
Apa itu Pembelajaran Ensemble
Pembelajaran ensemble adalah pendekatan pembelajaran mesin yang menggabungkan beberapa algoritma pembelajaran untuk meningkatkan performa prediksi. Dengan memanfaatkan kelebihan dari model-model dasar yang berbeda dan meminimalkan kelemahan masing-masing, metode ensemble menciptakan prediktor yang kuat dan akurat. Teknik pembelajaran ensemble terdiri dari tiga teknik utama: Bagging, Boosting, dan Stacking.
Dengan memahami dan menerapkan ketiga teknik utama pembelajaran ensemble, Bagging, Boosting, dan Stacking, Anda dapat membuat model pembelajaran mesin yang akurat dan stabil yang dapat menangani masalah dunia nyata yang kompleks dengan mudah.
Bias dan varian dalam Model
Bias dan varian adalah konsep penting dalam pembelajaran mesin, karena membantu kita memahami kompromi antara underfitting dan overfitting. Dengan memahami bagaimana bias dan varian mempengaruhi performa model, kita dapat memilih model dan teknik pembelajaran ensemble yang paling cocok untuk tugas-tugas yang berbeda.
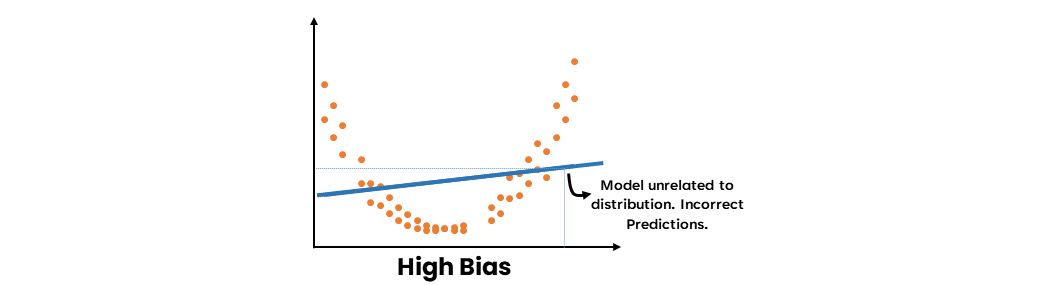
- Bias Tinggi
Bias tinggi merujuk pada ketidakmampuan model untuk menangkap pola yang mendasari dalam data, yang mengakibatkan kurva yang buruk. Hal ini dapat disebabkan oleh kesederhanaan model atau penggunaan asumsi yang tidak tepat. Ketika suatu model menunjukkan bias yang tinggi, model tersebut cenderung underfitting pada data, yang berarti bahwa model tersebut tidak cukup baik dalam menangkap hubungan antara fitur input dan variabel target.
Ensemble Learning Methods: Bagging, Boosting and Stacking
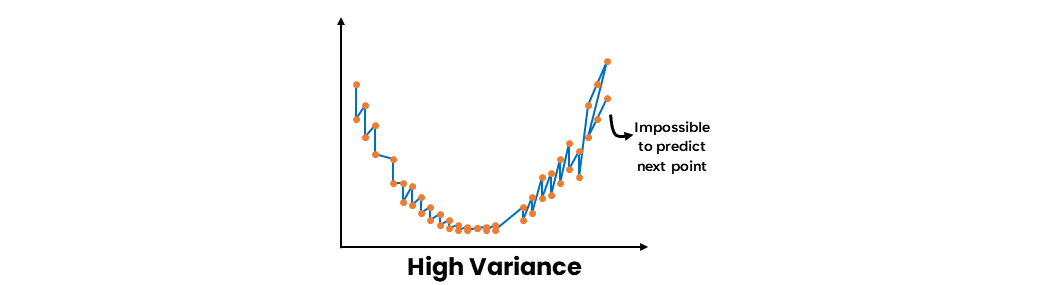
- Varian Tinggi
Varian tinggi merujuk pada sensitivitas model terhadap fluktuasi kecil dalam data pelatihan, yang mengakibatkan overfitting. Model overfitting tampil baik pada data pelatihan tetapi gagal menggeneralisasi ke data baru yang belum terlihat. Ketika suatu model menunjukkan varian tinggi, model tersebut tidak hanya menangkap pola yang mendasari dalam data tetapi juga noise, yang dapat memengaruhi performa model pada dataset uji.
Ensemble Learning Methods: Bagging, Boosting and Stacking
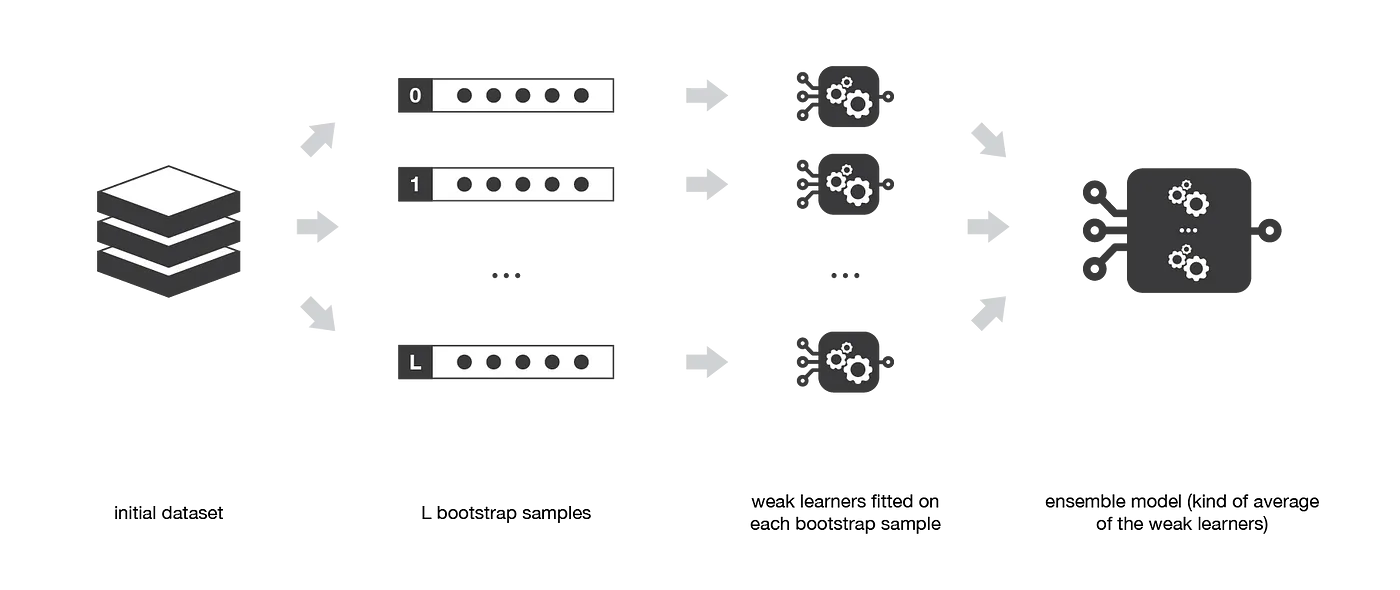
Bagging: Bootstrap Aggregating
Bagging, yang merupakan singkatan dari Bootstrap Aggregating, adalah teknik pembelajaran ensemble yang bertujuan untuk meningkatkan performa model pembelajaran mesin dengan mengurangi varian dalam prediksi. Teknik ini bekerja dengan melatih beberapa model dasar secara independen pada subset yang berbeda dari dataset asli dan menggabungkan prediksi mereka melalui voting mayoritas (untuk klasifikasi) atau rata (untuk regresi).
Ensemble methods: bagging, boosting and stacking
Bootstrap Samples
Bootstrap sample adalah subset acak dari dataset asli yang diperoleh dengan pengambilan sampel dengan penggantian. Dalam Bagging, setiap model dasar dilatih pada bootstrap sample yang berbeda, yang berarti bahwa beberapa titik data mungkin termasuk lebih dari satu kali, sementara yang lain mungkin tidak termasuk sama sekali. Proses ini memperkenalkan keragaman di antara model dasar, yang pada akhirnya membantu mengurangi varian prediksi ensemble.
Ensemble methods: bagging, boosting and stacking
Algoritma dan Implementasi
Algoritma Bagging terdiri dari langkah-langkah berikut:
- Buat
nbootstrap sample dari dataset asli dengan mengambil sampel secara acak dengan penggantian. - Latih setiap model dasar secara independen pada setiap bootstrap sample.
- Gabungkan prediksi dari semua model dasar.
Berikut adalah implementasi algoritma Bagging:
- Inisialisasi jumlah model dasar dan jenis model dasar (misalnya, pohon keputusan, regresi logistik, dll.).
- Untuk setiap model dasar, buat bootstrap sample dari dataset asli dengan mengambil sampel secara acak dengan penggantian.
- Latih model dasar pada bootstrap sample yang sesuai.
- Ulangi langkah 2-3 untuk semua model dasar.
- Peroleh prediksi dari setiap model dasar untuk dataset uji.
- Gabungkan prediksi dengan voting mayoritas (klasifikasi) atau rata-rata (regresi) untuk mendapatkan prediksi akhir.
Kelebihan
- Bagging mengurangi overfitting dengan mengambil rata-rata prediksi dari beberapa model dasar, menghasilkan model yang lebih akurat dan stabil.
- Efektif dalam meningkatkan performa pembelajaran yang tidak stabil seperti pohon keputusan.
- Bagging dapat dengan mudah diparalelkan, karena setiap model dasar dilatih secara independen.
Keterbatasan
- Pilihan model dasar dan jumlah model dasar dapat signifikan mempengaruhi performa ensemble.
- Bagging mungkin tidak efektif dalam mengurangi bias, karena fokus utamanya pada mengurangi varian.
- Dapat menjadi mahal secara komputasional, terutama ketika bekerja dengan dataset besar atau model dasar yang kompleks.
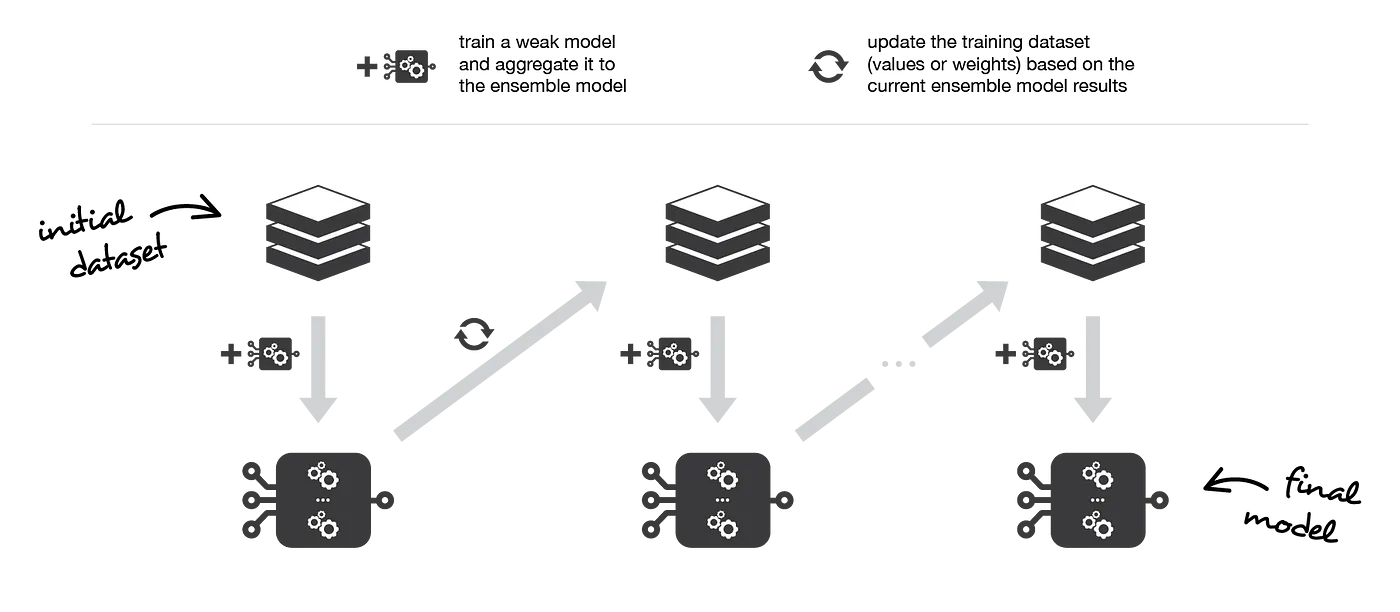
Boosting: Adaptive Ensemble Learning
Boosting adalah teknik pembelajaran ensemble yang berfokus pada meningkatkan akurasi prediksi dengan melatih serangkaian pembelajaran yang lemah secara berurutan. Setiap pembelajaran pada urutan bertujuan untuk memperbaiki kesalahan yang dilakukan oleh pendahulunya, pada akhirnya menciptakan model yang kuat dengan menggabungkan prediksi mereka. Boosting sangat cocok untuk skenario di mana pembelajaran dasar menunjukkan bias yang tinggi atau akurasi yang rendah, karena bertujuan untuk meningkatkan daya prediksi dengan mengurangi bias.
Ensemble methods: bagging, boosting and stacking
Pembelajaran Lemah
Pembelajaran lemah adalah model pembelajaran mesin yang relatif sederhana yang dapat menghasilkan prediksi dengan akurasi sedikit lebih baik dari acak, tetapi tidak sebaik model yang lebih canggih. Pembelajaran lemah biasanya efisien secara komputasi dan mudah dilatih, tetapi mungkin memiliki daya prediksi yang terbatas karena kesederhanaannya. Contoh pembelajaran lemah termasuk decision stumps (pohon keputusan pada level tunggal) atau pohon keputusan dangkal.
Dalam konteks teknik pembelajaran ensemble, seperti boosting, pembelajaran lemah digabungkan untuk membentuk pembelajaran yang kuat, yang dapat memberikan prediksi yang lebih akurat dan dapat diandalkan. Pendekatan ensemble memanfaatkan kekuatan dari beberapa pembelajaran lemah, mengkompensasi keterbatasan individu mereka, dan akhirnya meningkatkan performa prediksi keseluruhan model yang digabungkan.
Algoritma Kunci: AdaBoost dan Gradient Boosting
Dua algoritma populer dalam keluarga Boosting adalah AdaBoost (Adaptive Boosting) dan Gradient Boosting. Kedua algoritma memiliki tujuan umum untuk meningkatkan performa pembelajaran lemah; namun, mereka berbeda dalam pendekatan mereka untuk mencapai tujuan ini.
-
AdaBoost
AdaBoost adalah algoritma iteratif yang memperbarui bobot sampel pelatihan berdasarkan kesalahan yang dilakukan oleh pembelajaran lemah sebelumnya. Pada setiap iterasi, pembelajaran lemah baru dilatih pada bobot sampel yang diperbarui, berfokus pada sampel yang salah diklasifikasikan oleh pembelajaran lemah sebelumnya. -
Gradient Boosting
Gradient Boosting memperluas konsep boosting dengan mengoptimalkan fungsi kerugian menggunakan gradien turun. Pada setiap iterasi, pembelajaran lemah baru ditambahkan ke ensemble, dan bobot pembelajaran lemah ini disesuaikan untuk meminimalkan fungsi kerugian keseluruhan.
Algoritma dan Implementasi
Berikut adalah gambaran algoritma Boosting:
- Inisialisasi bobot sampel pelatihan secara seragam.
- Latih pembelajaran lemah pada dataset yang telah ditimbang.
- Perbarui bobot sampel berdasarkan kesalahan yang dilakukan oleh pembelajaran lemah.
- Ulangi langkah 2-3 untuk jumlah iterasi yang diinginkan.
- Gabungkan prediksi pembelajaran lemah dengan penjumlahan tertimbang atau voting mayoritas.
Untuk mengimplementasikan algoritma Boosting:
- Initialize the weights of training samples uniformly.
- Train a weak learner on the weighted dataset.
- Update the sample weights based on the errors made by the weak learner.
- Repeat steps 2-3 for the desired number of iterations.
- Combine the weak learners' predictions with a weighted sum or majority vote.
To implement the Boosting algorithm:
- Pilih jumlah pembelajaran lemah dan jenis pembelajaran dasar (mis. pohon keputusan, regresi logistik, dll.).
- Inisialisasi bobot sampel secara seragam.
- Untuk setiap pembelajaran lemah:
- Latih pembelajaran dasar pada dataset yang ditimbang.
- Hitung tingkat kesalahan dari pembelajaran dasar.
- Perbarui bobot sampel berdasarkan tingkat kesalahan.
- Normalisasi bobot sampel.
- Dapatkan prediksi dari setiap pembelajaran lemah untuk dataset uji.
- Gabungkan prediksi menggunakan penjumlahan tertimbang (regresi) atau voting mayoritas (klasifikasi) untuk mendapatkan prediksi akhir.
Kelebihan
- Boosting dapat secara signifikan meningkatkan akurasi pembelajaran lemah dengan fokus pada sampel yang sulit dan mengurangi bias.
- Lebih sedikit rentan terhadap overfitting dibandingkan dengan Bagging, karena melatih pembelajaran lemah secara berurutan daripada paralel.
- Boosting dapat diterapkan pada berbagai jenis pembelajaran dasar, menjadikannya teknik pembelajaran ensemble yang serbaguna.
Keterbatasan
- Boosting dapat sensitif terhadap noise dan outlier, karena cenderung fokus pada sampel yang sulit.
- Dapat mahal secara komputasi, terutama saat menggunakan banyak pembelajaran lemah atau pembelajaran dasar yang kompleks.
- Pilihan jumlah pembelajaran lemah dan jenis pembelajaran dasar dapat signifikan mempengaruhi performa ensemble.
Stacking: Menggabungkan Pembelajaran
Stacking, juga dikenal sebagai Stacked Generalization, adalah teknik pembelajaran ensemble yang menggabungkan beberapa pembelajar dasar dengan melatih sebuah meta-model pada prediksi mereka. Tujuannya adalah untuk memanfaatkan kekuatan dari setiap pembelajar dasar sementara juga mengurangi kelemahan mereka. Dengan belajar dari prediksi beberapa pembelajar dasar, meta-model seringkali dapat mencapai akurasi prediksi yang lebih tinggi daripada setiap model individu secara terpisah.
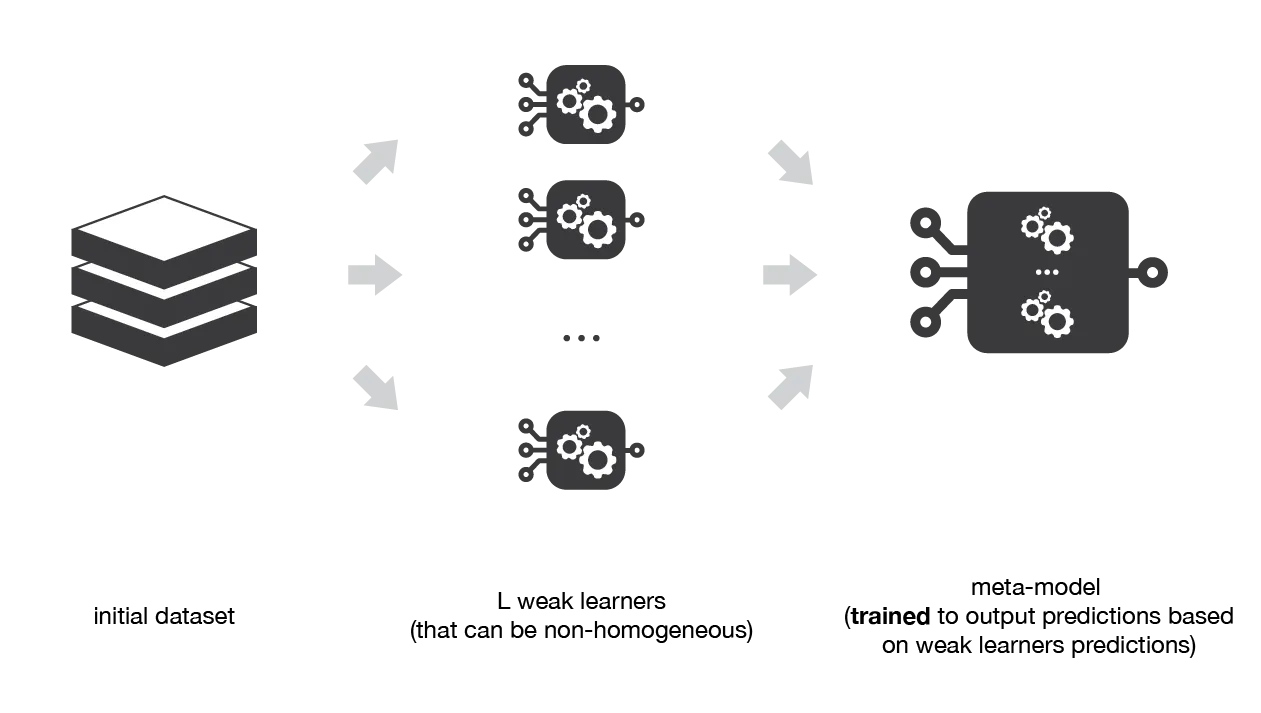
Ensemble methods: bagging, boosting and stacking
Algoritma dan Implementasi
Algoritma Stacking dapat dibagi menjadi beberapa langkah berikut:
- Bagi dataset menjadi set pelatihan dan set validasi.
- Latih pembelajar dasar pada set pelatihan.
- Dapatkan prediksi dari setiap pembelajar dasar pada set validasi.
- Gunakan prediksi dari langkah 3 sebagai fitur untuk melatih sebuah meta-model.
- Dapatkan prediksi dari setiap pembelajar dasar dan meta-model pada dataset uji.
Berikut adalah implementasi dari algoritma Stacking:
- Pilih jumlah pembelajar dasar, tipe pembelajar dasar, dan meta-model (misalnya, regresi logistik, pohon keputusan, dll.).
- Bagi dataset menjadi set pelatihan dan set validasi.
- Latih setiap pembelajar dasar pada set pelatihan.
- Dapatkan prediksi dari setiap pembelajar dasar pada set validasi.
- Gunakan prediksi dari langkah 4 sebagai fitur untuk melatih meta-model.
- Dapatkan prediksi dari setiap pembelajar dasar pada dataset uji.
- Gunakan prediksi dari langkah 6 sebagai fitur untuk mendapatkan prediksi akhir dari meta-model.
Keuntungan
- Stacking dapat memanfaatkan kekuatan dari pembelajar dasar yang berbeda, seringkali mencapai akurasi prediksi yang lebih tinggi daripada setiap model individu.
- Ini dapat diterapkan pada berbagai jenis pembelajar dasar dan meta-model, membuatnya menjadi teknik pembelajaran ensemble yang serbaguna.
- Stacking dapat membantu mengurangi kelemahan pembelajar dasar individu, menghasilkan prediksi yang lebih kuat dan dapat diandalkan.
Keterbatasan
- Stacking dapat memakan waktu komputasi yang besar, terutama ketika menggunakan beberapa pembelajar dasar dan meta-model yang kompleks.
- Pilihan pembelajar dasar, meta-model, dan jumlah pembelajar dasar dapat memengaruhi kinerja ensemble secara signifikan.
- Ini dapat rentan terhadap overfitting, terutama ketika menggunakan meta-model yang kompleks atau data validasi yang tidak memadai untuk melatih meta-model.
Membandingkan Teknik: Bagging vs. Boosting vs. Stacking
Metrik Kinerja
Saat membandingkan teknik pembelajaran ensemble, penting untuk mempertimbangkan berbagai metrik kinerja untuk menilai efektivitas mereka. Metrik umum meliputi:
-
Akurasi
Proporsi prediksi yang benar dibandingkan dengan jumlah total prediksi. -
Presisi, Recall, dan F1-score
Metrik ini memberikan pandangan yang lebih komprehensif tentang kinerja klasifikasi, terutama pada dataset yang tidak seimbang. -
Mean Squared Error (MSE) atau Root Mean Squared Error (RMSE)
Metrik ini mengukur perbedaan antara nilai yang diprediksi dan nilai aktual pada tugas regresi. -
Area Under the ROC Curve (AUC-ROC)
Metrik yang mengukur trade-off antara true positive rate dan false positive rate.
Kesesuaian untuk Tugas yang Berbeda
Setiap teknik pembelajaran ensemble memiliki karakteristik uniknya, sehingga membuatnya cocok untuk tugas yang berbeda:
-
Bagging
Bagging paling efektif untuk mengurangi overfitting dan meningkatkan stabilitas pembelajar yang tidak stabil, seperti pohon keputusan. Ini cocok untuk tugas di mana pembelajar dasar cenderung memiliki varian yang tinggi. -
Boosting
Boosting dirancang untuk meningkatkan akurasi pembelajar lemah dengan mengurangi bias. Ini cocok untuk tugas di mana pembelajar dasar menunjukkan bias yang tinggi atau akurasi yang rendah. -
Stacking
Stacking cocok untuk tugas di mana memanfaatkan kekuatan dari beberapa pembelajar dasar dapat menghasilkan prediksi yang lebih baik. Ini adalah teknik yang serbaguna yang dapat diterapkan pada berbagai jenis pembelajar dasar dan meta-model.
Kompleksitas Komputasi
Kompleksitas komputasi dari teknik pembelajaran ensemble bervariasi tergantung pada jumlah pembelajar dasar, tipe pembelajar dasar, dan meta-model (dalam kasus Stacking):
-
Bagging
Bagging dapat dengan mudah diparalelkan, karena setiap pembelajar dasar dilatih secara independen. Namun, dapat memakan waktu komputasi yang besar ketika menggunakan jumlah pembelajar dasar yang besar atau pembelajar dasar yang kompleks. -
Boosting
Boosting dapat memakan waktu komputasi yang besar, karena melatih pembelajar dasar secara berurutan. Kompleksitas meningkat dengan jumlah pembelajar lemah dan kompleksitas pembelajar dasar. -
Stacking
Stacking dapat memakan waktu komputasi yang besar, terutama ketika menggunakan beberapa pembelajar dasar dan meta-model yang kompleks. Selain itu, ini membutuhkan pembagian dataset menjadi set pelatihan dan validasi, yang dapat meningkatkan biaya komputasi lebih lanjut.
Referensi


















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS