

パーセプトロンとは
パーセプトロンは、脳内の生物学的ニューロンの振る舞いから着想を得た、単純でありながら強力なモデルです。人工ニューラルネットワークの基本的な構成要素であり、より複雑な深層学習アーキテクチャを理解するための基盤となっています。
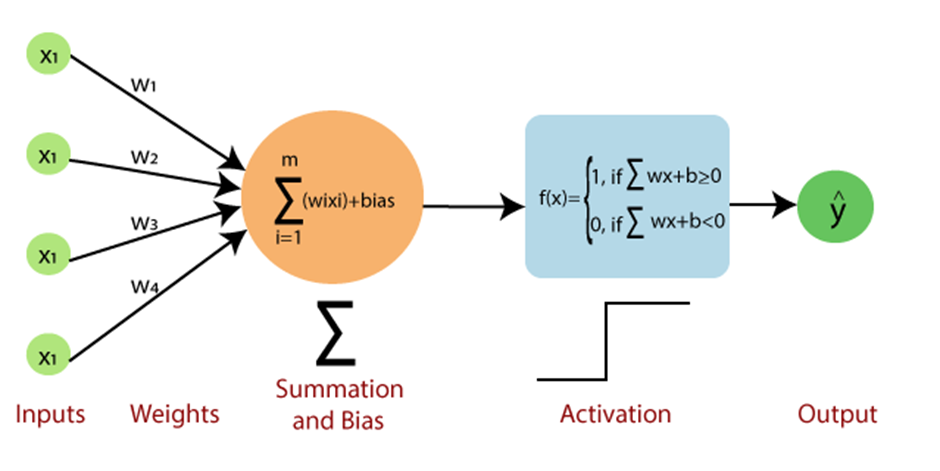
パーセプトロンは、入力ノード、重み、バイアス、そして活性化関数などのいくつかの主要な構成要素から構成されます。入力ノードは入力値を受け取り、重みとバイアスは接続の強度と方向を決定します。そして、活性化関数は入力の加重和を出力に変換する役割を担います。
-
入力ノード
入力ノードは、入力データの特徴量または変数を表します。単純なパーセプトロンでは、各入力ノードは1つの特徴量に対応します。入力ノードは、対応する重みで乗算された値を次の層に伝達します。 -
重み
重みは、入力ノードとパーセプトロンの出力の接続の強度と方向を示す数値です。学習プロセス中、重みは予測された出力と実際の出力の誤差を最小化するように調整されます。 -
バイアス
バイアスは、パーセプトロンが決定境界をシフトするための追加のパラメータです。オフセットとして機能し、パーセプトロンが入力特徴量と出力の間のより複雑な関係を学習することを可能にします。 -
活性化関数
活性化関数は、入力の加重和を処理して出力値を生成します。活性化関数の選択は、パーセプトロンの振る舞いや学習能力に大きな影響を与えます。
Difference between perceptron and neuron?
パーセプトロンの学習アルゴリズム
パーセプトロン学習アルゴリズムは、実際の出力と予測された出力の誤差に基づいて重みとバイアスを調整します。アルゴリズムは次のようにまとめることができます。
- 重みとバイアスをランダムな値で初期化
- トレーニングデータセット内の各入力について、入力の加重和を計算し、活性化関数を介して予測された出力を取得
- 予測された出力と実際の出力の誤差を計算
- 誤差と学習率を使用して、重みとバイアスを更新
- パーセプトロンが解に収束するか、あるいは事前に定義された停止基準に到達するまで、ステップ2-4を繰り返す
パーセプトロン学習アルゴリズムは、モデルをトレーニングするためにラベル付きのデータセットが必要な教師あり学習の一例です。また、重みとバイアスは各入力例を処理した後にインクリメンタルに更新されるため、オンライン学習の一例でもあります。
深層学習におけるパーセプトロン
パーセプトロンは、より高度なアーキテクチャの構築ブロックとして、深層学習において基礎的な役割を果たしています。この章では、パーセプトロンがどのように深層学習モデル内で組織されるか、多層パーセプトロン(MLPs)について説明し、バックプロパゲーションを用いて深層MLPを訓練する過程について説明します。
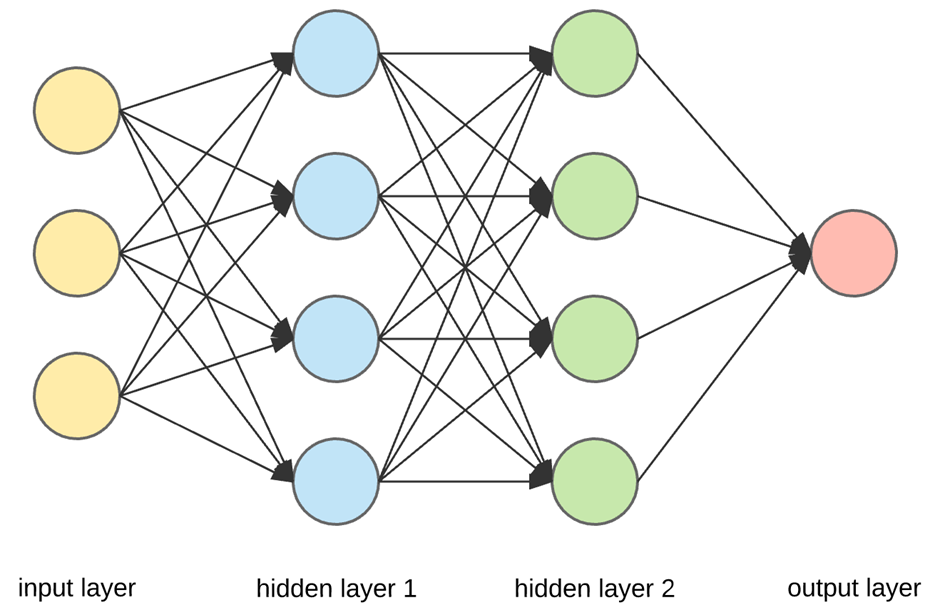
パーセプトロン層
深層学習において、パーセプトロンは層に組み込まれます。各層には複数のパーセプトロンが含まれ、3つの主要なタイプの層があります。
-
入力層
入力層は、生データを受け取り、データセット内の特徴量の数と同じ数の入力ノードから構成されます。この層は計算を実行せず、単に入力値を次の層に伝達します。 -
隠れ層
隠れ層は、入力層からの情報を処理・変換します。深層学習モデルには、複数の隠れ層が含まれる場合があります。これにより、モデルは入力データのより複雑で抽象的な表現を学習することができます。各隠れ層には、アーキテクチャや解決すべき問題に応じて、さまざまな数のパーセプトロンが含まれます。 -
出力層
出力層は、最終的な予測または分類を出力します。出力ノードの数は、タスクによって異なります。バイナリ分類の場合、1つの出力ノードが十分であり、多クラス分類や回帰タスクの場合は複数の出力ノードが必要になります。
Difference between perceptron and neuron?
多層パーセプトロン(MLPs)
MLPは、複数のパーセプトロンの層から構成されるフィードフォワードニューラルネットワークです。フィードフォワードという用語は、情報がループなしに入力層から出力層に向かって1方向に流れることを示しています。
MLPの重要な特徴は、入力と出力の間の複雑で非線形な関係を学習・表現する能力です。単層パーセプトロンが線形な決定境界のみを学習できるのに対し、MLPは十分な数の隠れ層とパーセプトロンがあれば、任意の連続関数を近似できます。
深層MLPの訓練
深層MLPの訓練には、バックプロパゲーションと呼ばれるプロセスを通じて重みとバイアスを調整します。バックプロパゲーションアルゴリズムは、誤差の各重みとバイアスに対する勾配を計算し、モデルのパラメータを更新するために使用されます。アルゴリズムは次のようにまとめることができます。
- 重みとバイアスをランダムな値で初期化
- ネットワークを前方に進め、各層で入力の加重和を計算し、活性化関数を適用して最終的な予測を取得
- 予測された出力と実際の出力の誤差を計算
- チェーンルールを使用して、誤差に対する各重みとバイアスの勾配を計算
- 計算された勾配と学習率を使用して、重みとバイアスを更新
- あらかじめ定義されたエポック数または停止基準に達するまで、ステップ2-5を繰り返す
バックプロパゲーションは、モデルをトレーニングするためにラベル付きのデータセットが必要な教師あり学習の例です。また、重みとバイアスは、データセット全体を処理した後に更新されるため、バッチ学習の例でもあります。
参考

















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS