
ML システムのサービングパターン
機械学習システムの推論のサービングには様々な方法があります。今回はMercari社の GitHub に記載されている次のMLシステムのサービングのパターンを紹介します。
- Web-singleパターン
- 同期パターン
- 非同期パターン
- バッチパターン
- Prep-predパターン
- 直列マイクロサービスパターン
- 並列マイクロサービスパターン
- 推論キャッシュパターン
- データキャッシュパターン
Web-single パターン
Web-singleパターンはWebサーバーにモデルを同梱させるパターンです。同一サーバーにRESTインターフェイス(もしくはGRPC)と前処理、学習済みモデルをインストールすることにより、シンプルな推論器を生成することができます。
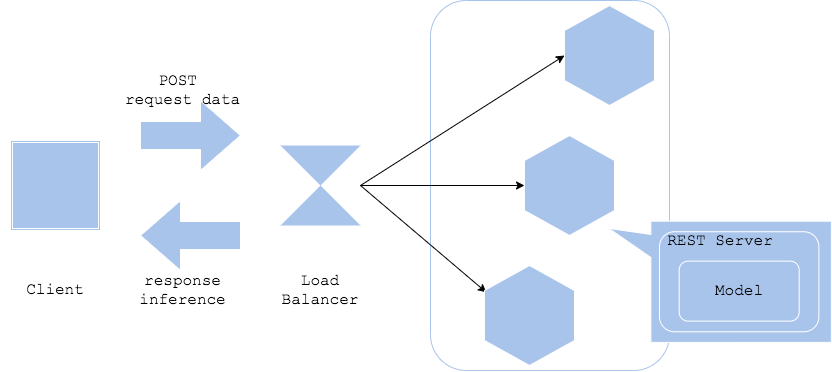
- Pros
- 同一のプログラミング言語でWeb、前処理、推論を実装することができる
- シンプルな構成で運用が容易
- Cons
- コンポーネント(Web、前処理、推論)が同一のコンテナイメージに封入されるため、コンポーネントを個別に更新することができない
- ユースケース
- シンプルな構成で推論器を素早くリリースしたい場合
- 1つのモデルで同期的に推論を返すのみの場合
同期パターン
同期パターンでは、Webサーバーと推論サーバーを分離し、推論を同期的に処理します。クライアントは推論のリクエストに対してレスポンスが得られるまで待機します。
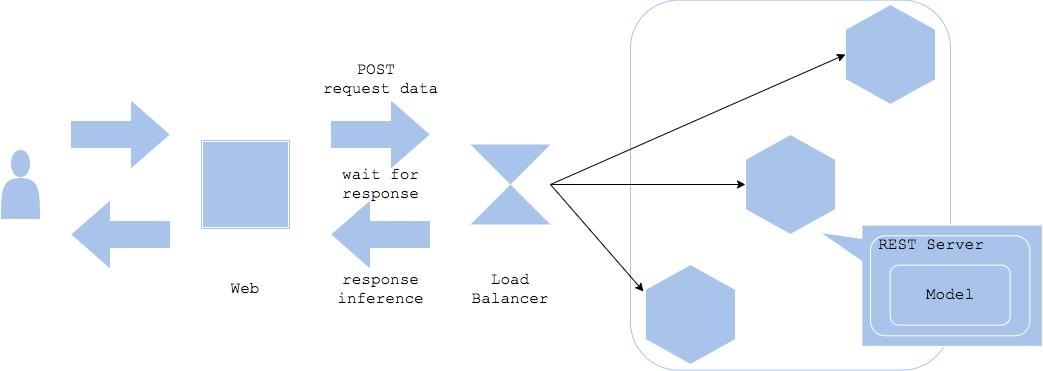
- Pros
- シンプルな構成で運用しやすい。
- 推論が完了するまでクライアントは次の処理に移行しないため、ワークフローを考えやすい。
- Cons
- 推論がパフォーマンスのボトルネックになりやすい。
- 推論の待機時間が発生するため、その間にユーザー体験を低下させない方法を考慮する必要がある。
- ユースケース
- アプリケーションのワークフローとして、推論結果が出るまで次に進めない仕様のとき
- ワークフローが推論結果に依存するとき
非同期パターン
非同期パターンでは、リクエストと推論の中間にキューやキャッシュを配置し、推論リクエストと推論結果の取得を非同期にします。このパターンでは、リクエストと推論を切り離すことにより、クライアントのワークフローで推論時間を待つ必要が無くなります。
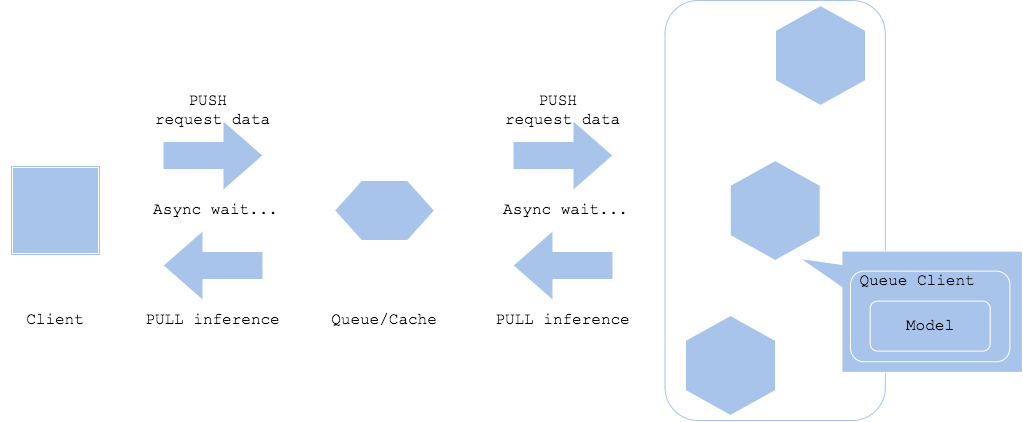
- Pros
- クライアントと推論を切り離すことができる
- 推論の待機時間が長い場合でもクライアントに悪影響が出ることが少ない
- Cons
- キューやキャッシュが必要になる
- リアルタイムな処理には向いていない
- ユースケース
- 直後の動作が推論結果に依存しないワークフロー場合
- クライアントと推論結果の出力先を分離する場合
バッチパターン
推論をリアルタイムに実行する必要がない場合は、バッチジョブを起動して定期的に推論を行うことができます。このパターンでは溜まったデータを夜間など、定期的に推論し、結果を保存することができます。
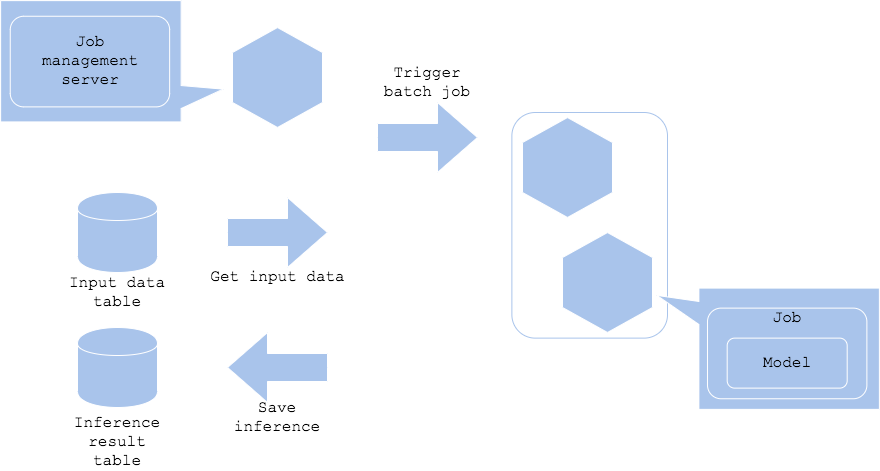
- Pros
- サーバーのリソース管理を柔軟に行うことができる
- 何らかの理由で推論に失敗しても再度推論することができる
- Cons
- ジョブ管理サーバーが必要になる
- ユースケース
- リアルタイムまたは準リアルタイムで推論する必要がない場合
- 過去のデータにまとめて推論を実行したい場合
夜間、毎時、毎月など、定期的にデータを推論したい場合
Prep-pred パターン
前処理と推論では必要なリソースやライブラリが異なることがあります。その場合は前処理と推論でサーバーやコンテナを分割し、開発と運用を効率化することができます。前処理器と推論器を分割するため、効率的なリソース活用や個別開発、障害分離が可能になる一方、それぞれのリソースのチューニングや相互のネットワーク設計、バージョニングが必要になります。ディープラーニングを推論器に使用する場合はこのパターンになることが多いです。
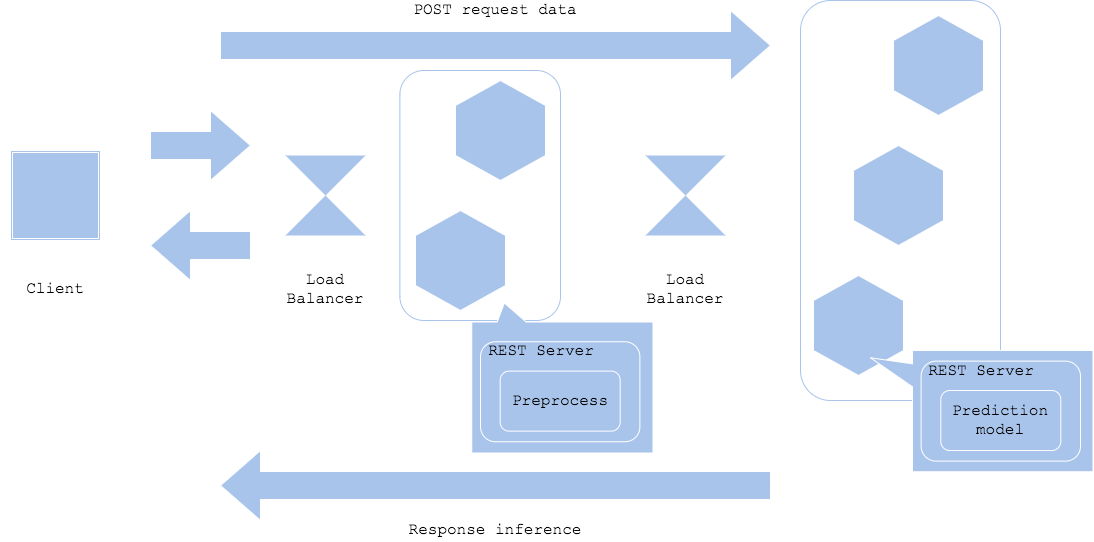
Simple prep-pred pattern
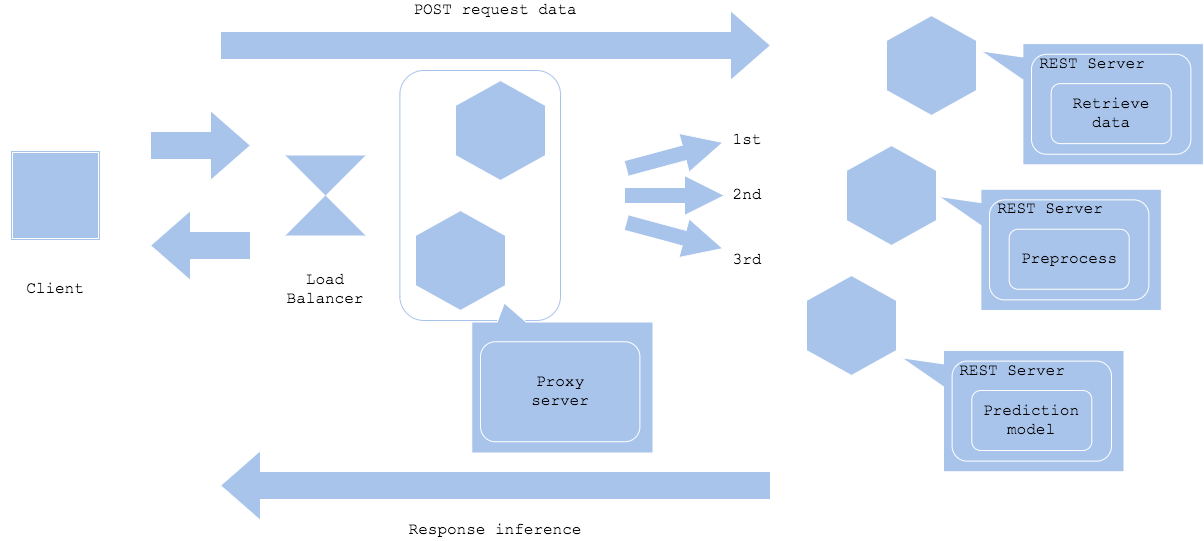
Microservice prep-pred pattern
- Pros
- 障害分離が可能になる
- ライブラリの選定やリソースの増減が柔軟になる
- Cons
- 管理対象のサーバーやネットワーク構成が複雑になり、運用負荷が増加する
- 前処理サーバーと推論サーバーとのネットワークがボトルネックになる場合がある
- ユースケース
- 前処理と推論でライブラリやコードベース、リソース負荷が異なる場合
- 前処理と推論を分割することで可用性を向上させたい場合
直列マイクロサービスパターン
複数の推論モデルを順列に実行したい場合は、複数の機械学習モデルを別サーバーで並列して配置します。それぞれに順番に推論リクエストを送信し、最後の推論を集計した後に推論結果を得ます。
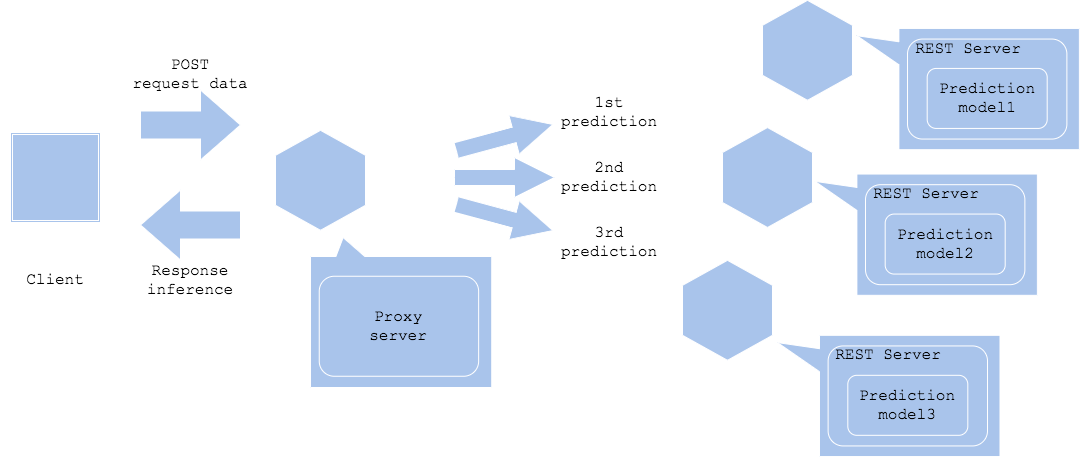
- Pros
- 各推論モデルを順番に実行することができる
- 前の推論モデルの結果次第で次モデルの推論リクエスト先を選択する構成とすることができる
- 各推論でサーバーやコードベースを分割することで、リソースの効率化や障害分離が可能。
- Cons
- 複数の推論を順番に実行するため、所要時間が長くなる場合がある
- 前の推論結果を得られないと次の推論を実行することができず、ボトルネックになる
- システム構成が複雑になる可能性がある
- ユースケース
- 1つの操作に対して複数の推論を実行する場合
- 複数の推論間で実行順や依存関係がある場合
並列マイクロサービスパターン
並列マイクロサービスパターンでは、各推論サーバーに平行して推論リクエストを送信し、複数の推論結果を得ます。
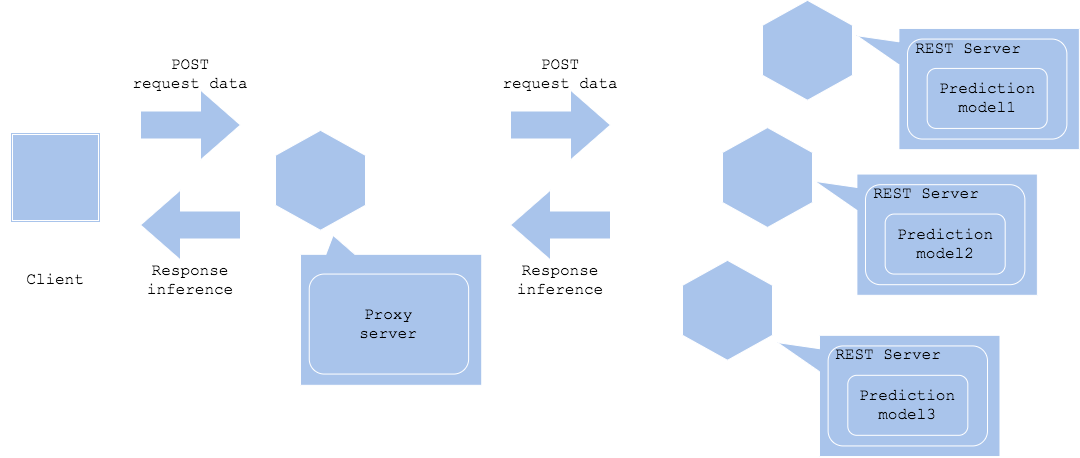
Synchronized horizontal
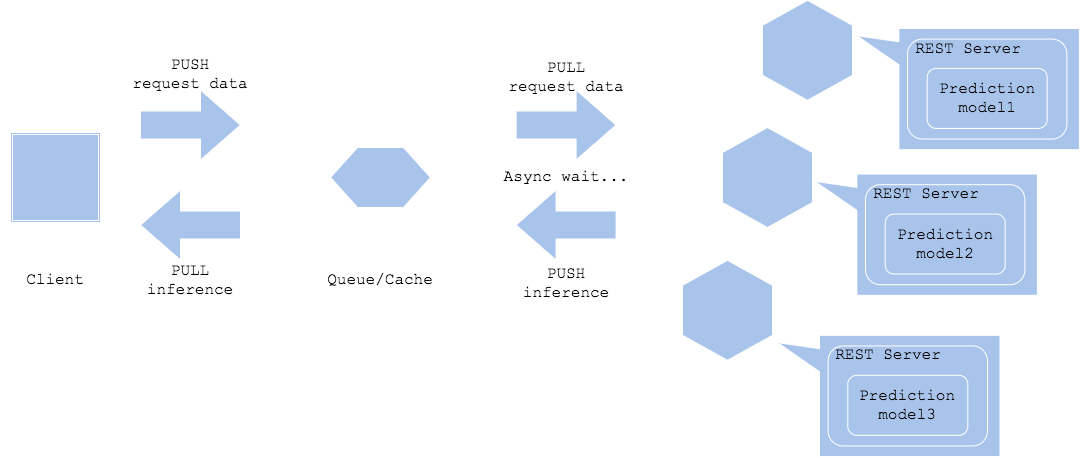
Asynchronized horizontal
- Pros
- 推論サーバーを分割することでリソースの調整や障害分離が可能となる
- 推論のワークフロー間で依存関係を持たせずに柔軟にシステムを構築することができる
- Cons
- 複数の推論を稼働させるため、システムが複雑になる場合がある
- 同期的に実行する場合、所要時間が最遅の推論に依存する
- 非同期に実行する場合、推論サーバー間の所要時間の差を後段のワークフローで吸収する必要がある
- ユースケース
- 依存関係のない複数の推論を平行して実行する場合
- 複数の推論結果を最後に集計するワークフローの場合
推論キャッシュパターン
推論キャッシュパターンでは、推論結果をキャッシュに格納し、同一データの推論をキャッシュ検索します。
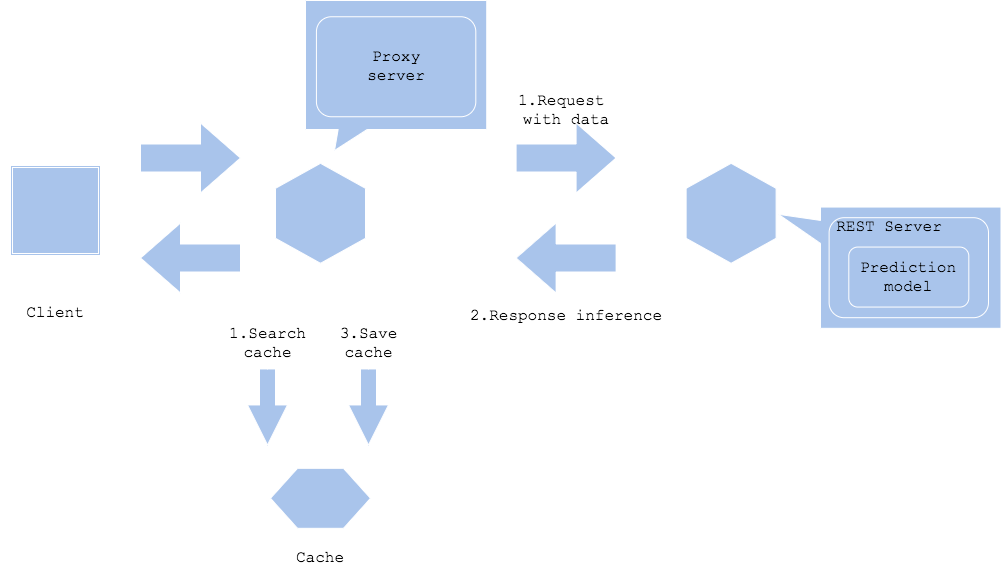
- Pros
- 推論速度を改善し、推論サーバーへの負荷をオフロードすることができる
- Cons
- キャッシュサーバーのコストが発生する(多くのキャッシュはストレージよりもコストが高く、容量が小さい傾向にある)
- キャッシュクリアの方針を考える必要がある
- ユースケース
- 同一データの推論リクエストが頻繁に発生する場合
- キャッシュのキーで検索可能な入力データの場合
- 推論を高速に処理したい場合
データキャッシュパターン
データキャッシュパターンでは、データをキャッシュします。画像やテキストなどのコンテンツはデータ容量が大きい傾向にあります。入力データや前処理データのサイズが大きい場合はデータキャッシュによりデータ取得の負荷を軽減することができます。
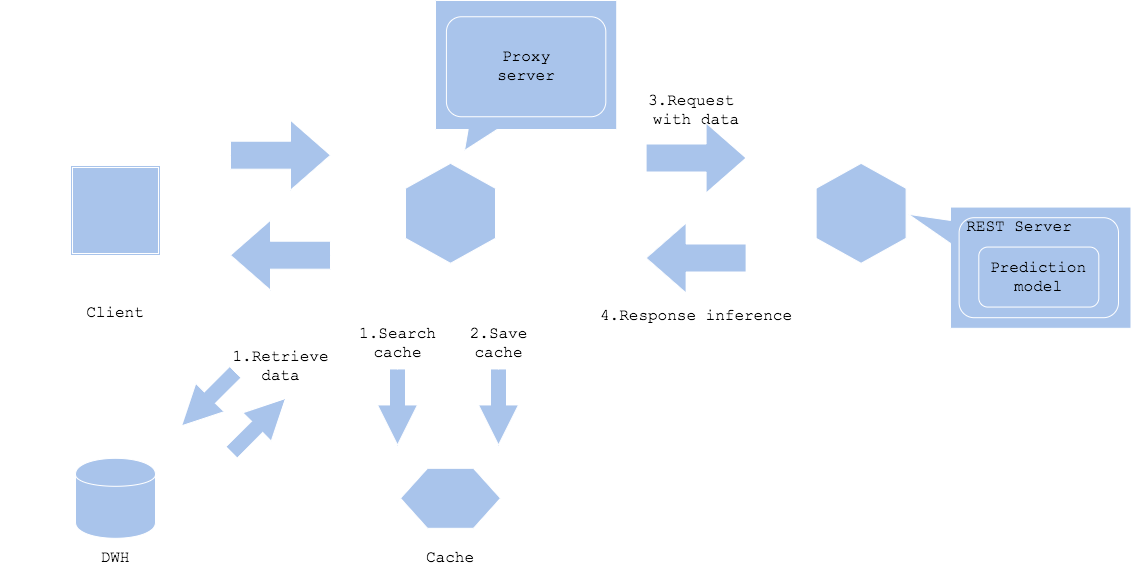
Input data cache
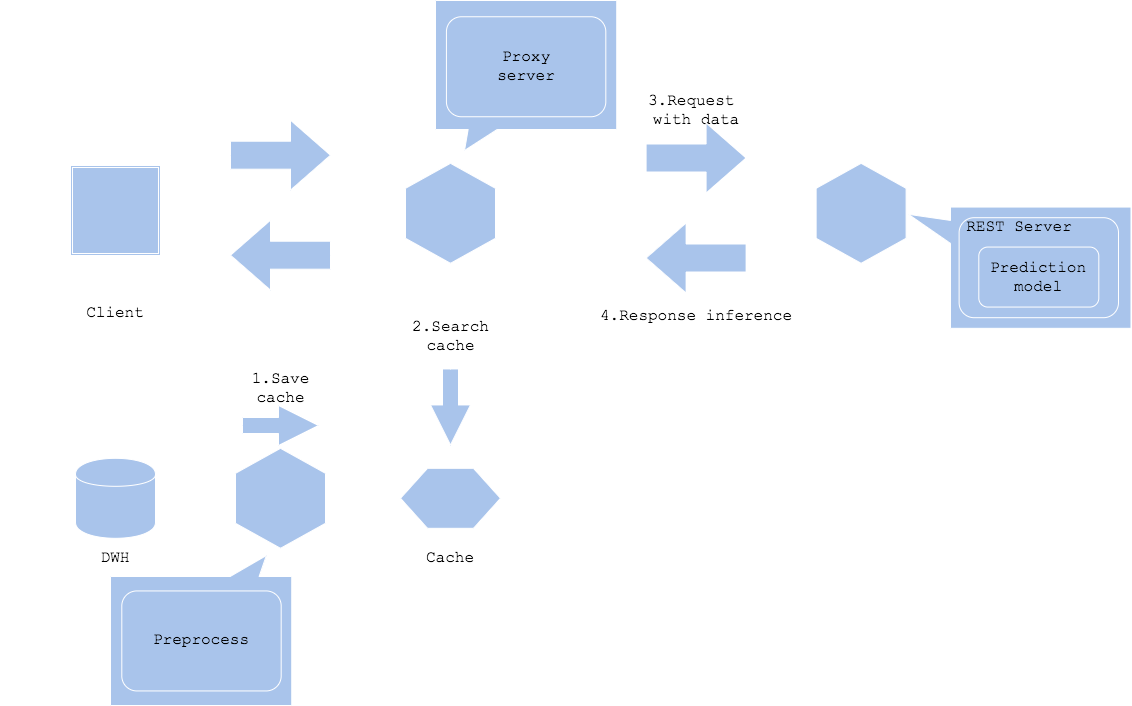
Preprocessed data cache
- Pros
- データ取得や前処理のオーバーヘッドを削減することができる
- 高速に推論を開始することができる
- Cons
- キャッシュサーバーのコストが発生する
- キャッシュクリアの方針を考える必要がある
- ユースケース
- 同一データの推論リクエストが発生するワークフローの場合
- 同じデータを繰り返し入力データとする場合
- キャッシュのキーで検索可能な入力データの場合
- データ処理を高速にしたい場合
参考


















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS