
Modern Data Stack とは
The Modern Data Stackとは、クラウドネイティブなデータ関連のサービスで構成されたテクノロジーの集合体です。現代のクラウド環境下にふさわしいデータ基盤の設計により、データの実用化にかかるタイムラグを短縮することができます。
Modern Data Stackには次のようなサービス群が存在しています。
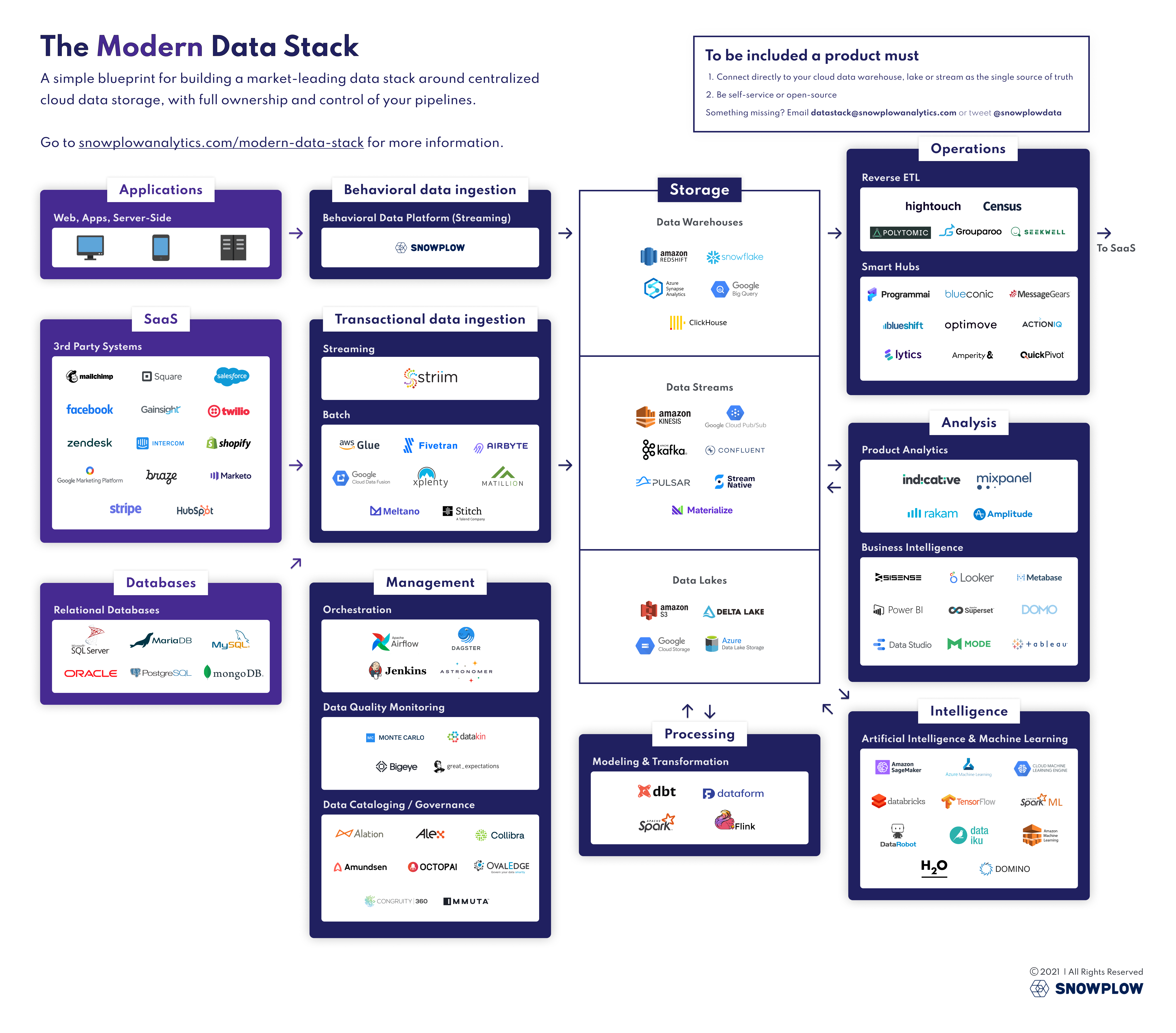
The modern data stack: a guide | SNOWPLOW
- データ蓄積
- Data Warehouses
分析に最適化された形でデータを蓄積するためのサービス群
- Data Warehouses
- データ統合
- ETL Tools / Change Data Capture / Data Streaming
データを統合するサービス群
- ETL Tools / Change Data Capture / Data Streaming
- データ処理
- Modeling & Transformation
蓄積されたデータを変換するサービス群
- Modeling & Transformation
- データ管理
- Orchestration
データ統合やデータモデリングを動かすためのジョブ管理サービス群 - Data Cataloging / Governance
メタデータを蓄積し、データの検索性や理解を促すためのサービス群 - Data Quality / Monitoring
低品質なデータの検知や、データ品質を担保するためのサービス群
- Orchestration
- データ分析
- Business Intelligence
データの可視化や簡易的な処理を行うためのサービス群 - Product Analytics
提供製品の分析に特化したサービス群
- Business Intelligence
- データ運用
- Reverse ETL
蓄積したデータを別のSaaSに連携するためのサービス群
- Reverse ETL
Modern Data Stackに含まれるテクノロジーの主要な能力について以下が挙げられます。
- マネージドサービスとして提供される
エンジニアリングが最小限で済みます。 - クラウド DWH (データウェアハウス)を中心とする
近年のパワフルなクラウド型のDWHが中心となり構成されます。 - SQL 中心のエコシステムでデータを民主化
サービス群は、データ/アナリティクスエンジニアやビジネスユーザーのために、習得が容易なSQLを中心として構築されています。 - エラスティックなワークロード
従量課金であり、即座にスケールアップすることが可能です。
Modern Data Stackを採用することで、企業はセットアップが容易で低コストのデータプラットフォームを手に入れることができます。
Modern Data Stack の歴史
Modern Data Stackの根底にあるのは、BigQuery、Snowflake、RedshiftなどのクラウドDWHの進化です。
数十年前までは、大規模なデータセットを分析できるのは大企業だけで、それには計算資源の垂直スケーリングが必要であり、多額の先行投資が必要でした。そこからAWS、GCP、Azureといったパブリッククラウドの時代が到来し、企業が資本集約的なサーバーセンターを建設・維持する必要がなくなりました。AWS、GCP、Azureは、あらゆる規模の企業が、必要なだけのストレージとコンピューティングリソースを従量制で支払うことを可能にしました。
現代のクラウドDWH革命は、2010年のGoogleのBigQueryで始まり、2012年にRedshiftとSnowflakeが続きました。クラウドDWHは、以前のRDBMSと同じようにシンプルで使いやすく、ビッグデータ型のワークロードを処理するために構築されています。この変化は、ビッグデータソリューションに必要な人員が不足している中小企業から始まり、SaaS指向のクラウド環境が参入障壁を劇的に低下させたため、瞬く間に大企業も弾力的なワークロードによる簡素化とコスト削減の動きに乗ってきました。
クラウドDWH登場の直後から、次のようなクラウドネイティブの隣接技術のエコシステムが出現し始めました。
- BI
- Chartio - 2010
- Looker - 2011
- Mode - 2012
- データ統合
- Fivetran - 2012
- Segment - 2013
- Stitch - 2015
- データ変換
- dbt - 2016
- Dataform - 2018
- Reverse ETL
- Census - 2018
- Hightouch - 2018
DWHの周りに生まれたエコシステムが、Modern Data Stackを作り上げています。資金をかけず、アーキテクチャのレビューやパイプラインの統合に何ヶ月もかけず、ゼロから本番稼動まで1週間もかからずにデータ基盤の構築が実現できるようになりました。今やDWHは堅牢で活用しやすいプラットフォームとなり、どんな企業でも手に入れることができ、データ分析における最高のハイテク企業と同等の競争力を持つことができるようになりました。
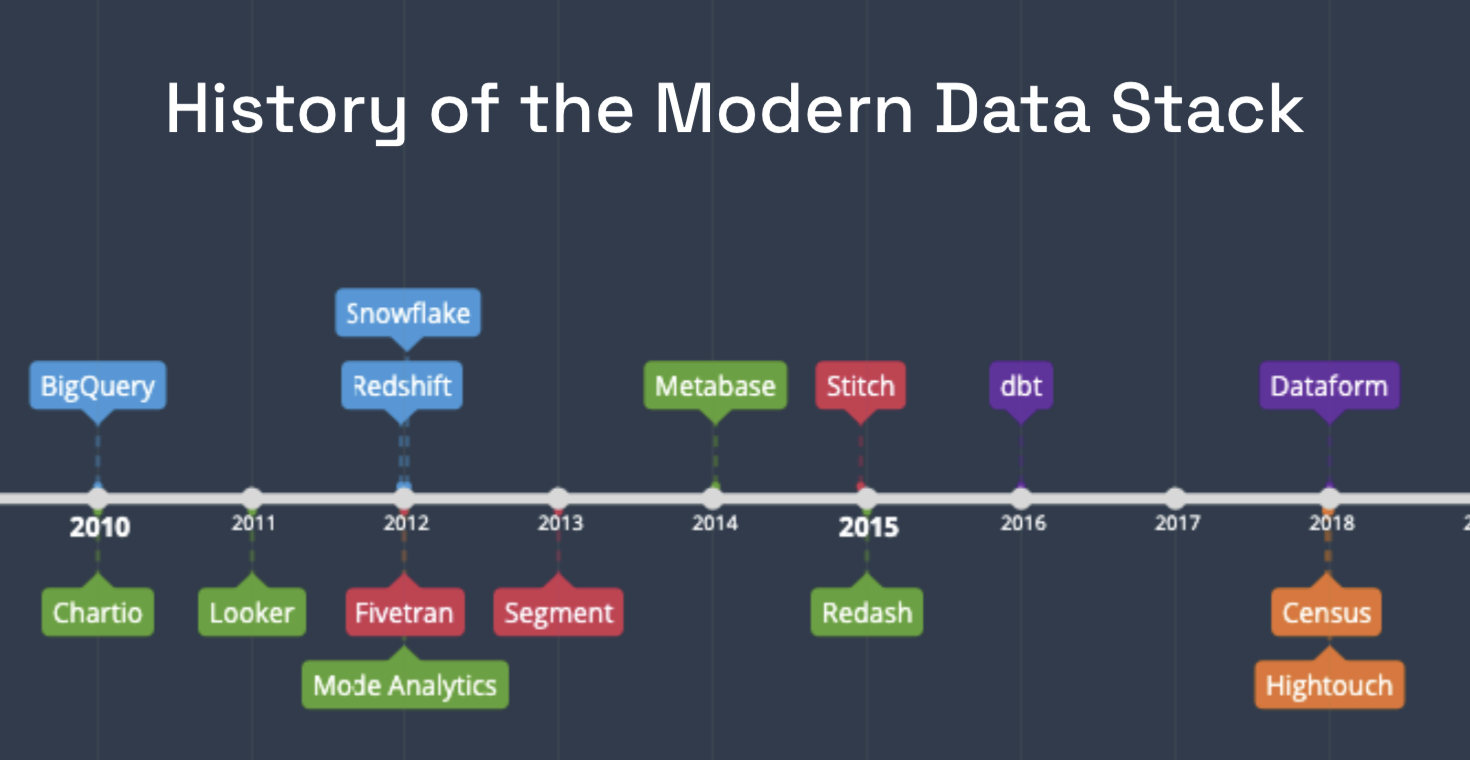
Modern Data Stack のトレンド
データインテグレーション
データの活用領域は年々増加し、企業が扱うSaaSの数が増加しています。以前は各種SaaSからデータを抽出してDWHに入れるためのREST APIを自社開発していましたが、FivetranなどのサービスやAirbyte、MeltanoなどのOSSの登場により、データ統合の自社開発をする必要性が少なくなってきています。多くの企業はは自社開発よりも、データをDWHに同期するだけのマネージドサービスを選択するようになっています。
ELT
近年のクラウドDWHの拡張性や分散システム技術、クエリエンジンの向上により、DWH上で変換処理を行うことが合理的になり、ELTは一般的なアプローチとして定着しつつあります。
dbt
ELTの中心となるソフトウェアがdbtです。dbt(data build tool)とは、 ELTのTを担当するソフトウェアであり、DWHにあるデータを加工してDWHに書き戻します。SQLのSELECT文を知っていれば誰でもdbtでデータマートの開発をすることができます。dbtには主に次の機能や特徴があります。
- SQLのSELECT文だけで開発可能
- スキーマや依存関係に関するドキュメントの自動生成機能
- NULL、参照整合性などの自動テスト機能
- Jinjaによる処理のモジュール化
- データリネージ
- Git、CI / CDなどソフトウェア開発の手法が活用可能
Reverse ETL
Reverse ETLとは、DWHからSaaSへ統合するプロセスや技術のことです。企業はDWHやSaaSの活用が進み、データパイプラインが複雑化し、DWHからサードパーティのSaaSツールにデータを同期させるために各種SaaSのAPIを調査して実装するというコストが大きくなっていきました。そのような背景から、Reverse ETL製品が台頭し、DWHからSaaSへ統合するスクリプトを自社で書く必要性がなくなってきています。
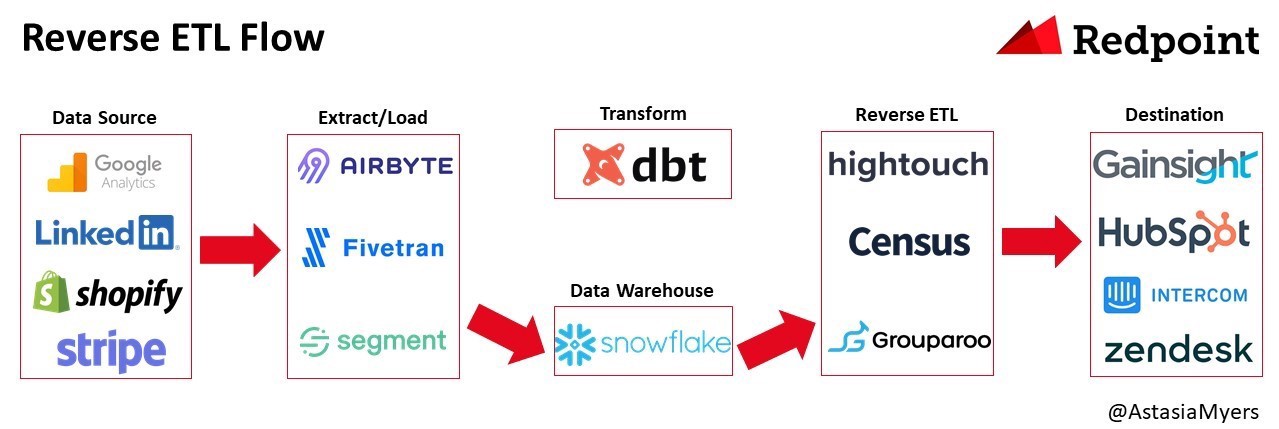
現在は次のようなReverse ETL製品があります。
- Census
- Hightouch
- Grouparoo
- Polytomic
- Rudderstack
- Seekwell
- Workato
テンプレート化された SQL や YAML によるデータ管理
ELTの「T」を管理する方法として、テンプレート化されたSQLとYAMLによって行われるようになってきています。SQLは成熟したインターフェイスであり、習得が容易で宣言的です。これをJinjaのようなテンプレート言語と組み合わせることで、パラメータ化され、よりダイナミックなものにすることが可能になります。また、コード管理することができ、 CI/CDも適用可能です。
データメッシュ
組織の拡大につれて中央集権型のデータ管理は問題になり、非中央集権型データガバナンスである「データメッシュ」という概念が提起されています。
データレイクハウス
DWHは構造化データセットを対象としており、データレイクは非構造化および半構造化データを対象としていますが、近年、データレイクをDWHに統合し、DWHの機能、スキーマ、メタデータをデータレイクで活用できるようにする「データレイクハウス」が登場しています。データレイクハウスの登場の背景には、データ形式などが異なることで保存先が分散していることによる「データのサイロ化」や、データエンジニアリングやデータサイエンス、BIなど、業務ごとに扱うツールが異なることでの「プロセスのサイロ化」などといったAI活用の本格化に伴い浮上することになった各種課題があります。
参考


















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS