



Pendahuluan
Artikel ini akan menunjukkan cara mengimplementasikan pengklasifikasi random forest dengan menggunakan dataset Titanic dari library seaborn.
Persiapan dataset
Pertama-tama, mari kita impor library yang diperlukan dan memuat dataset Titanic.
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import matplotlib.pyplot as plt
# Memuat dataset
data = sns.load_dataset('titanic')
# Menghapus kolom yang tidak diperlukan
data = data.drop(['deck', 'embark_town', 'alive', 'who', 'adult_male', 'class'], axis=1)
# Mengatasi nilai yang hilang
data['age'] = data['age'].fillna(data['age'].median())
data['embarked'] = data['embarked'].fillna(data['embarked'].mode()[0])
# Mengkodekan variabel kategorikal
encoder = LabelEncoder()
data['sex'] = encoder.fit_transform(data['sex'])
data['embarked'] = encoder.fit_transform(data['embarked'])
# Membagi dataset menjadi set pelatihan dan pengujian
X = data.drop('survived', axis=1)
y = data['survived']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
Membangun model
Selanjutnya, kita akan membuat pengklasifikasi random forest dengan menggunakan scikit-learn.
# Membuat pengklasifikasi random forest dengan hiperparameter tambahan
rf_clf = RandomForestClassifier(
n_estimators=100, # Number of trees in the forest
criterion='gini', # Function to measure the quality of a split ('gini' or 'entropy')
max_depth=None, # Maximum depth of the tree (None means nodes are expanded until all leaves are pure)
min_samples_split=2, # Minimum number of samples required to split an internal node
min_samples_leaf=1, # Minimum number of samples required to be at a leaf node
max_features='auto', # Number of features to consider when looking for the best split ('auto', 'sqrt', 'log2', or an integer)
bootstrap=True, # Whether bootstrap samples are used when building trees
oob_score=False, # Whether to use out-of-bag samples to estimate the generalization accuracy
n_jobs=None, # Number of jobs to run in parallel for both fit and predict (-1 means using all processors)
random_state=42, # Controls both the randomness of the bootstrapping and feature sampling
verbose=0, # Controls the verbosity when fitting and predicting
warm_start=False, # Reuse the solution of the previous call to fit and add more estimators to the ensemble
class_weight=None # Weights associated with classes (None or 'balanced')
)
Berikut ini adalah penjelasan singkat mengenai hiperparameter tambahan:
-
n_estimators
Merupakan jumlah pohon keputusan dalam ensemble random forest. Dengan kata lain, mengontrol ukuran hutan dengan menentukan berapa banyak pohon yang akan dibangun dan digabungkan. Secara default, nilai ini diatur pada 100, yang berarti random forest akan terdiri dari 100 pohon keputusan. -
criterion
Fungsi yang digunakan untuk mengukur kualitas pemisahan. Kriteria yang didukung adalah"gini"untuk impuritas Gini dan"entropy"untuk gain informasi. Secara default, diatur menjadi"gini". -
max_depth
Kedalaman maksimum dari pohon. JikaNone, maka node diperluas hingga semua daun murni atau semua daun mengandung kurang dari sampel minimum untuk dibagi. Nilai yang lebih tinggi dapat menyebabkan overfitting, sedangkan nilai yang lebih rendah dapat menghasilkan underfitting. -
min_samples_split
Jumlah sampel minimum yang diperlukan untuk membagi node internal. Meningkatkan nilai ini dapat mengurangi overfitting namun dapat menghasilkan model yang kurang akurat. -
min_samples_leaf
Jumlah sampel minimum yang diperlukan pada suatu node daun. Meningkatkan nilai ini dapat mengurangi overfitting namun dapat menghasilkan model yang kurang akurat. -
max_features
Jumlah fitur yang dipertimbangkan saat mencari pemisahan terbaik. Dapat diatur menjadi'auto','sqrt','log2', atau sebuah bilangan bulat. Jika'auto', makamax_features=sqrt(n_features)digunakan. Jika 'sqrt', makamax_features=sqrt(n_features)digunakan. Jika'log2', makamax_features=log2(n_features)digunakan. Jika sebuah bilangan bulat, maka jumlah fitur dipertimbangkan pada setiap pemisahan. -
bootstrap
Menentukan apakah sampel bootstrap digunakan saat membangun pohon. JikaFalse, keseluruhan dataset digunakan untuk membangun setiap pohon. -
oob_score
Menentukan apakah sampel out-of-bag digunakan untuk memperkirakan akurasi generalisasi. Sampel out-of-bag adalah sampel yang tidak digunakan dalam sampel bootstrap untuk pohon tertentu. -
n_jobs
Jumlah pekerjaan yang berjalan secara paralel baik saat fit maupun prediksi.-1artinya semua processor digunakan. -
verbose
Mengontrol kecerewetan saat memfitting dan memprediksi. Nilai yang lebih tinggi akan menghasilkan lebih banyak informasi selama proses tersebut. -
warm_start
Saat diatur menjadi True, mengunakan solusi pemanggilan sebelumnya untuk fit dan menambahkan estimator baru pada ensemble. Ini dapat menghemat waktu saat menyesuaikan hiperparameter secara iteratif, karena menggunakan kembali pohon yang telah dilatih sebelumnya dan menambahkan pohon baru, daripada melatih semua pohon dari awal. -
class_weight
Bobot yang terkait dengan kelas. JikaNone, semua kelas dianggap memiliki bobot yang sama. Jika'balanced', bobot kelas disesuaikan berdasarkan jumlah sampel di setiap kelas. Ini dapat berguna saat menangani dataset yang tidak seimbang.
Pelatihan dan evaluasi
Selanjutnya, mari latih classifier random forest pada data training dan evaluasi performanya pada data testing.
# Train the model
rf_clf.fit(X_train, y_train)
# Make predictions on the test set
y_pred = rf_clf.predict(X_test)
# Evaluate the model
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
print("Classification Report:")
print(classification_report(y_test, y_pred))
print("Confusion Matrix:")
print(confusion_matrix(y_test, y_pred))
Accuracy: 0.78
Classification Report:
precision recall f1-score support
0 0.80 0.83 0.81 157
1 0.74 0.70 0.72 111
accuracy 0.78 268
macro avg 0.77 0.77 0.77 268
weighted avg 0.77 0.78 0.78 268
Confusion Matrix:
[[130 27]
[ 33 78]]
Visualisasi kepentingan fitur
Terakhir, kita akan memvisualisasikan kepentingan fitur dari model random forest.
# Calculate feature importances
importances = rf_clf.feature_importances_
# Sort feature importances in descending order
indices = np.argsort(importances)[::-1]
# Rearrange feature names so they match the sorted feature importances
names = [X.columns[i] for i in indices]
# Create a bar plot
plt.figure(figsize=(10, 5))
plt.title("Feature Importance")
plt.bar(range(X.shape[1]), importances[indices])
# Add feature names as x-axis labels
plt.xticks(range(X.shape[1]), names, rotation=90)
# Show the plot
plt.show()
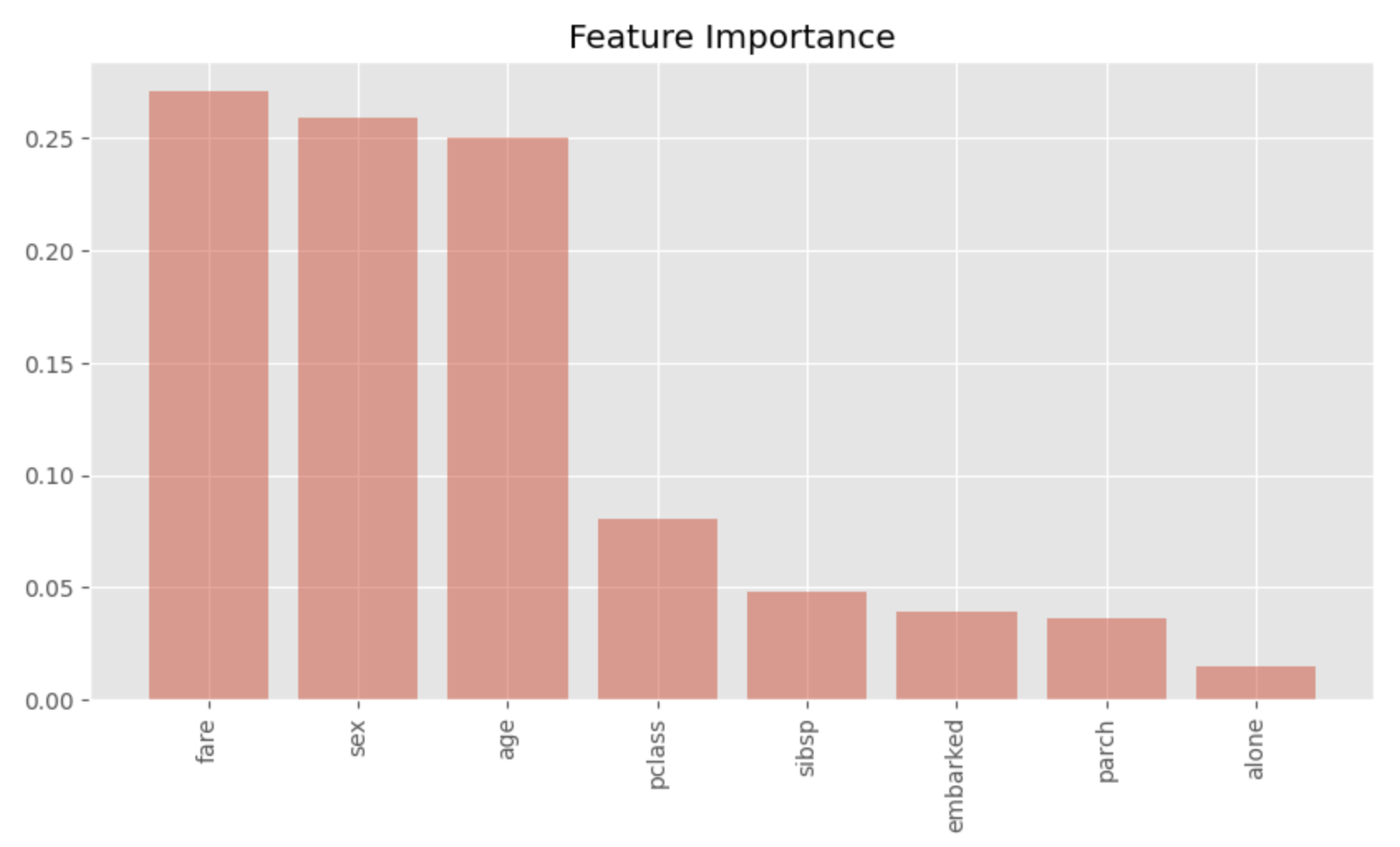
Dengan memplotnya seperti ini, kita bisa melihat dengan sekilas fitur mana yang penting. Kita bisa melihat bahwa sex, age dan fare sangat penting. Hasil ini cukup meyakinkan sebagai faktor penting yang membuat perbedaan antara hidup dan mati di Titanic.















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS