



Pengantar
Klasifikasi teks adalah salah satu tugas umum dalam NLP dan dapat digunakan untuk berbagai macam aplikasi. Pada artikel ini, saya akan menggunakan DistilBERT untuk melakukan analisis sentimen, sebuah bentuk klasifikasi teks.
Ekosistem Hugging Face
Ekosistem Hugging Face memudahkan pengembangan model yang disesuaikan dengan baik untuk menyimpulkan dari teks mentah.
Dengan ekosistem Hugging Face, pengembangan dilakukan dengan alur sebagai berikut:
- Dapatkan dataset
Cari di halaman Hugging Face untuk mendapatkan dataset untuk tugas yang ingin Anda selesaikan (jika Anda tidak menemukan dataset yang sesuai, buatlah dataset Anda sendiri) - Dapatkan Tokenizer
Dapatkan Tokenizer yang cocok dengan model yang telah Anda latih sebelumnya - Tokenisasi
Memproses dataset dengan Tokenizer - Dapatkan model
Dapatkan model yang telah dilatih sebelumnya - Pelatihan
Jalankan pelatihan - Inferensi
Inferensi oleh model
Berikut ini, kita mengikuti alur di atas untuk mengembangkan model di lingkungan Google Colab.
Instal pustaka
Instal pustaka berikut ini.
!pip install transformers
!pip install datasets
Dapatkan dataset
Anda harus terlebih dahulu menemukan dataset untuk digunakan.
Hugging Face menawarkan banyak sekali dataset. Dataset dapat ditemukan di tautan berikut.
Untuk mengunduh data dari Hugging Face Hub, gunakan pustaka dataset. Pada artikel ini, saya akan mengunduh dataset bernama emotion.
from datasets import load_dataset
dataset = load_dataset("emotion")
Periksa isi kumpulan data yang diperoleh.
>> dataset
DatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 16000
})
validation: Dataset({
features: ['text', 'label'],
num_rows: 2000
})
test: Dataset({
features: ['text', 'label'],
num_rows: 2000
})
})
Dataset dibagi menjadi train, validasi, dan test, yang masing-masing memiliki informasi seperti teks dan label.
Dataset dapat diperlakukan sebagai DataFrame dengan mengatur format ke pandas.
dataset.set_format(type="pandas")
train_df = dataset["train"][:]
>> train_df.head(5)
| | text | label |
| --- | ------------------------------------------------- | ----- |
| 0 | i didnt feel humiliated | 0 |
| 1 | i can go from feeling so hopeless to so damned... | 0 |
| 2 | im grabbing a minute to post i feel greedy wrong | 3 |
| 3 | i am ever feeling nostalgic about the fireplac... | 2 |
| 4 | i am feeling grouchy | 3 |
Periksa rincian label.
>> train_df.value_counts(["label"])
label
1 5362
0 4666
3 2159
4 1937
2 1304
5 572
dtype: int64
Kita dapat melihat bahwa ada enam label yang berbeda. Arti setiap label dapat diperiksa menggunakan features.
>> dataset["train"].features
{'text': Value(dtype='string', id=None),
'label': ClassLabel(names=['sadness', 'joy', 'love', 'anger', 'fear', 'surprise'], id=None)}
label adalah sebuah kelas ClassLabel dan tampaknya ditetapkan sebagai berikut.
- 0: sadness
- 1: joy
- 2: love
- 3: anger
- 4: fear
- 5: surprise
Metode int2str() dari kelas ClassLabel dapat digunakan untuk membuat kolom baru di DataFrame yang sesuai dengan nama label.
def label_int2str(x):
return dataset["train"].features["label"].int2str(x)
train_df["label_name"] = train_df["label"].apply(label_int2str)
>> train_df.head()
| | text | label | label_name |
| --- | ------------------------------------------------- | ----- | ---------- |
| 0 | i didnt feel humiliated | 0 | sadness |
| 1 | i can go from feeling so hopeless to so damned... | 0 | sadness |
| 2 | im grabbing a minute to post i feel greedy wrong | 3 | anger |
| 3 | i am ever feeling nostalgic about the fireplac... | 2 | love |
| 4 | i am feeling grouchy | 3 | anger |
Terakhir, kembalikan pemformatan yang telah dilakukan ke DataFrame.
dataset.reset_format()
Dapatkan Tokenizer
Hugging Face menyediakan kelas AutoTokenizer yang mudah digunakan yang memungkinkan Anda memuat Tokenizer yang terkait dengan model yang telah dilatih sebelumnya dengan cepat.
Tokenizer dapat dimuat hanya dengan memanggil metode from_pretrained() dengan ID model pada Hub atau jalur file lokal. Dalam kasus ini, kita akan memuat distilbert-base-uncased, yang merupakan Tokenizer untuk DistilBERT.
from transformers import AutoTokenizer
model_ckpt = "distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
Siapkan contoh teks dan jalankan Tokenizer.
sample_text = "\
DistilBERT is a small, fast, cheap and light Transformer model based on the BERT architecture. \
Knowledge distillation is performed during the pre-training step to reduce the size of a BERT model by 40% \
"
Hasil dari Tokenizer adalah sebagai berikut.
sample_text_encoded = tokenizer(sample_text)
print(sample_text_encoded)
{'input_ids': [101, 4487, ..., 1003, 102], 'attention_mask': [1, 1, ..., 1, 1]}
Teks yang dikodekan oleh Tokenizer berisi input_ids dan attention_mask.
input_ids adalah token yang dikodekan dengan angka.
attention_mask adalah sebuah topeng untuk menentukan apakah token tersebut valid untuk model-model selanjutnya. Token yang tidak valid, seperti [PAD], diproses dengan attention_mask yang disetel ke 0.
Metode convert_ids_to_tokens() dapat digunakan untuk mendapatkan string token.
tokens = tokenizer.convert_ids_to_tokens(sample_text_encoded.input_ids)
print(tokens)
['[CLS]', 'di', '##sti', '##lbert', 'is', 'a', 'small', ',', 'fast', ',', 'cheap', 'and', 'light', 'transform', '##er', 'model', 'based', 'on', 'the', 'bert', 'architecture', '.', 'knowledge', 'di', '##sti', '##llation', 'is', 'performed', 'during', 'the', 'pre', '-', 'training', 'step', 'to', 'reduce', 'the', 'size', 'of', 'a', 'bert', 'model', 'by', '40', '%', '[SEP]']
Awalan ## mengindikasikan bahwa string telah dipecah menjadi beberapa subkata.
Anda dapat menggunakan convert_tokens_to_string() untuk merekonstruksi string.
decode_text = tokenizer.convert_tokens_to_string(tokens)
print(decode_text)
[CLS] distilbert is a small, fast, cheap and light transformer model based on the bert architecture. knowledge distillation is performed during the pre - training step to reduce the size of a bert model by 40 % [SEP]
Tokenisasi
Untuk menerapkan proses tokenisasi ke seluruh kumpulan data, tentukan sebuah fungsi untuk memprosesnya secara batch dan gunakan map untuk melakukannya.
def tokenize(batch):
return tokenizer(
batch["text"],
padding=True,
truncation=True
)
Jika padding=True ditentukan, batch akan diisi dengan angka nol hingga ukuran yang terpanjang dalam batch, dan jika truncation=True ditentukan, batch akan dipotong melebihi ukuran konteks maksimum yang didukung oleh model.
Ukuran konteks maksimum yang didukung oleh model dapat ditemukan di bawah ini.
>> tokenizer.model_max_length
512
Menerapkan tokenisasi ke seluruh kumpulan data. batched=True untuk batch, batch_size=None untuk membuat seluruh set menjadi satu batch.
dataset_encoded = dataset.map(tokenize, batched=True, batch_size=None)
>> dataset_encoded
DatasetDict({
train: Dataset({
features: ['text', 'label', 'input_ids', 'attention_mask'],
num_rows: 16000
})
validation: Dataset({
features: ['text', 'label', 'input_ids', 'attention_mask'],
num_rows: 2000
})
test: Dataset({
features: ['text', 'label', 'input_ids', 'attention_mask'],
num_rows: 2000
})
})
Anda dapat melihat bahwa kolom telah ditambahkan ke seluruh kumpulan data.
Anda dapat memeriksa hasilnya berdasarkan sampel per sampel menggunakan DataFrame atau sejenisnya.
import pandas as pd
sample_encoded = dataset_encoded["train"][0]
pd.DataFrame(
[sample_encoded["input_ids"]
, sample_encoded["attention_mask"]
, tokenizer.convert_ids_to_tokens(sample_encoded["input_ids"])],
['input_ids', 'attention_mask', "tokens"]
).T
| | input_ids | attention_mask | tokens |
| --- | --------- | -------------- | ------ |
| 0 | 101 | 1 | \[CLS] |
| 1 | 1045 | 1 | i |
| 2 | 2134 | 1 | didn |
| 3 | 2102 | 1 | ##t |
| 4 | 2514 | 1 | feel |
| ... | ... | ... | ... |
| 82 | 0 | 0 | \[PAD] |
| 83 | 0 | 0 | \[PAD] |
| 84 | 0 | 0 | \[PAD] |
| 85 | 0 | 0 | \[PAD] |
| 86 | 0 | 0 | \[PAD] |
Dapatkan model
Model yang telah dilatih sebelumnya dapat diambil dari yang berikut ini.
Kelas khusus sudah disiapkan untuk tugas mengklasifikasikan teks dalam unit seri.
import torch
from transformers import AutoModelForSequenceClassification, EvalPrediction
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
num_labels = len(dataset_encoded["train"].features["label"].names)
model = AutoModelForSequenceClassification.from_pretrained(model_ckpt, num_labels=num_labels).to(device)
Pelatihan
Pertama, tentukan metrik yang akan digunakan selama pelatihan sebagai sebuah fungsi.
from sklearn.metrics import accuracy_score, f1_score
def compute_metrics(pred: EvalPrediction):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
f1 = f1_score(labels, preds, average="weighted")
acc = accuracy_score(labels, preds)
return {"accuracy": acc, "f1": f1}
Kemudian, parameter pelatihan didefinisikan dengan menggunakan kelas TrainingArguments.
from transformers import TrainingArguments
batch_size = 16
logging_steps = len(dataset_encoded["train"]) // batch_size
model_name = "sample-distilbert-text-classification"
training_args = TrainingArguments(
output_dir=model_name,
num_train_epochs=2,
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
weight_decay=0.01,
evaluation_strategy="epoch",
disable_tqdm=False,
logging_steps=logging_steps,
push_to_hub=False,
log_level="error"
)
Kelas Trainer digunakan untuk pelatihan.
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=dataset_encoded["train"],
eval_dataset=dataset_encoded["validation"],
tokenizer=tokenizer
)
trainer.train()
| Epoch | Training Loss | Validation Loss | Accuracy | F1 |
| ----- | ------------- | --------------- | -------- | -------- |
| 1 | 0.481200 | 0.199959 | 0.926000 | 0.924853 |
| 2 | 0.147700 | 0.155566 | 0.936500 | 0.936725 |
TrainOutput(global_step=2000, training_loss=0.3144808197021484, metrics={'train_runtime': 301.8879, 'train_samples_per_second': 106.0, 'train_steps_per_second': 6.625, 'total_flos': 720342861696000.0, 'train_loss': 0.3144808197021484, 'epoch': 2.0})
Inferensi
Anda bisa mendapatkan hasil inferensi dengan predict().
preds_output = trainer.predict(dataset_encoded["validation"])
Hasil inferensi divisualisasikan dalam matriks kebingungan sebagai berikut.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import ConfusionMatrixDisplay, confusion_matrix
plt.style.use('ggplot')
y_preds = np.argmax(preds_output.predictions, axis=1)
y_valid = np.array(dataset_encoded["validation"]["label"])
labels = dataset_encoded["train"].features["label"].names
def plot_confusion_matrix(y_preds, y_true, labels):
cm = confusion_matrix(y_true, y_preds, normalize="true")
fig, ax = plt.subplots(figsize=(8, 8))
plt.rcParams.update({'font.size': 12})
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=labels)
disp.plot(cmap="Blues", values_format=".2f", ax=ax, colorbar=True)
plt.grid(None)
plt.title("Normalized confusion matrix", fontsize=16)
plt.show()
plot_confusion_matrix(y_preds, y_valid, labels)
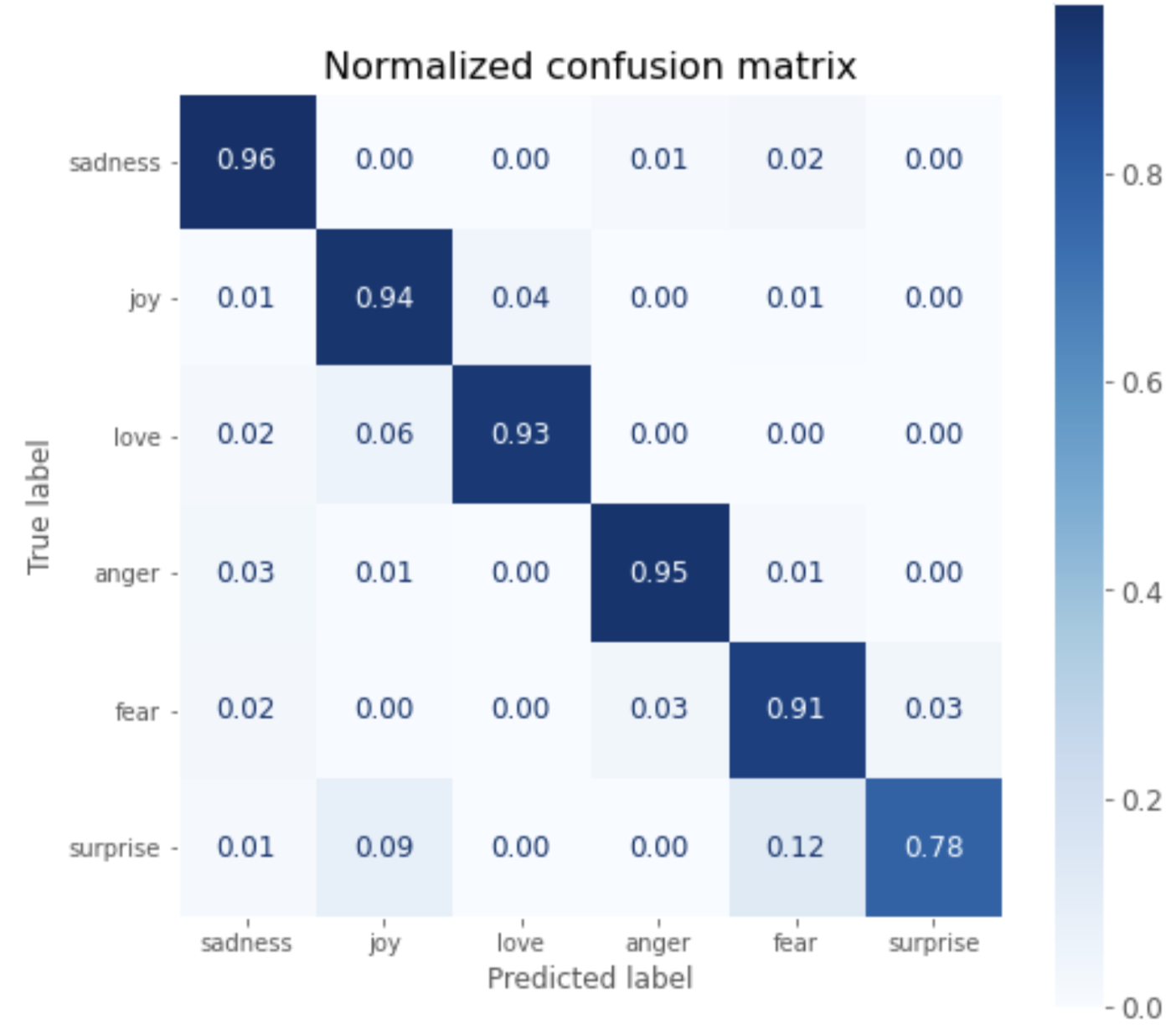
Anda dapat melihat bahwa kecuali untuk surprise, tingkat jawaban yang benar lebih dari 90%.
Menyimpan model
Atur informasi label dan simpan model dengan save_model().
id2label = {}
for i in range(dataset["train"].features["label"].num_classes):
id2label[i] = dataset["train"].features["label"].int2str(i)
label2id = {}
for i in range(dataset["train"].features["label"].num_classes):
label2id[dataset["train"].features["label"].int2str(i)] = i
trainer.model.config.id2label = id2label
trainer.model.config.label2id = label2id
trainer.save_model(f"./{model_name}")
Hasil penyimpanan adalah struktur direktori berikut ini.
sample-distilbert-text-classification
├── config.json
├── pytorch_model.bin
├── special_tokens_map.json
├── tokenizer_config.json
├── training_args.bin
└── vocab.txt
Muat dan simpulkan
Memuat Tokenizer dan model yang telah disimpan sebagai model PyTorch.
saved_tokenizer = AutoTokenizer.from_pretrained(f"./{model_name}")
saved_model = AutoModelForSequenceClassification.from_pretrained(f"./{model_name}").to(device)
Mari kita coba menyimpulkan contoh teks tersebut.
inputs = saved_tokenizer(sample_text, return_tensors="pt")
new_model.eval()
with torch.no_grad():
outputs = saved_model(
inputs["input_ids"].to(device),
inputs["attention_mask"].to(device),
)
outputs.logits
tensor([[-0.5823, 2.9460, -1.4961, 0.1718, -0.0931, -1.4067]],
device='cuda:0')
Mengonversi logit menjadi label yang disimpulkan menunjukkan bahwa emosi dari contoh teks disimpulkan sebagai joy.
y_preds = np.argmax(outputs.logits.to('cpu').detach().numpy().copy(), axis=1)
def id2label(x):
return new_model.config.id2label[x]
y_dash = [id2label(x) for x in y_preds]
>> y_dash
['joy']
Kode Google Colaboratory
Berikut ini adalah ringkasan kode tersebut.
from datasets import load_dataset
from transformers import AutoModelForSequenceClassification, AutoTokenizer
from transformers import TrainingArguments
from transformers import Trainer
from sklearn.metrics import accuracy_score, f1_score
from sklearn.metrics import ConfusionMatrixDisplay, confusion_matrix
import torch
import matplotlib.pyplot as plt
import numpy as np
plt.style.use('ggplot')
# checkpoint
model_ckpt = "distilbert-base-uncased"
# get dataset
dataset = load_dataset("emotion")
# get tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
# get model
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
num_labels = dataset["train"].features["label"].num_classes
model = (AutoModelForSequenceClassification
.from_pretrained(model_ckpt, num_labels=num_labels)
.to(device))
# tokenize
def tokenize(batch):
return tokenizer(batch["text"], padding=True, truncation=True)
dataset_encoded = dataset.map(tokenize, batched=True, batch_size=None)
# preparation for training
batch_size = 16
logging_steps = len(dataset_encoded["train"]) // batch_size
model_name = f"sample-text-classification-distilbert"
training_args = TrainingArguments(
output_dir=model_name,
num_train_epochs=2,
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
weight_decay=0.01,
evaluation_strategy="epoch",
disable_tqdm=False,
logging_steps=logging_steps,
push_to_hub=False,
log_level="error",
)
# define evaluation metrics
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
f1 = f1_score(labels, preds, average="weighted")
acc = accuracy_score(labels, preds)
return {"accuracy": acc, "f1": f1}
# train
trainer = Trainer(
model=model, args=training_args,
compute_metrics=compute_metrics,
train_dataset=dataset_encoded["train"],
eval_dataset=dataset_encoded["validation"],
tokenizer=tokenizer
)
trainer.train()
# eval
preds_output = trainer.predict(dataset_encoded["validation"])
y_preds = np.argmax(preds_output.predictions, axis=1)
y_valid = np.array(dataset_encoded["validation"]["label"])
labels = dataset_encoded["train"].features["label"].names
def plot_confusion_matrix(y_preds, y_true, labels):
cm = confusion_matrix(y_true, y_preds, normalize="true")
fig, ax = plt.subplots(figsize=(8, 8))
plt.rcParams.update({'font.size': 12})
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=labels)
disp.plot(cmap="Blues", values_format=".2f", ax=ax, colorbar=True)
plt.grid(None)
plt.title("Normalized confusion matrix", fontsize=16)
plt.show()
plot_confusion_matrix(y_preds, y_valid, labels)
# labeling
id2label = {}
for i in range(dataset["train"].features["label"].num_classes):
id2label[i] = dataset["train"].features["label"].int2str(i)
label2id = {}
for i in range(dataset["train"].features["label"].num_classes):
label2id[dataset["train"].features["label"].int2str(i)] = i
trainer.model.config.id2label = id2label
trainer.model.config.label2id = label2id
# save
trainer.save_model(f"./{model_name}")
# load
new_tokenizer = AutoTokenizer\
.from_pretrained(f"./{model_name}")
new_model = (AutoModelForSequenceClassification
.from_pretrained(f"./{model_name}")
.to(device))
# infer with sample text
inputs = new_tokenizer(sample_text, return_tensors="pt")
new_model.eval()
with torch.no_grad():
outputs = new_model(
inputs["input_ids"].to(device),
inputs["attention_mask"].to(device),
)
y_preds = np.argmax(outputs.logits.to('cpu').detach().numpy().copy(), axis=1)
def id2label(x):
return new_model.config.id2label[x]
y_dash = [id2label(x) for x in y_preds]
y_dash
Referensi















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS