


Apa itu Permutation Importance
Permutation Importance adalah teknik yang digunakan dalam bidang machine learning untuk memahami relevansi fitur dalam model prediksi. Dengan memperkirakan dampak setiap fitur terhadap kinerja model, teknik ini membantu ilmuwan data mengidentifikasi fitur paling penting dan membuat keputusan informasi yang tepat saat membangun dan menyempurnakan model.
Metodologi untuk Menghitung Permutation Importance
Dalam matematika, permutation adalah susunan objek dalam urutan tertentu. Dalam konteks Permutation Importance, permutation mengacu pada proses acak mengocok nilai fitur dalam kumpulan data sambil menjaga fitur lainnya tidak berubah. Proses pengocokan ini membantu menilai dampak fitur pada kinerja model, karena kehilangan akurasi atau metrik lainnya dapat diatribusikan pada gangguan nilai fitur.
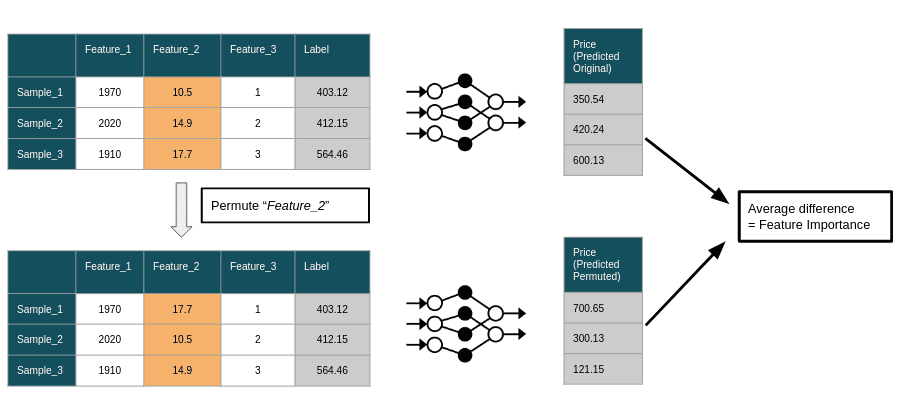
Menghitung Permutation Importance melibatkan beberapa langkah, seperti diuraikan di bawah ini:
-
Latih model
Sesuaikan model machine learning dengan kumpulan data asli menggunakan metrik evaluasi dan fungsi kerugian yang dipilih. -
Evaluasi kinerja dasar
Evaluasi kinerja model pada kumpulan data asli dan catat nilai metrik dasar. -
Permutasi fitur
Acak secara acak nilai satu fitur dalam kumpulan data, menjaga fitur lain tidak berubah. -
Evaluasi kinerja ulang
Evaluasi kinerja model pada kumpulan data yang diganggu, dan hitung perbedaan dalam nilai metrik antara kumpulan data yang diganggu dan asli. -
Ulangi langkah 3-4
Acak dan evaluasi setiap fitur dalam kumpulan data, mencatat perubahan kinerja untuk setiap permutasi. -
Hitung skor pentingnya
Rata-ratakan perubahan kinerja di beberapa iterasi untuk setiap fitur. -
Urutkan fitur
Urutkan fitur berdasarkan skor pentingnya secara menurun.
Menangani Variabel Kategorikal
Permutation Importance dapat diperluas ke variabel kategorikal dengan melakukan permutasi dalam setiap kategori. Ini mempertahankan struktur kategorikal sambil tetap memungkinkan penilaian tentang pentingnya variabel. Namun, harus berhati-hati saat menafsirkan hasilnya, karena skor penting dapat dipengaruhi oleh jumlah kategori dan distribusinya dalam kumpulan data.
Memvisualisasikan Permutation Importance dengan Python
Dalam bab ini, saya akan menunjukkan bagaimana memvisualisasikan Permutation Importance menggunakan kumpulan data California Housing.
Kumpulan data California Housing berisi informasi tentang pasar perumahan di California, termasuk fitur seperti pendapatan median, usia rumah median, dan rata-rata jumlah kamar per rumah. Variabel target adalah nilai rumah median.
Pertama, mari muat kumpulan data dan bagi menjadi kumpulan data pelatihan dan pengujian:
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
data = fetch_california_housing()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Untuk contoh ini, kita akan melatih random forest regressor:
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
Kita dapat menggunakan fungsi permutation_importance dari sklearn untuk menghitung Permutation Importance untuk setiap fitur:
from sklearn.inspection import permutation_importance
result = permutation_importance(model, X_test, y_test, n_repeats=10, random_state=42)
Parameter n_repeats pada fungsi permutation_importance menentukan jumlah kali proses permutasi diulang untuk setiap fitur dalam kumpulan data.
Kita dapat membuat plot batang untuk memvisualisasikan skor Permutation Importance untuk setiap fitur menggunakan matplotlib dan seaborn:
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# Sort the features by importance
sorted_idx = result.importances_mean.argsort()
# Create a horizontal bar plot
plt.figure(figsize=(10, 6))
sns.barplot(x=result.importances_mean[sorted_idx], y=np.array(data.feature_names)[sorted_idx], palette='viridis')
# Add error bars to show the standard deviation of the importance scores
plt.errorbar(x=result.importances_mean[sorted_idx], y=np.arange(len(sorted_idx)),
xerr=result.importances_std[sorted_idx], fmt='o', capsize=5, color='black')
# Set the plot title and labels
plt.title('Permutation Importance of Features')
plt.xlabel('Importance Score')
plt.ylabel('Feature')
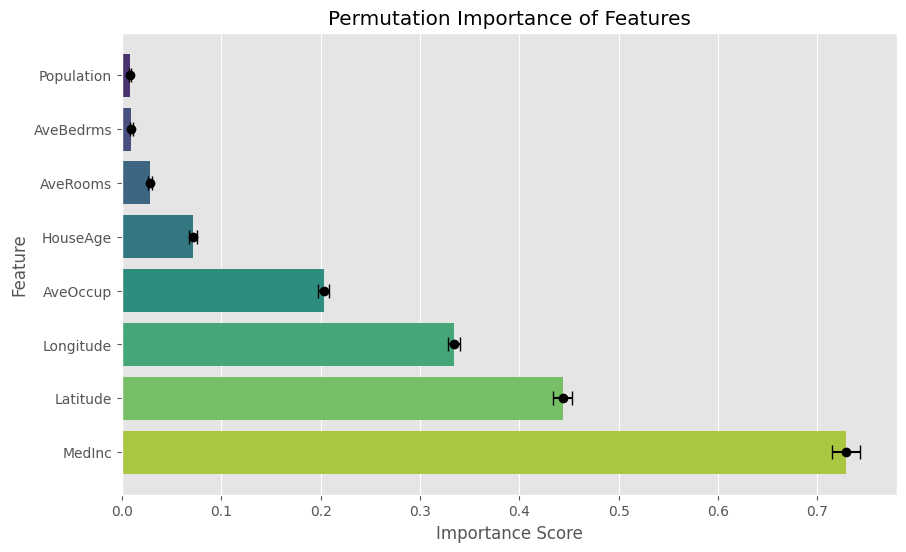
Visualisasi ini dengan jelas menampilkan skor Permutation Importance untuk setiap fitur dalam kumpulan data California Housing, beserta deviasi standarnya. Dengan memeriksa plot, kita dapat melihat bahwa MedInc (pendapatan median) adalah fitur yang paling penting.
Referensi
















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS