di antara keduanya, yang mengindikasikan bahwa ada perbedaan tergantung pada jenis kelamin. Lebih lanjut, kandidat kelima, prostitute, sebuah kata yang berkonotasi merendahkan, dihasilkan ketika subjeknya perempuan.
Model BERT telah dilatih sebelumnya pada Wikipedia dan Bookcorpus, dua set data yang mungkin tidak mengandung banyak prasangka. Namun, model ini dapat memberikan hasil seperti ini dalam beberapa kasus.
Referensi















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS