

Pengenalan
Inisialisasi bobot merupakan aspek penting dalam pelatihan model deep learning, karena dapat secara signifikan mempengaruhi kinerja, waktu pelatihan, dan stabilitas model. Bobot awal dari jaringan saraf dapat mempengaruhi seberapa cepat model konvergen selama pelatihan dan apakah konvergen pada solusi optimal atau suboptimal. Memilih strategi inisialisasi bobot yang tepat sangat penting untuk mencapai hasil terbaik dalam proyek deep learning Anda.
Inisialisasi bobot menentukan nilai awal dari bobot pada jaringan saraf yang sangat mempengaruhi proses pembelajaran. Inisialisasi bobot yang tepat dapat mempercepat konvergensi dan meningkatkan generalisasi, sedangkan inisialisasi bobot yang buruk dapat mengakibatkan konvergensi yang lambat atau bahkan kegagalan dalam pembelajaran. Dengan memahami dampak dari berbagai teknik inisialisasi bobot, praktisi dapat membuat keputusan yang lebih terinformasi dan mengembangkan model yang lebih baik.
Teknik-teknik Inisialisasi Bobot
Dalam bab ini, saya akan menjelajahi berbagai teknik inisialisasi bobot yang banyak digunakan dalam komunitas deep learning. Setiap teknik memiliki keunggulan uniknya dan cocok untuk jenis arsitektur jaringan saraf dan fungsi aktivasi yang berbeda. Memahami teknik ini akan membantu Anda membuat keputusan yang lebih terinformasi saat merancang dan melatih model deep learning.
Inisialisasi Nol
Inisialisasi nol merupakan metode paling sederhana, di mana semua bobot pada jaringan diinisialisasi menjadi nol. Meskipun mudah dilaksanakan, pendekatan ini memiliki kekurangan signifikan: semua neuron dalam jaringan belajar fitur yang sama selama pelatihan. Sebagai hasilnya, model menjadi tidak mampu menangkap kompleksitas data, yang mengakibatkan kinerja yang buruk. Fenomena ini dikenal sebagai "masalah simetri" dan umumnya tidak direkomendasikan untuk digunakan pada model deep learning.
Inisialisasi Acak
Untuk mengatasi masalah simetri, inisialisasi acak memberikan nilai acak kecil pada bobot. Metode ini memastikan bahwa setiap neuron belajar fitur yang berbeda, sehingga memungkinkan model untuk menangkap kompleksitas data. Namun, inisialisasi acak juga memiliki masalah. Ketika bobot awal terlalu besar atau terlalu kecil, dapat mengakibatkan gradasi yang hilang atau eksplorasi yang dapat berdampak negatif pada proses pembelajaran.
Inisialisasi Xavier (Glorot)
Diusulkan oleh Glorot dan Bengio pada tahun 2010, inisialisasi Xavier mengatasi masalah yang terkait dengan inisialisasi acak dengan menyetel bobot awal berdasarkan jumlah unit masukan dan keluaran pada suatu lapisan. Secara khusus, bobot diambil dari distribusi Gaussian dengan rata-rata 0 dan varians
Inisialisasi He (Kaiming)
Inisialisasi He, juga dikenal sebagai inisialisasi Kaiming, diperkenalkan oleh He dkk. pada tahun 2015. Seperti inisialisasi Xavier, inisialisasi He juga menyetel bobot awal, tetapi dirancang khusus untuk jaringan dengan Rectified Linear Unit (ReLU) dan varian-varian aktivasi ReLU. Bobot diambil dari distribusi Gaussian dengan rata-rata 0 dan varians
Inisialisasi LeCun
Inisialisasi LeCun, yang diusulkan oleh Yann LeCun, adalah metode inisialisasi bobot populer lainnya. Seperti inisialisasi Xavier dan He, inisialisasi LeCun juga menyetel bobot awal berdasarkan ukuran masukan pada suatu lapisan. Bobot diambil dari distribusi Gaussian dengan rata-rata 0 dan varians
Inisialisasi Ortogonal
Inisialisasi Ortogonal, yang diperkenalkan oleh Saxe dkk. pada tahun 2013, menginisialisasi matriks bobot dengan matriks ortogonal acak. Metode ini membantu menjaga magnitudo gradien selama propagasi balik, yang dapat mengakibatkan konvergensi yang lebih cepat dan kinerja yang lebih baik. Inisialisasi Ortogonal sangat berguna untuk jaringan saraf dalam atau rekursif, di mana gradasi yang hilang atau eksplorasi yang dapat menjadi masalah.
Memilih Metode Inisialisasi yang Tepat
Memilih metode inisialisasi bobot yang tepat sangat penting untuk melatih model deep learning yang efektif. Dalam bab ini, saya akan membahas faktor-faktor yang harus dipertimbangkan saat memilih teknik inisialisasi, serta pedoman untuk memilih teknik yang paling sesuai untuk kasus penggunaan Anda.
Arsitektur Jaringan
Arsitektur jaringan saraf Anda memainkan peran kritis dalam menentukan metode inisialisasi bobot yang paling cocok. Misalnya, jaringan yang dalam dengan banyak lapisan lebih rentan terhadap gradasi yang hilang atau eksplorasi yang dapat mengakibatkan teknik inisialisasi seperti Xavier, He, atau Orthogonal lebih cocok. Sebaliknya, jaringan yang dangkal mungkin tidak sensitif terhadap pilihan metode inisialisasi.
Fungsi Aktivasi
Jenis fungsi aktivasi yang digunakan dalam jaringan saraf Anda juga memengaruhi pilihan inisialisasi bobot. Sebagai contoh:
- Fungsi aktivasi Sigmoid atau Hyperbolic Tangent (tanh) cocok dengan inisialisasi Xavier atau LeCun.
- ReLU dan varian-varian nya, seperti Leaky ReLU dan Parametric ReLU, lebih cocok dengan inisialisasi He (Kaiming).
- Jaringan saraf dalam atau rekursif yang rentan terhadap gradasi yang hilang atau eksplorasi dapat menguntungkan dari inisialisasi Ortogonal.
Kompleksitas Masalah
Kompleksitas masalah yang diselesaikan juga memainkan peran dalam memilih metode inisialisasi bobot yang sesuai. Masalah yang lebih kompleks, seperti data dengan dimensi tinggi atau tugas dengan beberapa modalitas, mungkin memerlukan teknik inisialisasi yang lebih canggih untuk memastikan pembelajaran yang efektif.
Memilih Metode Inisialisasi yang Tepat
Berdasarkan faktor-faktor yang disebutkan di atas, pedoman-pedoman berikut dapat membantu Anda memilih teknik inisialisasi bobot yang paling sesuai untuk model deep learning Anda:
- Hindari inisialisasi nol, karena mengakibatkan masalah simetri dan kinerja model yang buruk.
- Untuk jaringan dengan fungsi aktivasi sigmoid atau tanh, pertimbangkan menggunakan inisialisasi Xavier atau LeCun.
- Untuk jaringan dengan ReLU atau varian-varian nya, seperti inisialisasi He (Kaiming) umumnya merupakan pilihan yang disukai.
- Untuk jaringan dalam atau rekursif yang rentan terhadap gradasi yang hilang atau eksplorasi, inisialisasi Ortogonal dapat menjadi pilihan yang cocok.
Ingatlah bahwa pedoman-pedoman ini adalah pedoman umum, dan metode inisialisasi bobot terbaik untuk masalah khusus Anda dapat bervariasi. Penting untuk bereksperimen dengan teknik yang berbeda dan memantau dampaknya pada kinerja model selama proses pelatihan.
Membandingkan Teknik Inisialisasi Bobot
Dalam bab ini, saya akan membandingkan teknik inisialisasi bobot dengan menerapkannya dalam Python dan menganalisis dampaknya pada distribusi aktivasi dari jaringan saraf 4-lapisan tersembunyi. Kita akan menggunakan dataset publik dan memvisualisasikan distribusi aktivasi dalam bentuk histogram untuk memahami perbedaan antara metode inisialisasi.
Setup Dataset dan Model:
Untuk perbandingan ini, kita akan menggunakan dataset MNIST yang populer, yang terdiri dari 60.000 gambar latihan dan 10.000 gambar uji dari digit tulisan tangan (0-9). Kita akan menggunakan jaringan saraf pengumpanan maju sederhana dengan 5 lapisan dan fungsi aktivasi ReLU.
Model adalah jaringan saraf 5 lapisan dengan struktur berikut:
- Lapisan input dengan 784 node (sesuai dengan ukuran gambar MNIST yang dibentangkan sebesar 28x28 piksel)
- Lapisan tersembunyi pertama dengan 512 node
- Lapisan tersembunyi kedua dengan 256 node
- Lapisan tersembunyi ketiga dengan 128 node
- Lapisan tersembunyi keempat dengan 64 node
Menerapkan Teknik Inisialisasi Bobot di Python
Mari mulai dengan mengimpor library yang diperlukan dan mendefinisikan fungsi inisialisasi:
import numpy as np
import matplotlib.pyplot as plt
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import Adam
from keras.initializers import Zeros, RandomNormal, GlorotNormal, HeNormal, LecunNormal
# Define weight initialization functions
def init_zeros(shape, dtype=None):
return Zeros()(shape, dtype=dtype)
def init_random_normal(shape, dtype=None):
return RandomNormal(stddev=0.01)(shape, dtype=dtype)
def init_xavier(shape, dtype=None):
return GlorotNormal()(shape, dtype=dtype)
def init_he(shape, dtype=None):
return HeNormal()(shape, dtype=dtype)
def init_lecun(shape, dtype=None):
return LecunNormal()(shape, dtype=dtype)
Membangun Model dan Visualisasi Distribusi Aktivasi
Sekarang, mari buat fungsi untuk membangun model menggunakan metode inisialisasi bobot yang ditentukan, melatihnya pada dataset MNIST, dan membuat histogram dari distribusi aktivasi di setiap lapisan.
def build_and_train_model(init_func, dataset, layer_dims=[784, 512, 256, 128, 64], activation='relu', epochs=5):
(X_train, y_train), (X_test, y_test) = dataset
model = Sequential()
input_dim = layer_dims[0]
for layer_dim in layer_dims[1:]:
model.add(Dense(layer_dim, input_dim=input_dim, activation=activation, kernel_initializer=init_func))
input_dim = layer_dim
model.compile(optimizer=Adam(), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs=epochs, validation_data=(X_test, y_test), verbose=0)
activations = []
for layer in model.layers:
intermediate_model = Sequential(model.layers[:model.layers.index(layer) + 1])
activations.append(intermediate_model.predict(X_test))
return history, activations
Menganalisis Distribusi Aktivasi
Sekarang mari kita analisis distribusi aktivasi untuk setiap metode inisialisasi dengan memplot histogram di setiap lapisan.
initializers = {
'Zero': init_zeros,
'Random Normal': init_random_normal,
'Xavier': init_xavier,
'He': init_he,
'LeCun': init_lecun
}
dataset = mnist.load_data()
fig, axes = plt.subplots(len(initializers), 4, figsize=(25, 25))
plt.style.use('ggplot')
for idx, (name, init_func) in enumerate(initializers.items()):
_, activations = build_and_train_model(init_func, dataset)
for layer_idx, activation in enumerate(activations):
axes[idx, layer_idx].hist(activation.flatten(), bins=50, density=True, color='blue', alpha=0.5)
axes[idx, layer_idx].set_xlim(-1, 1)
axes[idx, layer_idx].set_ylim(0, 4)
axes[idx, layer_idx].set_title(f'{name} Initialization - Layer {layer_idx + 1}', fontsize=16)
axes[idx, layer_idx].set_xlabel('Activation Value', fontsize=12)
axes[idx, layer_idx].set_ylabel('Density', fontsize=12)
plt.subplots_adjust(hspace=0.4, wspace=0.4)
plt.show()
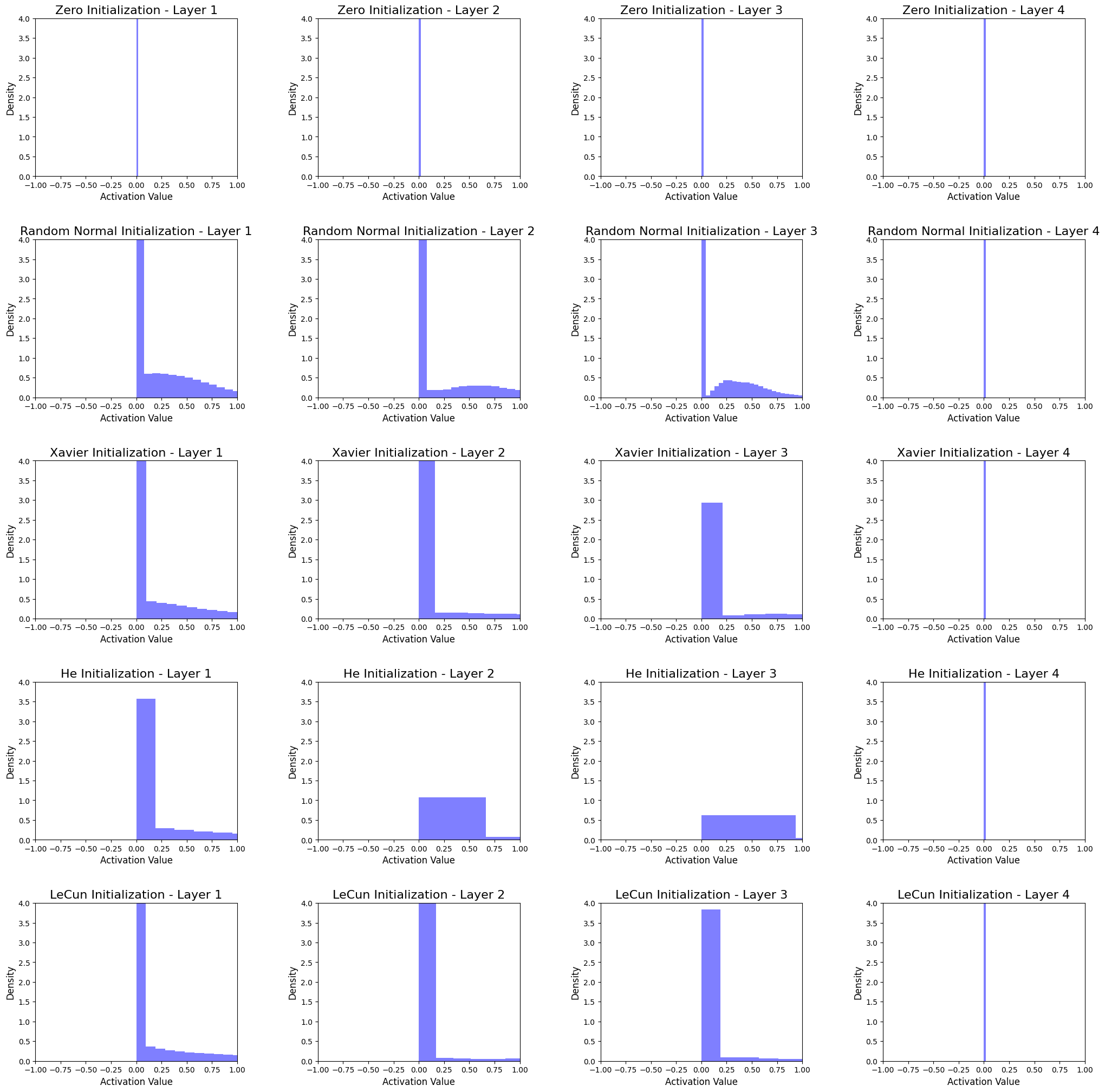
Menginterpretasi Histogram
Histogram menunjukkan distribusi aktivasi dari jaringan saraf 4-lapisan tersembunyi untuk setiap metode inisialisasi. Dengan menganalisis histogram, kita dapat membuat kesimpulan sebagai berikut:
-
Inisialisasi Nol
Aktivasi untuk semua lapisan terkonsentrasi pada nol. Ini menunjukkan bahwa model tidak dapat menangkap kompleksitas data dan menghasilkan pembelajaran yang buruk. -
Inisialisasi Normal Acak
Aktivasi di setiap lapisan memiliki distribusi normal. Namun, sebagian besar aktivasi dekat dengan nol, yang mungkin menyebabkan neuron mati, yang berdampak negatif pada proses pembelajaran. -
Inisialisasi Xavier
Aktivasi memiliki distribusi normal dengan simpangan baku yang lebih tinggi daripada Inisialisasi Normal Acak, sehingga menghasilkan pembelajaran yang lebih baik. Metode ini cocok untuk jaringan yang menggunakan fungsi aktivasi sigmoid atau tanh, tetapi mungkin bukan pilihan terbaik untuk fungsi aktivasi ReLU. -
Inisialisasi He
Aktivasi lebih merata dibandingkan dengan metode lainnya, sehingga membantu menghindari neuron mati dan menghasilkan pembelajaran yang lebih baik. Metode ini dirancang khusus untuk jaringan dengan fungsi aktivasi ReLU dan umumnya menjadi pilihan yang disukai. -
Inisialisasi LeCun
Aktivasi mirip dengan Inisialisasi Xavier, tetapi dengan simpangan baku yang sedikit lebih rendah. Metode ini cocok untuk jaringan yang menggunakan fungsi aktivasi sigmoid atau tanh.
Dalam semua metode, aktivasi untuk lapisan tersembunyi terakhir terkonsentrasi pada nol. Salah satu faktor mungkin adalah ukuran node (64 node) pada lapisan tersembunyi terakhir.
Dari analisis tersebut, dapat kita lihat bahwa pilihan metode inisialisasi bobot memiliki dampak yang signifikan pada distribusi aktivasi di jaringan. Secara umum, Inisialisasi He tampil terbaik untuk jaringan dengan fungsi aktivasi ReLU, sedangkan Inisialisasi Xavier atau LeCun mungkin lebih cocok untuk jaringan dengan fungsi aktivasi sigmoid atau tanh. Penting untuk memilih teknik inisialisasi bobot yang sesuai berdasarkan karakteristik khusus dari arsitektur jaringan saraf dan fungsi aktivasi yang digunakan.

















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS