


Apa itu BERT
BERT adalah singkatan dari Bidirectional Encoder Representations dari Transformers dan merupakan model pemrosesan bahasa alami yang diumumkan oleh Google pada tanggal 11 Oktober 2018.
BERT adalah model pra-pelatihan oleh Transformer yang bersifat dua arah menggunakan dataset besar yang tidak diawasi. BERT adalah model pra-pelatihan, bukan model prediktif, sehingga BERT dengan sendirinya tidak dapat melakukan apa pun. Penyempurnaan untuk tugas-tugas individual seperti klasifikasi dokumen atau analisis sentimen menjadikannya model prediktif.
Fitur-fitur BERT
BERT memiliki fitur-fitur berikut:
- Pemahaman kontekstual
- Fleksibilitas tinggi
- Mengatasi kekurangan data
Pemahaman kontekstual
Sebelum BERT, ada model pemrosesan bahasa seperti ELMo dan OpenAI GPT, yang tidak dapat memahami konteks karena ELMo adalah model dua arah yang dangkal dan OpenAI GPT adalah model searah. Berikut adalah contoh dari Google.
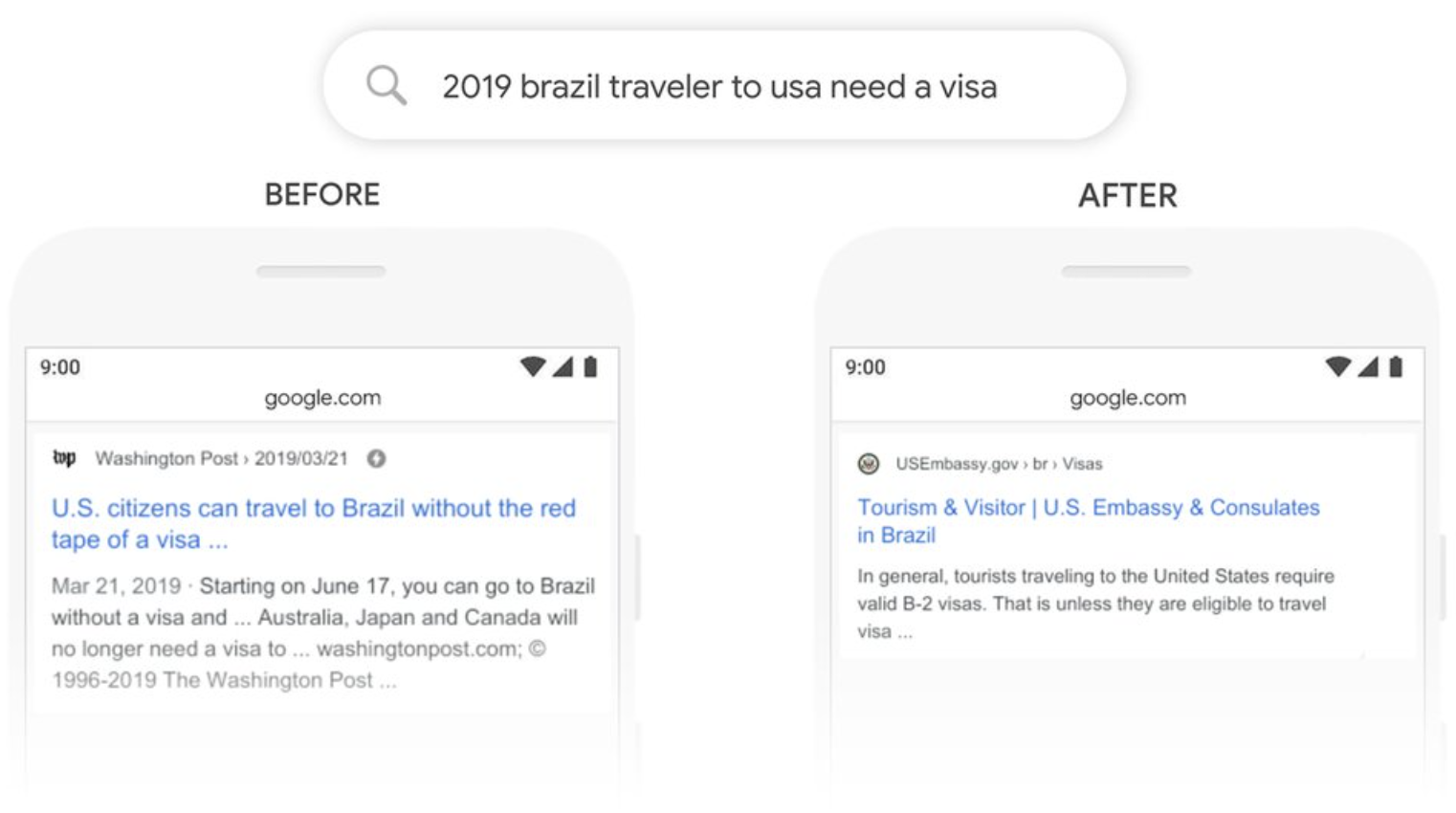
Sebelum diperkenalkannya BERT, pencarian Google tidak dapat memproses kata-kata seperti "to" yang membentuk hubungan kalimat-ke-kalimat. Sebagai contoh, misalkan kita memiliki istilah pencarian berikut.
2019 brazil traveler to usa need a visa
Dalam kasus istilah pencarian di atas, yang ingin diketahui oleh pengguna adalah apakah pelancong dari Brasil memerlukan visa untuk pergi ke Amerika Serikat. Namun, sebelum diperkenalkannya BERT, kata "to" tidak dapat diproses, sehingga dapat diartikan sebagai "American traveler to Brazil," yang menghasilkan hasil pencarian yang tidak sesuai dengan kebutuhan.
BERT adalah model yang sadar konteks dengan menggunakan Transformer interaktif, dan setelah BERT diimplementasikan, "Brazilian travelers to the U.S." dapat ditafsirkan dan halaman informasi visa Kedutaan Besar AS untuk wisatawan Brasil dapat ditampilkan di bagian atas hasil pencarian. Model ini sekarang ditafsirkan sebagai "Brazilian travelers to the U.S.".
Understanding searches better than ever before
Fleksibilitas tinggi
BERT dapat melatih data teks dalam jumlah besar dari Wikipedia, BooksCorpus, dan sumber-sumber lain, dan kemudian menerapkannya pada berbagai tugas seperti analisis sentimen dan penerjemahan melalui penyempurnaan.
Mengatasi kekurangan data
Tidak seperti model tradisional, BERT dapat memproses kumpulan data yang tidak berlabel. Kumpulan data berlabel sering kali sulit diperoleh; BERT dapat mengatasi kekurangan data dengan mengizinkan data yang tidak berlabel untuk digunakan sebagai bahan untuk diproses.
Bagaimana BERT bekerja
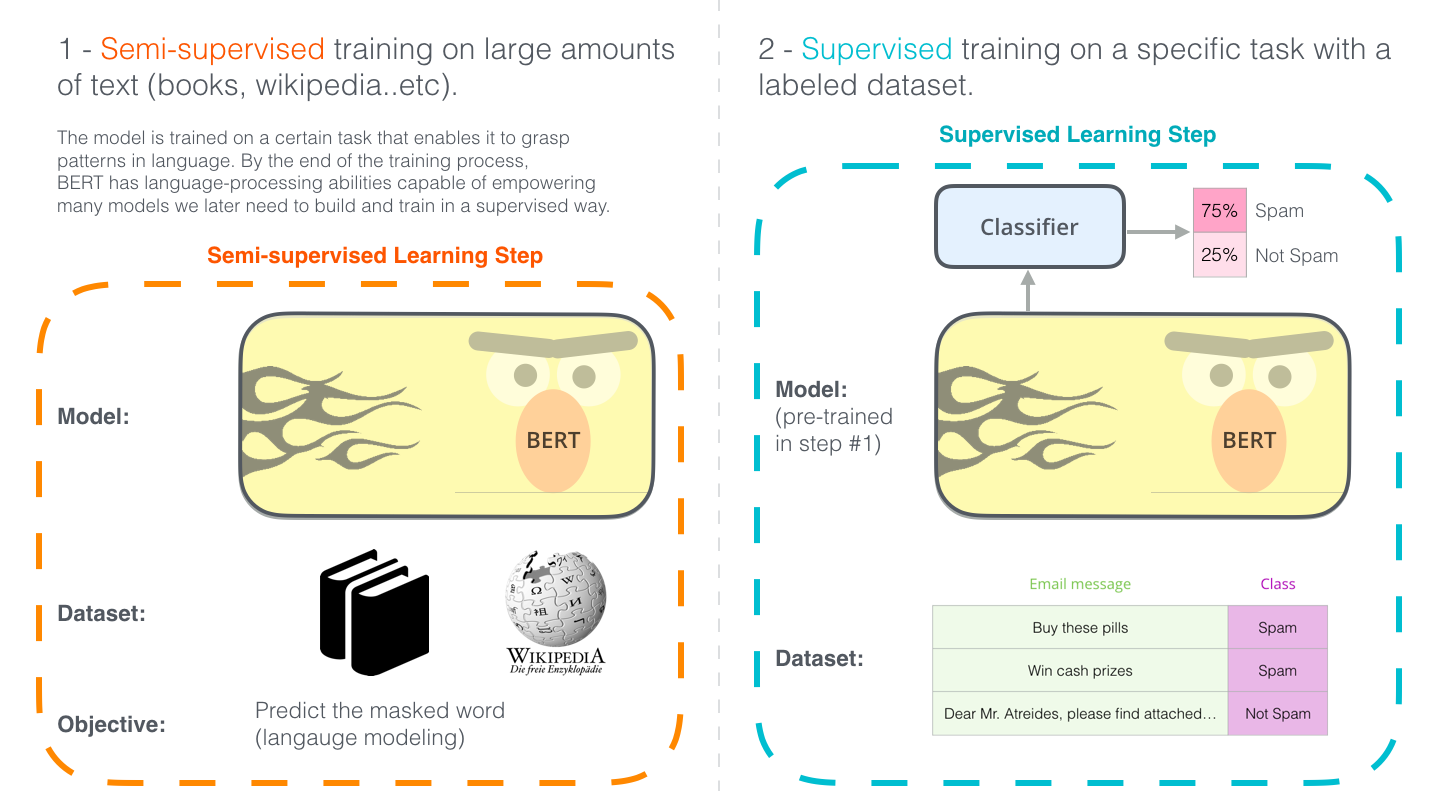
Mempelajari BERT melibatkan dua langkah berikut:
- Pra-pelatihan
Pra-pelatihan dengan data yang tidak berlabel - Fine tuning
Fine tuning dengan data berlabel menggunakan bobot yang telah dilatih sebelumnya sebagai nilai awal
Sebagai contoh, tugas klasifikasi spam diilustrasikan di bawah ini.
The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)
BERT hanya memiliki arsitektur Transformer Encoder, dan ada model BASE dan LARGE.
| Model | L (# of Transformer blocks) | H (hidden layer size) | A (# of Self-Attention head) | # parameters |
|---|---|---|---|---|
| 12 | 768 | 12 | 110M | |
| 24 | 1024 | 16 | 340M |
Pra-pelatihan
Data yang digunakan dalam pra-pelatihan BERT adalah data teks mentah tanpa label.
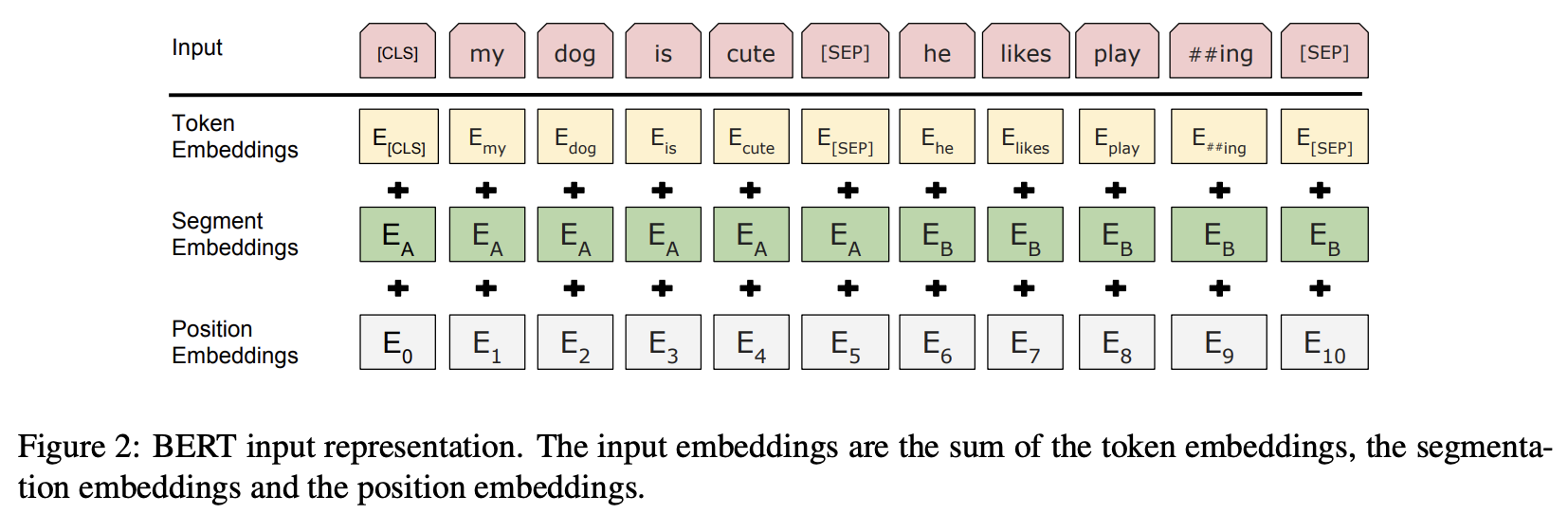
Data dokumen dikonversi menjadi urutan vektor seperti yang ditunjukkan pada gambar di bawah ini.
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Pada baris teratas, "Input," strukturnya adalah satu urutan input, yang terdiri dari token khusus [CLS] di awal dan dua kalimat A dan B yang digabungkan dengan menyisipkan token khusus [SEP] di akhir setiap kalimat.
Pada tahap kedua dan selanjutnya, segera setelah urutan input dikirimkan, ketiga Embeddings menggantikan token, kategori kalimat, dan posisi dalam urutan tersebut dengan representasi tertanam H-dimensi yang dipelajari dalam proses pra-pelatihan, dan urutan vektor yang diperoleh dengan menambahkan token-token ini menjadi input ke Transformer.
- Token Embeddings: Token ID
- Segment Embeddings: Segmen kalimat A dan B
- Position Embeddings: Posisi dalam kalimat
BERT melakukan pra-pelatihan pada input ini, dengan menggabungkan dua fungsi objektif berikut
- Masked language Model
- Next Sentence Prediction
Masked Language Model
Model pemrosesan bahasa alami konvensional hanya dapat memproses kalimat dari satu arah dan harus membuat prediksi berdasarkan data dari kalimat-kalimat yang mendahului kata target. Namun, BERT, melatih menggunakan Transformator dua arah, menghasilkan peningkatan akurasi yang signifikan dibandingkan metode konvensional. Hal ini dimungkinkan oleh Masked Language Model.
Proses Masked Language Model bekerja dengan mengganti 15% kata dalam kalimat input dengan kata lain secara probabilistik dan memprediksi kata sebelum kata yang diganti berdasarkan konteksnya. Dari 15% yang dipilih, 80% disamarkan untuk diganti dengan [MASK], 10% dengan kata acak lainnya, dan 10% sisanya dibiarkan tidak berubah.
- 80% dari 15% kata yang dipilih diubah menjadi [MASK].
- my dog is hairy ➡︎ my dog is [MASK]
- 10% dari 15% kata yang dipilih diubah menjadi kata acak.
- my dog is hairy ➡︎ my dog is apple
- 10% dari 15% kata yang dipilih tetap sama.
- my dog is hairy ➡︎ my dog is hairy
Dengan menyelesaikan tugas menebak kata-kata yang diganti ini dari konteks di sekitarnya, informasi kontekstual yang sesuai dengan kata-kata tersebut dapat dipelajari.
Next Sentence Prediction
Masked Language Model dapat mempelajari kata-kata, ia tidak dapat mempelajari kalimat. Prediksi Kalimat Berikutnya dapat mempelajari hubungan antara dua kalimat.
Next Sentence Prediction belajar dengan mengganti salah satu kalimat dengan kalimat lainnya dengan probabilitas 50% dan menentukan apakah kalimat-kalimat tersebut berdekatan (isNext atau notNext) atau tidak (isNext atau notNext). Sebuah token yang disebut [CLS] disediakan untuk klasifikasi.
| Contoh kalimat | Penghakiman |
|---|---|
| [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP] | isNext |
| [CLS] the man went to [MASK] store [SEP] penguin [MASK] are flightless birds [SEP] | notNext |
Dengan cara ini, BERT tidak hanya dapat belajar tentang kata-kata, tetapi juga tentang ekspresi seluruh kalimat.
Fine tuning
Model BERT yang telah dilatih sebelumnya disetel dengan baik sesuai dengan tugas yang harus diselesaikan. Fine tuning melibatkan pembelajaran pada sejumlah kecil data berlabel.
Ketika fine tuning dilakukan, parameter yang diperoleh dari pra-pelatihan digunakan sebagai nilai awal model, dan parameter dipelajari menggunakan data berlabel.
Dengan demikian, dengan menggunakan parameter yang diperoleh pada pra-pelatihan sebagai nilai awal selama fine tuning, model dengan kinerja tinggi dapat diperoleh bahkan dengan jumlah data pelatihan yang relatif kecil.
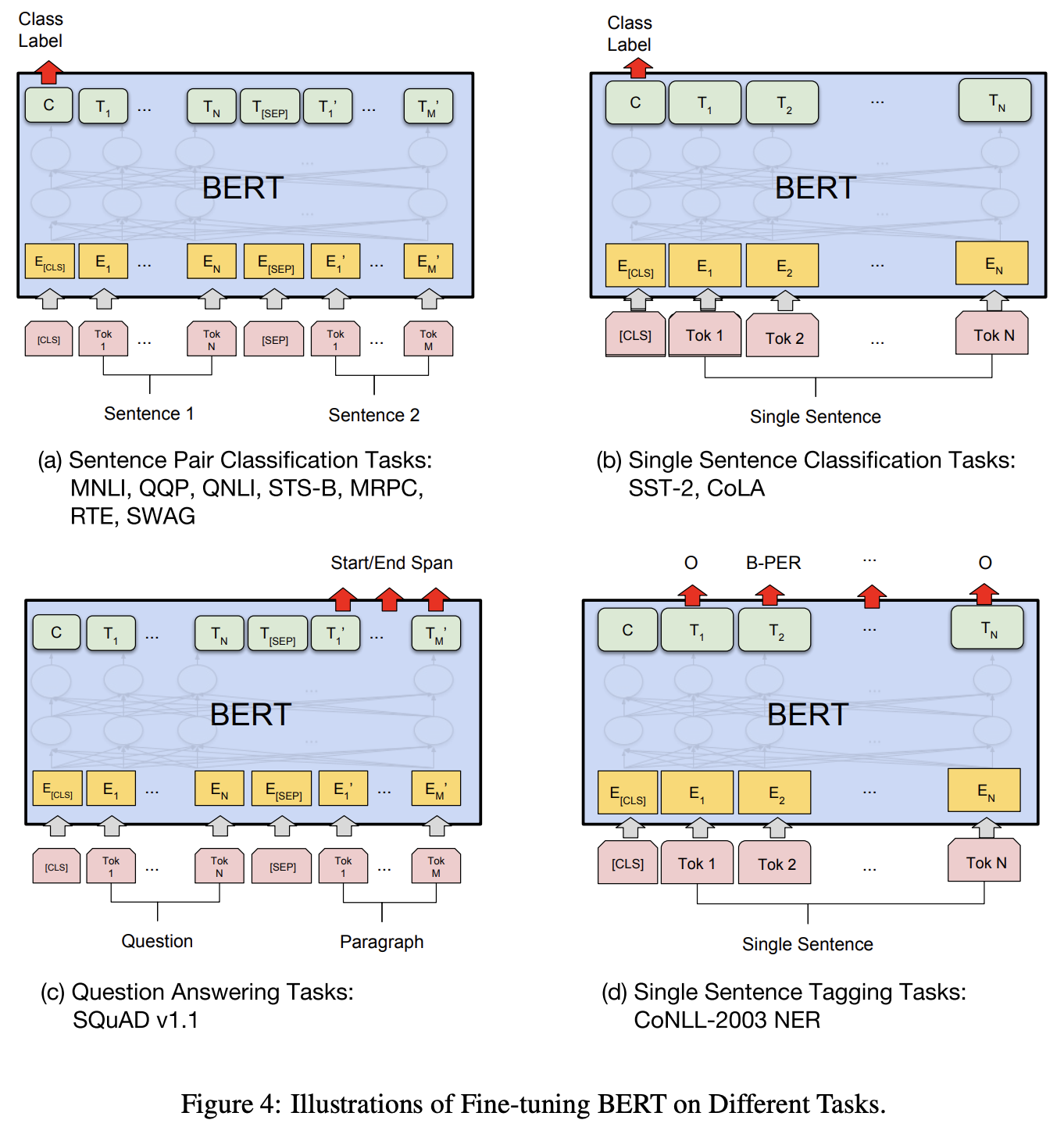
Gambar di bawah ini menunjukkan contoh fine tuning.
- (a) Sentence Pair Classification Tasks
- (b) Single Sentence Classification Tasks
- (c) Question Answering Tasks
- (d) Single Sentence Tagging Tasks
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Tolok ukur kinerja BERT
Kinerja model pemrosesan bahasa alami diukur dengan GLUE (The General Language Understanding Evaluation), sebuah tolok ukur yang menghitung skor pada semua tugas pemrosesan bahasa alami. Tabel berikut ini menunjukkan hasil GLUE yang dijelaskan dalam makalah ini.
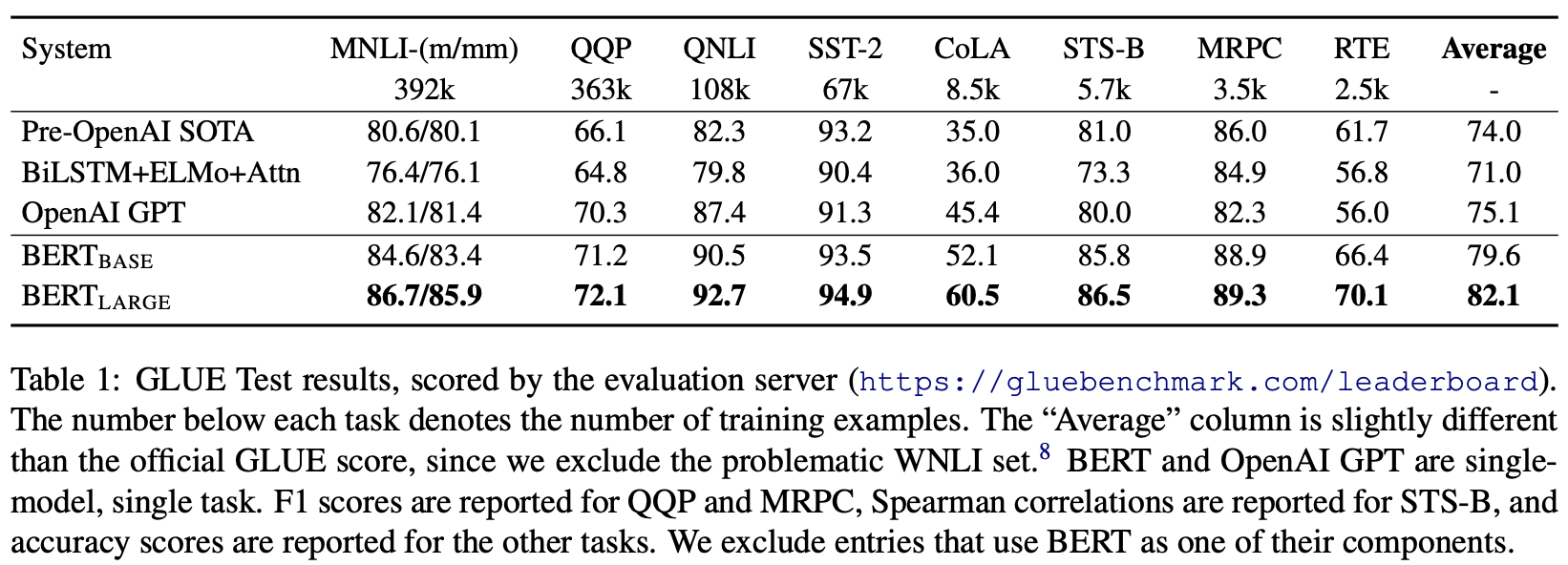
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Skor BERT lebih tinggi daripada model yang sudah ada seperti OPEN AI pada semua dataset.
Referensi
















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS