
Apa itu Tradeoff antara Bias dan Variance
Tradeoff antara bias dan variance adalah proses untuk menemukan keseimbangan optimal antara bias dan variance untuk meminimalkan kesalahan prediksi keseluruhan. Secara umum, meningkatkan kompleksitas model dapat mengurangi bias tetapi meningkatkan variance, sedangkan mengurangi kompleksitas model dapat meningkatkan bias tetapi mengurangi variance. Tantangannya adalah menemukan keseimbangan yang tepat yang mengarah pada performa terbaik pada data baru yang belum pernah dilihat.
Bias dan Variance dalam Machine Learning
In this chapter, I will delve into the concepts of bias and variance, providing clear definitions and intuitive examples.
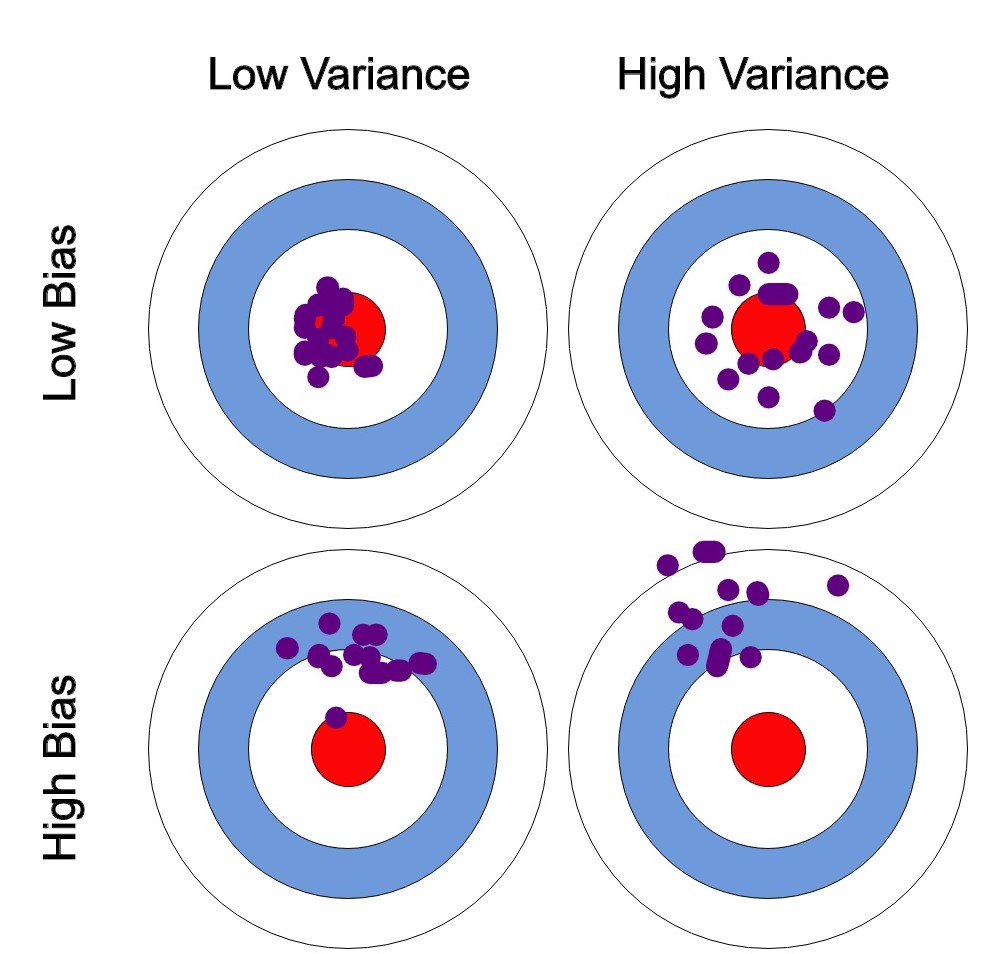
Bias: Kesalahan Sistematis
Bias mengacu pada kesalahan yang diperkenalkan oleh model yang bersifat sederhana ketika memetakan suatu masalah di dunia nyata. Dalam konteks machine learning, bias mengukur seberapa baik prediksi model sejalan dengan nilai sebenarnya secara rata-rata. Model dengan bias yang tinggi membuat asumsi kuat tentang data dan dapat menghasilkan underfitting, di mana model terlalu sederhana untuk menangkap pola yang mendasari pada data.
Sebagai contoh, pertimbangkan dataset harga rumah dengan fitur seperti luas tanah, jumlah kamar tidur, dan lokasi. Model dengan bias yang tinggi mungkin menganggap bahwa harga rumah hanya bergantung pada luas tanah, mengabaikan fitur lainnya. Simplifikasi ini dapat menghasilkan kesesuaian dengan data yang buruk, karena model tidak akan menangkap variasi harga rumah yang disebabkan oleh perbedaan jumlah kamar tidur atau lokasi.
Variance: Kesalahan Acak
Variance, di sisi lain, adalah kesalahan yang diperkenalkan oleh sensitivitas model terhadap fluktuasi kecil dalam data training. Model dengan variance yang tinggi sangat fleksibel dan dapat menyesuaikan data training dengan sangat baik, tetapi rentan terhadap overfitting, di mana model menjadi terlalu khusus untuk data training dan performanya buruk pada data baru yang belum pernah dilihat.
Kembali ke contoh harga rumah, model dengan variance yang tinggi mungkin cocok dengan data training dengan sangat baik dengan memperhitungkan semua fitur yang tersedia dan interaksi yang kompleks antar fitur. Namun, model ini mungkin terlalu sensitif terhadap noise dalam data training, seperti outlier atau kesalahan pengukuran. Akibatnya, model ini mungkin tidak dapat digeneralisasi dengan baik pada data baru, menghasilkan performa yang buruk pada harga rumah yang sebelumnya belum pernah dilihat.
Dekomposisi Bias-Variance
Dekomposisi bias-variance adalah teknik yang digunakan untuk memecah kesalahan prediksi keseluruhan model machine learning menjadi komponen bias, variance, dan kesalahan yang tidak dapat dikurangi. Kesalahan prediksi keseluruhan diberikan oleh:
Istilah bias mewakili perbedaan kuadrat antara prediksi rata-rata model dan nilai sebenarnya. Istilah variance mengukur sensitivitas model terhadap fluktuasi kecil dalam data, sementara kesalahan yang tidak dapat dikurangi bersifat inheren pada masalah dan tidak dapat dikurangi.
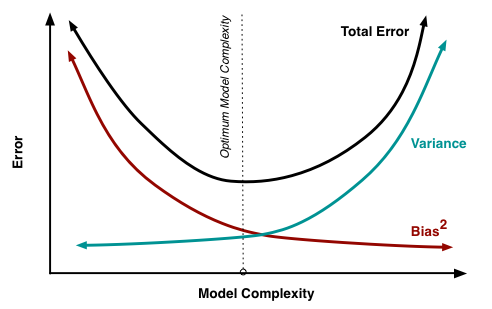
Understanding the Bias-Variance Tradeoff
Teknik untuk Mengelola Tradeoff
Di bab ini, saya akan memperkenalkan berbagai teknik yang dapat membantu Anda mengelola tradeoff antara bias dan variance dengan efektif. Dengan menerapkan strategi ini, data scientist dapat membangun model yang mencapai keseimbangan optimal antara bias dan variance, yang dapat meningkatkan generalisasi dan performa pada data baru yang belum pernah dilihat.
Regularisasi
Regularisasi adalah teknik yang digunakan untuk mencegah overfitting dengan menambahkan istilah hukuman pada fungsi tujuan model, yang efektif membatasi kompleksitasnya. Dua jenis regularisasi yang umum adalah regularisasi L1 (Lasso) dan L2 (Ridge).
Dengan mengintegrasikan regularisasi, Anda dapat mengontrol kompleksitas model dan mengurangi overfitting, yang menghasilkan keseimbangan yang lebih baik antara bias dan variance.
Cross Validation
Cross validation adalah teknik untuk mengevaluasi performa model machine learning dengan membagi dataset menjadi beberapa set training dan validasi. Bentuk cross-validation yang paling umum adalah k-fold cross validation, di mana dataset dibagi menjadi k-fold yang sama besar. Model dilatih pada k-1 fold dan divalidasi pada fold yang tersisa, dengan proses ini diulang k kali, menggunakan fold yang berbeda untuk validasi setiap kali.
Cross-validation menyediakan penilaian yang lebih akurat dari performa model pada data yang belum pernah dilihat, yang memungkinkan Anda untuk membandingkan model atau pengaturan hyperparameter yang berbeda dan memilih yang mencapai keseimbangan terbaik antara bias dan variance.
Ensemble Learning
Ensemble learning adalah teknik yang menggabungkan prediksi dari beberapa model dasar untuk membuat prediksi keseluruhan yang lebih akurat dan tangguh. Ada beberapa jenis metode ensemble learning, termasuk bagging, boosting, dan stacking.
Teknik ensemble learning dapat membantu mengurangi efek dari kedua bias dan variance yang tinggi, meningkatkan keseimbangan keseluruhan antara keduanya dan meningkatkan performa model pada data baru.
Referensi


















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS