


What is LightGBM
LightGBM, short for Light Gradient Boosting Machine, is a fast, distributed, high-performance gradient boosting library developed by Microsoft. It is specifically designed to handle large-scale datasets and high-dimensional feature spaces efficiently, making it an ideal choice for various machine learning tasks, including regression, classification, and ranking problems.
LightGBM's Unique Features and Advantages
LightGBM offers several key features and advantages over other gradient boosting libraries.
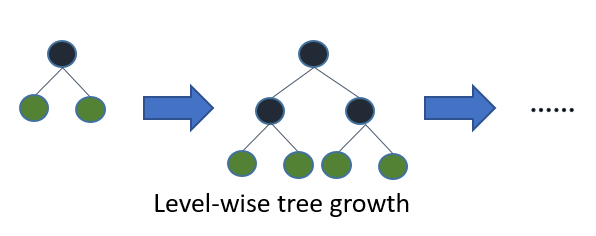
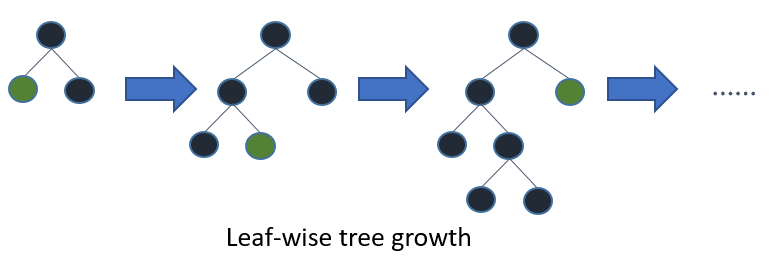
Leaf-wise Tree Growth
Traditional gradient boosting algorithms grow trees level-wise, where all nodes at the same level are split before any node in the next level. In contrast, LightGBM employs a leaf-wise growth strategy, which prioritizes splitting nodes with the highest loss reduction. This approach allows for faster convergence and improved model accuracy, albeit at the risk of overfitting if not properly controlled.
Histogram-based Algorithms
LightGBM uses histogram-based algorithms to speed up the training process. It approximates continuous feature values by dividing them into discrete bins, which reduces the number of split points to evaluate. This approach results in a significant reduction in training time and memory usage compared to traditional gradient boosting methods.
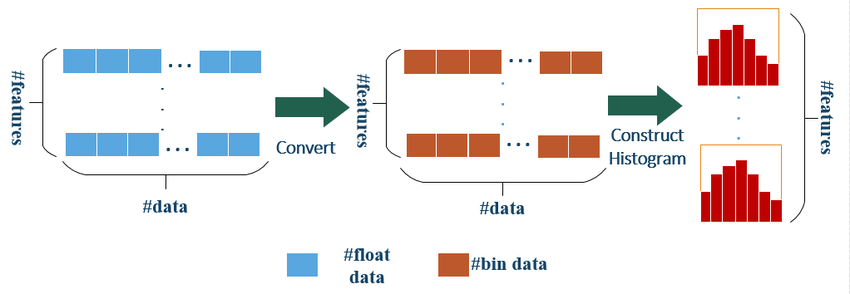
Histogram algorithm of LightGBM
Categorical Feature Support
Unlike other gradient boosting libraries, LightGBM offers native support for categorical features, eliminating the need for one-hot encoding or other preprocessing steps. By using optimal split points, LightGBM can efficiently handle categorical variables with high cardinality, which improves model performance and simplifies the feature engineering process.
Efficient Parallel Learning
LightGBM supports both data and feature parallelism, enabling efficient parallel learning on multi-core CPUs and distributed systems. This feature allows LightGBM to scale well with large datasets and high-dimensional feature spaces, making it suitable for a wide range of applications.
Gradient-based One-Side Sampling (GOSS)
To further accelerate the training process, LightGBM introduces Gradient-based One-Side Sampling (GOSS), a novel sampling technique. GOSS selectively samples a subset of the training data in each iteration based on the magnitude of their gradients. Instances with larger gradients, which contribute more to the model's overall loss, are prioritized, while a random subset of instances with smaller gradients is also included to maintain data diversity. This approach retains the most informative samples while reducing the computational cost of training, leading to faster convergence and improved model performance.

An Example of Hyperparameter Optimization on XGBoost, LightGBM and CatBoost using Hyperopt
Exclusive Feature Bundling (EFB)
Another unique feature of LightGBM is Exclusive Feature Bundling (EFB), which aims to reduce the dimensionality of sparse datasets. EFB identifies sets of mutually exclusive features, meaning they never take nonzero values simultaneously, and bundles them together into a single feature. This bundling process effectively compresses the feature space without loss of information, enabling more efficient tree construction and reduced memory usage. EFB is particularly useful when dealing with high-dimensional, sparse datasets commonly found in text and click-through rate prediction tasks.
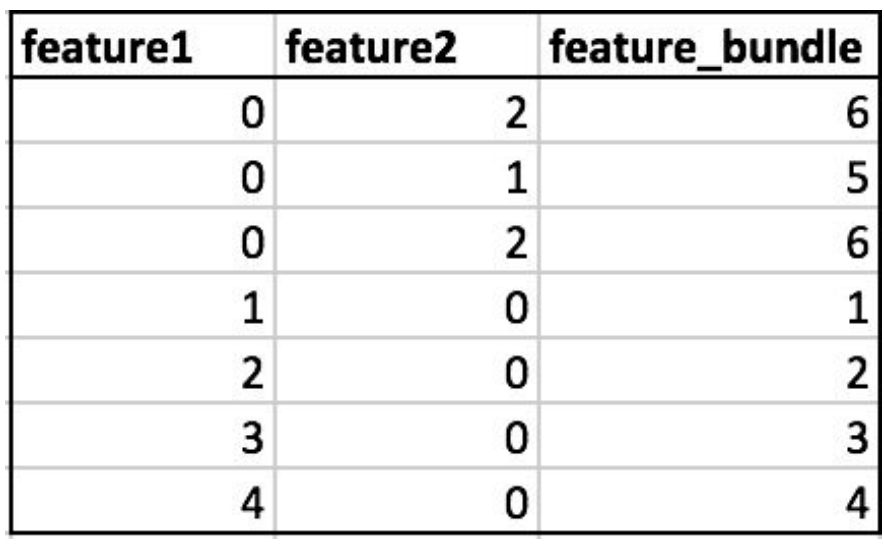
Comparing lightgbm to other R GBDT libraries
Comparison to XGBoost
Both XGBoost and LightGBM are designed to deliver high performance and scalability for large-scale datasets. However, LightGBM often outperforms XGBoost in terms of training speed and memory usage, thanks to its histogram-based algorithms, leaf-wise tree growth, GOSS, and EFB. These features enable LightGBM to handle larger datasets and higher-dimensional feature spaces more efficiently than XGBoost.
However, it is essential to note that performance can vary depending on the specific problem and dataset. In some cases, XGBoost might provide better accuracy, while LightGBM might deliver faster training times. It is recommended to try both libraries on your dataset to determine which one offers the best performance for your specific case.
Ease of Use
Both XGBoost and LightGBM offer a user-friendly interface and can be easily integrated with popular machine learning libraries such as scikit-learn, Keras, and TensorFlow. Both libraries provide comprehensive documentation and active community support, making them accessible for users of all experience levels.
Unique Features
While both libraries share many common features, they also have unique capabilities that differentiate them from one another. Some key unique features of LightGBM include:
- Leaf-wise tree growth
- Gradient-based One-Side Sampling (GOSS)
- Exclusive Feature Bundling (EFB)
- Native support for categorical features
On the other hand, XGBoost offers the following unique features:
- Column block for external memory
- Built-in support for missing values
- Regularized learning objective
- Monotonic constraints on tree splits
References
















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS