

Apa itu Transformer
Transformer adalah model pembelajaran mendalam yang pertama kali muncul dalam makalah tentang NLP yang berjudul Attention Is All You Need yang diterbitkan oleh Google pada tahun 2017. Transformer adalah model Encoder-Decoder yang hanya menggunakan Attention, tidak seperti model Encoder-Decoder yang menggunakan RNN yang telah menjadi arus utama di dunia NLP hingga saat itu.
Transformer adalah model dasar yang penting yang digunakan dalam model NLP mutakhir saat ini. Baru-baru ini, Transformer juga mulai digunakan di bidang pengenalan gambar.
Fitur-fitur Transformer
Transformer memiliki fitur-fitur berikut ini:
- Dibangun hanya dengan lapisan Attention tanpa RNN
- Ini mencapai komputasi paralel, yang tidak mungkin dilakukan apabila RNN digunakan bersama-sama, dan mempercepat komputasi.
- Adopsi lapisan Positional Encoding (Pengkodean Posisi)
- Data kata masukan dapat mempertahankan informasi kontekstual dengan menyematkan informasi posisi kata dalam keseluruhan kalimat.
- Penerapan model Query-Key-Value di lapisan Attention
- Ini meningkatkan akurasi dengan merefleksikan korespondensi kata per kata secara lebih akurat
Sejarah perkembangan Transformer
Secara historis, Transformer lahir dari alur pengembangan model berikut ini.
- RNN
- Seq2seq
- Seq2seq dengan Attention
- Transformer
RNN
Model bahasa membutuhkan pemrosesan kontekstual. Sebagai contoh, misalkan kita memiliki kalimat berikut ini.
Bob gets an apple. He eats it.
Di sini, mustahil untuk mengetahui siapa "he" dan apa "it" tanpa memahami konteksnya.
Di sinilah model rekursif yang dapat menyimpan informasi ketergantungan untuk seluruh kalimat, seperti RNN, muncul. Idenya adalah ketika data input diubah menjadi vektor dengan panjang tetap, informasi dari kata-kata sebelumnya juga diperhitungkan; dalam RNN, fungsi yang sama digunakan secara rekursif untuk menghasilkan output secara berurutan, dan output sebelumnya disertakan sebagai bagian dari data yang digunakan untuk input berikutnya.
RNN sekarang dapat merefleksikan konteks, tetapi RNN dihitung secara berurutan dan tidak dapat memparalelkan komputasi, yang menyisakan masalah bahwa sulit untuk mempercepat komputasi.
Seq2seq
Model Seq2seq (RNN dengan Encoder-Decoder) dirancang untuk memanfaatkan data deret waktu yang berbeda, seperti penerjemahan mesin.
Dalam Seq2seq, data input dikonversi menjadi vektor panjang tetap tunggal dalam Encoder-Decoder dan digunakan dengan cara yang sama seperti dalam RNN. Meskipun Seq2seq telah mencapai hasil yang baik dalam hal mengkonversi data deret waktu yang berbeda, beberapa masalah berikut menjadi jelas:
- Kompresi ke dalam vektor dengan panjang tetap mencegah informasi untuk sepenuhnya terkandung dalam kalimat yang panjang.
- Penggunaan kolokasi antara kata dan kalimat tidak memungkinkan.
Penggunaan korelasi sangat penting terutama ketika berurusan dengan data deret waktu yang berbeda, seperti dalam tugas penerjemahan. Sebagai contoh, terjemahan yang lebih akurat akan lebih mungkin dilakukan jika Anda menggunakan korespondensi antara "air" dan "eau (air dalam bahasa Prancis)" daripada hanya mencari secara samar-samar apa arti "air".
Seq2seq dengan Attention
Seq2seq dengan Attention memecahkan masalah Seq2seq dengan menggunakan vektor dengan panjang tetap yang dibuat dari bagian Encoder pada Seq2seq, tetapi hanya bagian terakhir dari vektor yang digunakan. Dengan menggunakan semua vektor panjang tetap yang dikeluarkan ketika setiap kata dimasukkan, maka hal berikut ini mungkin terjadi
- Jumlah vektor konteks dengan panjang tetap yang sama dengan jumlah kata dapat diperoleh (jumlah informasi yang sesuai dengan panjang kalimat dapat diperoleh).
- Attention memungkinkan perolehan korespondensi antar kata.
Transformer
Meskipun akurasi ditingkatkan dengan menggunakan Attention, ia memiliki masalah karena tidak dapat memparalelkan dan mempercepat komputasi, yang disebabkan oleh penggunaan RNN dalam kombinasi.
Oleh karena itu, Transformer, yang hanya menggunakan lapisan Attention tanpa RNN, lahir, memecahkan masalah RNN dan Seq2seq dengan Attention, seperti kurangnya paralelisasi dan ketidakmampuan untuk membangun model ketergantungan yang akurat. Transformer telah berhasil memecahkan masalah RNN dan Seq2seq dengan Attention.
Transformer mencapai hal-hal berikut dalam tugas penerjemahan bahasa Inggris-Jerman (EN-DE) dan Inggris-Prancis (EN-FR) WMT 2014
- Menetapkan skor BLEU tertinggi pada saat itu
- dan menjaga biaya pelatihan tetap rendah dibandingkan model pesaing
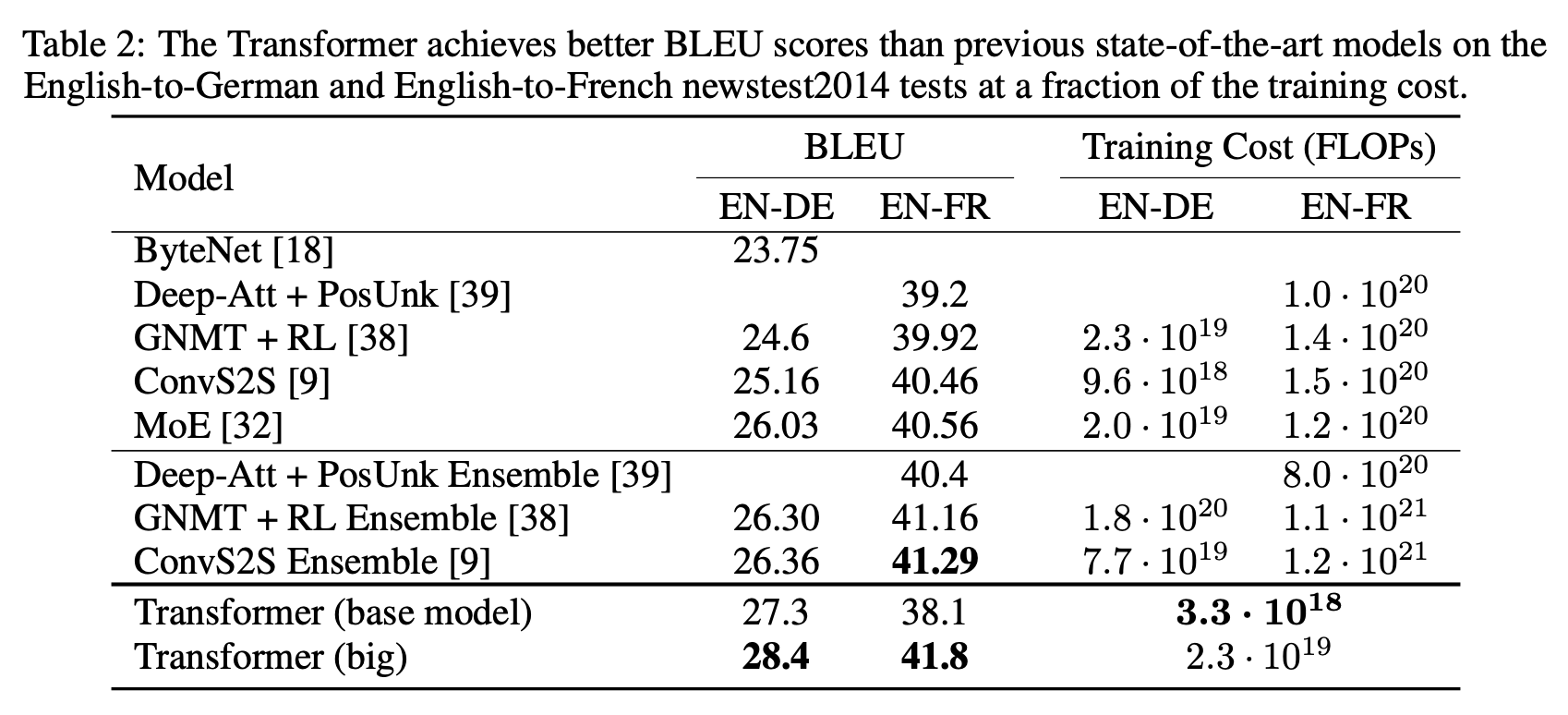
Arsitektur Transformer
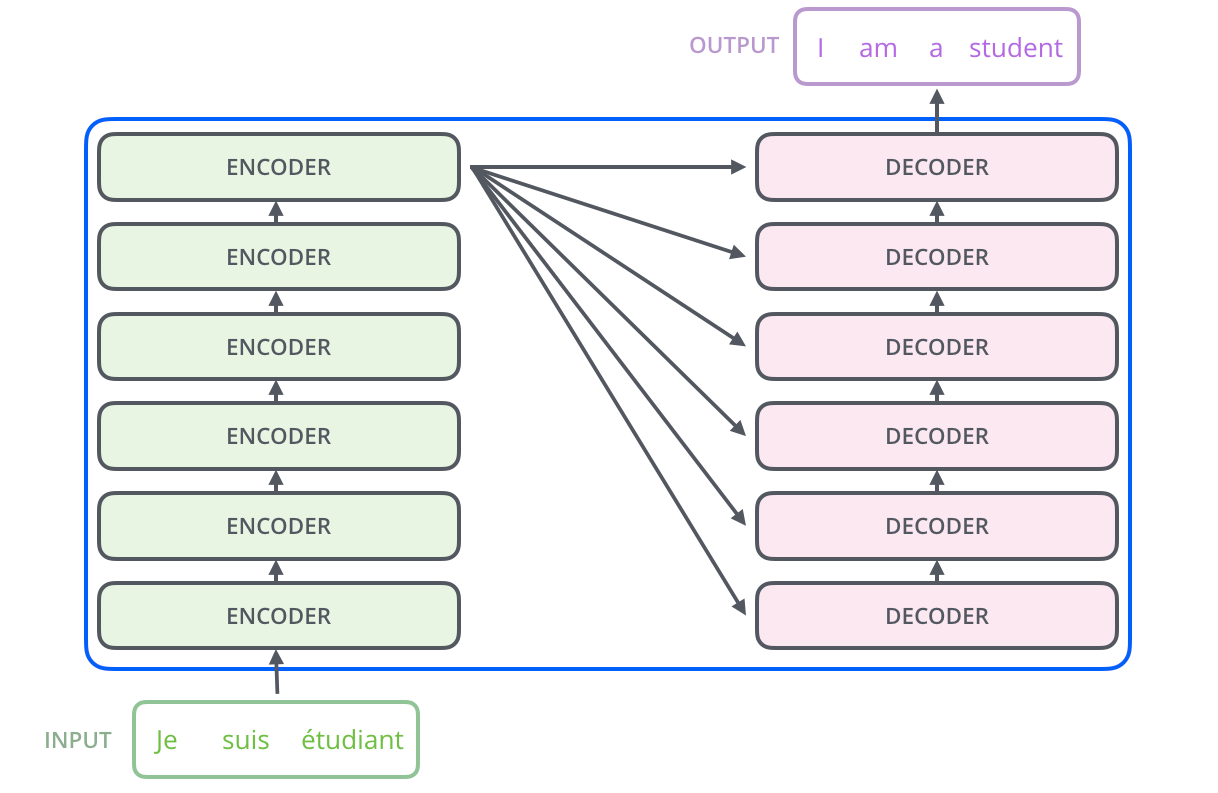
Berikut ini adalah arsitektur Transformer selama melakukan tugas penerjemahan.
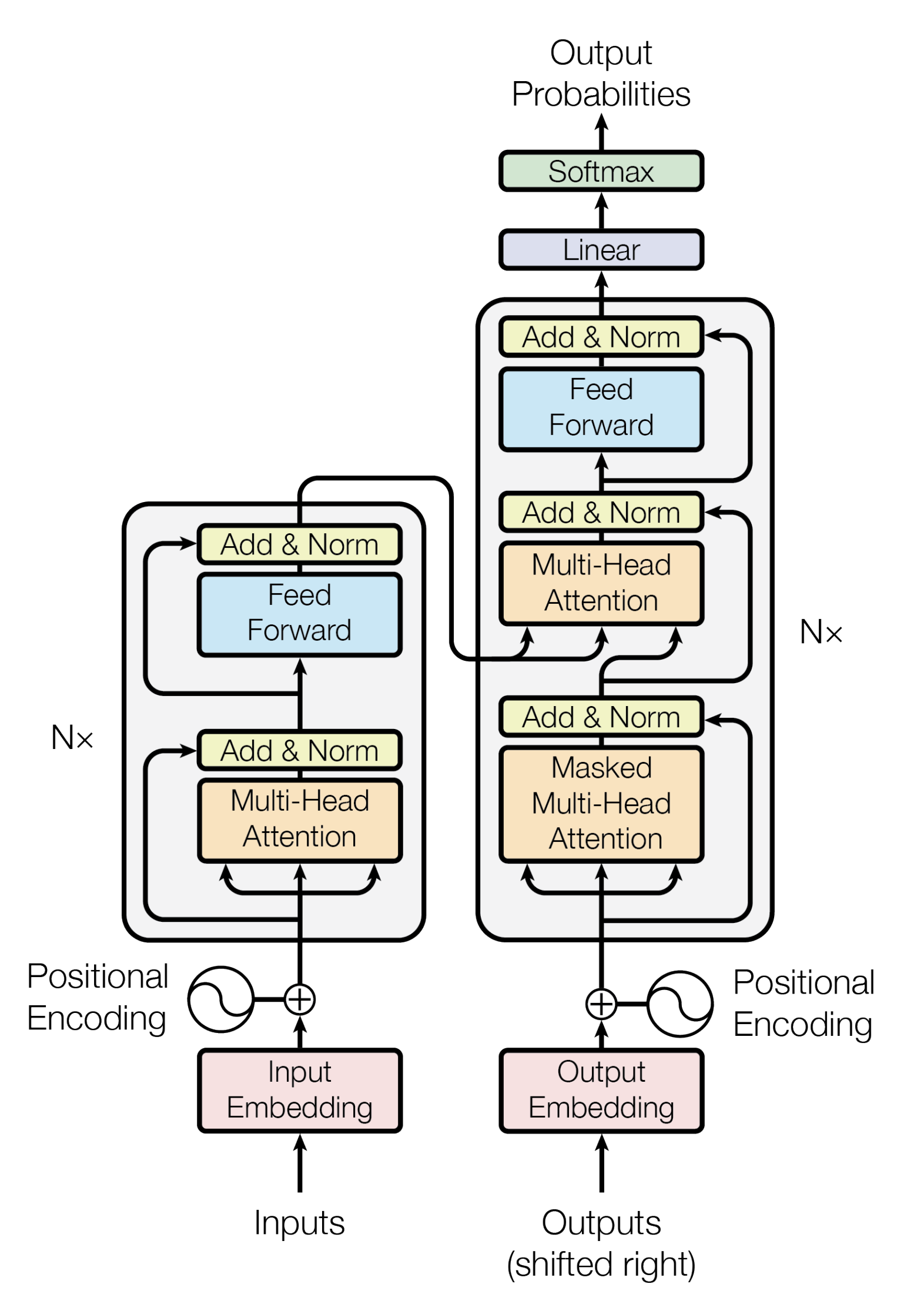
Transformer didasarkan pada model Encoder-Decoder.
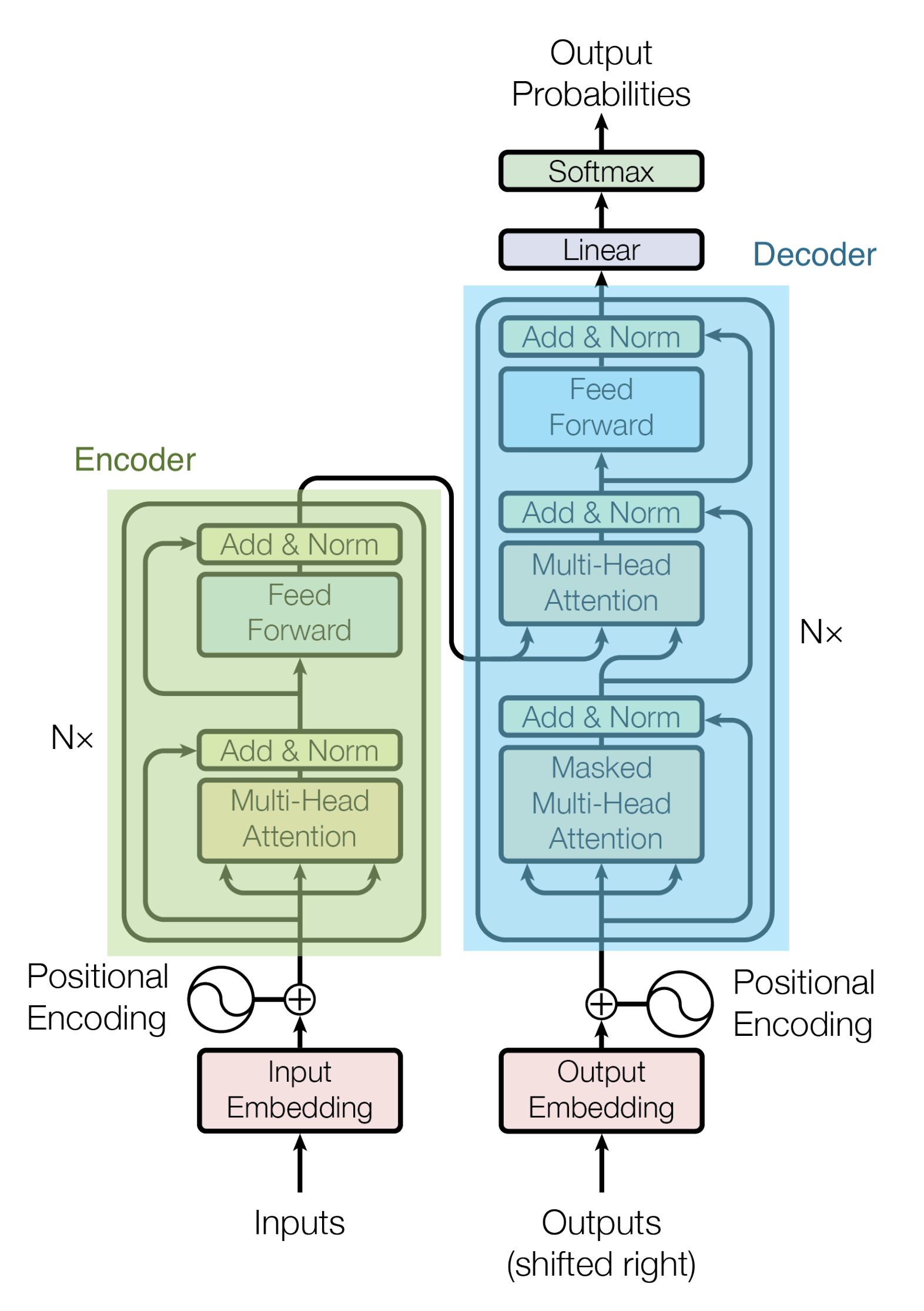
Sebuah Encoder terdiri dari setumpuk Encoder. Dalam makalah ini, enam Encoder ditumpuk. (Jumlah lain dapat dicoba.) Sebuah Decoder juga terdiri dari tumpukan 6 Decoder.
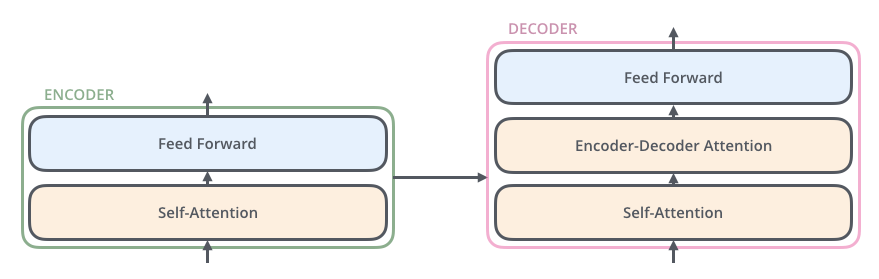
Encoder dan Decoder terdiri dari Multi-Head Attention dan Feed Forward (lapisan affine).
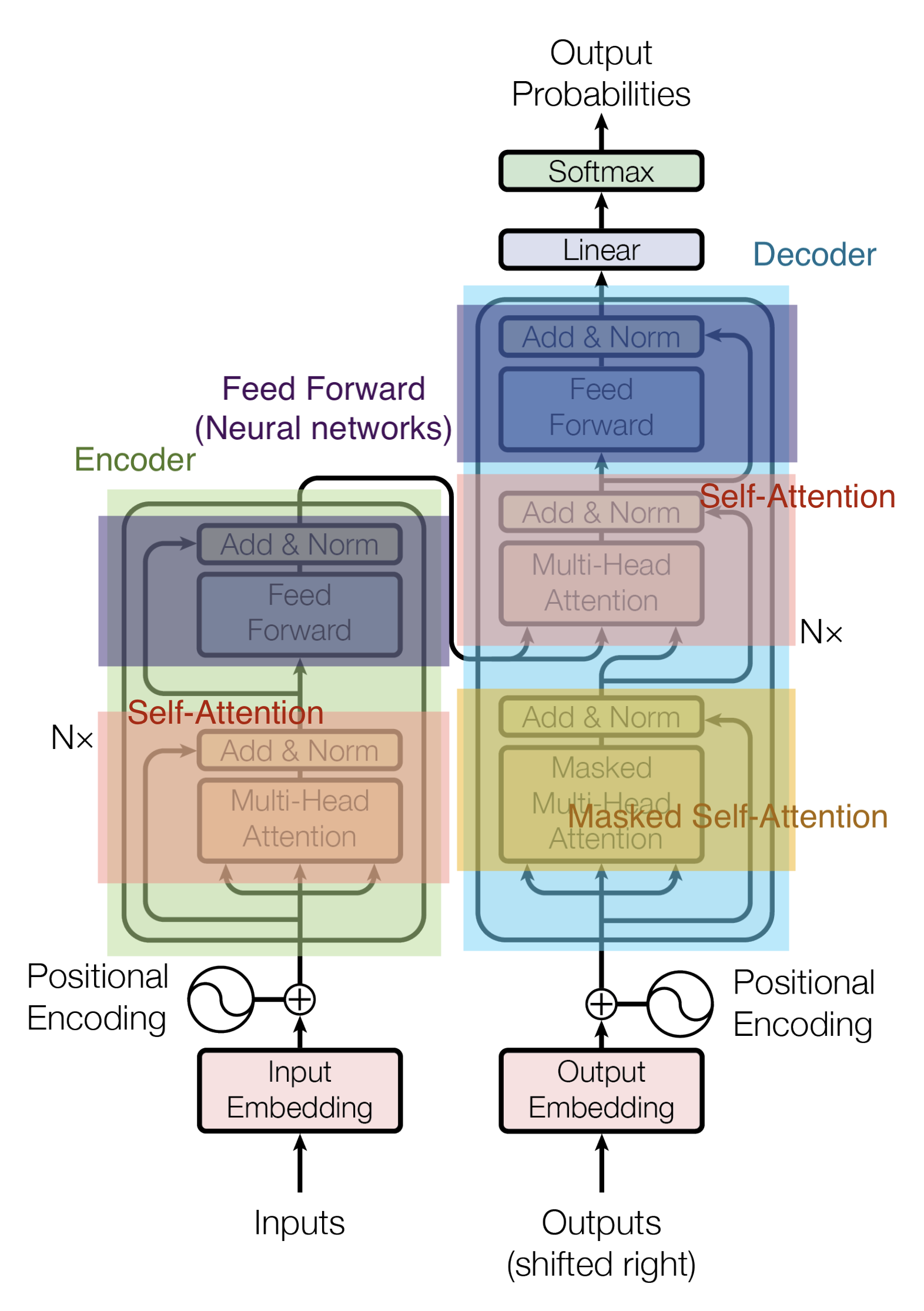
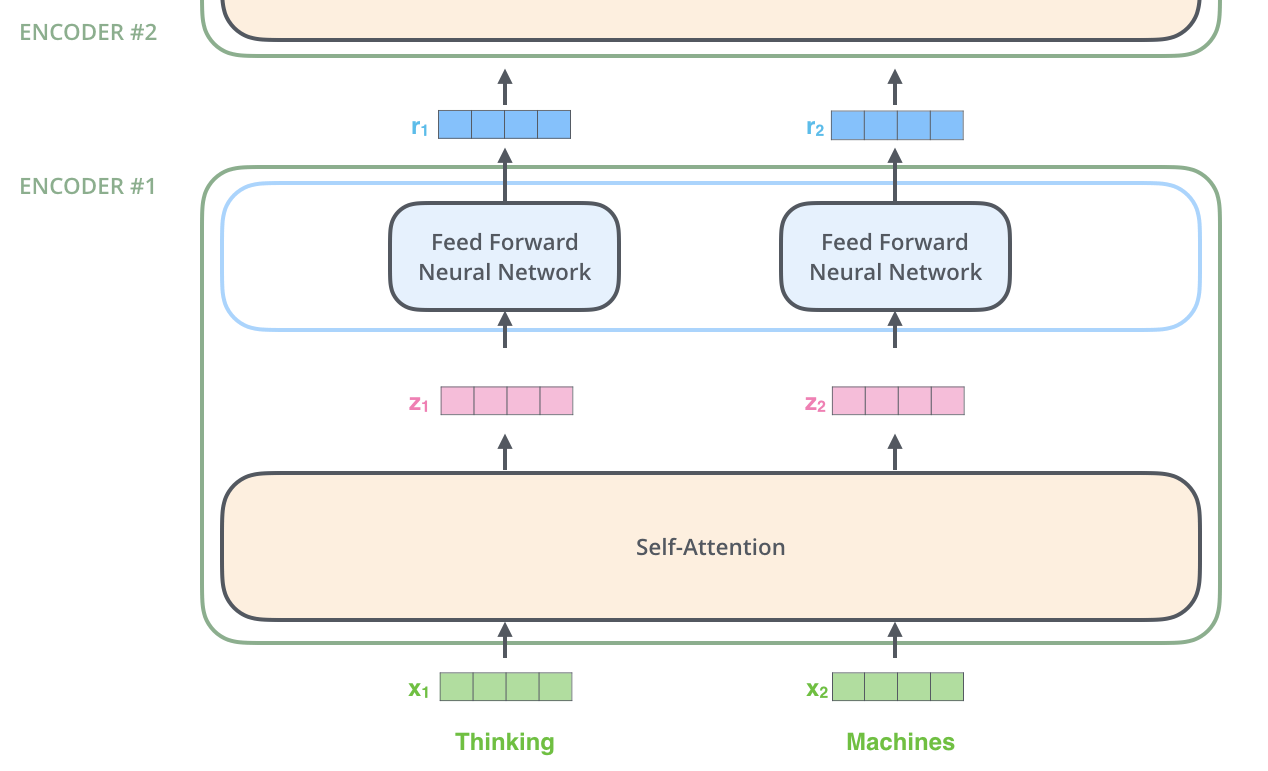
Masukan ke Encoder pertama-tama melewati Self-Attention dan kemudian melalui lapisan Feed Forward.
Decoder berisi lapisan Self-Attention dan Feed Forward, tetapi di antaranya terdapat Attention, yang membantu menentukan di mana dalam urutan input untuk memusatkan perhatian. (Attention Encoder-Decoder pada gambar di bawah ini memainkan peran yang sama dengan Attention pada model Seq2seq).
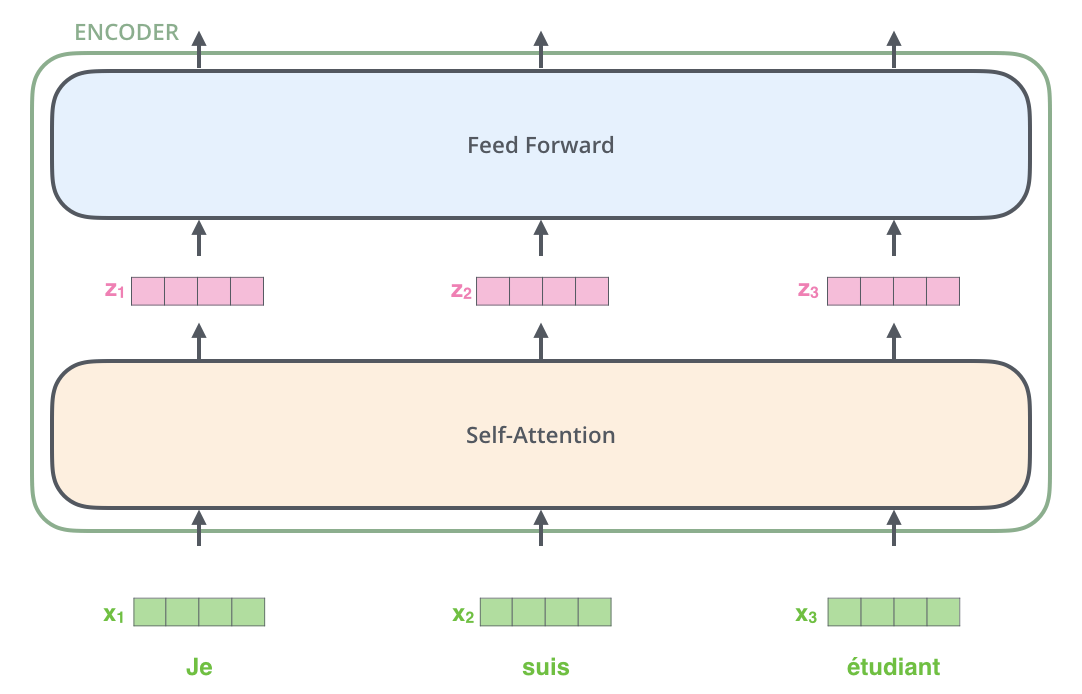
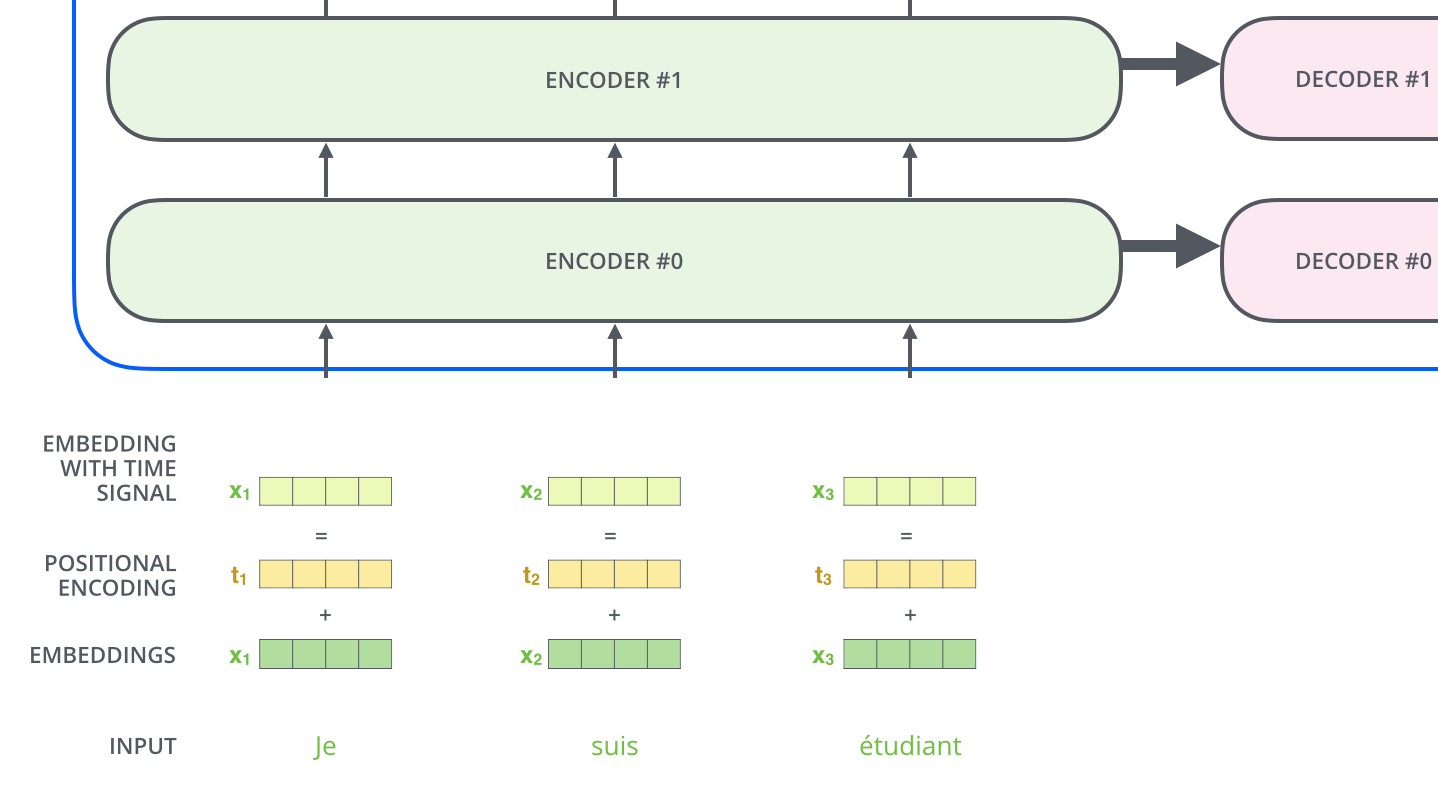
Di sini, setiap kata masukan diubah menjadi vektor penyisipan dengan ukuran 512 sebelum diteruskan ke Encoder atau Decoder. Berikut ini, vektor penyisipan diwakili oleh empat kotak sederhana.

Proses penyematan kata terjadi sebelum baris bawah Encoder. Secara umum, semua Encoder menerima daftar vektor, masing-masing berukuran 512. Ukuran daftar ini dapat dikonfigurasi sebagai hiperparameter dan pada dasarnya adalah panjang kalimat terpanjang dalam kumpulan data pelatihan.
Setiap vektor penyisipan kata melewati Encoder.
Di sini, salah satu sifat penting dari Transformer adalah bahwa kata-kata di setiap posisi mengalir melalui jalurnya masing-masing di Encoder; di lapisan Self-Attention, ada ketergantungan antara jalur-jalur ini, sedangkan di lapisan Feed Forward tidak ada ketergantungan seperti itu. Oleh karena itu, berbagai jalur dapat dieksekusi secara paralel saat mengalir melalui Feed Forward Layer.
Encoder
Encoder mengambil masukan berupa daftar vektor penyisipan kata, yang diteruskan ke lapisan Self-Attention, lalu ke lapisan Feed Forward, dan kemudian ke Encoder berikutnya untuk keluaran.
Self-Attention
Tidak seperti lapisan Attention yang digunakan dalam Seq2seq (yang memperoleh korespondensi antara data yang berbeda), lapisan Self-Attention memperoleh informasi tentang korespondensi antara kata-kata dalam data input.
| Korespondensi | Attention | |
|---|---|---|
| Attention Konvensional | I am a student <=> Je suis un étudiant | "I" memperoleh korespondensi antara "Je" dan "étudiant" khususnya |
| Self-Attention | I am a student <=> I am a student | "I" memperoleh korespondensi antara "I" dan "memiliki" khususnya |
Sebagai contoh, misalkan Anda ingin menerjemahkan kalimat masukan berikut ini.
The animal didn't cross the street because it was too tired
Memahami apa yang dimaksud dengan "it" dalam kalimat di atas adalah hal yang mudah bagi manusia, tetapi sulit bagi mesin.
Self-Attention memungkinkan model untuk mengasosiasikan "it" dengan "animal" ketika memproses kata "it".
Sebagai contoh, Encoder#5 (Encoder teratas) menyandikan kata "it"; bagian dari Attention berfokus pada "animal" dan memasukkan beberapa representasinya ke dalam penyandian kata "it".

Dengan demikian, Self-Attention memungkinkan kita untuk mendapatkan kesamaan dalam kalimat yang sama dan memahami dengan benar apa yang dimaksud, terutama dalam hal polisemi dan kata ganti.
Selain itu, Self-Attention membutuhkan lebih sedikit perhitungan. Di bawah ini adalah tabel yang digunakan dalam makalah ini. Di mana

Self-Attention diimplementasikan dengan urutan sebagai berikut.
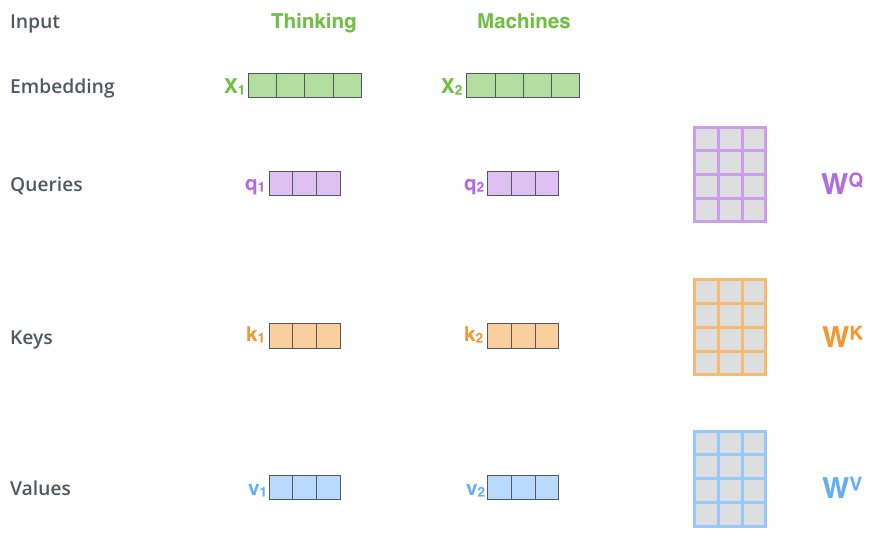
- Buat vektor Query, vektor Key, dan vektor Value
- Hitung nilai dari vektor penyisipan kata masukan
- Bagi skor dengan akar kuadrat dari dimensi vektor Key
- Hitung skor Softmax
- Kalikan setiap vektor Value dengan skor Softmax
- Tambahkan vektor-vektor Value yang telah dibobotkan
Langkah pertama dalam mengimplementasikan Self-Attention adalah membuat tiga vektor berikut untuk setiap kata dari setiap vektor input Encoder (penyisipan setiap kata)
- Vektor Query
- Vektor Key
- Vektor Value
Vektor-vektor ini dibuat dengan mengalikan matriks vektor penyisipan
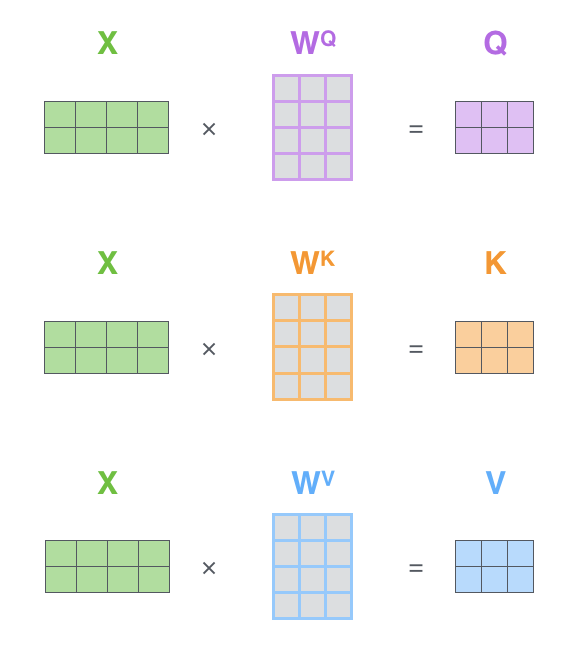
Vektor baru ini memiliki dimensi yang lebih kecil daripada vektor tertanam. Dimensi vektor tertanam dan vektor input/output Encoder adalah 512, sedangkan dimensi vektor yang baru dibuat adalah 64. Ini adalah arsitektur untuk menjaga komputasi Multi-Head Attention tetap konstan.
Pada gambar di bawah ini, dimensi vektor baru adalah 3.
Mengalikan
Langkah kedua dalam mengimplementasikan Self-Attention adalah menghitung skor. Dalam contoh kita, kita ingin menghitung Self-Attention untuk kata pertama "Berpikir". Untuk kata ini, kita perlu memberi skor pada setiap kata dalam kalimat input. Skor menentukan seberapa besar fokus yang diberikan kepada bagian lain dari kalimat input ketika mengkodekan kata pada posisi tertentu.
Skor dihitung dengan mengambil hasil perkalian antara vektor Query dan vektor Key dari kata yang diinginkan. Artinya, jika kita memproses Self-Attention untuk kata pada posisi 1, skor pertama adalah hasil kali dalam dari
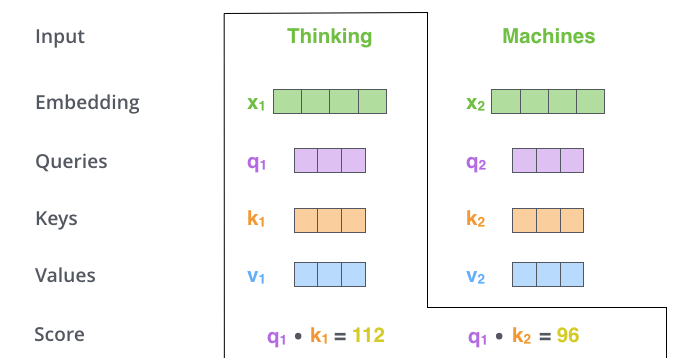
Pada langkah ketiga dan keempat, skor dibagi dengan 8. Angka 8 berasal dari akar kuadrat dimensi vektor Key yang digunakan dalam kertas. Proses ini memungkinkan gradien yang lebih stabil untuk dipertahankan. Nilai lain dapat ditentukan, tetapi akar kuadrat dari dimensi vektor Key adalah nilai default. Hasilnya kemudian diteruskan ke Softmax, yang mengambil semua nilai positif dan menormalkan skor sehingga berjumlah 1.
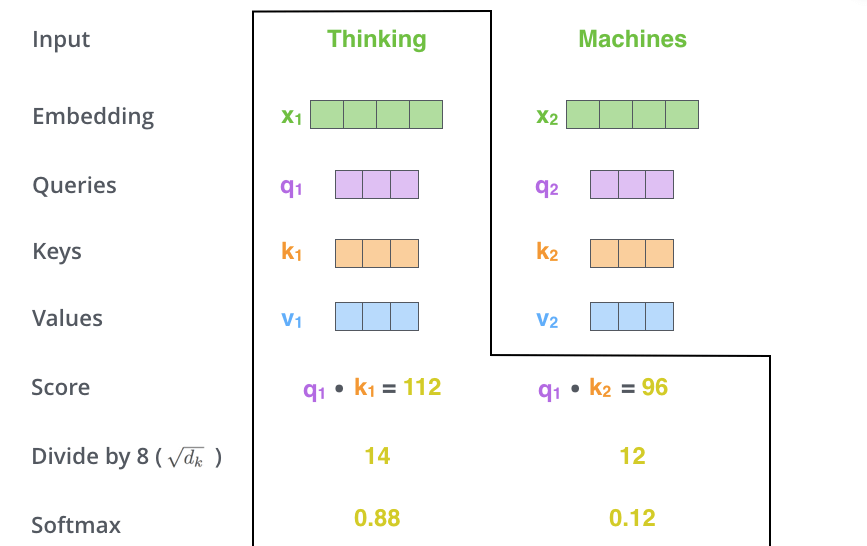
Skor Softmax ini menentukan seberapa baik setiap kata diwakili dalam posisi ini. Sering kali, kata pada posisi yang sedang diproses akan memiliki skor Softmax tertinggi, tetapi terkadang berguna untuk fokus pada kata lain yang terkait dengan kata yang sedang diproses.
Pada langkah kelima, setiap vektor Value dikalikan dengan skor Softmax. Proses ini membuat nilai dari kata yang menarik tetap utuh dan menenggelamkan kata-kata yang tidak relevan.
Pada langkah terakhir, vektor-vektor Value yang telah dibobotkan dijumlahkan. Proses ini menghasilkan output dari lapisan Self-Attention untuk posisi yang sedang diproses (untuk kata pertama pada contoh di bawah ini).
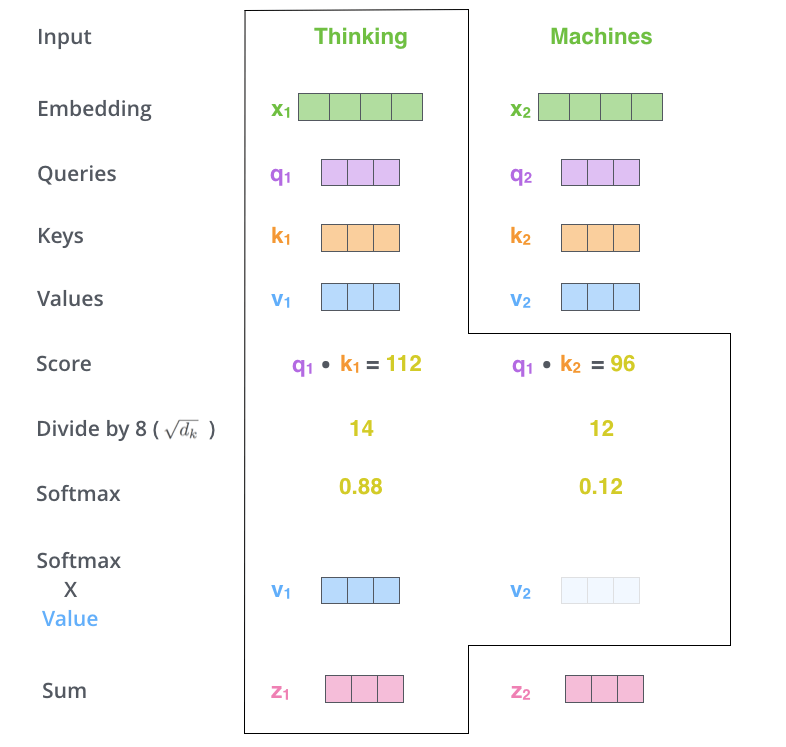
Vektor-vektor yang dihasilkan
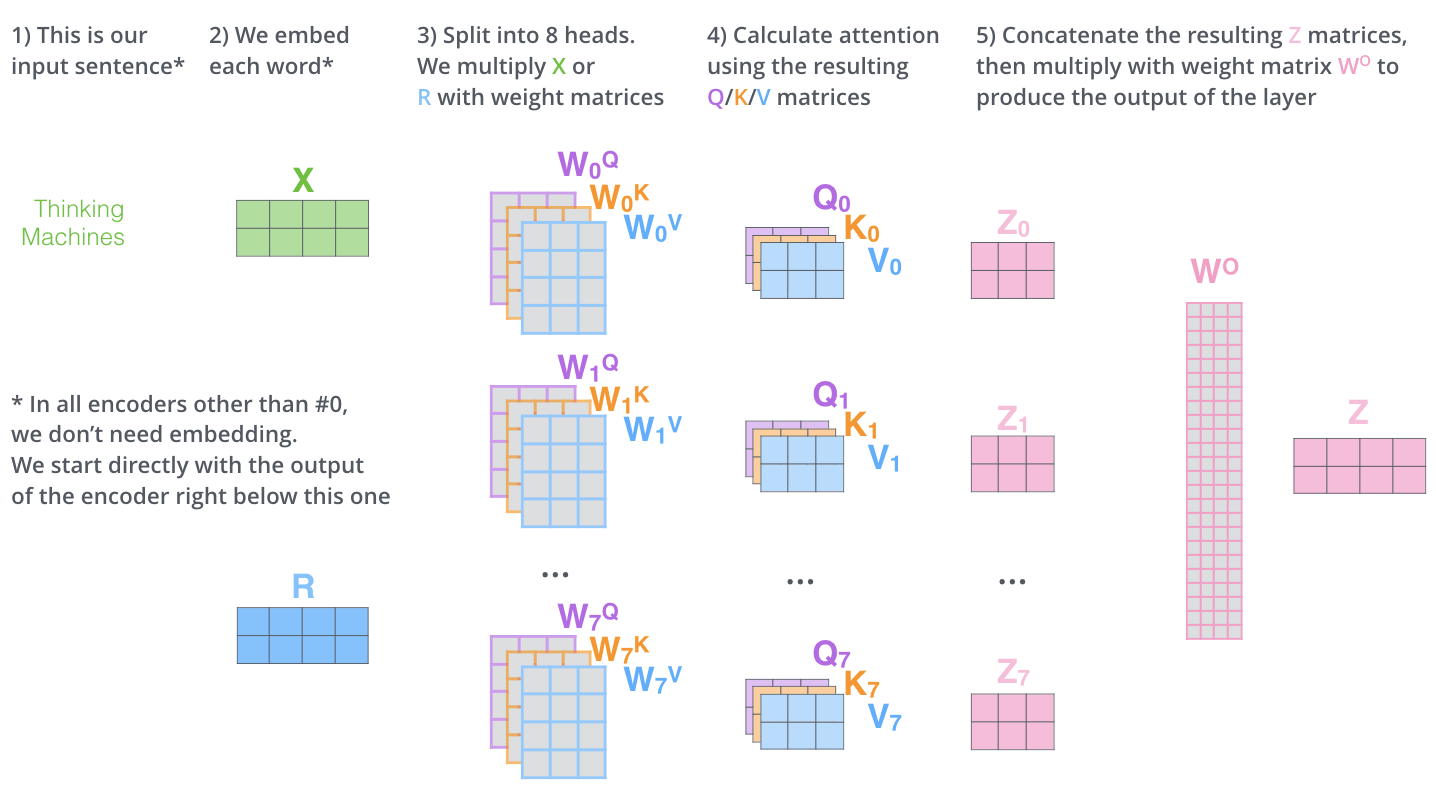
Multi-Head Attention
Makalah ini lebih lanjut menyempurnakan lapisan Self-Attention dengan menambahkan mekanisme yang disebut Multi-Head Attention, yang merupakan bagian terpenting dari mekanisme Transformer. Mekanisme ini memecahkan dua masalah dari model konvensional: "tidak ada memori jangka panjang" dan "tidak ada paralelisasi.
Multi-Head Attention memperluas kemampuan untuk fokus pada lokasi yang berbeda dalam model. Pada contoh di atas,
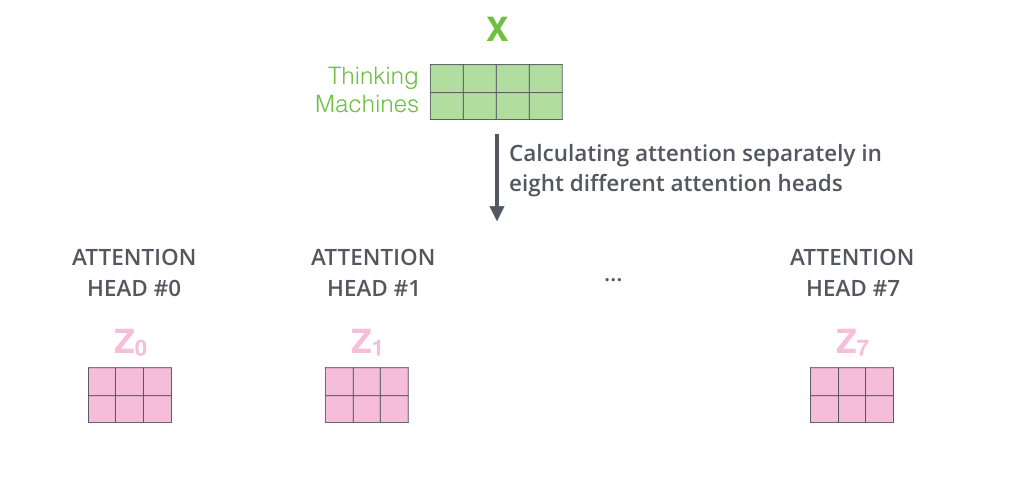
Selain itu, Multi-Head Attention mempertahankan matriks bobot Query/Key/Value yang terpisah, sehingga menghasilkan matriks Query/Key/Value yang berbeda. Karena Transformer menggunakan delapan Attention, delapan set Query/Key/Value diperlukan untuk setiap Encoder dan Decoder.
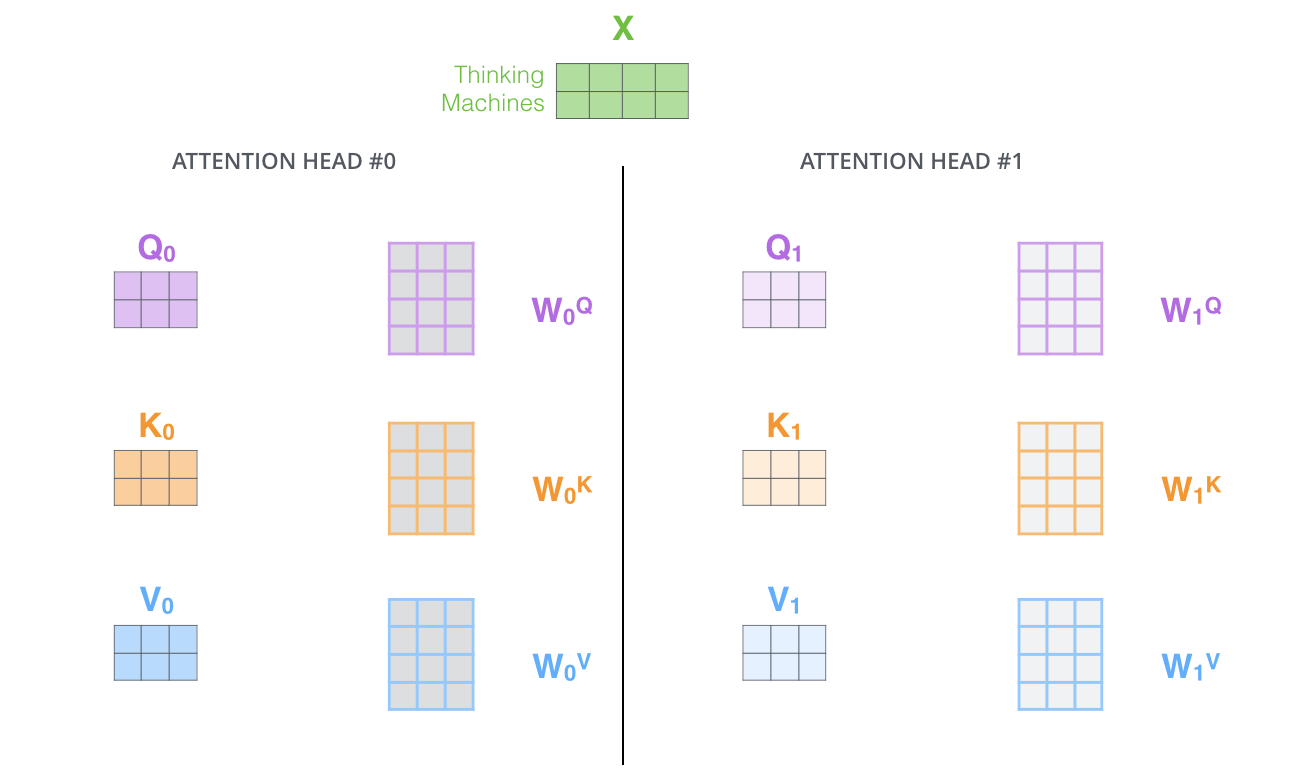
Melakukan perhitungan Self-Attention sebanyak delapan kali dengan matriks bobot yang berbeda menghasilkan delapan matriks
Lapisan Feed Forward mengharapkan satu matriks (vektor dari setiap kata), bukan 8 matriks. Oleh karena itu, gabungkan matriks-matriks tersebut dan kalikan dengan menambahkan matriks bobot
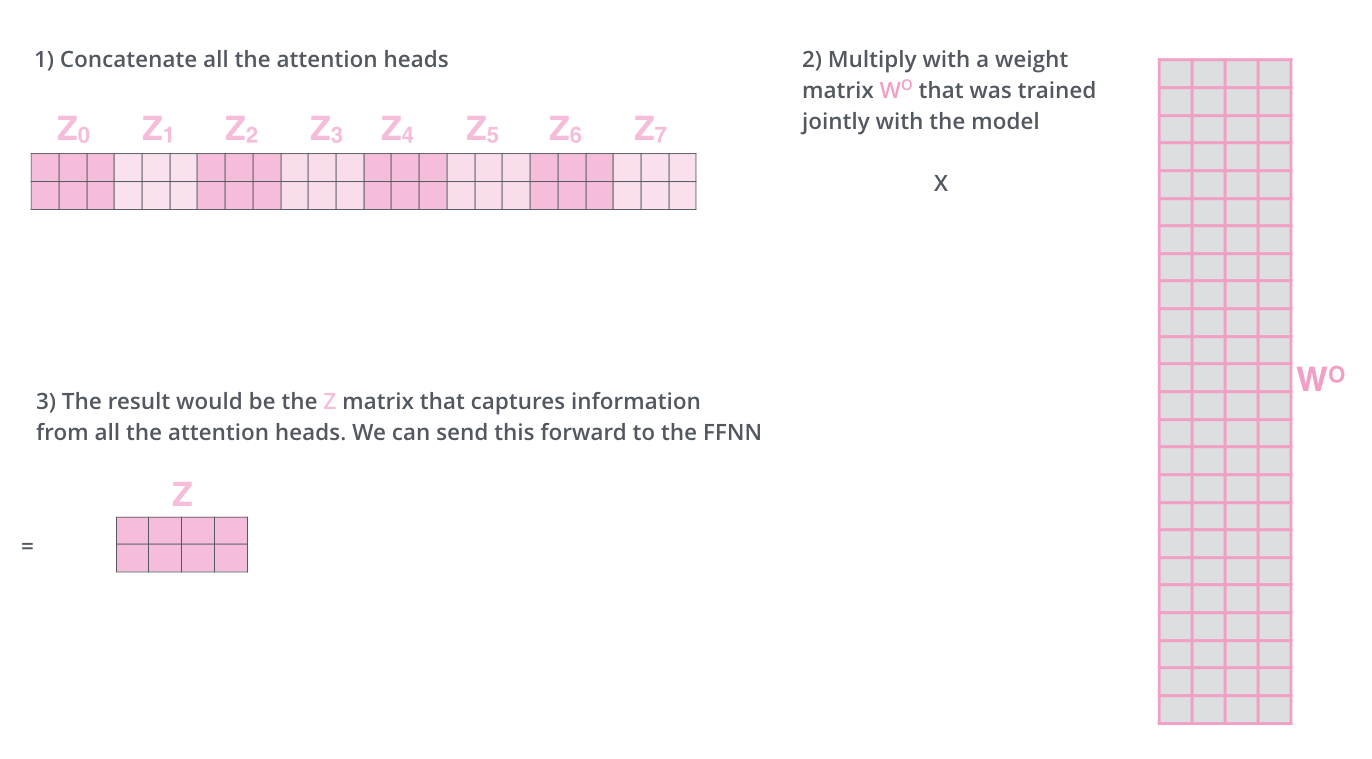
Operasi matriks Multi-Head Attention dapat diringkas dalam satu visual sebagai berikut
Lihat di mana Self-Attention yang berbeda difokuskan ketika mengkodekan kata "it" dalam contoh kalimat sebelumnya.

Ketika mengkodekan kata "it," satu Self-Attention (Self-Attention berwarna merah) memberikan perhatian paling besar pada "binatang" dan Self-Attention lainnya (Self-Attention berwarna hijau) memberikan perhatian paling besar pada "tired". Dalam arti tertentu, representasi model dari kata "it" dapat diartikan sebagai penggabungan bagian dari representasi "animal" dan "tired".
Feed Forward
Lapisan Feed Forward adalah jaringan saraf tiruan dua lapis yang terdiri dari lapisan perantara 2048 dimensi dan lapisan keluaran 512 dimensi yang diaktifkan oleh ReLU. Persamaannya adalah sebagai berikut
Positional Encoding
Karena Transformer tidak menggunakan RNN, maka Transformer tidak lagi dapat memperoleh "konteks" yang sebelumnya menjadi tanggung jawab RNN. Sebagai contoh, "Saya suka kucing" dan "kucing suka saya" menjadi hal yang sama.
Lapisan Positional Encoding adalah mekanisme yang diperkenalkan untuk memecahkan masalah di atas dan menambahkan informasi posisi ke setiap elemen dalam sebuah kalimat. Dengan menambahkan informasi posisi, meskipun setiap data elemen diproses secara paralel, dimungkinkan untuk mempertahankan informasi hubungan dengan elemen sebelumnya dan selanjutnya dalam kalimat yang dimiliki oleh data input.
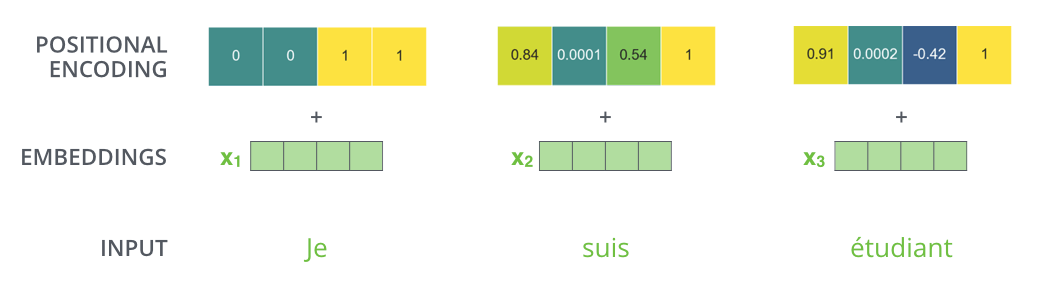
Dalam praktiknya, Positional Encoding memberikan informasi posisi dengan menyematkan nilai fungsi sin dan cos, yang memiliki frekuensi yang berbeda, ke dalam sebuah vektor.
Dengan mengasumsikan bahwa jumlah dimensi penyematan adalah 4, nilai aktual vektor Pengkodean Posisi adalah sebagai berikut.
Decoder
Di dalam Decoder, rangkaian input pertama kali diproses. Output dari Encoder paling atas kemudian diubah menjadi satu set vektor Key dan Value. Ini digunakan oleh setiap Decoder untuk Encoder-Decoder Attention dan membantu Decoder untuk fokus pada tempat yang tepat dalam rangkaian input.
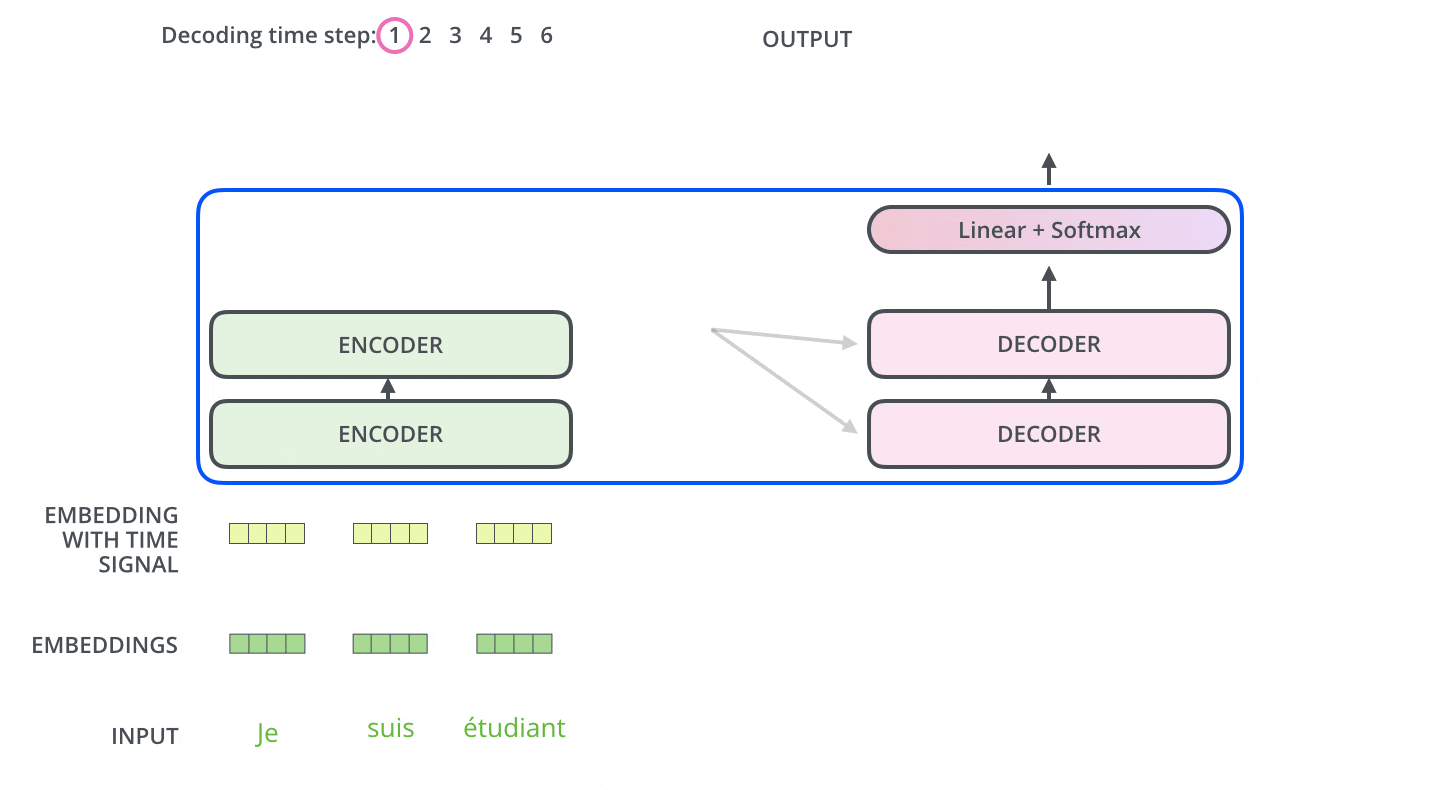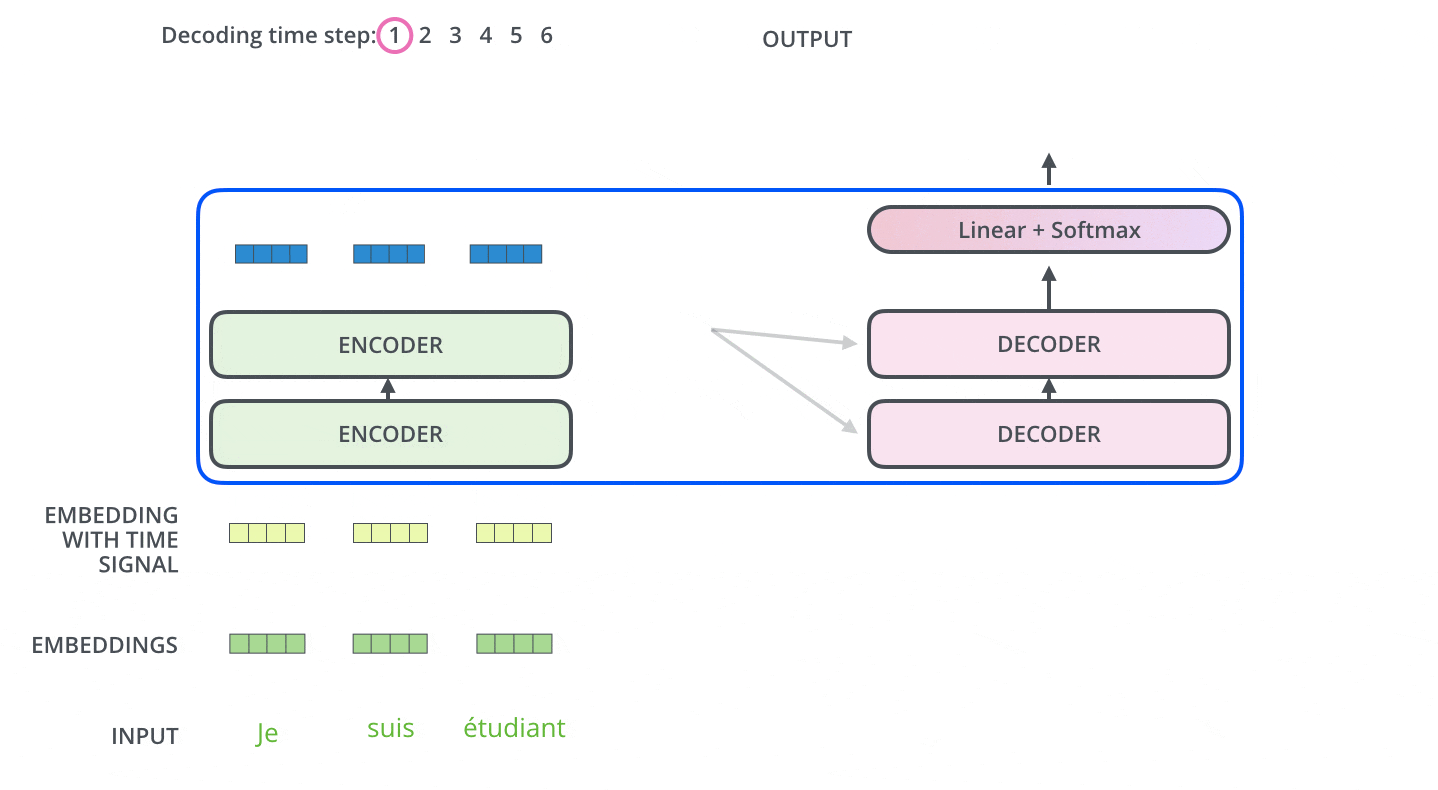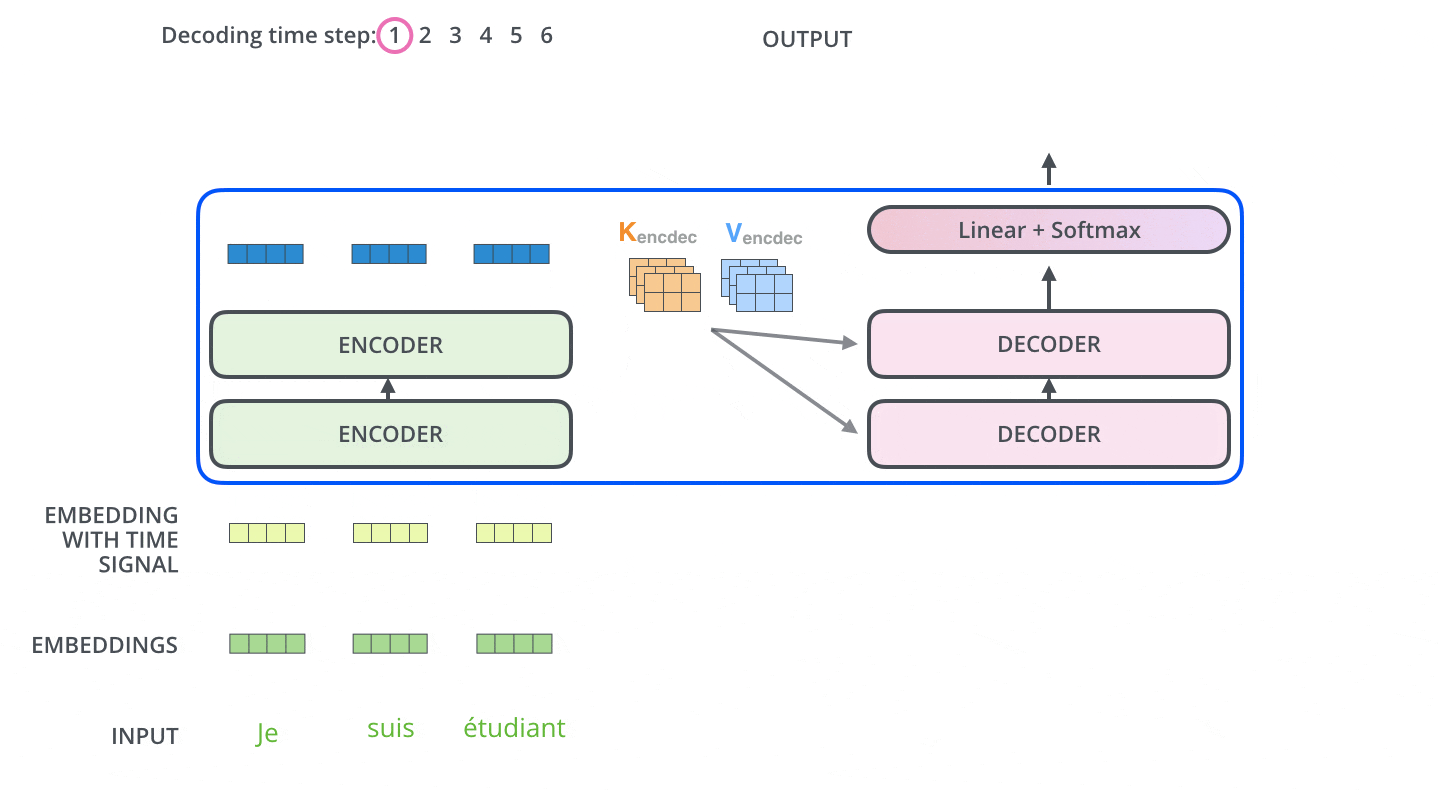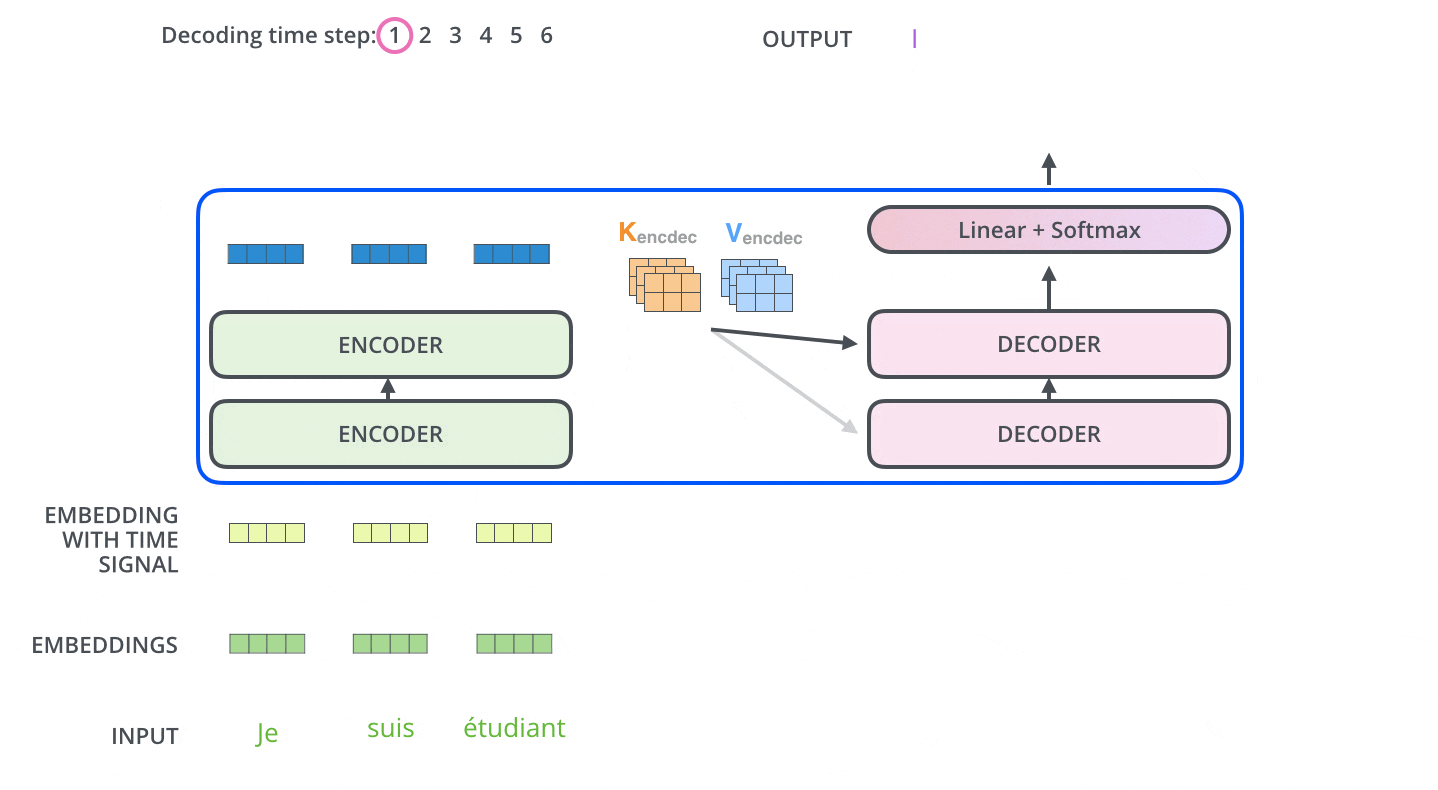
Setelah penyandian selesai, penguraian kode dimulai. Setiap langkah pengodean menghasilkan satu elemen dari rangkaian output (dalam hal ini, terjemahan bahasa Inggris).
Pada langkah berikutnya, Dekoder Transformer mengulangi proses tersebut hingga mencapai simbol khusus yang menunjukkan bahwa output telah selesai. Output dari setiap langkah diumpankan ke Decoder bawah pada langkah waktu berikutnya, yang kemudian mengirimkan hasil yang diterjemahkan ke Decoder atas. Dengan demikian, ia menambahkan vektor pengkodean posisi ke input Decoder untuk menunjukkan posisi setiap kata, mirip dengan apa yang dilakukan dengan input Encoder.
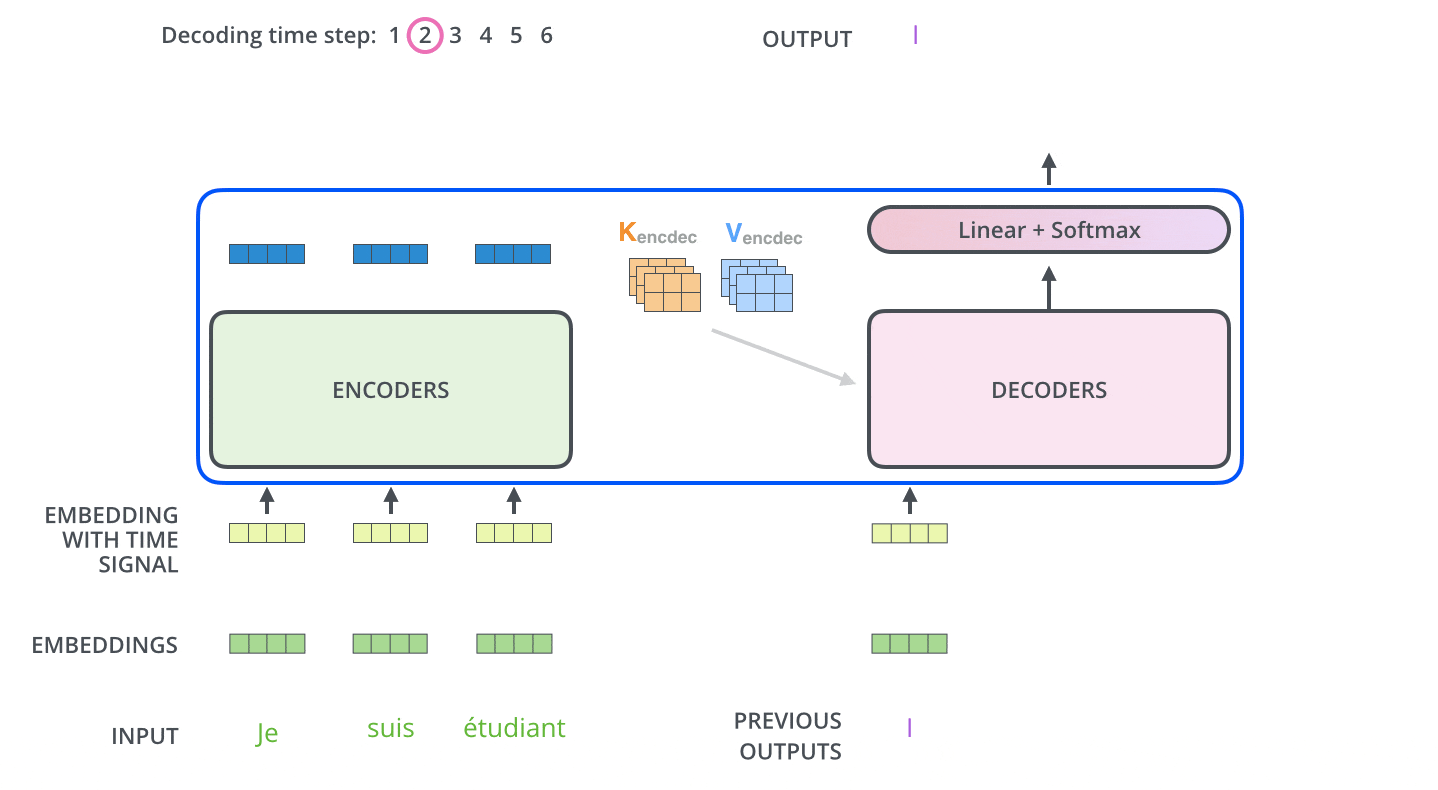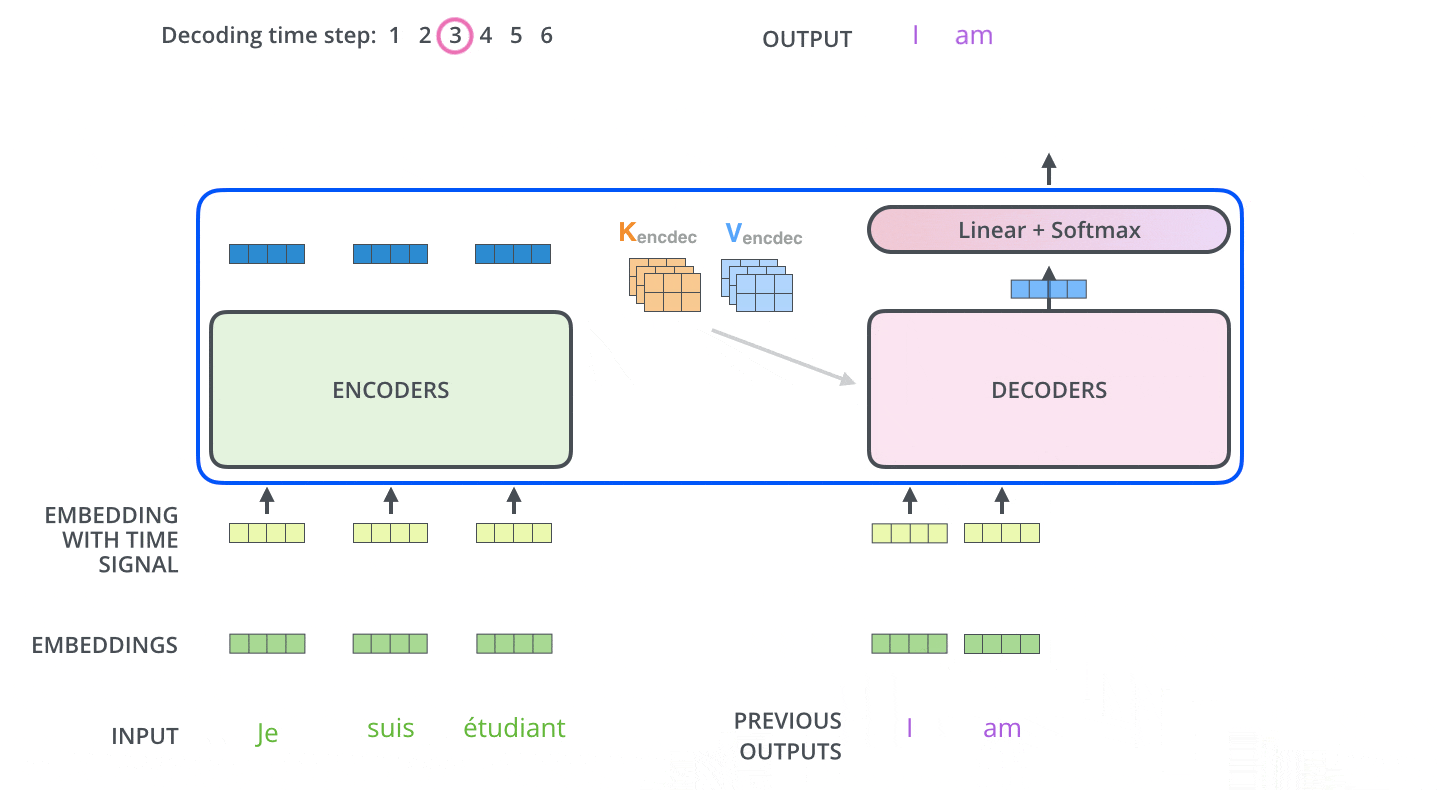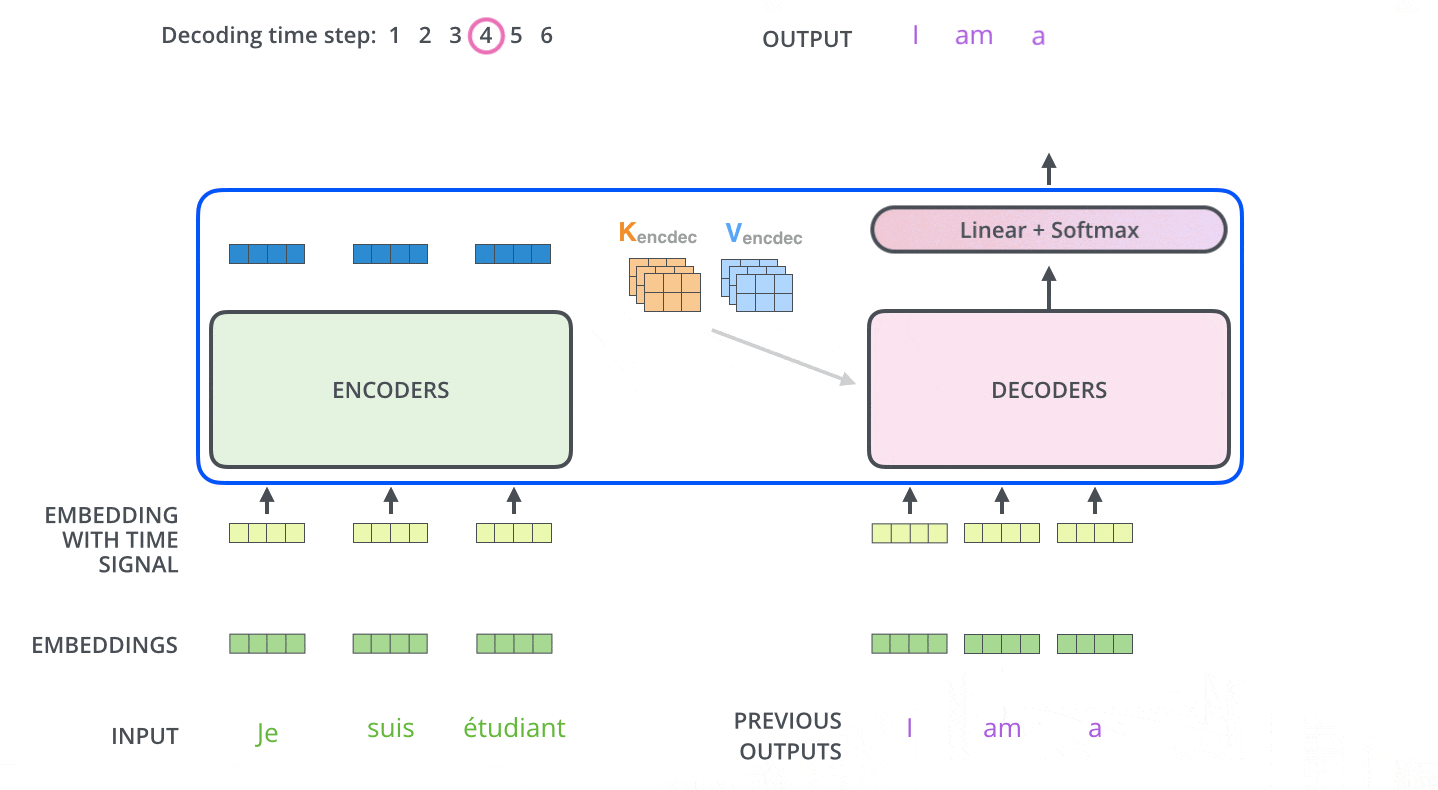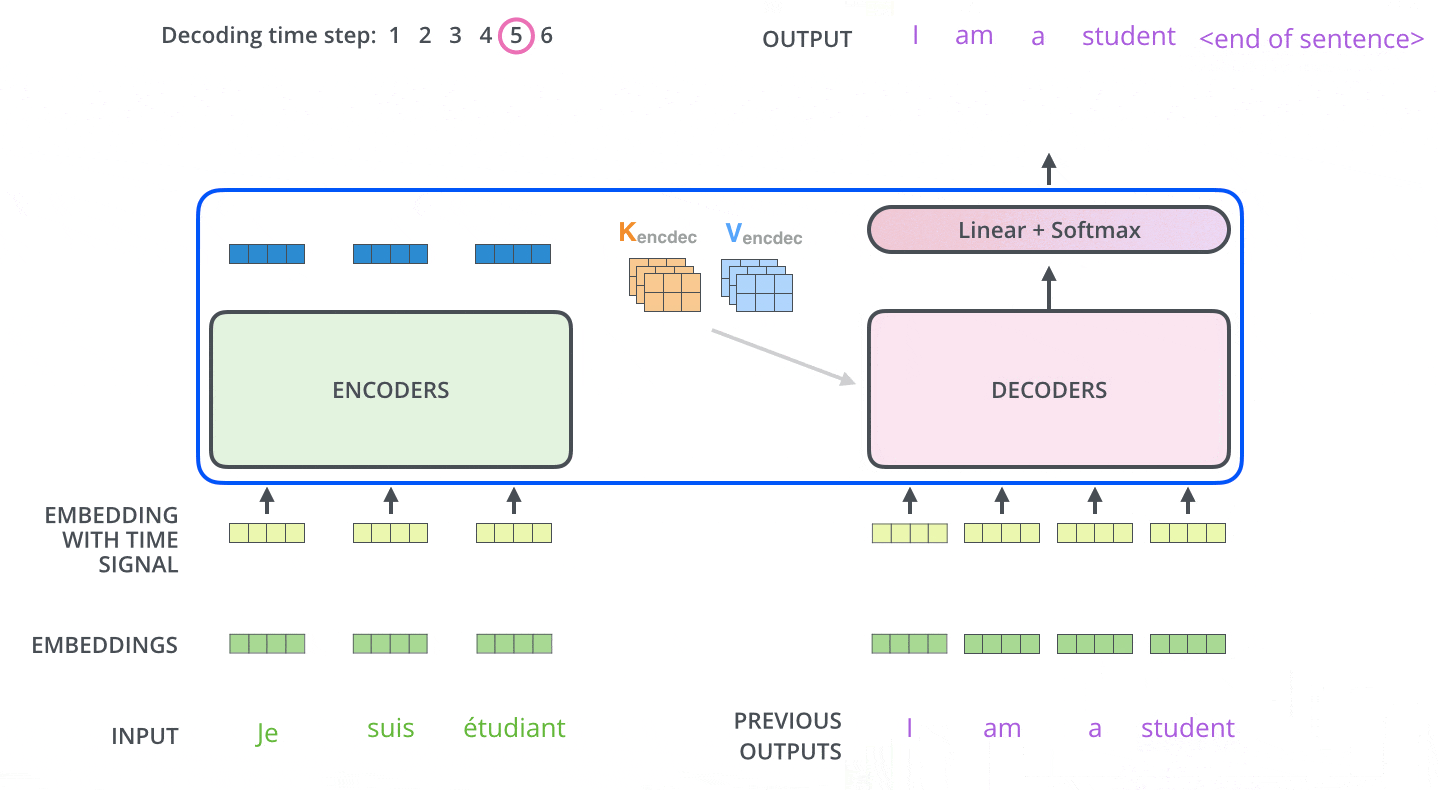
Masked Multi-Head Attention
Multi-Head Attention pertama dari Decoder adalah Masked Multi-Head Attention, yang menutupi informasi yang seharusnya tidak digunakan (misalnya, mengganti beberapa kata dalam kalimat masukan dengan tanda hubung).
Masukan ke Decoder selama pelatihan adalah urutan kata yang diterjemahkan, tetapi urutan kata yang diterjemahkan harus dibuat secara berurutan dari depan, dan ketika memprediksi kata yang diterjemahkan ke-i, hanya informasi hingga kata ke-i-1 yang harus digunakan.
Tanpa masking, hal ini akan menjadi curang, karena penebak harus melihat jawaban dari kata sebelumnya dan juga kata sebelum kata tersebut.
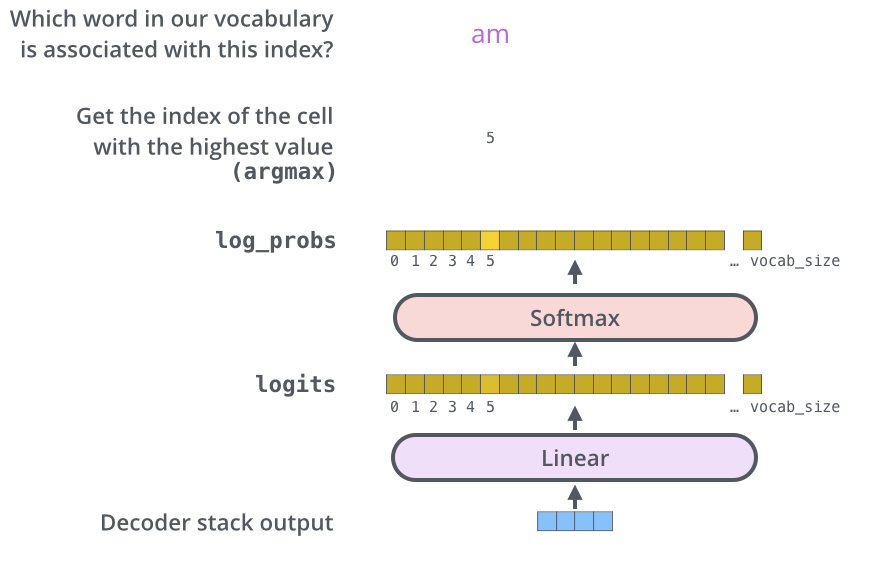
Linear dan Softmax
Sebuah vektor dikeluarkan oleh Decoder. Vektor ini diubah menjadi kata-kata oleh lapisan Linear dan Softmax.
Lapisan Linear adalah jaringan all-join sederhana yang mengubah keluaran vektor dari Decoder menjadi vektor yang disebut vektor logit. Sebagai contoh, dengan asumsi model telah mempelajari 10.000 kata bahasa Inggris dari dataset pelatihan, vektor logit akan memiliki lebar 10.000 sel.
Lapisan Softmax mengubah vektor logit menjadi probabilitas. Sel dengan probabilitas tertinggi dipilih dan kata yang terkait dihasilkan sebagai output untuk langkah waktu ini.
Kerangka kerja Transformator
Model transformer dapat dengan mudah diimplementasikan menggunakan kerangka kerja Transformers yang disediakan oleh Hugging Face.
Transformers` adalah modul Python untuk pustaka pembelajaran mendalam yang populer seperti PyTorch dan TensorFlow.
Kemajuan Transformer
Terdapat dua model AI pemahaman bahasa utama berdasarkan Transformer.
- BERT
- Seri GPT
Notebook Colab untuk Transformer
Notebook Google Colab berikut ini memberikan pemahaman visual tentang kata-kata yang menjadi fokus perhatian Transformer.
Notebook yang disertakan dengan Tensorflow
VizBERT
Referensi

















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS