



Hugging Face Transformers Tokenizer
Model Transformer tidak mengizinkan input langsung data teks mentah, sehingga teks harus dikonversi menjadi data numerik. Tokenizer melakukan konversi ini.
Tokenizer melakukan pemrosesan berikut pada teks input:
- Memisahkan teks ke dalam unit terkecil seperti kata, sub-kata, simbol, dll.
- Menetapkan ID untuk setiap token
- Menambahkan token khusus ke teks input yang memberikan informasi yang diperlukan untuk mengisi model
- Sebagai contoh, BERT membutuhkan token seperti
<CLS>untuk menunjukkan awal kalimat dan<EOS>untuk menunjukkan akhir kalimat.
- Sebagai contoh, BERT membutuhkan token seperti
Anda dapat menggunakan metode from_pretrained dari kelas AutoTokenizer untuk menggunakan Tokenizer dari model yang ditentukan.
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
encoded_input = tokenizer("Do not meddle in the affairs of wizards, for they are subtle and quick to anger.")
print(encoded_input)
>> {'input_ids': [101, 2079, 2025, 19960, 10362, 1999, 1996, 3821, 1997, 16657, 1010, 2005, 2027, 2024, 11259, 1998, 4248, 2000, 4963, 1012, 102],
>> 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
Arti dari nilai pengembalian adalah sebagai berikut
| Return | Deskripsi |
|---|---|
| input_ids | Teks masukan dibagi menjadi token, masing-masing digantikan oleh ID |
| attention_mask | Indikasi apakah token input memenuhi syarat untuk Attention |
| token_type_ids | Pernyataan yang menunjukkan kalimat mana yang termasuk dalam setiap token, ketika satu input terdiri dari beberapa kalimat |
Penggunaan dasar
Gunakan kelas AutoTokenizer untuk menginstansiasi Tokenizer sebagai berikut.
from transformers import AutoTokenizer
checkpoint = "bert-base-cased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
Anda dapat menyandikan teks menggunakan Tokenizer sebagai berikut.
text = "The quick brown fox jumps over the lazy dog."
encoded_text = tokenizer(text)
print(encoded_text)
>> {
>> 'input_ids': [101, 1109, 3613, 3058, 17594, 15457, 1166, 1204, 1103, 16688, 3676, 119, 102],
>> 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
>> }
Metode convert_ids_to_tokens juga dapat digunakan untuk mengonversi dari ID ke token.
tokens = tokenizer.convert_ids_to_tokens(encoded_text.input_ids)
print(tokens)
['[CLS]', 'The', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog', '.', '[SEP]']
[CLS] merujuk pada token yang menunjukkan awal kalimat dalam model BERT, dan [SEP] merujuk pada token yang menunjukkan jeda kalimat. Pada inputs_ids, 101 merujuk pada [CLS] dan 102 merujuk pada [SEP].
Metode convert_tokens_to_string dapat digunakan untuk mengonversi dari ID ke teks.
print(tokenizer.convert_tokens_to_string(tokens))
[CLS] The quick brown fox jumps over the lazy dog. [SEP]
Konversi dari ID ke teks dilakukan sebagai berikut.
decoded_string = tokenizer.decode(encoded_text["input_ids"])
print(decoded_string)
The quick brown fox jumps over the lazy dog.
Token khusus, dll., secara otomatis dihapus, sehingga bentuknya mudah digunakan saat mengeluarkan hasil inferensi.
Pengkodean beberapa kalimat
Beberapa kalimat dapat dikodekan bersama dengan meneruskannya ke Tokenizer sebagai daftar.
batch_sentences = [
"But what about second breakfast?",
"Don't think he knows about second breakfast, Pip.",
"What about elevensies?",
]
encoded_inputs = tokenizer(batch_sentences)
print(encoded_inputs)
>> {'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102],
>> [101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
>> [101, 1327, 1164, 5450, 23434, 136, 102]],
>> 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0],
>> [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> [0, 0, 0, 0, 0, 0, 0]],
>> 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1],
>> [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
>> [1, 1, 1, 1, 1, 1, 1]]}
Opsi berikut ini dapat diatur untuk pengodean:
- Mengisi setiap kalimat dengan panjang maksimum kalimat dalam batch
- Memotong setiap kalimat hingga panjang maksimum yang diizinkan oleh model
- Kembalikan tensor
Padding
Tensor, yang merupakan masukan untuk model, harus memiliki bentuk yang seragam. Oleh karena itu, panjang kalimat yang berbeda dapat menjadi masalah. Padding adalah sebuah strategi untuk memastikan bahwa tensor berbentuk persegi panjang dengan menambahkan sebuah token padding khusus pada kalimat-kalimat pendek.
Jika padding=True disetel, urutan pendek dalam satu kumpulan akan diberi padding agar sesuai dengan urutan terpanjang.
batch_sentences = [
"But what about second breakfast?",
"Don't think he knows about second breakfast, Pip.",
"What about elevensies?",
]
encoded_input = tokenizer(batch_sentences, padding=True)
print(encoded_input)
>> {'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
>> [101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
>> [101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
>> 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
>> 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
>> [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
>> [1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
Pemotongan
Di sisi lain, ada beberapa kasus di mana urutan terlalu panjang untuk ditangani oleh model. Dalam kasus ini, urutan harus dipotong menjadi lebih pendek.
Menetapkan truncation=True akan memotong urutan ke panjang maksimum yang dapat diterima oleh model.
batch_sentences = [
"But what about second breakfast?",
"Don't think he knows about second breakfast, Pip.",
"What about elevensies?",
]
encoded_input = tokenizer(batch_sentences, padding=True, truncation=True)
print(encoded_input)
>> {'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
>> [101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
>> [101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
>> 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
>> 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
>> [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
>> [1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
Kembalikan tensor
Mengembalikan tensor aktual yang diberikan ke model ke Tokenizer.
Atur parameter return_tensors ke pt untuk PyTorch atau tf untuk TensorFlow.
batch_sentences = [
"But what about second breakfast?",
"Don't think he knows about second breakfast, Pip.",
"What about elevensies?",
]
encoded_input = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="pt")
print(encoded_input)
>> {'input_ids': tensor([[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
>> [101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
>> [101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]]),
>> 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]),
>> 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
>> [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
>> [1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]])}
batch_sentences = [
"But what about second breakfast?",
"Don't think he knows about second breakfast, Pip.",
"What about elevensies?",
]
encoded_input = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="tf")
print(encoded_input)
>> {'input_ids': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
>> array([[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
>> [101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
>> [101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
>> dtype=int32)>,
>> 'token_type_ids': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
>> array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
>> [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], dtype=int32)>,
>> 'attention_mask': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
>> array([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
>> [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
>> [1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]], dtype=int32)>}
Opsi yang direkomendasikan
Tabel berikut ini merangkum opsi yang direkomendasikan untuk padding dan pemotongan.
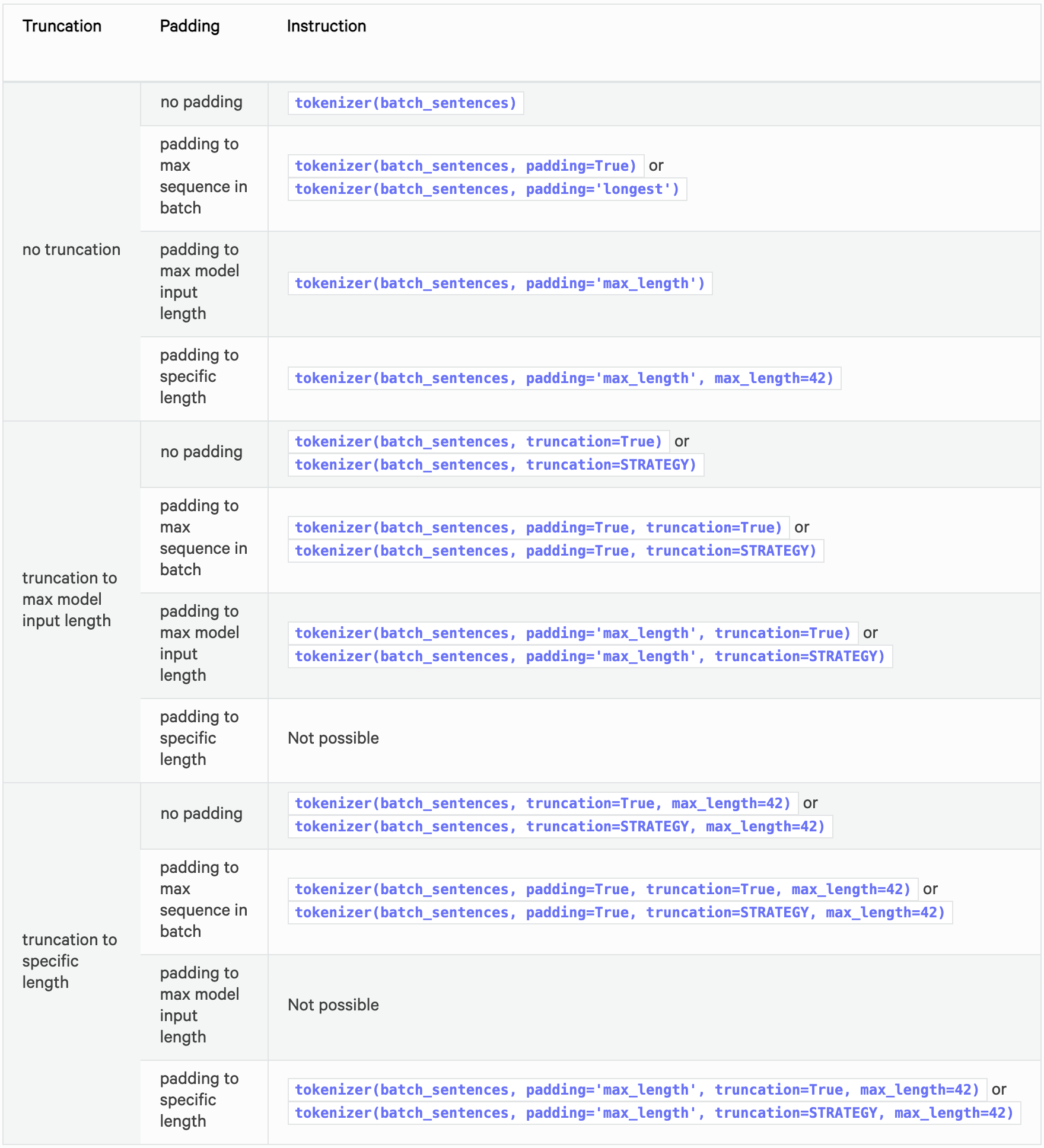
Lihat di bawah ini untuk spesifikasi detail padding dan pemotongan.
Pasangan kalimat
Terkadang perlu untuk memberikan pasangan kalimat pada model, seperti ketika seseorang ingin mengklasifikasikan apakah dua kalimat serupa.
Dalam BERT, input direpresentasikan sebagai berikut.
[CLS] Sequence A [SEP] Sequence B [SEP]
Dua kalimat dapat diberikan sebagai dua argumen untuk mengkodekan sepasang kalimat dalam format yang diharapkan oleh model.
encoded_input = tokenizer("How old are you?", "I'm 6 years old")
print(encoded_input)
>> {'input_ids': [101, 1731, 1385, 1132, 1128, 136, 102, 146, 112, 182, 127, 1201, 1385, 102],
>> 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1],
>> 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
token_type_ids digunakan untuk menentukan bagian mana yang merupakan kalimat A dan bagian mana yang merupakan kalimat B. Oleh karena itu, token_type_ids tidak diperlukan untuk semua model.
Secara default, tokenisasi Tokenizer hanya mengembalikan input yang diharapkan oleh model terkait. Anda dapat menggunakan return_input_ids atau return_token_type_ids untuk memaksa pengembalian atau non-pengembalian salah satu argumen khusus ini.
Penguraian ID token yang diambil akan menunjukkan bahwa token khusus telah ditambahkan dengan benar.
tokenizer.decode(encoded_input["input_ids"])
>> "[CLS] How old are you? [SEP] I'm 6 years old [SEP]"
Jika Anda memiliki daftar pasangan kalimat yang ingin Anda proses, berikan kedua daftar tersebut ke Tokenizer.
batch_sentences = ["Hello I'm a single sentence",
"And another sentence",
"And the very very last one"]
batch_of_second_sentences = ["I'm a sentence that goes with the first sentence",
"And I should be encoded with the second sentence",
"And I go with the very last one"]
encoded_inputs = tokenizer(batch_sentences, batch_of_second_sentences)
print(encoded_inputs)
>> {'input_ids': [[101, 8667, 146, 112, 182, 170, 1423, 5650, 102, 146, 112, 182, 170, 5650, 1115, 2947, 1114, 1103, 1148, 5650, 102],
>> [101, 1262, 1330, 5650, 102, 1262, 146, 1431, 1129, 12544, 1114, 1103, 1248, 5650, 102],
>> [101, 1262, 1103, 1304, 1304, 1314, 1141, 102, 1262, 146, 1301, 1114, 1103, 1304, 1314, 1141, 102]],
>> 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
>> [0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
>> [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1]],
>> 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
>> [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
>> [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
Anda juga dapat mendekode daftar input_ids satu per satu untuk memeriksa yang diberikan dalam model.
for ids in encoded_inputs["input_ids"]:
print(tokenizer.decode(ids))
>> [CLS] Hello I'm a single sentence [SEP] I'm a sentence that goes with the first sentence [SEP]
>> [CLS] And another sentence [SEP] And I should be encoded with the second sentence [SEP]
>> [CLS] And the very very last one [SEP] And I go with the very last one [SEP]
Pre-Tokenized input
Anda juga dapat meneruskan input yang sudah di-tokenisasi ke Tokenizer.
Jika Anda ingin menggunakan input yang sudah di-tokenisasi, tentukan is_pretokenized=True saat mengoper input ke Tokenizer.
encoded_input = tokenizer(["Hello", "I'm", "a", "single", "sentence"], is_pretokenized=True)
print(encoded_input)
>> {'input_ids': [101, 8667, 146, 112, 182, 170, 1423, 5650, 102],
>> 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0],
>> 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
Perhatikan bahwa Tokenizer akan menambahkan token khusus kecuali jika Anda menentukan add_special_token=False.
Sekumpulan pernyataan dapat dikodekan sebagai berikut.
batch_sentences = [["Hello", "I'm", "a", "single", "sentence"],
["And", "another", "sentence"],
["And", "the", "very", "very", "last", "one"]]
encoded_inputs = tokenizer(batch_sentences, is_pretokenized=True)
Anda juga dapat menyandikan pasangan kalimat sebagai berikut.
batch_of_second_sentences = [["I'm", "a", "sentence", "that", "goes", "with", "the", "first", "sentence"],
["And", "I", "should", "be", "encoded", "with", "the", "second", "sentence"],
["And", "I", "go", "with", "the", "very", "last", "one"]]
encoded_inputs = tokenizer(batch_sentences, batch_of_second_sentences, is_pretokenized=True)
Referensi















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS