

dbt とは
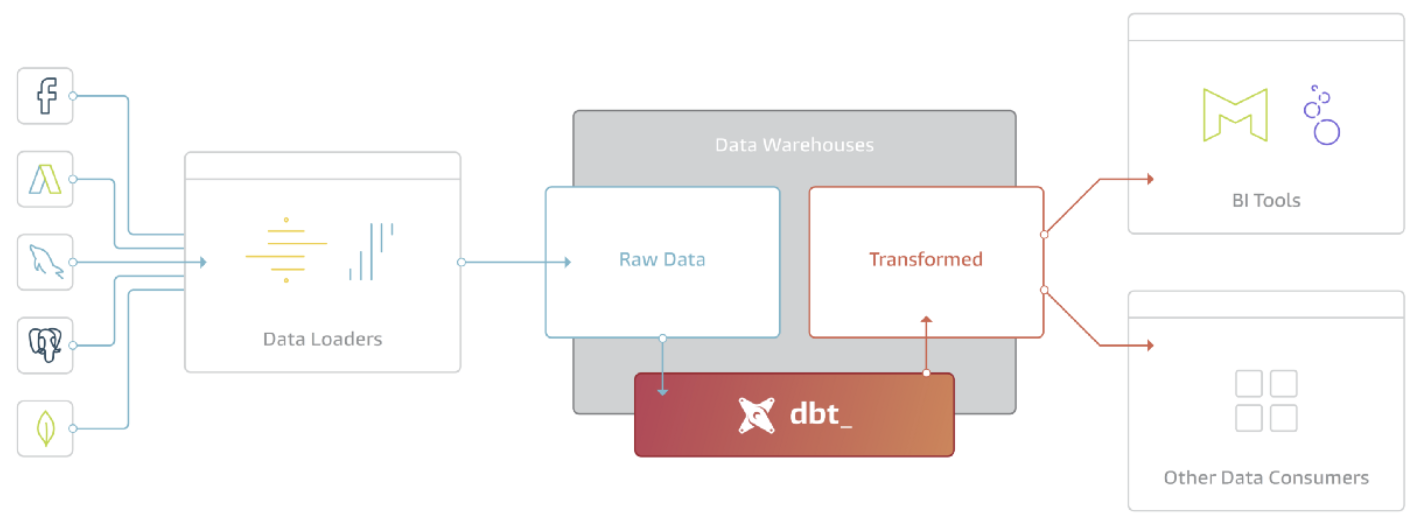
dbtとは、ELT(Extract、 Load、 Transform)のTを担当するツールです。dbtはあくまでデータ変換のみを実行するツールであり、データがAmazon RedshiftやGoogle BigQuery, Snowflakeなどのデータウェアハウス(DWH)上にすでにロードされていることを前提とし、ロードから先のデータ変換をdbtが担います。言い換えると、dbtはDWHに保存されているデータを加工し、加工結果をDWHに書き戻すツールになります。
dbt の特徴
dbtには主に次の特徴があります。
- SQL ベース
dbtではSQLのSELECTでデータの変換処理を記述します。 - Jinja による高度なクエリ処理
dbtではSQL内に軽量なテンプレート言語である Jinja を使うことができます。そのため、SQLにifやforなど制御構文を使用したり、処理をモジュール化することができます。 - ドキュメンテーション
dbtはSQLに記述されているモデル間の依存関係を把握し、各モデルのスキーマやデータリネージを含むドキュメントを自動で生成することができます。 - テスト機能
dbtではデータに対してNULLや参照整合性のチェックをすることができます。
dbt の利用方法
dbtは次の2種類の方法で利用することができます。
- dbt Core(OSS)
- dbt Cloud(SaaS)
dbt CoreはOSSなので無料で使うことが可能です。対してdbt CloudはSaaSであり、マネージドになります。dbt Cloudは一人だけの利用であれば無料ですが、複数人の利用の場合は有料になります。
dbt Cloudはdbt Coreの機能に加えて次の機能があります。
- 開発機能
dbtを利用した開発を1画面で行えるようにIDEが提供されます。 - 通知機能
Slackなどと連携することができます。 - ジョブ管理
ジョブを設定し、スケジュール実行する機能が提供されます。 - 環境変数の管理
環境ごとに設定や変数を管理することができます。 - ソースコード管理
dbtのコードを管理するためのgitレポジトリがデフォルトで提供されるため、GitHubなどが無くても開始することができます。
dbt Core のチュートリアル
dbt Coreを使ってBigQueryのデータを加工してみます。BigQueryにjaffle_shopという架空のECサイトのデータセットがあるとします。データセットには次のテーブルが存在します。
raw_customersraw_ordersraw_payments
プロジェクト作成
まずはdbt Coreをインストールします。dbt Coreのインストール方法は次の 4 種類があります。
- Homebrewを使用
- pipを使用
- Dockerイメージを使用
- Githubのソースコードを使用
今回はpipでインストールしたdbt Coreをインストールします。
$ mkdir dbt-projects && cd dbt-projects
$ python -m venv venv
$ source venv/bin/activate
$ pip install --upgrade pip
$ pip install dbt-bigquery
dbtのバージョンを確認します。
$ dbt --version
Core:
- installed: 1.3.1
- latest: 1.3.1 - Up to date!
Plugins:
- bigquery: 1.3.0 - Up to date!
jaffle_shopという名前のプロジェクトを作成します。インタラクティブに質問されるので答えていきます。
$ dbt init jaffle_shop
04:58:32 Running with dbt=1.3.1
Which database would you like to use?
[1] bigquery
(Don't see the one you want? https://docs.getdbt.com/docs/available-adapters)
Enter a number: 1
[1] oauth
[2] service_account
Desired authentication method option (enter a number): 2
keyfile (/path/to/bigquery/keyfile.json): </PATH/TO/YOUR CLIENT SECRET FILE> (e.g., /Users/BBaggins/.dbt/dbt-tutorial-project-331118.json)
project (GCP project id): <PROJECT ID>
dataset (the name of your dbt dataset): jaffle_shop
threads (1 or more): 1
job_execution_timeout_seconds [300]: 300
[1] US
[2] EU
Desired location option (enter a number): 1
04:59:32 Profile jaffle_shop written to /Users/xxx/.dbt/profiles.yml using target's profile_template.yml and your supplied values. Run 'dbt debug' to validate the connection.
04:59:32
Your new dbt project "jaffle_shop" was created!
For more information on how to configure the profiles.yml file,
please consult the dbt documentation here:
https://docs.getdbt.com/docs/configure-your-profile
One more thing:
Need help? Don't hesitate to reach out to us via GitHub issues or on Slack:
https://community.getdbt.com/
Happy modeling!
次のようにプロジェクトが作成されました。
.
├── jaffle_shop
│ ├── README.md
│ ├── analyses
│ ├── dbt_project.yml
│ ├── macros
│ ├── models
│ │ └── example
│ │ ├── my_first_dbt_model.sql
│ │ ├── my_second_dbt_model.sql
│ │ └── schema.yml
│ ├── seeds
│ ├── snapshots
│ └── tests
└── logs
└── dbt.log
また、~/.dbt/profiles.ymlにyamlファイル作成されています。
$ cat ~/.dbt/profiles.yml
jaffle_shop:
outputs:
dev:
dataset: jaffle_shop
job_execution_timeout_seconds: 300
job_retries: 1
keyfile: <PATH TO CLIENT SECRET FILE>
location: US
method: service-account
priority: interactive
project: <PROJECT ID>
threads: 1
type: bigquery
target: dev
次のコマンドでBigQueryとの接続を確認することができます。
$ dbt debug
Connection test: [OK connection ok]
モデリング
modelsディレクトリにcustomers.sqlというファイルを作成します。そしてcustomers.sqlファイルに次のSQLを記述します。
with customers as (
select
id as customer_id,
first_name,
last_name
from jaffle_shop.raw_customers
),
orders as (
select
id as order_id,
user_id as customer_id,
order_date,
status
from jaffle_shop.raw_orders
),
customer_orders as (
select
customer_id,
min(order_date) as first_order_date,
max(order_date) as most_recent_order_date,
count(order_id) as number_of_orders
from orders
group by 1
),
final as (
select
customers.customer_id,
customers.first_name,
customers.last_name,
customer_orders.first_order_date,
customer_orders.most_recent_order_date,
coalesce(customer_orders.number_of_orders, 0) as number_of_orders
from customers
left join customer_orders using (customer_id)
)
select * from final
/models/exampleフォルダを削除し、dbt_project.ymlのmodelsを次のように編集します。
models:
+ jaffle_shop:
+ +materialized: table
- example:
- +materialized: view
models:
jaffle_shop:
+materialized: table
ディレクトリは次のようになります。
.
├── jaffle_shop
│ ├── README.md
│ ├── analyses
│ ├── dbt_project.yml
│ ├── macros
│ ├── models
│ │ └── customers.sql
│ ├── seeds
│ ├── snapshots
│ └── tests
└── logs
└── dbt.log
dbt runで/modelsディレクトリ下にある.sqlファイルからBigQueryにテーブルを作成します。
$ dbt run
これでBigQueryのデータセットjaffle_shopにcustomersテーブルが作成されます。
参考

















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS