


Apa itu DistilBERT
DistilBERT adalah model yang muncul dalam makalah yang berjudul DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter.
DistilBERT adalah model Transformer yang didasarkan pada BERT. DistilBERT memiliki parameter 40% lebih sedikit, berjalan 60% lebih cepat, dan dapat mempertahankan 97% kinerja BERT yang diukur oleh GLUE Benchmark.
DistilBERT dilatih menggunakan Knowledge Distillation, sebuah teknik yang memampatkan model besar yang disebut Teacher menjadi model yang lebih kecil yang disebut Student. Distilasi BERT menghasilkan model Transformer yang memiliki banyak kemiripan dengan model BERT asli, tetapi lebih ringan dan lebih cepat dijalankan.
Latar Belakang DistilBERT
Dalam NLP baru-baru ini, telah menjadi praktik umum untuk membuat model bahasa yang sangat akurat dengan melakukan pra-pelatihan sejumlah besar parameter pada data yang tidak berlabel. Seri BERT dan GPT, misalnya, menjadi semakin besar dan besar, dan komputasi satu sampel membutuhkan waktu yang sangat lama sehingga terlalu intensif secara komputasi untuk rata-rata pengguna.
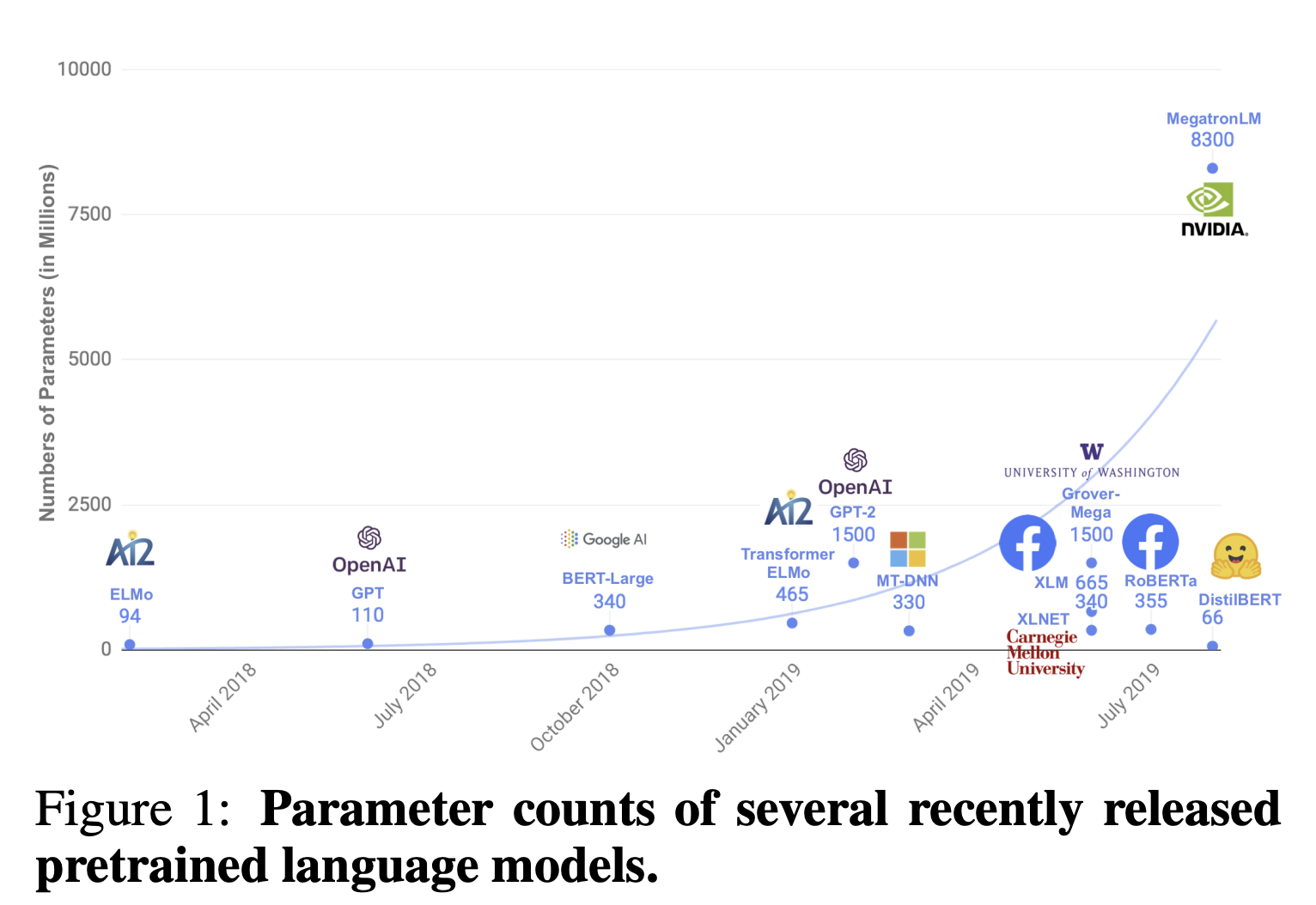
Oleh karena itu, tujuan dari makalah ini adalah untuk menciptakan model yang lebih ringan dengan tetap mempertahankan akurasi.
Knowledge Distillation
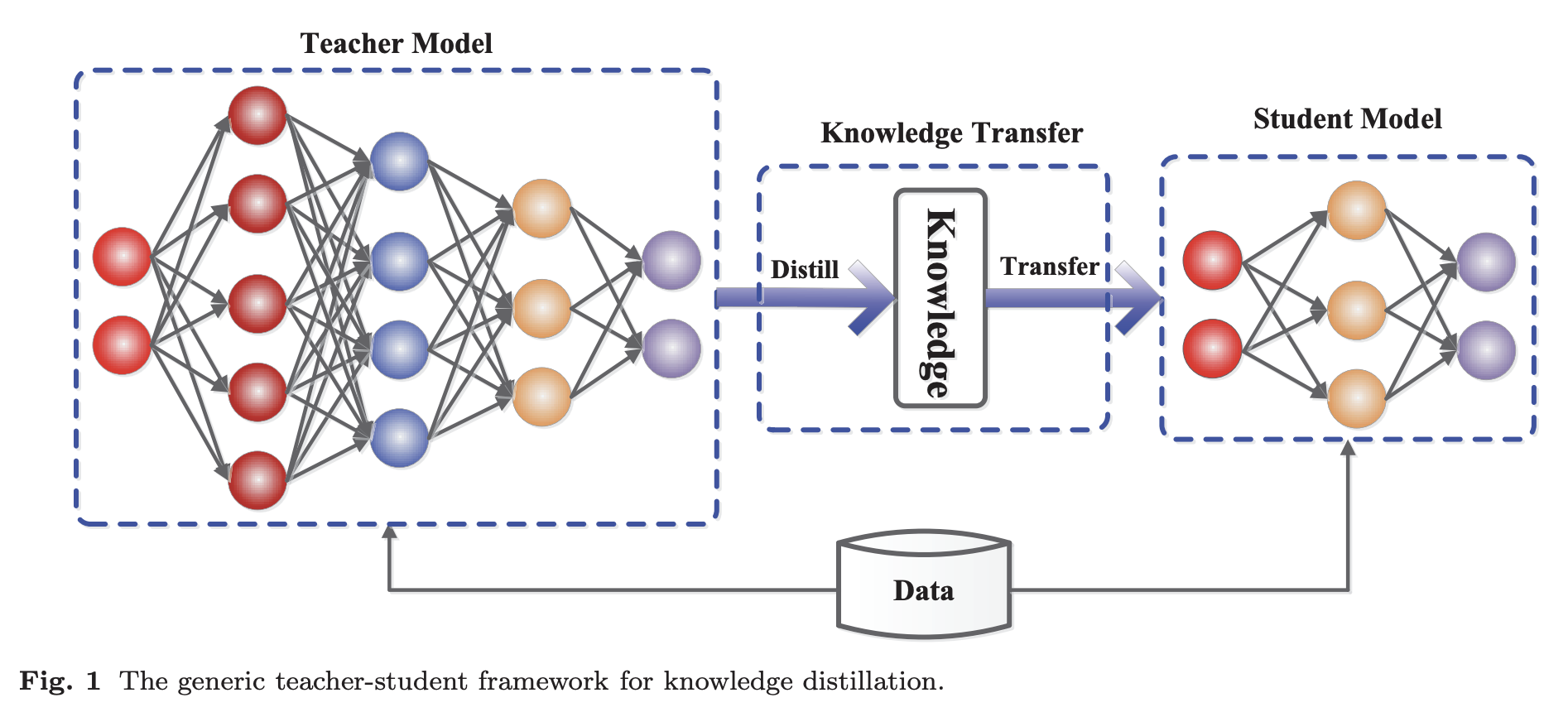
Knowledge Distillation adalah teknik yang muncul pada tahun 2015 dalam makalah Distilling the Knowledge in a Neural Network. Idenya adalah untuk memampatkan dan mentransfer pengetahuan dari model yang besar dan mahal secara komputasi (model Teacher) ke model yang lebih kecil (model Student) dengan tetap mempertahankan validitas.
Student dilatih untuk mereproduksi perilaku Teacher. Namun, model Student tidak memiliki memori (jumlah parameter) sebesar model Teacher, sehingga model Student berusaha sedekat mungkin dengan model Teacher dengan memorinya yang kecil.
-
Model Teacher
Ansambel model yang sangat besar atau model yang dilatih secara individual dengan regularisasi yang kuat, seperti putus sekolah. -
Model Student
Model kecil yang mengandalkan pengetahuan yang disaring dari model Teacher
Knowledge Distillation: A Survey
Dalam DistilBERT, Teacher mengacu pada BERT dan Student mengacu pada DistilBERT.
Struktur DistilBERT
Arsitektur Student
DistilBERT sebagai Student mengikuti arsitektur umum yang sama dengan BERT. DistilBERT mengambil langkah-langkah berikut untuk mengurangi parameter:
- Penghapusan lapisan penyematan Token
- Penghapusan lapisan Pooler (lapisan untuk klasifikasi setelah Transformer Encoder)
- Mengurangi separuh jumlah lapisan Transformer (BERT_BASE: 12, DistilBERT: 6)
Langkah-langkah ini akan menghasilkan pengurangan 40% dalam jumlah parameter.
Nilai awal untuk Student
Parameter BERT, Teacher, digunakan sebagai nilai awal untuk Student. Namun, karena jumlah lapisan Student adalah setengah dari jumlah lapisan Teacher, salah satu dari dua lapisan yang sesuai digunakan sebagai nilai awal.
Distillation
DistilBERT mengatur metode pembelajaran sebagai berikut:
- Tingkatkan ukuran batch menjadi 4.000
- Masking dilakukan secara dinamis
- Prediksi Kalimat Berikutnya tidak dilakukan
Fungsi Kerugian Pelatihan
Fungsi kerugian DistilBERT adalah kombinasi linier dari Distillation Loss (
Distillation Loss
Distillation Loss (
dimana
Fungsi kerugian dalam persamaan di atas memungkinkan kita untuk meniru tidak hanya kata dengan probabilitas prediksi tertinggi, tetapi juga kata dengan probabilitas prediksi tertinggi berikutnya, dan seterusnya, sehingga dapat mempelajari distribusi yang diprediksi oleh Teacher.
Sebagai contoh, perhatikan kalimat berikut.
I watched [MASK] yesterday.
Misalkan probabilitas yang diprediksi dari BERT, Teacher, adalah sebagai berikut
| Kata yang diprediksi | Probabilitas yang diprediksi |
|---|---|
| movie | 0.8 |
| TV | 0.1 |
| baseball | 0.05 |
| MMA | 0.05 |
Dalam kasus ini, Student tidak hanya mempelajari "film" tetapi juga "TV", "MMA", dan "baseball" sehingga probabilitas prediksinya lebih mendekati probabilitas prediksi Teacher, BERT.
Namun, di sini probabilitas prediksi softmax-temperature.
Jika
Dengan menggunakan softmax-temperature, fungsi ini belajar untuk memprediksi kata-kata dengan probabilitas rendah.
Masked Language Model Loss
Masked Language Modelling Loss (
Cosine Embedding Loss
Cosine Embedding Loss (
Referensi
















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS