


Apa itu distribusi kategorikal
Distribusi kategorikal adalah distribusi probabilitas yang diikuti oleh variabel acak
Distribusi kategorikal adalah distribusi probabilitas yang memperluas distribusi Bernoulli ke dimensi
Probabilitas dari distribusi kategorikal dinyatakan dengan persamaan berikut:
Distribusi kategorikal kadang-kadang dilambangkan sebagai
Nilai yang diharapkan dan varians dari distribusi kategorikal
Nilai yang diharapkan dan varians dari distribusi kategorikal masing-masing adalah:
Periksa distribusi kategorikal dengan Python
Mari kita periksa distribusi kategorikal dengan Python.
Pertama, perhatikan contoh dadu (
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('ggplot')
fig, ax = plt.subplots(facecolor="w", figsize=(10, 5))
p = [1/6, 1/6, 1/6, 1/6, 1/6, 1/6]
data = np.random.choice([1,2,3,4,5,6], p=p, size=6000)
plt.hist(data, bins = [0.5 + v for v in range(len(p) + 1)], alpha=0.5)
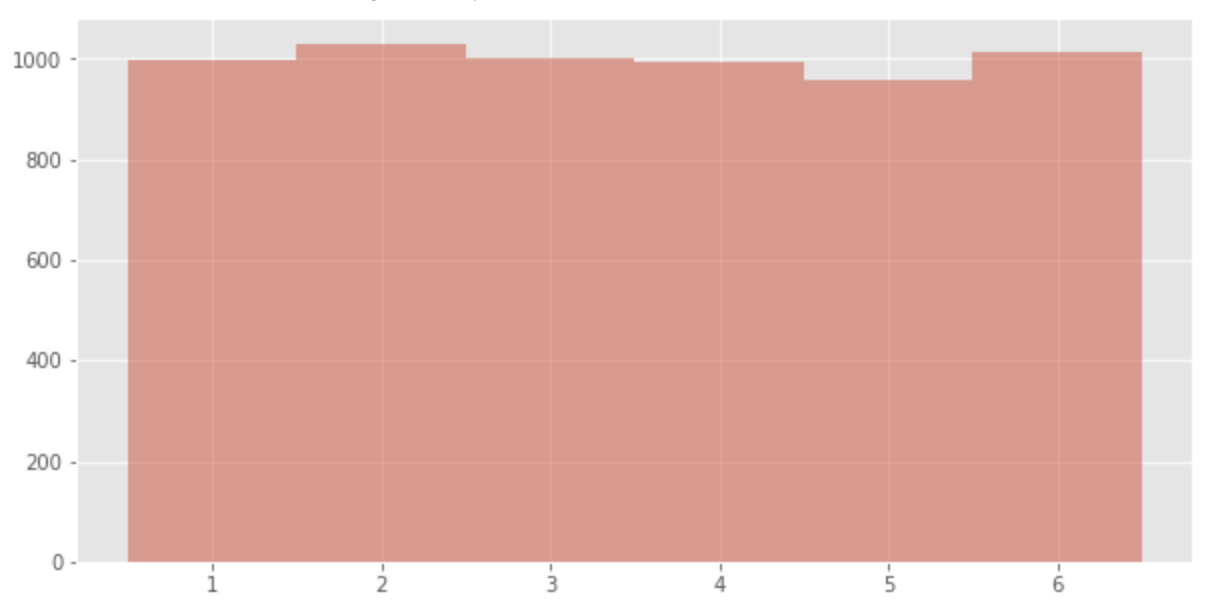
Kita dapat melihat bahwa jumlah kejadian dari setiap mata adalah sekitar 1000.
Selanjutnya, misalkan kita memiliki
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.ticker import MaxNLocator
plt.style.use('ggplot')
fig, ax = plt.subplots(facecolor="w", figsize=(10, 5))
ax.xaxis.set_major_locator(MaxNLocator(integer=True))
p = [2/10, 1/10, 5/10, 2/10]
data = np.random.choice([1,2,3,4], p=p, size=10000)
plt.hist(data, bins = [0.5 + v for v in range(len(p) + 1)], alpha=0.5)
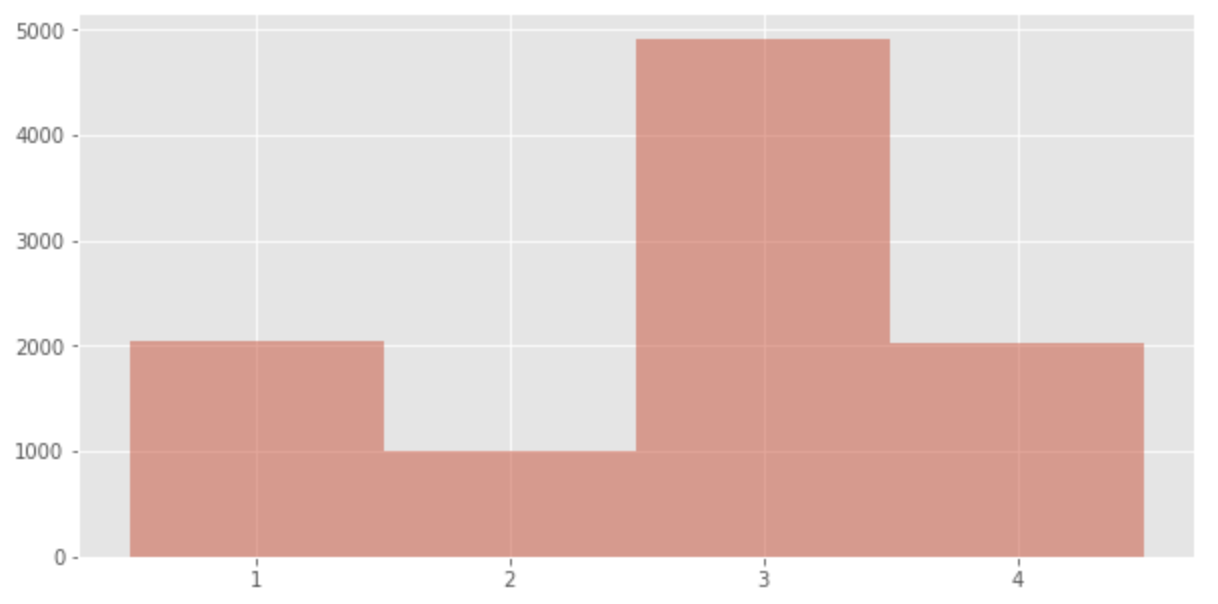
Kita bisa melihat bahwa distribusinya sejalan dengan probabilitas.
















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS